Высокий уровень доступности SAP HANA на виртуальных машинах Azure на SUSE Linux Enterprise Server
Чтобы установить высокий уровень доступности в локальном развертывании SAP HANA, можно использовать репликацию системы SAP HANA или общее хранилище.
В настоящее время на виртуальных машинах Azure репликация системы SAP HANA в Azure является единственной поддерживаемой функцией высокого уровня доступности.
Репликация системы SAP HANA состоит из одного первичного узла и по крайней мере одного дополнительного узла. Изменения данных на основном узле синхронно или асинхронно реплицируются на вторичные узлы.
В этой статье описывается, как развернуть и настроить виртуальные машины, установить платформу кластера и установить и настроить репликацию системы SAP HANA.
Перед началом работы ознакомьтесь со следующими заметками и документами SAP:
- Заметка SAP 1928533. Примечание включает в себя следующее:
- список размеров виртуальных машин Azure, поддерживаемых для развертывания ПО SAP;
- важные сведения о доступных ресурсах для каждого размера виртуальной машины Azure;
- Поддерживаемые сочетания программного обеспечения SAP, операционной системы (ОС) и базы данных.
- Необходимые версии ядра SAP для Windows и Linux в Microsoft Azure.
- примечание к SAP № 2015553, в котором описываются предварительные требования к SAP при развертывании программного обеспечения SAP в Azure;
- Примечание SAP 2205917 содержит рекомендуемые параметры ОС для SUSE Linux Enterprise Server 12 (SLES 12) для приложений SAP.
- Примечание SAP 2684254 содержит рекомендуемые параметры ОС для SUSE Linux Enterprise Server 15 (SLES 15) для приложений SAP.
- Sap Note 2235581 поддерживает операционные системы SAP HANA.
- Примечание SAP 2178632 содержит подробные сведения обо всех метрик мониторинга, сообщающихся для SAP в Azure.
- Примечание SAP 2191498 имеет необходимую версию агента узла SAP для Linux в Azure.
- Примечание SAP 2243692 содержит сведения о лицензировании SAP для Linux в Azure.
- примечание к SAP 1984787, содержащее общие сведения о SUSE Linux Enterprise Server 12;
- примечание к SAP 1999351, в котором приведены дополнительные сведения об устранении неполадок, связанных с расширением для расширенного мониторинга Azure для SAP;
- Примечание SAP 401162 содержит сведения о том, как избежать ошибок "адрес уже используется" при настройке репликации системы HANA.
- Вики-сайт поддержки сообщества SAP содержит все необходимые заметки SAP для Linux.
- Платформы IaaS с сертификатом SAP HANA.
- SAP NetWeaver на виртуальных машинах Windows. Руководство по планированию и внедрению;
- Руководство по развертыванию Виртуальные машины Azure для SAP в Linux.
- SAP NetWeaver на виртуальных машинах Windows. Руководство по развертыванию СУБД;
- Рекомендации по использованию SUSE Linux Enterprise Server для приложений SAP 15 и рекомендации по SUSE Linux Enterprise Server для приложений SAP 12:
- Настройка оптимизированной для производительности SAP HANA SR инфраструктуры (SLES для приложений SAP). В руководстве содержатся все необходимые сведения для настройки репликации системы SAP HANA для локальной разработки. Используйте это руководство как основу.
- Настройка оптимизированной для затрат инфраструктуры SAP HANA SR (SLES для приложений SAP).
Планирование высокой доступности SAP HANA
Чтобы обеспечить высокий уровень доступности, установите SAP HANA на двух виртуальных машинах. Данные реплицируются с помощью репликации системы HANA.
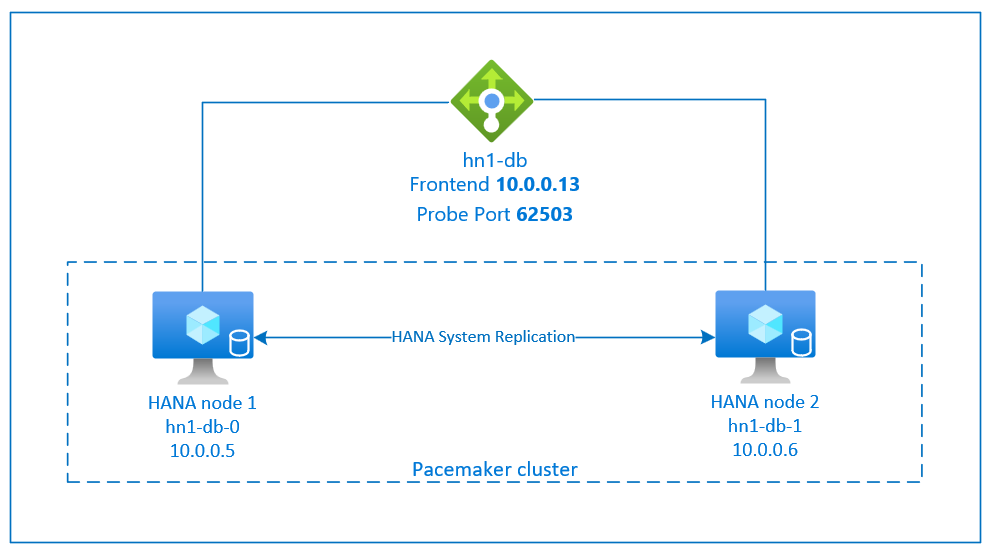
Настройка репликации системы SAP HANA использует выделенное имя виртуального узла и виртуальные IP-адреса. В Azure требуется подсистема балансировки нагрузки для развертывания виртуального IP-адреса.
На предыдущем рисунке показан пример подсистемы балансировки нагрузки с этими конфигурациями:
- Внешний IP-адрес: 10.0.0.13 для HN1-db
- Порт пробы: 62503
Подготовка инфраструктуры
Агент ресурсов для SAP HANA включен в состав SUSE Linux Enterprise Server for SAP Applications. Образ SUSE Linux Enterprise Server для приложений SAP 12 или 15 доступен в Azure Marketplace. Образ можно использовать для развертывания новых виртуальных машин.
Развертывание виртуальных машин Linux вручную с помощью портала Azure
В этом документе предполагается, что вы уже развернули группу ресурсов, Azure виртуальная сеть и подсеть.
Развертывание виртуальных машин для SAP HANA. Выберите подходящий образ SLES, поддерживаемый для системы HANA. Вы можете развернуть виртуальную машину в любом из вариантов доступности — масштабируемый набор виртуальных машин, зону доступности или группу доступности.
Внимание
Убедитесь, что выбранная ОС сертифицирована для SAP HANA на определенных типах виртуальных машин, которые планируется использовать в развертывании. Вы можете искать типы виртуальных машин, сертифицированные SAP HANA, и их выпуски ОС на платформах IaaS, сертифицированных sap HANA. Убедитесь, что вы просматриваете сведения о типе виртуальной машины, чтобы получить полный список выпусков ОС, поддерживаемых SAP HANA, для конкретного типа виртуальной машины.
Настройка Azure Load Balancer
Во время настройки виртуальной машины можно создать или выбрать выход из подсистемы балансировки нагрузки в разделе сети. Выполните следующие действия, чтобы настроить стандартную подсистему балансировки нагрузки для установки высокой доступности базы данных HANA.
Выполните действия, описанные в статье "Создание подсистемы балансировки нагрузки", чтобы настроить стандартную подсистему балансировки нагрузки для системы SAP с высоким уровнем доступности с помощью портал Azure. Во время настройки подсистемы балансировки нагрузки рассмотрите следующие моменты:
- Конфигурация внешнего IP-адреса: создание внешнего IP-адреса. Выберите ту же виртуальную сеть и имя подсети, что и виртуальные машины базы данных.
- Серверный пул: создайте внутренний пул и добавьте виртуальные машины базы данных.
- Правила для входящего трафика: создание правила балансировки нагрузки. Выполните те же действия для обоих правил балансировки нагрузки.
- Внешний IP-адрес: выберите внешний IP-адрес.
- Внутренний пул: выберите внутренний пул.
- Порты высокой доступности: выберите этот параметр.
- Протокол. Выберите TCP.
- Проба работоспособности: создайте пробу работоспособности со следующими сведениями:
- Протокол. Выберите TCP.
- Порт: например, 625<экземпляра no.>.
- Интервал. Введите 5.
- Пороговое значение пробы: введите 2.
- Время ожидания простоя (минуты): введите 30.
- Включите плавающий IP-адрес: выберите этот параметр.
Примечание.
Свойство конфигурации пробы работоспособности , в противном случае известное как неработоспособное пороговое значение numberOfProbesна портале, не учитывается. Чтобы управлять числом успешных или неудачных последовательных проб, задайте для свойства probeThreshold значение 2. В настоящее время невозможно задать это свойство с помощью портал Azure, поэтому используйте Azure CLI или команду PowerShell.
Дополнительные сведения о необходимых портах для SAP HANA см. в главе Подключения к базам данных клиента руководства Базы данных клиента SAP HANA или в примечании к SAP 2388694.
Примечание.
Если виртуальные машины, у которых нет общедоступных IP-адресов, помещаются в внутренний пул внутреннего (без общедоступного IP-адреса) стандартного экземпляра Azure Load Balancer, конфигурация по умолчанию не является исходящим подключением к Интернету. Вы можете выполнить дополнительные действия, чтобы разрешить маршрутизацию на общедоступные конечные точки. Дополнительные сведения о том, как обеспечить исходящее подключение, см. в статье "Подключение к общедоступной конечной точке для виртуальных машин" с помощью Azure Load Balancer (цен. категория в сценариях высокой доступности SAP.
Внимание
- Не включите метки времени TCP на виртуальных машинах Azure, размещенных за Azure Load Balancer. Включение меток времени TCP помешает работе проб работоспособности. Задайте для параметра
net.ipv4.tcp_timestamps0значение . Дополнительные сведения см. в 2382421 проб работоспособности Load Balancer или заметок SAP. - Чтобы предотвратить изменение значения saptune вручную
net.ipv4.tcp_timestamps,01обновите версию saptune до версии 3.1.1 или более поздней. Дополнительные сведения см. в разделе saptune 3.1.1 . Необходимо ли обновить?.
Создание кластера Pacemaker
Выполните действия, описанные в разделе "Настройка Pacemaker на SUSE Linux Enterprise Server в Azure ", чтобы создать базовый кластер Pacemaker для этого сервера HANA. Также вы можете применить один кластер Pacemaker для SAP HANA и SAP NetWeaver (A)SCS.
Установка SAP HANA
Во всех действиях этого раздела используются следующие префиксы.
- [A] — шаг применяется ко всем узлам.
- [1]: шаг применяется только к узлу 1.
- [2]. Шаг применяется только к узлу 2 кластера Pacemaker.
Замените <placeholders> значения для установки SAP HANA.
[A] Настройте структуру диска с помощью диспетчера логических томов (LVM).
Мы рекомендуем использовать диспетчер логических томов для всех томов, предназначенных для хранения данных и файлов журнала. В следующем примере предполагается, что виртуальные машины имеют четыре подключенных диска данных, которые используются для создания двух томов.
Выполните следующую команду, чтобы получить список всех доступных дисков:
ls /dev/disk/azure/scsi1/lun*Пример результата:
/dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 /dev/disk/azure/scsi1/lun2 /dev/disk/azure/scsi1/lun3Создайте физические тома для всех дисков, которые вы хотите использовать:
sudo pvcreate /dev/disk/azure/scsi1/lun0 sudo pvcreate /dev/disk/azure/scsi1/lun1 sudo pvcreate /dev/disk/azure/scsi1/lun2 sudo pvcreate /dev/disk/azure/scsi1/lun3Создайте группу томов для файлов данных. Используйте одну группу томов для файлов журналов и одной группы томов для общего каталога SAP HANA:
sudo vgcreate vg_hana_data_<HANA SID> /dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 sudo vgcreate vg_hana_log_<HANA SID> /dev/disk/azure/scsi1/lun2 sudo vgcreate vg_hana_shared_<HANA SID> /dev/disk/azure/scsi1/lun3Создайте логические тома.
Линейный том создается при использовании
lvcreateбез параметра-i. Для повышения производительности операций ввода-вывода мы рекомендуем создать том с чередованием. Сравняйте размеры полосы с значениями, описанными в конфигурациях хранилища виртуальных машин SAP HANA. Аргумент-iдолжен быть числом базовых физических томов, а-Iаргументом является размер полосы.Например, если для тома данных используются два физических тома,
-iаргумент коммутатора имеет значение 2, а размер полосы для тома данных составляет 256KiB. Журнальный том использует один физический том, поэтому параметры-iи-Iне используются явным образом в командах для журнального тома.Внимание
При использовании нескольких физических томов для каждого тома данных, тома журнала или общего тома используйте
-iкоммутатор и задайте для него количество базовых физических томов. При создании полосатого тома используйте-Iпараметр, чтобы указать размер полосы.Рекомендуемые конфигурации хранилища, включая размеры полосы и количество дисков, см . в конфигурациях хранилища виртуальных машин SAP HANA.
sudo lvcreate <-i number of physical volumes> <-I stripe size for the data volume> -l 100%FREE -n hana_data vg_hana_data_<HANA SID> sudo lvcreate -l 100%FREE -n hana_log vg_hana_log_<HANA SID> sudo lvcreate -l 100%FREE -n hana_shared vg_hana_shared_<HANA SID> sudo mkfs.xfs /dev/vg_hana_data_<HANA SID>/hana_data sudo mkfs.xfs /dev/vg_hana_log_<HANA SID>/hana_log sudo mkfs.xfs /dev/vg_hana_shared_<HANA SID>/hana_sharedСоздайте каталоги подключения и скопируйте универсальный уникальный идентификатор (UUID) всех логических томов:
sudo mkdir -p /hana/data/<HANA SID> sudo mkdir -p /hana/log/<HANA SID> sudo mkdir -p /hana/shared/<HANA SID> # Write down the ID of /dev/vg_hana_data_<HANA SID>/hana_data, /dev/vg_hana_log_<HANA SID>/hana_log, and /dev/vg_hana_shared_<HANA SID>/hana_shared sudo blkidИзмените файл /etc/fstab , чтобы создать
fstabзаписи для трех логических томов:sudo vi /etc/fstabВставьте следующие строки в файл /etc/fstab :
/dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_data_<HANA SID>-hana_data> /hana/data/<HANA SID> xfs defaults,nofail 0 2 /dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_log_<HANA SID>-hana_log> /hana/log/<HANA SID> xfs defaults,nofail 0 2 /dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_shared_<HANA SID>-hana_shared> /hana/shared/<HANA SID> xfs defaults,nofail 0 2Подключите новые тома:
sudo mount -a
[A] Настройте макет диска с помощью обычных дисков.
Для демонстрационных систем файлы данных и журналов HANA можно поместить на один диск.
Создайте раздел на /dev/disk/azure/scsi1/lun0 и отформатируйте его с помощью XFS:
sudo sh -c 'echo -e "n\n\n\n\n\nw\n" | fdisk /dev/disk/azure/scsi1/lun0' sudo mkfs.xfs /dev/disk/azure/scsi1/lun0-part1 # Write down the ID of /dev/disk/azure/scsi1/lun0-part1 sudo /sbin/blkid sudo vi /etc/fstabВставьте следующую строку в файл /etc/fstab:
/dev/disk/by-uuid/<UUID> /hana xfs defaults,nofail 0 2Создайте целевой каталог и подключите диск:
sudo mkdir /hana sudo mount -a
[A] Настройка разрешения имен узлов для всех узлов.
Вы можете использовать DNS-сервер или внести изменения в файл /etc/hosts на всех узлах. В этом примере показано, как использовать файл /etc/hosts . Замените IP-адреса и имена узлов в следующих командах.
Измените файл /etc/hosts :
sudo vi /etc/hostsВставьте следующие строки в файл /etc/hosts . Измените IP-адреса и имена узлов в соответствии с вашей средой.
10.0.0.5 hn1-db-0 10.0.0.6 hn1-db-1
[A] Установите SAP HANA, следуя документации SAP.
Настройка репликации системы SAP HANA 2.0
Во всех действиях этого раздела используются следующие префиксы.
- [A] — шаг применяется ко всем узлам.
- [1]: шаг применяется только к узлу 1.
- [2]. Шаг применяется только к узлу 2 кластера Pacemaker.
Замените <placeholders> значения для установки SAP HANA.
[1] Создайте базу данных клиента.
Если вы используете SAP HANA 2.0 или SAP HANA MDC, создайте базу данных клиента для системы SAP NetWeaver.
Выполните следующую команду как <adm sid>HANA:
hdbsql -u SYSTEM -p "<password>" -i <instance number> -d SYSTEMDB 'CREATE DATABASE <SAP SID> SYSTEM USER PASSWORD "<password>"'[1] Настройка репликации системы на первом узле:
Во-первых, создайте резервную копию баз данных в виде <adm безопасности>HANA:
hdbsql -d SYSTEMDB -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for SYS>')" hdbsql -d <HANA SID> -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for HANA SID>')" hdbsql -d <SAP SID> -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for SAP SID>')"Затем скопируйте файлы инфраструктуры открытых ключей системы (PKI) на дополнительный сайт:
scp /usr/sap/<HANA SID>/SYS/global/security/rsecssfs/data/SSFS_<HANA SID>.DAT hn1-db-1:/usr/sap/<HANA SID>/SYS/global/security/rsecssfs/data/ scp /usr/sap/<HANA SID>/SYS/global/security/rsecssfs/key/SSFS_<HANA SID>.KEY hn1-db-1:/usr/sap/<HANA SID>/SYS/global/security/rsecssfs/key/Создайте основной сайт:
hdbnsutil -sr_enable --name=<site 1>[2] Настройка репликации системы на втором узле:
Зарегистрируйте второй узел, чтобы запустить репликацию системы.
Выполните следующую команду как <adm sid>HANA:
sapcontrol -nr <instance number> -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2>
Реализация агентов ресурсов HANA
SUSE предоставляет два различных пакета программного обеспечения для агента ресурсов Pacemaker для управления SAP HANA. Пакеты программного обеспечения SAPHanaSR и SAPHanaSR-angi используют немного другой синтаксис и параметры и несовместимы. Дополнительные сведения и различия между SAPHanaSR и SAPHanaSR-angi см. в заметках о выпуске SUSE и документации. В этом документе рассматриваются оба пакета на отдельных вкладках в соответствующих разделах.
Предупреждение
Не замените пакет SAPHanaSR SAPHanaSR SAPHanaSR-angi в уже настроенном кластере. Для обновления с SAPHanaSR до SAPHanaSR-angi требуется определенная процедура.
- [A] Установите пакеты высокого уровня доступности SAP HANA.
Выполните следующую команду, чтобы установить пакеты высокой доступности:
sudo zypper install SAPHanaSR
Настройка поставщиков SAP HANA HA/DR
Поставщики SAP HANA HA/DR оптимизируют интеграцию с кластером и улучшают обнаружение при необходимости отработки отказа кластера. Основной скрипт перехватчика — SAPHanaSR (для пакета SAPHanaSR) / susHanaSR (для SAPHanaSR-angi). Настоятельно рекомендуется настроить перехватчик Python SAPHanaSR/susHanaSR. Для HANA 2.0 SPS 05 и более поздних версий рекомендуется реализовать как SAPHanaSR/susHanaSR, так и перехватчики susChkSrv.
Перехватчик susChkSrv расширяет функциональные возможности основного поставщика SAPHanaSR/susHanaSR HA. Он действует, когда процесс HANA завершает работу hdbindexserver. Если один процесс завершается сбоем, HANA обычно пытается перезапустить его. Перезапуск процесса indexserver может занять много времени, в течение которого база данных HANA не реагирует.
При реализации susChkSrv выполняется немедленное и настраиваемое действие. Действие активирует отработку отказа в настроенном периоде ожидания вместо ожидания перезапуска процесса hdbindexserver на том же узле.
- [A] Остановите HANA на обоих узлах.
Выполните следующий код как <sap-sid>adm:
sapcontrol -nr <instance number> -function StopSystem
[A] Установите перехватчики репликации системы HANA. Перехватчики должны быть установлены на обоих узлах базы данных HANA.
Совет
Перехватчик Python SAPHanaSR можно реализовать только для HANA 2.0. Пакет SAPHanaSR должен иметь по крайней мере версию 0.153.
Перехватчик Python SAPHanaSR-angi можно реализовать только для HANA 2.0 SPS 05 и более поздних версий.
Для перехватчика Python susChkSrv требуется установка SAP HANA 2.0 SPS 05, а 0.161.1_BF или более поздней версии SAPHanaSR.[A] Настройте global.ini на каждом узле кластера.
Если требования к перехватчику susChkSrv не выполнены, удалите весь
[ha_dr_provider_suschksrv]блок из следующих параметров. ПоведениеsusChkSrvможно настроить с помощьюaction_on_lostпараметра. Допустимые значения : [ignorekillfence|stop| | ].[ha_dr_provider_SAPHanaSR] provider = SAPHanaSR path = /usr/share/SAPHanaSR execution_order = 1 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR execution_order = 3 action_on_lost = fence [trace] ha_dr_saphanasr = infoЕсли указать путь параметра к расположению по умолчанию
/usr/share/SAPHanaSR, код перехватчика Python обновляется автоматически с помощью обновлений ОС или обновлений пакетов. HANA использует обновления кода перехватчика при следующем перезапуске. При необходимости можно/hana/shared/myHooksотделить обновления ОС от используемой версии перехватчика.[A] Кластеру требуется настройка sudoers на каждом узле кластера для <sap-sid>adm. В этом примере это достигается путем создания нового файла.
Выполните следующую команду от имени привилегированного пользователя. Замените <идентификатор безопасности> по нижнему регистру системного идентификатора SAP, <идентификатор> безопасности по верхнему регистру SAP и <siteA/B> с выбранными именами сайтов HANA.
cat << EOF > /etc/sudoers.d/20-saphana # Needed for SAPHanaSR and susChkSrv Python hooks Cmnd_Alias SOK_SITEA = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteA> -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEA = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteA> -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SOK_SITEB = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteB> -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEB = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteB> -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias HELPER_TAKEOVER = /usr/sbin/SAPHanaSR-hookHelper --sid=<SID> --case=checkTakeover Cmnd_Alias HELPER_FENCE = /usr/sbin/SAPHanaSR-hookHelper --sid=<SID> --case=fenceMe <sid>adm ALL=(ALL) NOPASSWD: SOK_SITEA, SFAIL_SITEA, SOK_SITEB, SFAIL_SITEB, HELPER_TAKEOVER, HELPER_FENCE EOF
Дополнительные сведения о реализации перехватчика репликации системы SAP HANA см. в разделе "Настройка поставщиков ha/DR HANA".
[A] Запустите SAP HANA на обоих узлах. Выполните следующую команду как <sap-sid>adm:
sapcontrol -nr <instance number> -function StartSystem[1]: проверьте установку перехватчика. Выполните следующую команду как <sap-sid>adm на активном сайте репликации системы HANA:
cdtrace awk '/ha_dr_SAPHanaSR.*crm_attribute/ \ { printf "%s %s %s %s\n",$2,$3,$5,$16 }' nameserver_* # Example output # 2021-04-08 22:18:15.877583 ha_dr_SAPHanaSR SFAIL # 2021-04-08 22:18:46.531564 ha_dr_SAPHanaSR SFAIL # 2021-04-08 22:21:26.816573 ha_dr_SAPHanaSR SOK
- [1] Проверьте установку крюка susChkSrv.
Выполните следующую команду как <sap-sid>adm на виртуальных машинах HANA:
cdtrace egrep '(LOST:|STOP:|START:|DOWN:|init|load|fail)' nameserver_suschksrv.trc # Example output # 2022-11-03 18:06:21.116728 susChkSrv.init() version 0.7.7, parameter info: action_on_lost=fence stop_timeout=20 kill_signal=9 # 2022-11-03 18:06:27.613588 START: indexserver event looks like graceful tenant start # 2022-11-03 18:07:56.143766 START: indexserver event looks like graceful tenant start (indexserver started)
Создание ресурсов кластера SAP HANA
- [1] Сначала создайте ресурс топологии HANA.
Выполните следующие команды на любом из узлов кластера Pacemaker.
sudo crm configure property maintenance-mode=true
# Replace <placeholders> with your instance number and HANA system ID
sudo crm configure primitive rsc_SAPHanaTopology_<HANA SID>_HDB<instance number> ocf:suse:SAPHanaTopology \
operations \$id="rsc_sap2_<HANA SID>_HDB<instance number>-operations" \
op monitor interval="10" timeout="600" \
op start interval="0" timeout="600" \
op stop interval="0" timeout="300" \
params SID="<HANA SID>" InstanceNumber="<instance number>"
sudo crm configure clone cln_SAPHanaTopology_<HANA SID>_HDB<instance number> rsc_SAPHanaTopology_<HANA SID>_HDB<instance number> \
meta clone-node-max="1" target-role="Started" interleave="true"
- [1] Далее создайте ресурсы HANA:
Примечание.
В этой статье содержатся ссылки на термины, которые корпорация Майкрософт больше не использует. Когда эти термины будут удалены из программных продуктов, мы удалим их и из этой статьи.
# Replace <placeholders> with your instance number and HANA system ID.
sudo crm configure primitive rsc_SAPHana_<HANA SID>_HDB<instance number> ocf:suse:SAPHana \
operations \$id="rsc_sap_<HANA SID>_HDB<instance number>-operations" \
op start interval="0" timeout="3600" \
op stop interval="0" timeout="3600" \
op promote interval="0" timeout="3600" \
op monitor interval="60" role="Master" timeout="700" \
op monitor interval="61" role="Slave" timeout="700" \
params SID="<HANA SID>" InstanceNumber="<instance number>" PREFER_SITE_TAKEOVER="true" \
DUPLICATE_PRIMARY_TIMEOUT="7200" AUTOMATED_REGISTER="false"
# Run the following command if the cluster nodes are running on SLES 12 SP05.
sudo crm configure ms msl_SAPHana_<HANA SID>_HDB<instance number> rsc_SAPHana_<HANA SID>_HDB<instance number> \
meta notify="true" clone-max="2" clone-node-max="1" \
target-role="Started" interleave="true"
# Run the following command if the cluster nodes are running on SLES 15 SP03 or later.
sudo crm configure clone msl_SAPHana_<HANA SID>_HDB<instance number> rsc_SAPHana_<HANA SID>_HDB<instance number> \
meta notify="true" clone-max="2" clone-node-max="1" \
target-role="Started" interleave="true" promotable="true"
sudo crm resource meta msl_SAPHana_<HANA SID>_HDB<instance number> set priority 100
- [1] Продолжайте использовать ресурсы кластера для виртуальных IP-адресов, значений по умолчанию и ограничений.
# Replace <placeholders> with your instance number, HANA system ID, and the front-end IP address of the Azure load balancer.
sudo crm configure primitive rsc_ip_<HANA SID>_HDB<instance number> ocf:heartbeat:IPaddr2 \
meta target-role="Started" \
operations \$id="rsc_ip_<HANA SID>_HDB<instance number>-operations" \
op monitor interval="10s" timeout="20s" \
params ip="<front-end IP address>"
sudo crm configure primitive rsc_nc_<HANA SID>_HDB<instance number> azure-lb port=625<instance number> \
op monitor timeout=20s interval=10 \
meta resource-stickiness=0
sudo crm configure group g_ip_<HANA SID>_HDB<instance number> rsc_ip_<HANA SID>_HDB<instance number> rsc_nc_<HANA SID>_HDB<instance number>
sudo crm configure colocation col_saphana_ip_<HANA SID>_HDB<instance number> 4000: g_ip_<HANA SID>_HDB<instance number>:Started \
msl_SAPHana_<HANA SID>_HDB<instance number>:Master
sudo crm configure order ord_SAPHana_<HANA SID>_HDB<instance number> Optional: cln_SAPHanaTopology_<HANA SID>_HDB<instance number> \
msl_SAPHana_<HANA SID>_HDB<instance number>
# Clean up the HANA resources. The HANA resources might have failed because of a known issue.
sudo crm resource cleanup rsc_SAPHana_<HANA SID>_HDB<instance number>
sudo crm configure property priority-fencing-delay=30
sudo crm configure property maintenance-mode=false
sudo crm configure rsc_defaults resource-stickiness=1000
sudo crm configure rsc_defaults migration-threshold=5000
Внимание
Рекомендуется установить AUTOMATED_REGISTER значение false только во время завершения тщательных тестов отработки отказа, чтобы предотвратить автоматическую регистрацию первичного экземпляра в качестве дополнительного экземпляра. После успешного завершения тестов отработки отказа установите значение AUTOMATED_REGISTER true, чтобы после перехода репликация системы автоматически возобновлялась.
Убедитесь, что состояние кластера и OK все ресурсы запущены. Это не имеет значения, на каком узле работают ресурсы.
sudo crm_mon -r
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full list of resources:
#
# stonith-sbd (stonith:external/sbd): Started hn1-db-0
# Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_HDB03
# rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0
Настройка репликации системы с поддержкой HANA в кластере Pacemaker
В SAP HANA 2.0 SPS 01 и более поздних версиях SAP позволяет настроить активную или чтение для репликации системы SAP HANA. В этом сценарии вторичные системы репликации системы SAP HANA можно активно использовать для рабочих нагрузок с интенсивным чтением.
Для поддержки этой настройки в кластере требуется второй виртуальный IP-адрес, чтобы клиенты могли получить доступ к базе данных SAP HANA с поддержкой дополнительного чтения. Чтобы обеспечить доступ к вторичному сайту репликации после перехода, кластеру необходимо переместить виртуальный IP-адрес вокруг вторичного ресурса SAPHana.
В этом разделе описаны дополнительные шаги, необходимые для управления HANA активной и считываемой системой репликации в кластере высокой доступности SUSE, использующего второй виртуальный IP-адрес.
Прежде чем продолжить, убедитесь, что вы полностью настроили кластер SUSE с высоким уровнем доступности, который управляет базой данных SAP HANA, как описано в предыдущих разделах.
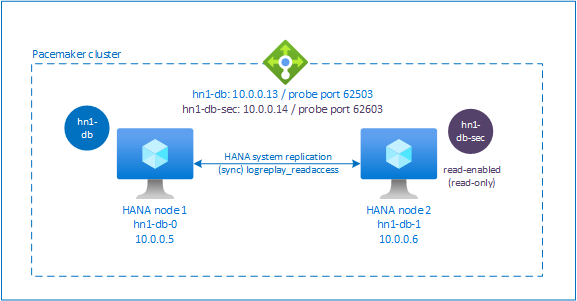
Настройка подсистемы балансировки нагрузки для активной и с поддержкой чтения системной репликации
Чтобы выполнить дополнительные действия по подготовке второго виртуального IP-адреса, убедитесь, что вы настроили Azure Load Balancer, как описано в разделе "Развертывание виртуальных машин Linux вручную с помощью портал Azure".
Для стандартной подсистемы балансировки нагрузки выполните эти дополнительные действия в той же подсистеме балансировки нагрузки, которую вы создали ранее.
- Создайте второй интерфейсный пул IP-адресов:
- Откройте подсистему балансировки нагрузки, выберите пул интерфейсных IP-адресов и щелкните Добавить.
- Введите имя нового пула интерфейсных IP-адресов (например, hana-frontend).
- Для параметра Назначение выберите значение Статическое и введите IP-адрес (например, 10.0.0.14).
- Нажмите ОК.
- После создания нового внешнего пула IP-адресов обратите внимание на внешний IP-адрес.
- Создайте пробу работоспособности:
- В подсистеме балансировки нагрузки выберите пробы работоспособности и нажмите кнопку "Добавить".
- Введите имя нового зонда работоспособности (например, hana-secondaryhp).
- Выберите TCP в качестве протокола и номера экземпляра> порта 626<. Сохраните значение Интервала, равное 5, а пороговое значение неработоспособного значения — 2.
- Нажмите ОК.
- Создайте правила балансировки нагрузки:
- В подсистеме балансировки нагрузки выберите правила балансировки нагрузки и нажмите кнопку "Добавить".
- Введите имя нового правила балансировки нагрузки (например, hana-secondarylb).
- Выберите интерфейсный пул IP-адресов, серверный пул и зонд работоспособности, который вы создали ранее (например, hana-secondaryIP, hana-backend и hana-secondaryhp).
- Выберите Порты высокой доступности.
- Увеличьте время ожидания простоя до 30 минут.
- Убедитесь, что вы включите плавающий IP-адрес.
- Нажмите ОК.
Настройка репликации системы с поддержкой HANA active/read
Действия по настройке репликации системы HANA описаны в разделе "Настройка репликации системы SAP HANA 2.0". Если вы развертываете дополнительный сценарий с поддержкой чтения, при настройке системной репликации на втором узле выполните следующую команду как <adm sid>HANA:
sapcontrol -nr <instance number> -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> --operationMode=logreplay_readaccess
Добавление ресурса вторичного виртуального IP-адреса
Вы можете настроить второй виртуальный IP-адрес и соответствующее ограничение совместного размещения с помощью следующих команд:
crm configure property maintenance-mode=true
crm configure primitive rsc_secip_<HANA SID>_HDB<instance number> ocf:heartbeat:IPaddr2 \
meta target-role="Started" \
operations \$id="rsc_secip_<HANA SID>_HDB<instance number>-operations" \
op monitor interval="10s" timeout="20s" \
params ip="<secondary IP address>"
crm configure primitive rsc_secnc_<HANA SID>_HDB<instance number> azure-lb port=626<instance number> \
op monitor timeout=20s interval=10 \
meta resource-stickiness=0
crm configure group g_secip_<HANA SID>_HDB<instance number> rsc_secip_<HANA SID>_HDB<instance number> rsc_secnc_<HANA SID>_HDB<instance number>
crm configure colocation col_saphana_secip_<HANA SID>_HDB<instance number> 4000: g_secip_<HANA SID>_HDB<instance number>:Started \
msl_SAPHana_<HANA SID>_HDB<instance number>:Slave
crm configure property maintenance-mode=false
Убедитесь, что состояние кластера и OK все ресурсы запущены. Второй виртуальный IP-адрес выполняется на вторичном сайте вместе со вторичным ресурсом SAPHana.
sudo crm_mon -r
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full list of resources:
#
# stonith-sbd (stonith:external/sbd): Started hn1-db-0
# Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_HDB03
# rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0
# Resource Group: g_secip_HN1_HDB03:
# rsc_secip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
# rsc_secnc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
В следующем разделе описывается типичный набор тестов отработки отказа для выполнения.
Рекомендации при тестировании кластера HANA, настроенного с поддержкой чтения, дополнительного:
При переносе ресурса
hn1-db-1кластера на второй виртуальныйSAPHana_<HANA SID>_HDB<instance number>IP-адрес переходит вhn1-db-0. Если вы настроилиAUTOMATED_REGISTER="false"и HANA системная репликация не зарегистрирована автоматически, второй виртуальный IP-адрес выполняетсяhn1-db-0на сервере, так как сервер доступен и службы кластеров находятся в сети.При проверке сбоя сервера второй виртуальный IP-ресурс (
rsc_secip_<HANA SID>_HDB<instance number>) и ресурсrsc_secnc_<HANA SID>_HDB<instance number>порта подсистемы балансировки нагрузки Azure выполняются на основном сервере вместе с основными виртуальными IP-ресурсами. Пока сервер-получатель отключен, приложения, подключенные к базе данных HANA с поддержкой чтения, подключаются к базе данных-источнику HANA. Это поведение ожидается, так как вы не хотите, чтобы приложения, подключенные к базе данных HANA с поддержкой чтения, были недоступны, пока сервер-получатель недоступен.Если сервер-получатель доступен и службы кластера находятся в сети, второй виртуальный IP-адрес и портовые ресурсы автоматически перемещаются на дополнительный сервер, даже если репликация системы HANA не может быть зарегистрирована как вторичная. Перед запуском служб кластеров на этом сервере необходимо зарегистрировать базу данных-получатель HANA как включенную для чтения. Вы можете настроить ресурс кластера экземпляра HANA, чтобы автоматически зарегистрировать вторичный, задав параметр
AUTOMATED_REGISTER="true".Во время отработки отказа и восстановления существующие подключения для приложений, которые затем используют второй виртуальный IP-адрес для подключения к базе данных HANA, могут быть прерваны.
Проверка настройки кластера
В этом разделе описано, как проверить настроенную систему. Каждый тест предполагает, что вы вошли в систему в качестве корневого каталога и что главный сервер SAP HANA выполняется на виртуальной hn1-db-0 машине.
Проверка миграции
Прежде чем начать тест, убедитесь, что Pacemaker не имеет никаких неудачных действий (запускcrm_mon -r), что не существует непредвиденных ограничений расположения (например, оставшиеся элементы теста миграции), и что HANA находится в состоянии синхронизации, например путем выполнения.SAPHanaSR-showAttr
hn1-db-0:~ # SAPHanaSR-showAttr
Sites srHook
----------------
SITE2 SOK
Global cib-time
--------------------------------
global Mon Aug 13 11:26:04 2018
Hosts clone_state lpa_hn1_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
hn1-db-0 PROMOTED 1534159564 online logreplay nws-hana-vm-1 4:P:master1:master:worker:master 150 SITE1 sync PRIM 2.00.030.00.1522209842 nws-hana-vm-0
hn1-db-1 DEMOTED 30 online logreplay nws-hana-vm-0 4:S:master1:master:worker:master 100 SITE2 sync SOK 2.00.030.00.1522209842 nws-hana-vm-1
Чтобы перенести главный узел SAP HANA, выполните следующую команду:
crm resource move msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1 force
Кластер перенесите главный узел SAP HANA и группу, содержащую виртуальный IP-адрес hn1-db-1.
После завершения crm_mon -r миграции выходные данные выглядят следующим образом:
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Stopped: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
Failed Actions:
* rsc_SAPHana_HN1_HDB03_start_0 on hn1-db-0 'not running' (7): call=84, status=complete, exitreason='none',
last-rc-change='Mon Aug 13 11:31:37 2018', queued=0ms, exec=2095ms
При этом AUTOMATED_REGISTER="false"кластер не перезагрузит сбой базы данных HANA или зарегистрирует его в новой первичной базе hn1-db-0данных. В этом случае настройте экземпляр HANA в качестве дополнительного, выполнив следующую команду:
su - <hana sid>adm
# Stop the HANA instance, just in case it is running
hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> sapcontrol -nr <instance number> -function StopWait 600 10
hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1>
При миграции создаются дополнительные ограничения расположения, которые следует удалить:
# Switch back to root and clean up the failed state
exit
hn1-db-0:~ # crm resource clear msl_SAPHana_<HANA SID>_HDB<instance number>
Очистите также состояние ресурса на вторичном узле:
hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0
Отслеживайте состояние ресурса HANA с помощью crm_mon -r. При запуске hn1-db-0HANA выходные данные выглядят следующим образом:
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
Блокировка сетевого взаимодействия
Состояние ресурсов перед запуском теста:
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
Выполните правило брандмауэра, чтобы заблокировать обмен данными на одном из узлов.
# Execute iptable rule on hn1-db-1 (10.0.0.6) to block the incoming and outgoing traffic to hn1-db-0 (10.0.0.5)
iptables -A INPUT -s 10.0.0.5 -j DROP; iptables -A OUTPUT -d 10.0.0.5 -j DROP
Если узлы кластера не могут взаимодействовать друг с другом, существует риск сценария разделения мозга. В таких ситуациях узлы кластера будут пытаться одновременно заборить друг друга, что приведет к гонке забора.
При настройке устройства ограждения рекомендуется настроить pcmk_delay_max свойство. Таким образом, в случае сценария разбиения мозга кластер вводит случайную задержку до pcmk_delay_max значения, в действие ограждения на каждом узле. Узел с самой короткой задержкой будет выбран для ограждения.
Кроме того, чтобы узел, на котором работает главный HANA, принимает приоритет и выигрывает гонку забора в сценарии разделения мозга, рекомендуется задать priority-fencing-delay свойство в конфигурации кластера. Включив свойство priority-fencing-delay, кластер может ввести дополнительную задержку в действии ограждения специально на главном ресурсе HANA узла, что позволяет узлу выиграть гонку забора.
Выполните следующую команду, чтобы удалить правило брандмауэра.
# If the iptables rule set on the server gets reset after a reboot, the rules will be cleared out. In case they have not been reset, please proceed to remove the iptables rule using the following command.
iptables -D INPUT -s 10.0.0.5 -j DROP; iptables -D OUTPUT -d 10.0.0.5 -j DROP
Проверка ограждения SBD
Вы можете проверить настройку SBD, убив процесс инквизитора:
hn1-db-0:~ # ps aux | grep sbd
root 1912 0.0 0.0 85420 11740 ? SL 12:25 0:00 sbd: inquisitor
root 1929 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-360014056f268462316e4681b704a9f73 - slot: 0 - uuid: 7b862dba-e7f7-4800-92ed-f76a4e3978c8
root 1930 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-360014059bc9ea4e4bac4b18808299aaf - slot: 0 - uuid: 5813ee04-b75c-482e-805e-3b1e22ba16cd
root 1931 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-36001405b8dddd44eb3647908def6621c - slot: 0 - uuid: 986ed8f8-947d-4396-8aec-b933b75e904c
root 1932 0.0 0.0 90524 16656 ? SL 12:25 0:00 sbd: watcher: Pacemaker
root 1933 0.0 0.0 102708 28260 ? SL 12:25 0:00 sbd: watcher: Cluster
root 13877 0.0 0.0 9292 1572 pts/0 S+ 12:27 0:00 grep sbd
hn1-db-0:~ # kill -9 1912
Узел <HANA SID>-db-<database 1> кластера перезагружается. Служба Pacemaker может не перезапуститься. Убедитесь, что вы снова запустите его.
Тестирование отработки отказа вручную
Вы можете протестировать отработку отказа вручную, остановив службу Pacemaker на hn1-db-0 узле:
service pacemaker stop
После отработки отказа можно снова запустить эту службу. Если задано AUTOMATED_REGISTER="false", ресурс SAP HANA на hn1-db-0 узле не запускается как дополнительный.
В этом случае настройте экземпляр HANA в качестве дополнительного, выполнив следующую команду:
service pacemaker start
su - <hana sid>adm
# Stop the HANA instance, just in case it is running
sapcontrol -nr <instance number> -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1>
# Switch back to root and clean up the failed state
exit
crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0
Тесты SUSE
Внимание
Убедитесь, что выбранная ОС сертифицирована для SAP HANA на определенных типах виртуальных машин, которые планируется использовать. Вы можете искать типы виртуальных машин, сертифицированные SAP HANA, и их выпуски ОС на платформах IaaS, сертифицированных sap HANA. Убедитесь, что вы просматриваете сведения о типе виртуальной машины, который планируется использовать для получения полного списка выпусков ОС, поддерживаемых SAP HANA, для этого типа виртуальной машины.
Запустите все тестовые случаи, перечисленные в руководстве по оптимизированному для производительности SAP HANA SR сценария или руководстве по оптимизированному для производительности SAP HANA SR сценария в зависимости от вашего сценария. Вы можете найти руководства, перечисленные в SLES для рекомендаций SAP.
Описания следующих тестов взяты из руководства по системной репликации SAP HANA, оптимизированной для высокой производительности, на сервере SUSE Linux Enterprise Server for SAP Applications версии 12 с пакетом обновлений 1 (SP1). Для актуальной версии также ознакомьтесь с самим руководством. Всегда убедитесь, что HANA синхронизирована перед началом теста и убедитесь, что конфигурация Pacemaker правильна.
В следующих описаниях тестов предполагается PREFER_SITE_TAKEOVER="true" и AUTOMATED_REGISTER="false".
Примечание.
Следующие тесты предназначены для выполнения в последовательности. Каждый тест зависит от состояния выхода предыдущего теста.
Тест 1. Остановка базы данных-источника на узле 1.
Состояние ресурса перед началом теста:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Выполните следующие команды, как <hana sid>adm на
hn1-db-0узле:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> HDB stopPacemaker обнаруживает остановленный экземпляр HANA и выполняет отработку отказа на другой узел. После завершения отработки отказа экземпляр HANA на
hn1-db-0узле останавливается, так как Pacemaker не автоматически регистрирует узел в качестве дополнительного объекта HANA.Выполните следующие команды, чтобы зарегистрировать узел в качестве дополнительного
hn1-db-0и очистить ресурс сбоем:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0Состояние ресурса после теста:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Тест 2. Остановка базы данных-источника на узле 2.
Состояние ресурса перед началом теста:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Выполните следующие команды, как <hana sid>adm на
hn1-db-1узле:hn1adm@hn1-db-1:/usr/sap/HN1/HDB01> HDB stopPacemaker обнаруживает остановленный экземпляр HANA и выполняет отработку отказа на другой узел. После завершения отработки отказа экземпляр HANA на
hn1-db-1узле останавливается, так как Pacemaker не автоматически регистрирует узел в качестве дополнительного объекта HANA.Выполните следующие команды, чтобы зарегистрировать узел в качестве дополнительного
hn1-db-1и очистить ресурс сбоем:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Состояние ресурса после теста:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Тест 3. Сбой базы данных-источника на узле 1.
Состояние ресурса перед началом теста:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Выполните следующие команды, как <hana sid>adm на
hn1-db-0узле:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> HDB kill-9Pacemaker обнаруживает убитый экземпляр HANA и выполняет отработку отказа на другой узел. После завершения отработки отказа экземпляр HANA на
hn1-db-0узле останавливается, так как Pacemaker не автоматически регистрирует узел в качестве дополнительного объекта HANA.Выполните следующие команды, чтобы зарегистрировать узел в качестве дополнительного
hn1-db-0и очистить ресурс сбоем:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0Состояние ресурса после теста:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Тест 4. Сбой базы данных-источника на узле 2.
Состояние ресурса перед началом теста:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Выполните следующие команды, как <hana sid>adm на
hn1-db-1узле:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB kill-9Pacemaker обнаруживает убитый экземпляр HANA и выполняет отработку отказа на другой узел. После завершения отработки отказа экземпляр HANA на
hn1-db-1узле останавливается, так как Pacemaker не автоматически регистрирует узел в качестве дополнительного объекта HANA.Выполните следующие команды, чтобы зарегистрировать узел в качестве дополнительного
hn1-db-1и очистить ресурс сбоем.hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Состояние ресурса после теста:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Тест 5. Сбой первичного узла сайта (узел 1).
Состояние ресурса перед началом теста:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Выполните следующие команды в качестве корневого
hn1-db-0каталога на узле:hn1-db-0:~ # echo 'b' > /proc/sysrq-triggerPacemaker обнаруживает убитый узел кластера и заборирует узел. Когда узел заборен, Pacemaker активирует переход экземпляра HANA. Когда заборированный узел перезагружается, Pacemaker не запускается автоматически.
Выполните следующие команды, чтобы запустить Pacemaker, очистить сообщения SBD для узла, зарегистрировать
hn1-db-0узел в качестве дополнительногоhn1-db-0и очистить неудачный ресурс:# run as root # list the SBD device(s) hn1-db-0:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-0:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-0 clear hn1-db-0:~ # systemctl start pacemaker # run as <hana sid>adm hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0Состояние ресурса после теста:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Тест 6. Сбой вторичного узла сайта (узел 2).
Состояние ресурса перед началом теста:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Выполните следующие команды в качестве корневого
hn1-db-1каталога на узле:hn1-db-1:~ # echo 'b' > /proc/sysrq-triggerPacemaker обнаруживает убитый узел кластера и заборирует узел. Когда узел заборен, Pacemaker активирует переход экземпляра HANA. Когда заборированный узел перезагружается, Pacemaker не запускается автоматически.
Выполните следующие команды, чтобы запустить Pacemaker, очистить сообщения SBD для узла, зарегистрировать
hn1-db-1узел в качестве дополнительногоhn1-db-1и очистить неудачный ресурс:# run as root # list the SBD device(s) hn1-db-1:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-1:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-1 clear hn1-db-1:~ # systemctl start pacemaker # run as <hana sid>adm hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Состояние ресурса после теста:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0 </code></pre>Тест 7. Остановите базу данных-получатель на узле 2.
Состояние ресурса перед началом теста:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Выполните следующие команды, как <hana sid>adm на
hn1-db-1узле:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB stopPacemaker обнаруживает остановленный экземпляр HANA и помечает ресурс как неудачный на
hn1-db-1узле. Pacemaker автоматически перезапускает экземпляр HANA.Выполните следующую команду, чтобы очистить состояние сбоя:
# run as root hn1-db-1>:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Состояние ресурса после теста:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Тест 8. Сбой базы данных-получателя на узле 2.
Состояние ресурса перед началом теста:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Выполните следующие команды, как <hana sid>adm на
hn1-db-1узле:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB kill-9Pacemaker обнаруживает убитый экземпляр HANA и помечает ресурс как неудачный на
hn1-db-1узле. Выполните следующую команду, чтобы очистить состояние сбоя. Pacemaker автоматически перезапускает экземпляр HANA.# run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> HN1-db-1Состояние ресурса после теста:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Тест 9. Сбой узла вторичного сайта (узел 2), на котором выполняется база данных-получатель HANA.
Состояние ресурса перед началом теста:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Выполните следующие команды в качестве корневого
hn1-db-1каталога на узле:hn1-db-1:~ # echo b > /proc/sysrq-triggerPacemaker обнаруживает убитый узел кластера и заборил узел. Когда заборированный узел перезагружается, Pacemaker не запускается автоматически.
Выполните следующие команды, чтобы запустить Pacemaker, очистить сообщения SBD для
hn1-db-1узла и очистить неудачный ресурс:# run as root # list the SBD device(s) hn1-db-1:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-1:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-1 clear hn1-db-1:~ # systemctl start pacemaker hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Состояние ресурса после теста:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Тест 10. Аварийное завершение сервера индексов базы данных-источника
Этот тест относится только к настройке перехватчика susChkSrv, как описано в разделе "Реализация агентов ресурсов HANA".
Состояние ресурса перед началом теста:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Выполните следующие команды в качестве корневого
hn1-db-0каталога на узле:hn1-db-0:~ # killall -9 hdbindexserverПосле завершения indexserver перехватчик susChkSrv обнаруживает событие и активирует действие для ограждения узла hn1-db-0 и инициирует процесс перебора.
Выполните следующие команды, чтобы зарегистрировать
hn1-db-0узел в качестве дополнительного и очистить неудачный ресурс:# run as <hana sid>adm hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0Состояние ресурса после теста:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Вы можете выполнить сопоставимый тестовый случай, вызвав сбой индексасервера на вторичном узле. В случае сбоя indexserver перехватчик susChkSrv распознает вхождение и инициирует действие для ограждения вторичного узла.