Хранилище знаний в поиске ИИ Azure
Хранилище знаний — это дополнительное хранилище для содержимого, обогащенного ИИ, созданного набором навыков в поиске ИИ Azure. В Службе поиска искусственного интеллекта Azure задание индексирования всегда отправляет выходные данные в индекс поиска, но при присоединении набора навыков к индексатору можно также отправить данные, обогащенные ИИ, в контейнер или таблицу в служба хранилища Azure. Хранилище знаний можно использовать для независимого анализа или последующей обработки в сценариях, отличных от поиска, таких как интеллектуальный анализ знаний.
Два выходных данных индексирования, индекс поиска и хранилища знаний, являются взаимоисключающими продуктами одного конвейера. Они производны от одних входных данных и содержат одни и те же данные, но их содержимое структурировано, хранится и используется в разных приложениях.

Физически хранилищем знаний является служба хранилища Azure (хранилище таблиц Azure, хранилище BLOB-объектов Azure или оба). Любой инструмент или процесс, который может подключиться к службе хранилища Azure, может использовать содержимое хранилища знаний. В поиске ИИ Azure нет поддержки запросов для получения содержимого из хранилища знаний.
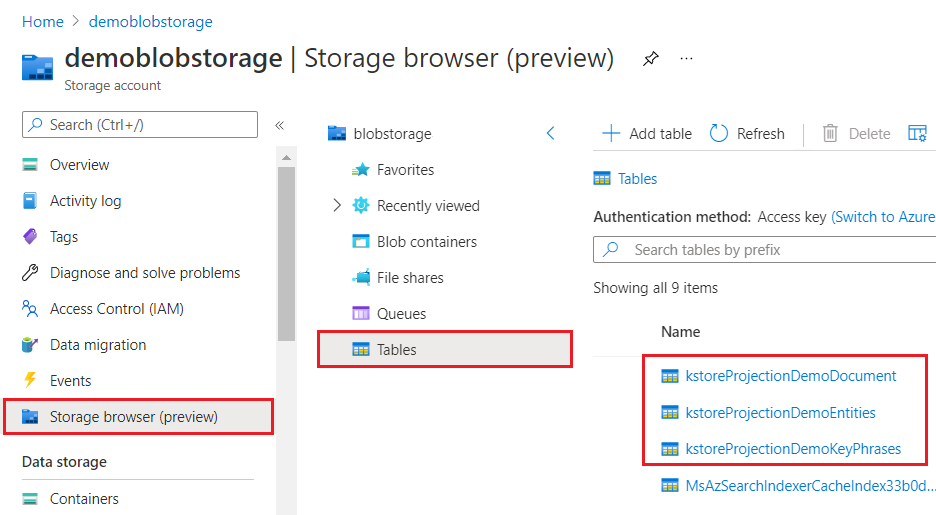
При просмотре с помощью портал Azure хранилище знаний выглядит как любая другая коллекция таблиц, объектов или файлов. На следующем снимка экрана показано хранилище знаний, состоящее из трех таблиц. Вы можете применить соглашение об именовании, например kstore префикс, чтобы сохранить содержимое вместе.
Преимущества хранилища знаний
Основными преимуществами хранилища знаний являются два раза: гибкий доступ к содержимому и возможность формировать данные.
В отличие от индекса поиска, доступ к которому можно получить только с помощью запросов в службе "Поиск ИИ Azure", хранилище знаний доступно любому инструменту, приложению или процессу, поддерживающим подключения к служба хранилища Azure. Эта гибкость открывает новые сценарии для использования проанализированного и обогащенного содержимого, созданного конвейером обогащения.
Тот же набор навыков, который дополняет данные, также можно использовать для формирования данных. Некоторые средства, такие как Power BI, лучше работают с таблицами, в то время как рабочая нагрузка обработки и анализа данных может потребовать сложной структуры данных в формате BLOB-объектов. Добавление навыка фигуры в набор навыков позволяет контролировать форму данных. Затем эти фигуры можно передать в проекции , таблицы или большие двоичные объекты, чтобы создать физические структуры данных, которые соответствуют предполагаемому использованию данных.
В следующем видео объясняется оба этих преимущества и многое другое.
Определение хранилища знаний
Хранилище знаний определяется в определении набора навыков и имеет два компонента:
Строка подключения для служба хранилища Azure
Проекции , определяющие, состоит ли хранилище знаний из таблиц, объектов или файлов. Элемент проекций — это массив. Можно создать несколько наборов сочетаний файлов табличного объекта в одном хранилище знаний.
"knowledgeStore": { "storageConnectionString":"<YOUR-AZURE-STORAGE-ACCOUNT-CONNECTION-STRING>", "projections":[ { "tables":[ ], "objects":[ ], "files":[ ] } ] }
Тип проекции, указанный в этой структуре, определяет тип хранилища, используемого хранилищем знаний, но не его структуру. Поля в таблицах, объектах и файлах определяются выходными данными навыка shaper, если вы создаете хранилище знаний программным способом или мастером импорта данных, если вы используете портал.
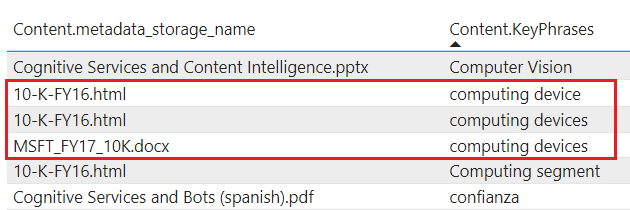
tablesпроецирует обогащенное содержимое в Хранилище таблиц. Определите проекцию таблицы, если вам нужны табличные структуры отчетов для входных данных средств аналитики или экспорта в виде кадров данных в другие хранилища данных. Можно указать несколько элементовtablesв одной группе проекции, чтобы получить некоторое подмножество или пересечение обогащенных документов. В одной группе проекции связи между таблицами сохраняются, чтобы можно было работать со всеми таблицами.Проецированное содержимое не агрегируется или нормализовано. На следующем снимке экрана показана таблица, отсортированная по ключевой фразе, с родительским документом, указанным в соседнем столбце. В отличие от приема данных во время индексирования, нет лингвистического анализа или агрегирования содержимого. Формы множественного числа и различия в регистре считаются уникальными экземплярами.
objectsпроецирует документ JSON в Хранилище BLOB-объектов. Физическое представлениеobject— это иерархическая структура JSON, которая представляет обогащенный документ.filesпроецирует файлы изображений в Хранилище BLOB-объектов.file— это изображение, извлеченное из документа, которое переносится в хранилище BLOB-объектов без изменений. Хотя он называется "files", он отображается в хранилище BLOB-объектов, а не в хранилище файлов.
Создание хранилища знаний
Чтобы создать хранилище знаний, используйте портал или API.
Вам потребуется служба хранилища Azure, набор навыков и индексатор. Так как индексаторы требуют индекса поиска, необходимо также указать определение индекса.
Перейдите к подходу портала к самому быстрому маршруту в готовое хранилище знаний. Кроме того, выберите REST API для более глубокого понимания того, как определены и связаны объекты.
Создайте простое хранилище знаний, выполнив четыре шага с использованием мастера импорта данных.
Определите источник данных, содержащий данные, которые нужно дополнить.
Определите набор навыков. Набор навыков задает шаги обогащения и хранилище знаний.
Определите схему индекса. Возможно, вам не потребуется один, но индексаторы требуют его. Мастер может выводить индекс.
Завершите работу мастера. На этом последнем шаге происходит извлечение, обогащение и создание хранилища знаний.
Мастер автоматизирует несколько задач. В частности, для вас создаются определения физических структур данных и проекции (определения физических структур данных в служба хранилища Azure).
Подключение с помощью приложений
После того как обогащенное содержимое существует в хранилище, любое средство или технология, подключающиеся к служба хранилища Azure, можно использовать для изучения, анализа или использования содержимого. Вот список основных таких средств:
Обозреватель службы хранилища или браузер хранилища в портал Azure для просмотра обогащенной структуры документа и содержимого. Его можно считать базовым средством для просмотра содержимого хранилища знаний.
Power BI для отчетов и анализа.
Фабрика данных Azure позволяет выполнять дальнейшую обработку данных.
Жизненный цикл содержимого
Хранилище знаний обновляется при каждом запуске индексатора и набора навыков, если есть изменения в наборе навыков или базовом источнике данных. Любые обнаруженные индексатором изменения передаются через процесс обогащения в проекции в хранилище знаний. Это гарантирует, что проецируемые данные являются актуальным представлением содержимого в источнике данных.
Примечание.
Вы можете изменять данные в проекциях, но такие изменения будут перезаписаны при следующем вызове конвейера, если изменится документ в исходных данных.
Изменения в исходных данных
Для источников данных, которые поддерживают отслеживание изменений, индексатор будет обрабатывать новые и измененные документы, пропуская существующие документы, которые уже были обработаны. Сведения о метке времени зависят от конкретного источника данных, например в контейнере больших двоичных объектов индексатор проверяет дату lastmodified, чтобы определить, какие большие двоичные объекты нужно принимать.
Изменения в наборе навыков
Если вы вносите изменения в набор навыков, необходимо включить кэширование обогащенных документов для повторного использования существующих обогащений, где это возможно.
Без добавочного кэширования индексатор всегда будет обрабатывать документы в порядке увеличения значений метки, не возвращаясь в обратную сторону. Например, индексатор будет обрабатывать большие двоичные объекты в порядке сортировки по lastModified, независимо от изменений параметров индексатора или набора навыков. Если вы измените набор навыков, ранее обработанные документы не будут обновляться с учетом нового набора навыков. Для документов, которые обрабатываются после изменения набора навыков, будет применяться новый набор навыков, а значит в документах индекса будут перемешаны результаты, полученные старым и новым наборами навыков.
При добавочном кэшировании в случае обновления набора навыков индексатор будет использовать любые сохраненные обогащения, которых не коснулось изменение набора навыков. Обогащения, которые выполняются до измененного навыка или вовсе с ним не связаны, извлекаются из кэша.
удаления
Хотя индексатор создает и обновляет структуры и содержимое в служба хранилища Azure, он не удаляет их. Проекции продолжат существовать даже в случае удаления индексатора или набора навыков. Как владелец учетной записи хранения, следует удалить проекцию, если она больше не нужна.
Следующие шаги
Хранилище знаний обеспечивает стойкость обогащенных документов, полезных при разработке набора навыков или создании структур и содержимого для использования любыми клиентскими приложениями, которые могут получить доступ к учетной записи службы хранилища Azure.
Самый простой подход к созданию обогащенных документов осуществляется на портале, но клиент REST и ИНТЕРФЕЙСы REST API могут получить более подробное представление о создании и использовании программной ссылки на объекты.