Управление непрерывностью бизнес-процессов в Azure
Azure поддерживает одну из самых зрелых и уважаемых программ управления непрерывностью бизнес-процессов в отрасли. Цель непрерывности бизнес-процессов в Azure заключается в создании и повышении устойчивости и устойчивости для всех независимо восстанавливаемых служб, независимо от того, является ли служба клиентом (часть предложения Azure) или внутренней вспомогательной платформы.
В понимании непрерывности бизнес-процессов важно отметить, что многие предложения состоят из нескольких служб. В Azure каждая служба статически определяется с помощью инструментов и является единицей мер, используемых для конфиденциальности, безопасности, инвентаризации, управления непрерывностью бизнес-процессов и других функций. Для правильного измерения возможностей службы три элемента людей, процессов и технологий включаются для каждой службы независимо от типа службы.
Например:
- Если бизнес-процесс основан на людях, таких как служба технической поддержки или команда, доставка услуг — это то, что они делают. Люди используют процессы и технологии для выполнения службы.
- Если есть технология как услуга, например Azure Виртуальные машины, доставка служб — это технология вместе с людьми и процессами, которые поддерживают свою работу.
Модель общей ответственности
Многие предложения Azure требуют настройки аварийного восстановления в нескольких регионах и не несут ответственности за корпорацию Майкрософт. Не все службы Azure автоматически реплицируют данные или выполняют откат, выполняя переход из неудачного региона для перекрестной репликации в другой включенный регион. В этих случаях вы несете ответственность за настройку восстановления и реплика tion.
Корпорация Майкрософт гарантирует, что доступны базовые службы инфраструктуры и платформы. Но в некоторых сценариях использование требует дублирования развертываний и хранилища в емкости с несколькими регионами, если вы решили. В этих примерах показана модель общей ответственности. Это фундаментальный принцип обеспечения непрерывности бизнес-процессов и стратегии аварийного восстановления.
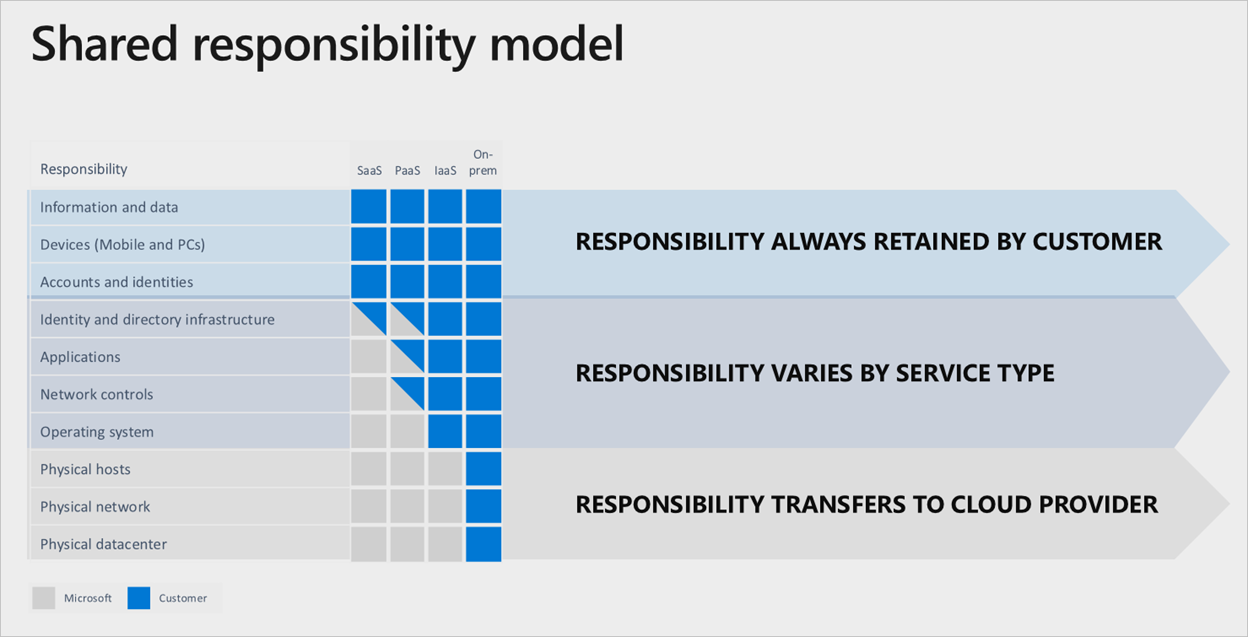
Разделение ответственности
В любом локальном центре обработки данных вы владеете всем стеком. При перемещении ресурсов в облако некоторые обязанности передаются в корпорацию Майкрософт. На следующей схеме показаны области и разделение ответственности между вами и Корпорацией Майкрософт в соответствии с типом развертывания.
Хорошим примером модели общей ответственности является развертывание виртуальных машин. Если вы хотите настроить межрегионную реплика tion для устойчивости при сбое региона, необходимо развернуть повторяющийся набор виртуальных машин в альтернативном регионе с поддержкой. Azure не автоматически реплика эти службы, если произошел сбой. Вы несете ответственность за развертывание необходимых ресурсов. Чтобы вручную изменить основные регионы, необходимо использовать диспетчер трафика для обнаружения и автоматического отработки отказа.
Все службы аварийного восстановления с поддержкой клиентов имеют общедоступную документацию, которая поможет вам. Пример общедоступной документации по аварийному восстановлению с поддержкой клиентов см. в статье Azure Data Lake Analytics.
Дополнительные сведения о модели общей ответственности см . в Центре управления безопасностью Майкрософт.
Соответствие требованиям к непрерывности бизнес-процессов: ответственность за уровень обслуживания
Каждая служба требуется для завершения записей аварийного восстановления непрерывности бизнес-процессов в средстве диспетчера непрерывности бизнес-процессов Azure. Владельцы служб могут использовать средство для работы в федеративной модели для выполнения и включения требований, которые включают:
Свойства службы: определяет службу и способ достижения аварийного восстановления и устойчивости и определяет ответственной стороной для аварийного восстановления (для технологии). Дополнительные сведения о владельцах восстановления см. в обсуждении модели общей ответственности в предыдущем разделе и схеме.
Анализ влияния на бизнес: этот анализ помогает владельцу службы определить целевое время восстановления (RTO) и целевой точки восстановления (RPO) на основе критической важности службы в таблице последствий. Операционные, юридические, нормативные, фирменные изображения и финансовые последствия используются в качестве целевых целей для восстановления.
Примечание.
Корпорация Майкрософт не публикует RTO или RPOS для служб, так как эти данные предназначены только для внутренних мер. Все обещания и меры клиента основаны на уровне соглашения об уровне обслуживания, так как он охватывает более широкий диапазон и RTO или RPO, что применимо только в катастрофических потерях.
Зависимости. Каждая служба сопоставляет зависимости (другие службы), необходимые для работы независимо от того, насколько важно, и сопоставляется со средой выполнения, необходимой только для восстановления или обоих. При наличии зависимостей хранилища сопоставляются другие данные, определяющие хранимые данные, и если требуется моментальные снимки на определенный момент времени, например.
Рабочая сила: как отмечалось в определении службы, важно знать расположение и количество сотрудников, способных поддерживать службу, обеспечивая отсутствие отдельных точек сбоя, и если критически важные сотрудники разбросаны, чтобы избежать сбоев путем совместного проживания в одном расположении.
Внешние поставщики: Корпорация Майкрософт сохраняет полный список внешних поставщиков, и поставщики считаются критически важными для возможностей. Если служба идентифицируется как зависимость, возможности поставщика сравниваются с потребностями службы, чтобы убедиться, что сторонний сбой не нарушает службы Azure.
Оценка восстановления: эта оценка уникальна для программы управления непрерывностью бизнес-процессов Azure. Эта оценка измеряет несколько ключевых элементов для создания оценки устойчивости:
- Готовность к отработке отказа: хотя может быть процесс, это может не быть первым выбором для краткосрочных сбоев.
- Автоматизация отработки отказа.
- Автоматизация решения о отработки отказа.
Самый надежный и короткий срок отработки отказа — это служба, которая автоматизирована и не требует принятия человеческих решений. Автоматическая служба использует мониторинг пульса или искусственные транзакции, чтобы определить, что служба отключена, и начать немедленное исправление.
План восстановления и тест: Azure требует, чтобы каждая служба была подробной план восстановления и тестировать этот план, как если бы служба завершилась сбоем из-за катастрофического сбоя. Планы восстановления должны быть написаны, чтобы кто-то с аналогичными навыками и доступом могли выполнить задачи. Письменный план избегает того, чтобы полагаться на экспертов по темам, доступных.
Тестирование выполняется несколькими способами, включая самостоятельное тестирование в рабочей или почти рабочей среде, а также в рамках детализации полного региона Azure в наборах канарских регионов. Эти регионы с поддержкой идентичны рабочим регионам, но их можно отключить, не затрагивая ваши службы. Тестирование считается интегрированным, так как все службы затрагиваются одновременно.
Включение клиентов. Если вы отвечаете за настройку аварийного восстановления, Azure требуется для предоставления общедоступной документации. Для всех таких служб ссылки предоставляются в документации и подробных сведениях о процессе.
Проверка соответствия непрерывности бизнес-процессов
Когда служба завершит свою запись управления непрерывностью бизнес-процессов, необходимо отправить ее на утверждение. Она назначена опытному специалисту по управлению непрерывностью бизнес-процессов, который проверяет всю запись для полноты и качества. Если запись соответствует всем требованиям, она утверждена. Если это не так, это отклонено с запросом на повторную работу. Этот процесс гарантирует, что обе стороны согласны с тем, что соответствие требованиям непрерывности бизнес-процессов было выполнено, и что работа подтверждается только владельцем службы. Внутренние группы аудита и соответствия требованиям Azure также выполняют периодические случайные выборки, чтобы обеспечить отправку лучших данных.
Тестирование служб
Корпорация Майкрософт и Azure выполняют обширное тестирование как для аварийного восстановления, так и для готовности зоны доступности. Службы самостоятельно тестируются в рабочей или предварительной среде для демонстрации независимой возможности восстановления для служб, которые не зависят от основных отработок отказа платформы.
Чтобы службы могли аналогичным образом восстановиться в сценарии с истинным регионом вниз, тестирование типа "pull-the-plug" выполняется в канарной среде, которая полностью развернута в регионах, соответствующих рабочей среде. Например, кластеры, стойки и блоки питания буквально отключаются для имитации общего сбоя региона.
В ходе этих тестов Azure использует тот же рабочий процесс для обнаружения, уведомления, ответа и восстановления. Никто не ожидает детализации, и инженеры полагаются на восстановление являются обычными ресурсами смены по вызову. Это время избегает в зависимости от экспертов, которые могут быть недоступны во время фактического события.
В эти тесты входят службы, в которых вы отвечаете за настройку аварийного восстановления после общедоступной документации Майкрософт. Команды служб создают такие экземпляры, как клиент, чтобы показать, что аварийное восстановление с поддержкой клиента работает должным образом и что предоставленные инструкции являются точными.
Дополнительные сведения о сертификации см. в Центре управления безопасностью Майкрософт и в разделе о соответствии.