Руководство. Исправление набора навыков с помощью сеансов отладки
В службе "Поиск ИИ Azure" набор навыков координирует действия навыков, которые анализируют, преобразуют или создают содержимое, которое можно найти. Часто выходные данные одного навыка становятся входными данными другого. Если входные данные зависят от выходных, ошибки в определениях набора навыков и связываниях полей могут привести к отсутствию операций и данных.
Сеансы отладки — это средство портал Azure, которое обеспечивает целостную визуализацию набора навыков, выполняемого в службе "Поиск ИИ Azure". С помощью этого средства вы можете перейти к определенным шагам и определить, где возникает ошибка.
В этой статье используйте сеансы отладки для поиска и исправления отсутствующих входных и выходных данных. Это руководство включает все необходимое для работы. Он предоставляет примеры данных, REST-файл, который создает объекты и инструкции по отладке проблем в наборе навыков.
Если у вас нет подписки Azure, создайте бесплатную учетную запись, прежде чем приступить к работе.
Необходимые компоненты
Поиск по искусственному интеллекту Azure. Создайте службу или найдите имеющуюся службу в рамках текущей подписки. Вы можете использовать бесплатную службу для выполнения инструкций, описанных в этом учебнике. Бесплатный уровень не предоставляет поддержку управляемых удостоверений для служба Azure AI. Необходимо использовать ключи для подключений к служба хранилища Azure.
учетная запись служба хранилища Azure с Хранилище BLOB-объектов, используемое для размещения примеров данных, а также для сохранения кэшированных данных, созданных во время сеанса отладки. Если вы используете бесплатную службу поиска, учетная запись хранения должна иметь ключи общего доступа и разрешить доступ к общедоступной сети.
Visual Studio Code с клиентом REST.
Пример файла debug-session.rest, используемого для создания конвейера обогащения.
Примечание.
В этом руководстве также используются службы ИИ Azure для обнаружения языка, распознавания сущностей и извлечения ключевых фраз. Так как рабочая нагрузка настолько мала, службы ИИ Azure касаются за кулисами для бесплатной обработки до 20 транзакций. Это означает, что вы можете выполнить это упражнение, не создавая оплачиваемый ресурс служб ИИ Azure.
Настройка примеров данных
С помощью инструкций из этого раздела вы создадите пример набора данных в Хранилище BLOB-объектов Azure, с которыми будут работать индексатор и набор навыков.
Скачайте пример данных (clinical-trials-pdf-19), состоящий из 19 файлов.
Создайте учетную запись хранения Azure или найдите имеющуюся учетную запись.
Выберите тот же регион, что и поиск ВИ Azure, чтобы избежать расходов на пропускную способность.
Выберите тип учетной записи StorageV2 (общего назначения версии 2).
Перейдите к страницам служб хранилища Azure на портале и создайте контейнер больших двоичных объектов. Рекомендуется указать уровень доступа "частный". Присвойте контейнеру имя
clinicaltrialdataset.В контейнере выберите "Отправить ", чтобы отправить скачанные и распакованные примеры файлов на первом шаге.
Во время на портале скопируйте строка подключения для служба хранилища Azure. Вы можете получить строку подключения, выбрав Параметры>Ключи доступа на портале.
Копирование ключа и URL-адреса
В этом руководстве используются ключи API для проверки подлинности и авторизации. Вам нужна конечная точка службы поиска и ключ API, который можно получить из портал Azure.
Войдите в портал Azure, перейдите на страницу обзора и скопируйте URL-адрес. Пример конечной точки может выглядеть так:
https://mydemo.search.windows.net.В разделе "Ключи>параметров" скопируйте ключ администратора. Ключи администратора используются для добавления, изменения и удаления объектов. Существует два взаимозаменяемых ключа администратора. Скопируйте любой из них.
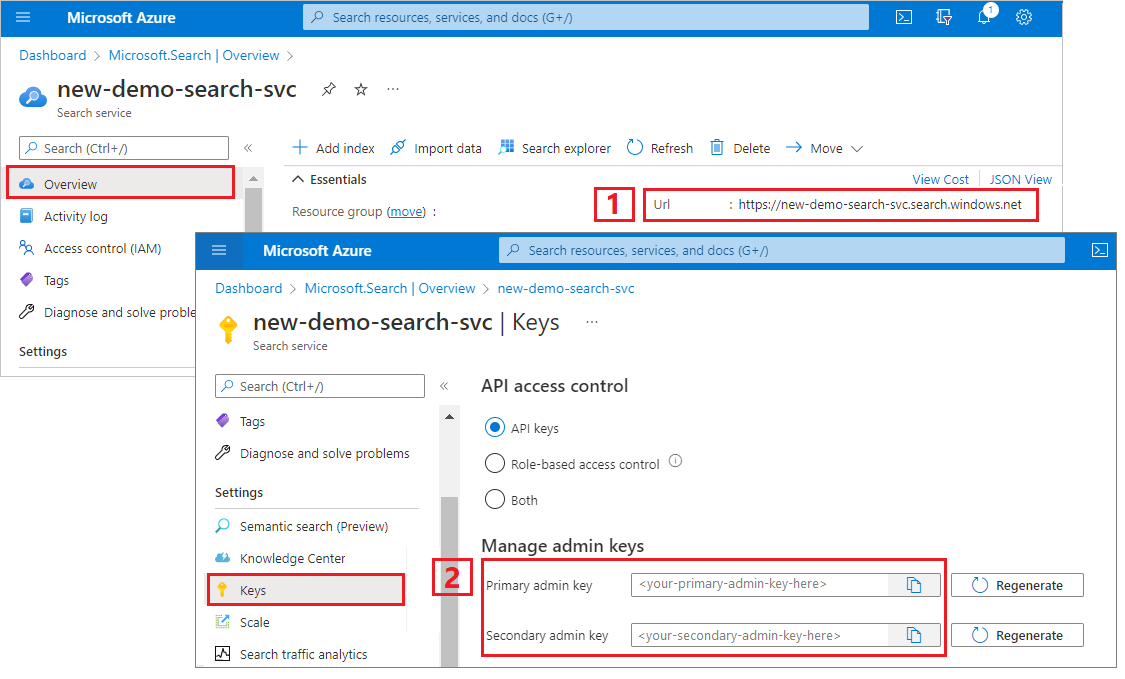
Допустимый ключ API устанавливает доверие на основе каждого запроса между приложением, отправляя запрос и службу поиска, обрабатывая ее.
Создание источника данных, набора навыков, индекса и индексатора
В этом разделе описано, как создать рабочий процесс buggy, который можно исправить в этом руководстве.
Запустите Visual Studio Code и откройте
debug-sessions.restфайл.Укажите следующие переменные: URL-адрес службы поиска, ключ API администрирования служб поиска, строка подключения хранилища и имя контейнера BLOB-объектов, в котором хранятся PDF-файлы.
Отправьте каждый запрос в свою очередь. Создание индексатора занимает несколько минут.
Закройте файл.
Просмотр результатов на портале
Пример кода специально создает индекс с ошибками, как следствие проблем, возникших во время выполнения набора навыков. Проблема заключается в том, что индекс отсутствует данные.
В портал Azure на странице обзора службы поиска выберите вкладку "Индексы".
Выберите клинические испытания.
Введите эту строку запроса JSON в представлении JSON обозревателя поиска. Он возвращает поля для определенных документов (идентифицируется уникальным
metadata_storage_pathполем)."search": "*", "select": "metadata_storage_path, organizations, locations", "count": trueВыполните запрос. Вы должны увидеть пустые значения для
organizationsиlocations.Эти поля должны быть заполнены с помощью навыка распознавания сущностей набора навыков, используемого для обнаружения организаций и расположений в любом месте содержимого большого двоичного объекта. В следующем упражнении вы отладите набор навыков, чтобы определить, что пошло не так.
Ошибки и предупреждения также можно изучить на портале Azure.
Откройте вкладку Индексаторов и выберите клинические испытания-idxr.
Обратите внимание, что в то время как задание индексатора успешно выполнено в целом, были предупреждения.
Выберите "Успех" , чтобы просмотреть предупреждения (если в основном произошли ошибки, ссылка на сведения будет выполнена сбоем). Вы увидите длинный список с каждым предупреждением, выданным индексатором.

Запуск сеанса отладки
В области навигации слева от службы поиска в разделе "Управление поиском" выберите сеансы отладки.
Выберите и добавьте сеанс отладки.
Присвойте сеансу имя.
В шаблоне индексатора укажите имя индексатора. Индексатор содержит ссылки на источник данных, набор навыков и индекс.
Выберите учетную запись хранилища.
Сохраните сеанс.

Сеанс отладки открывается на странице параметров. Вы можете внести изменения в начальную конфигурацию и переопределить все значения по умолчанию. Сеанс отладки работает только с одним документом. По умолчанию необходимо принять первый документ в коллекции в качестве основы сеансов отладки. Вы можете выбрать определенный документ для отладки, предоставив URI в служба хранилища Azure.
После завершения инициализации сеанса отладки необходимо увидеть рабочий процесс навыков с сопоставлениями и индексом поиска. Обогащенная структура данных документа отображается в области сведений на стороне. Мы исключили его из следующего снимка экрана, чтобы увидеть больше рабочего процесса.



Поиск проблем с набором навыков
Все проблемы, сообщаемые индексатором, указываются как ошибки и предупреждения.
Обратите внимание, что количество ошибок и предупреждений гораздо меньше списка, чем отображаемое ранее, так как этот список содержит только подробные сведения об ошибках для одного документа. Как и список, отображаемый индексатором, можно выбрать предупреждение и просмотреть сведения об этом предупреждении.
Выберите предупреждения , чтобы просмотреть уведомления. Вы должны увидеть четыре:
"Не удалось выполнить навык, так как один или несколько входных данных навыка были недопустимыми. Отсутствуют необходимые входные данные навыка. Имя: "text", источник: "/document/content".
Could not map output field 'locations' to search index. Could not map output field 'locations' to search index. Missing value '/document/merged_content/locations'. (Не удалось сопоставить поле выходных данных organizations с индексом поиска. Проверьте свойство outputFieldMappings индексатора. Отсутствует значение /document/merged_content/locations.)
Could not map output field 'organizations' to search index. Check the 'outputFieldMappings' property of your indexer. Missing value '/document/merged_content/organizations'. (Не удалось сопоставить поле выходных данных organizations с индексом поиска. Проверьте свойство outputFieldMappings индексатора. Отсутствует значение /document/merged_content/organizations.)
"Навык выполнен, но может иметь непредвиденные результаты, так как один или несколько входных данных навыка были недопустимыми. (Навык выполнен, но может привести к непредвиденным результатам, так как некоторые входные данные навыка недопустимы. Отсутствуют дополнительные входные данные навыка. Имя: languageCode; источник: /document/languageCode. Проблемы синтаксического анализа языка выражений: отсутствующее значение "/document/languageCode".
Многие навыки имеют параметр languageCode. Проверив операцию, вы увидите, что входные данные кода языка отсутствуют из EntityRecognitionSkill.#1того же навыка распознавания сущностей, что имеет проблемы с выходными данными "расположения" и "организации".
Так как все четыре уведомления относятся к этому навыку, следующим шагом является отладка этого навыка. Если это возможно, сначала решить входные проблемы перед переходом к выходным проблемам.
Исправление отсутствующих значений входных навыков
На рабочей поверхности выберите навык, который сообщает предупреждения. В этом руководстве это навык распознавания сущностей.
Область сведений о навыке открывается справа с разделами для итерации и их соответствующих входных данных и выходных данных, параметров навыка для определения навыка и сообщений для любых ошибок и предупреждений, которые этот навык выдает.

Наведите указатель мыши на все входные данные (или выберите входные данные), чтобы отобразить значения в вычислителе выражений. Обратите внимание, что отображаемый результат для этого ввода не выглядит как текстовый ввод. Он выглядит как ряд новых символов
\n \n\n\n\nстроки вместо текста. Отсутствие текста означает, что сущности не могут быть идентифицированы, поэтому этот документ не может соответствовать предварительным требованиям навыка или есть еще один вход, который следует использовать вместо этого.
Вернитесь в структуру обогащенных данных и просмотрите узлы обогащения для этого документа. Обратите внимание, что
\n \n\n\n\nдля "содержимого" нет исходного источника, но другое значение для "merged_content" имеет выходные данные OCR. Хотя нет никаких признаков, содержимое этого PDF-файла, как представляется, jpeg-файл, как показано извлеченным и обработанным текстом в "merged_content".
Вернитесь к навыку и выберите параметры набора навыков, чтобы открыть определение JSON.
Измените выражение на
/document/content/document/merged_content, а затем нажмите кнопку "Сохранить". Обратите внимание, что предупреждение больше не указано.
Выберите "Запустить " в меню окна сеанса. Это запускает другое выполнение набора навыков с помощью документа.
После завершения выполнения сеанса отладки обратите внимание, что число предупреждений сократилось на один. Предупреждения показывают, что ошибка ввода текста исчезла, но остальные предупреждения остаются. Следующий шаг — адрес предупреждения о отсутствующих или пустых значениях
/document/languageCode.
Выберите навык и наведите указатель мыши
/document/languageCode. Значение для этого ввода равно NULL, которое не является допустимым входным.Как и в предыдущей проблеме, сначала просмотрите структуру обогащенных данных для подтверждения своих узлов. Обратите внимание, что нет узла languageCode, но есть один для языка. Поэтому в параметрах навыка есть опечатка.
Скопируйте выражение
/document/language.В области сведений о навыке выберите "Параметры навыка" для навыка #1 и вставьте новое значение
/document/language.Выберите Сохранить.
Выберите Выполнить.
После завершения выполнения сеанса отладки можно проверить результаты в области сведений о навыках. При наведении указателя мыши
/document/languageвы увидитеenзначение в вычислителе выражений.
Обратите внимание, что предупреждения о входных данных исчезли. Теперь остаются только два предупреждения о выходных полях для организаций и расположений.
Исправление ошибок из-за отсутствия выходного значения навыка
Сообщения говорят, чтобы проверить свойство outputFieldMappings индексатора, поэтому давайте начнем с этого.
Выберите сопоставления полей вывода на рабочей поверхности. Обратите внимание, что отсутствуют сопоставления выходных полей.

Сначала убедитесь, что индекс поиска имеет ожидаемые поля. В этом случае индекс содержит поля для "расположения" и "организации".
Если нет проблем с индексом, следующий шаг — проверить выходные данные навыка. Как и раньше, выберите структуру обогащенных данных и прокрутите узлы, чтобы найти "расположения" и "организации". Обратите внимание, что родительский элемент — "содержимое" вместо "merged_content". Контекст неправильный.
Переключитесь на панель сведений "Навыки" для навыка распознавания сущностей.
В параметрах навыка измените значение
contextdocument/merged_content. На этом этапе необходимо внести три изменения в определение навыка.
Выберите Сохранить.
Выберите Выполнить.
Все ошибки устранены.
Фиксация изменений в наборе навыков
При запуске сеанса отладки служба "Поиск" создала копию набора навыков. Это сделано для защиты исходного набора навыков в вашей службе поиска. Завершив отладку набора навыков, вы можете зафиксировать исправления (перезаписав исходный набор навыков).
Кроме того, если вы не готовы зафиксировать изменения, вы можете сохранить сеанс отладки и открыть его позже.
Выберите "Зафиксировать изменения" в главном меню сеансов отладки.
Нажмите кнопку "ОК ", чтобы подтвердить, что вы хотите обновить набор навыков.
Закройте сеанс отладки и откройте индексаторы из левой области навигации .
Выберите "клинические испытания-idxr".
Выберите Сброс.
Выберите Выполнить.
Выберите "Обновить" , чтобы отобразить состояние команд сброса и выполнения.
Когда индексатор завершит работу, должен быть зеленый флажок и слово Success рядом с меткой времени для последнего запуска на вкладке журнала выполнения. Чтобы убедиться, что изменения были применены:
В области навигации слева откройте индексы.
Выберите индекс "клинические испытания" и на вкладке обозревателя поиска введите эту строку запроса:
$select=metadata_storage_path, organizations, locations&$count=trueчтобы вернуть поля для определенных документов (идентифицируемых уникальнымmetadata_storage_pathполем).Нажмите Поиск.
В результатах должно быть указано, что сущности organizations и locations теперь заполнены ожидаемыми значениями.
Очистка ресурсов
Если вы работаете в собственной подписке, в конце проекта следует решить, нужны ли вам созданные ресурсы. Ресурсы, которые продолжат работать, могут быть платными. Вы можете удалить ресурсы по отдельности либо удалить всю группу ресурсов.
Просматривать ресурсы и управлять ими можно на портале с помощью ссылок Все ресурсы или Группы ресурсов на панели навигации слева.
Бесплатная служба ограничена тремя индексами, индексаторами и источниками данных. Вы можете удалить отдельные элементы на портале, чтобы не превысить лимит.
Следующие шаги
В этом руководстве рассмотрены разные аспекты, касающиеся определения набора навыков и его обработки. Чтобы узнать больше о понятиях и рабочих процессах, ознакомьтесь со следующими статьями: