Руководство. Индексирование больших данных из Apache Spark с помощью SynapseML и поиска ИИ Azure
В этом руководстве по поиску ИИ Azure вы узнаете, как индексировать и запрашивать большие данные, загруженные из кластера Spark. Настройте Записную книжку Jupyter, которая выполняет следующие действия:
- Загрузка различных форм (счетов) в кадр данных в сеансе Apache Spark
- Анализ их для определения их функций
- Сбор результирующего вывода в табличную структуру данных
- Запись выходных данных в индекс поиска, размещенный в поиске ИИ Azure
- Изучение и запрос содержимого, созданного вами
В этом руководстве используется зависимость от SynapseML, библиотеки открытый код, которая поддерживает массовое параллельное машинное обучение по большим данным. В SynapseML индексирование поиска и машинное обучение предоставляются через преобразователи , выполняющие специализированные задачи. Преобразователи касались широкого спектра возможностей искусственного интеллекта. В этом упражнении используйте API AzureSearchWriter для анализа и обогащения ИИ.
Хотя служба поиска ИИ Azure имеет собственное обогащение ИИ, в этом руководстве показано, как получить доступ к возможностям ИИ за пределами службы "Поиск ИИ Azure". Используя SynapseML вместо индексаторов или навыков, вы не подвергаетесь ограничениям данных или другим ограничениям, связанным с этими объектами.
Совет
Просмотрите короткое видео этой демонстрации по адресу https://www.youtube.com/watch?v=iXnBLwp7f88. Видео расширяется в этом руководстве с дополнительными шагами и визуальными элементами.
Необходимые компоненты
Вам нужна synapseml библиотека и несколько ресурсов Azure. По возможности используйте ту же подписку и регион для ресурсов Azure и поместите все в одну группу ресурсов для простой очистки позже. Следующие ссылки предназначены для установки портала. Пример данных импортируется из общедоступного сайта.
- Пакет SynapseML 1
- Поиск ИИ Azure (любой уровень) 2
- Службы ИИ Azure (любой уровень) 3
- Azure Databricks (любой уровень) 4
1 Эта ссылка разрешается в учебник по загрузке пакета.
2 Вы можете использовать бесплатный уровень поиска для индексирования примеров данных, но выберите более высокий уровень , если объемы данных большие. Для платных уровней укажите ключ API поиска на шаге "Настройка зависимостей ".
3 В этом руководстве используется Аналитика документов Azure и Azure AI Translator. В приведенных ниже инструкциях укажите ключ с несколькими службами и регион. Один и тот же ключ работает для обеих служб.
4 В этом руководстве Azure Databricks предоставляет платформу вычислений Spark. Мы использовали инструкции портала для настройки рабочей области.
Примечание.
Все перечисленные выше ресурсы Azure поддерживают функции безопасности на платформе удостоверений Майкрософт. Для простоты в этом руководстве предполагается проверка подлинности на основе ключей с помощью конечных точек и ключей, скопированных на страницах портала каждой службы. Если вы реализуете этот рабочий процесс в рабочей среде или совместно используете решение с другими пользователями, не забудьте заменить жестко закодированные ключи интегрированными ключами безопасности или зашифрованными ключами.
Шаг 1. Создание кластера Spark и записной книжки
В этом разделе описано, как создать кластер, установить synapseml библиотеку и создать записную книжку для запуска кода.
В портал Azure найдите рабочую область Azure Databricks и выберите "Запустить рабочую область".
В меню слева выберите "Вычисления".
Выберите "Создать вычисления".
Примите конфигурацию по умолчанию. Создание кластера занимает несколько минут.
Установите библиотеку
synapsemlпосле создания кластера:Выберите библиотеки на вкладках в верхней части страницы кластера.
Нажмите кнопку "Установить новую".
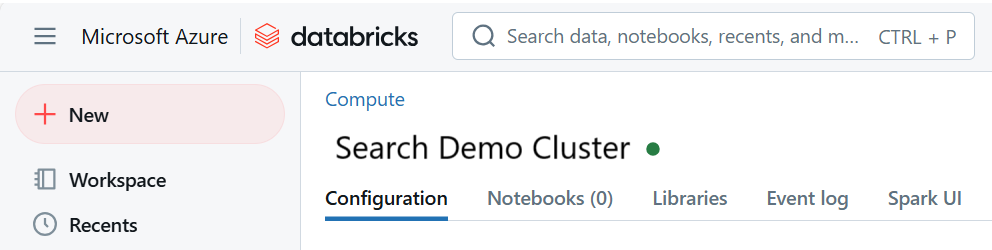
Выберите Maven.
В координатах введите
com.microsoft.azure:synapseml_2.12:1.0.4Выберите Установить.
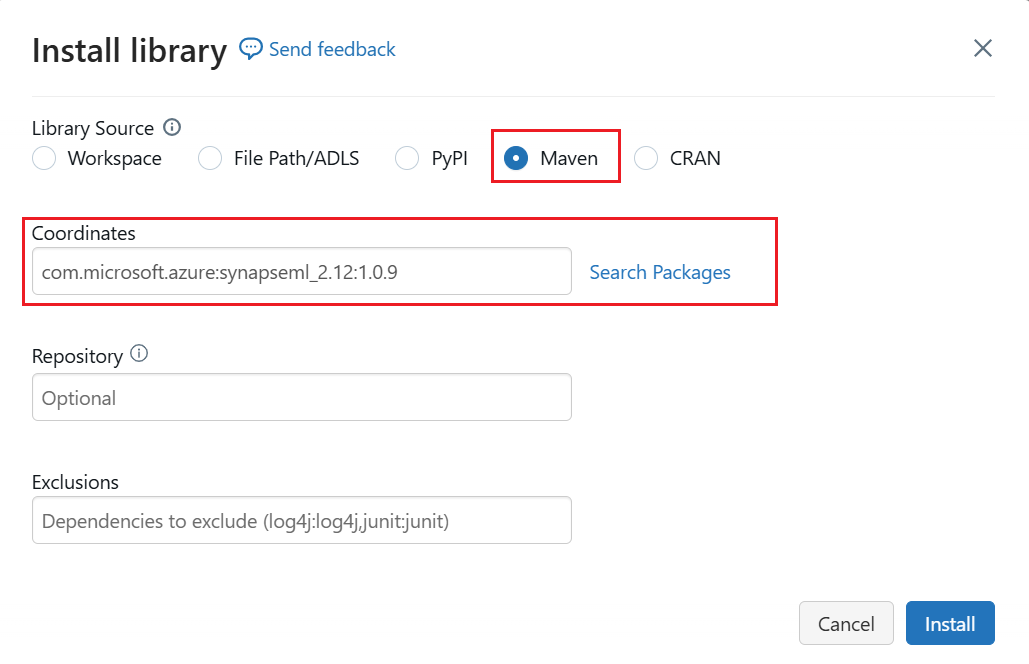
В меню слева выберите "Создать>записную книжку".
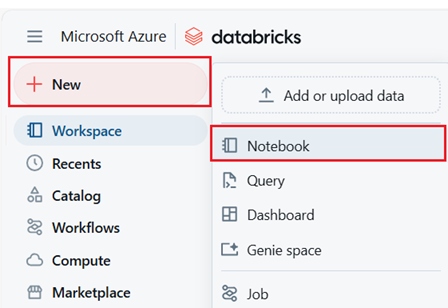
Присвойте записной книжке имя, выберите Python в качестве языка по умолчанию и выберите кластер с библиотекой
synapseml.Создайте семь последовательных ячеек. Вставьте код в каждый из них.
Шаг 2. Настройка зависимостей
Вставьте следующий код в первую ячейку записной книжки.
Замените заполнители конечными точками и ключами доступа для каждого ресурса. Укажите имя нового индекса поиска. Никаких других изменений не требуется, поэтому запустите код, когда вы будете готовы.
Этот код импортирует несколько пакетов и настраивает доступ к ресурсам Azure, используемым в этом рабочем процессе.
import os
from pyspark.sql.functions import udf, trim, split, explode, col, monotonically_increasing_id, lit
from pyspark.sql.types import StringType
from synapse.ml.core.spark import FluentAPI
cognitive_services_key = "placeholder-cognitive-services-multi-service-key"
cognitive_services_region = "placeholder-cognitive-services-region"
search_service = "placeholder-search-service-name"
search_key = "placeholder-search-service-api-key"
search_index = "placeholder-search-index-name"
Шаг 3. Загрузка данных в Spark
Вставьте следующий код во вторую ячейку. Никаких изменений не требуется, поэтому запустите код, когда вы будете готовы.
Этот код загружает несколько внешних файлов из учетной записи хранения Azure. Файлы представляют собой различные счета, и они считываются в кадр данных.
def blob_to_url(blob):
[prefix, postfix] = blob.split("@")
container = prefix.split("/")[-1]
split_postfix = postfix.split("/")
account = split_postfix[0]
filepath = "/".join(split_postfix[1:])
return "https://{}/{}/{}".format(account, container, filepath)
df2 = (spark.read.format("binaryFile")
.load("wasbs://ignite2021@mmlsparkdemo.blob.core.windows.net/form_subset/*")
.select("path")
.limit(10)
.select(udf(blob_to_url, StringType())("path").alias("url"))
.cache())
display(df2)
Шаг 4. Добавление аналитики документов
Вставьте следующий код в третью ячейку. Никаких изменений не требуется, поэтому запустите код, когда вы будете готовы.
Этот код загружает преобразователь AnalyzeInvoices и передает ссылку на кадр данных, содержащий счета. Она вызывает предварительно созданную модель счета аналитики документов Azure для извлечения сведений из счетов.
from synapse.ml.cognitive import AnalyzeInvoices
analyzed_df = (AnalyzeInvoices()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setImageUrlCol("url")
.setOutputCol("invoices")
.setErrorCol("errors")
.setConcurrency(5)
.transform(df2)
.cache())
display(analyzed_df)
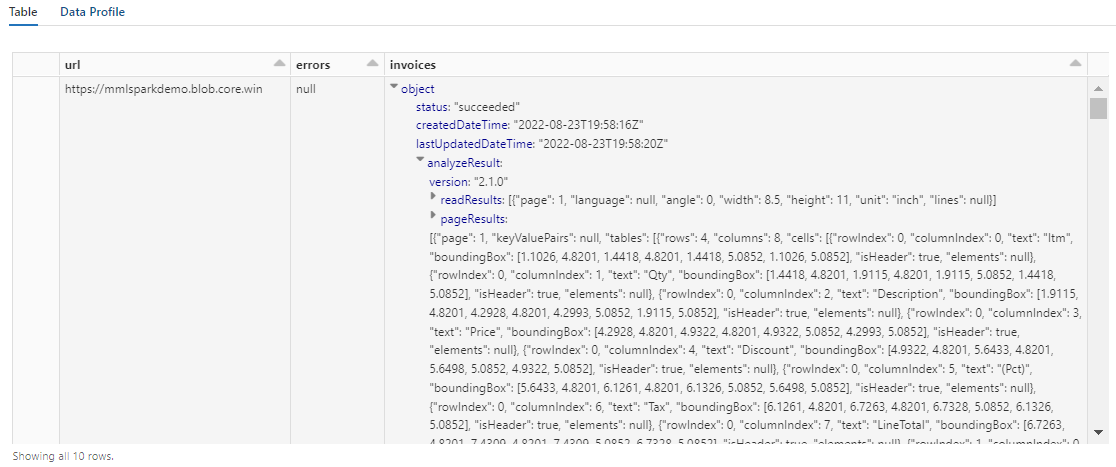
Выходные данные этого шага должны выглядеть примерно так, как на следующем снимку экрана. Обратите внимание, что анализ форм упакован в плотно структурированный столбец, с которым трудно работать. Следующее преобразование устраняет эту проблему, анализируя столбец в строки и столбцы.
Шаг 5. Реструктурирование выходных данных аналитики документов
Вставьте следующий код в четвертую ячейку и запустите ее. Никаких изменений не требуется.
Этот код загружает FormOntologyLearner, преобразователь, который анализирует выходные данные преобразователей аналитики документов и выводит табличную структуру данных. Выходные данные AnalyzeInvoices являются динамическими и зависят от функций, обнаруженных в содержимом. Кроме того, преобразователь объединяет выходные данные в один столбец. Так как выходные данные являются динамическими и консолидированными, трудно использовать в подчиненных преобразованиях, требующих больше структуры.
FormOntologyLearner расширяет программу преобразователя AnalyzeInvoices путем поиска шаблонов, которые можно использовать для создания табличной структуры данных. Упорядочение выходных данных в нескольких столбцах и строках позволяет использовать содержимое в других преобразователях, таких как AzureSearchWriter.
from synapse.ml.cognitive import FormOntologyLearner
itemized_df = (FormOntologyLearner()
.setInputCol("invoices")
.setOutputCol("extracted")
.fit(analyzed_df)
.transform(analyzed_df)
.select("url", "extracted.*").select("*", explode(col("Items")).alias("Item"))
.drop("Items").select("Item.*", "*").drop("Item"))
display(itemized_df)
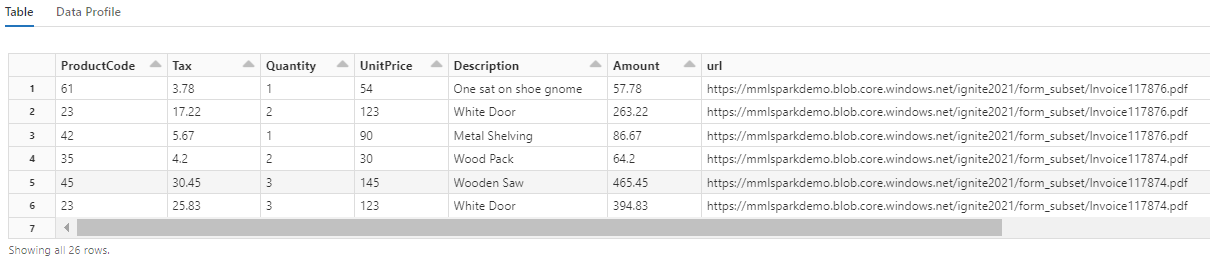
Обратите внимание, как это преобразование переадресует вложенные поля в таблицу, что позволяет выполнять следующие два преобразования. Этот снимок экрана обрезается для краткости. Если вы следуют вместе с собственной записной книжкой, у вас есть 19 столбцов и 26 строк.
Шаг 6. Добавление переводов
Вставьте следующий код в пятую ячейку. Никаких изменений не требуется, поэтому запустите код, когда вы будете готовы.
Этот код загружает преобразователь, который вызывает службу Azure AI Translator в службах ИИ Azure. Исходный текст, который находится на английском языке в столбце "Описание", преобразуется на различные языки. Все выходные данные объединяются в массив output.translations.
from synapse.ml.cognitive import Translate
translated_df = (Translate()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setTextCol("Description")
.setErrorCol("TranslationError")
.setOutputCol("output")
.setToLanguage(["zh-Hans", "fr", "ru", "cy"])
.setConcurrency(5)
.transform(itemized_df)
.withColumn("Translations", col("output.translations")[0])
.drop("output", "TranslationError")
.cache())
display(translated_df)
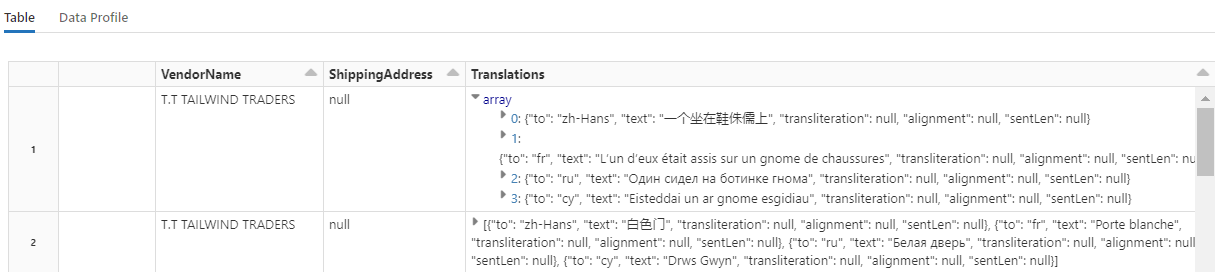
Совет
Чтобы проверить переведенные строки, прокрутите страницу до конца строк.
Шаг 7. Добавление индекса поиска с помощью AzureSearchWriter
Вставьте следующий код в шестую ячейку и запустите его. Никаких изменений не требуется.
Этот код загружает AzureSearchWriter. Он использует табличный набор данных и выводит схему индекса поиска, которая определяет одно поле для каждого столбца. Поскольку структура переводов представляет собой массив, он сформулируется в индексе как сложная коллекция с подполями для каждого перевода языка. Созданный индекс содержит ключ документа и использует значения по умолчанию для полей, созданных с помощью REST API создания индекса.
from synapse.ml.cognitive import *
(translated_df.withColumn("DocID", monotonically_increasing_id().cast("string"))
.withColumn("SearchAction", lit("upload"))
.writeToAzureSearch(
subscriptionKey=search_key,
actionCol="SearchAction",
serviceName=search_service,
indexName=search_index,
keyCol="DocID",
))
Страницы службы поиска можно проверить в портал Azure, чтобы изучить определение индекса, созданное AzureSearchWriter.
Примечание.
Если вы не можете использовать индекс поиска по умолчанию, можно указать внешнее настраиваемое определение в ФОРМАТЕ JSON, передав его URI в виде строки в свойстве IndexJson. Сначала создайте индекс по умолчанию, чтобы узнать, какие поля нужно указать, а затем следовать настраиваемым свойствам, если вам нужны определенные анализаторы, например.
Шаг 8. Запрос индекса
Вставьте следующий код в седьмую ячейку и запустите ее. Никаких изменений не требуется, за исключением того, что вам может потребоваться изменить синтаксис или попробовать дополнительные примеры для дальнейшего изучения содержимого:
Нет преобразователя или модуля, который выдает запросы. Эта ячейка является простым вызовом REST API поиска документов.
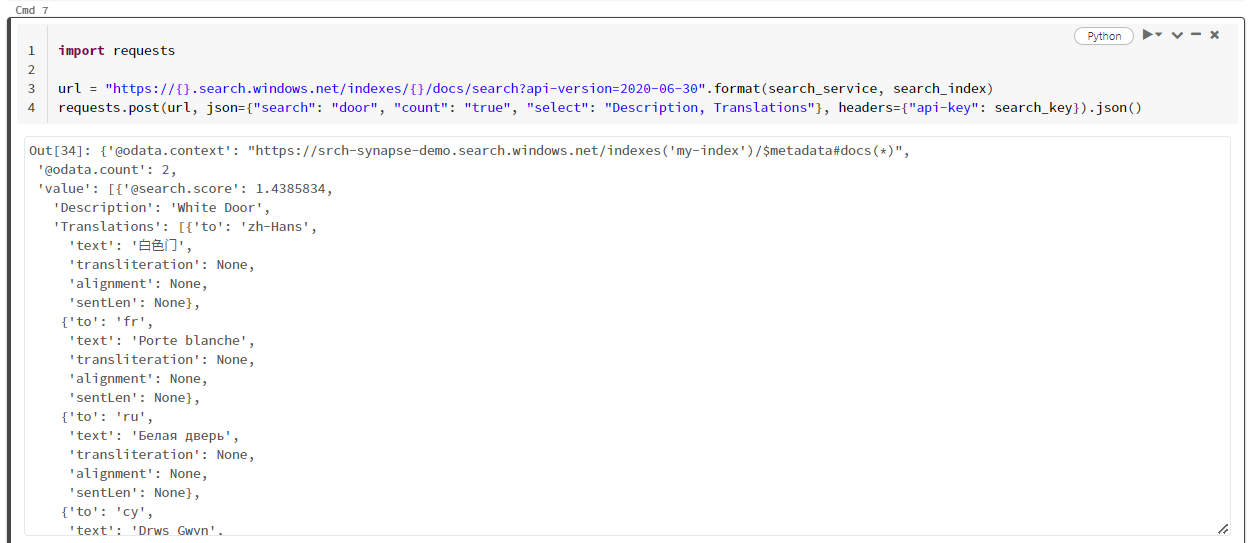
В этом конкретном примере выполняется поиск слова "door" ("search": "door"). Он также возвращает значение "count" количества соответствующих документов и выбирает только содержимое полей "Описание" и "Переводы" для результатов. Если вы хотите просмотреть полный список полей, удалите параметр select.
import requests
url = "https://{}.search.windows.net/indexes/{}/docs/search?api-version=2024-07-01".format(search_service, search_index)
requests.post(url, json={"search": "door", "count": "true", "select": "Description, Translations"}, headers={"api-key": search_key}).json()
На следующем снимке экрана показаны выходные данные ячейки для примера скрипта.
Очистка ресурсов
Если вы работаете в своей подписке, после завершения проекта целесообразно удалить созданные ресурсы, которые вам больше не потребуются. Ресурсы, которые продолжат работать, могут быть платными. Вы можете удалить ресурсы по отдельности либо удалить всю группу ресурсов.
Просматривать ресурсы и управлять ими можно на портале с помощью ссылок Все ресурсы или Группы ресурсов на панели навигации слева.
Следующие шаги
В этом руководстве вы узнали о преобразователе AzureSearchWriter в SynapseML, который является новым способом создания и загрузки индексов поиска в поиске ИИ Azure. Преобразователь принимает структурированный JSON в качестве входных данных. FormOntologyLearner может предоставить необходимую структуру для выходных данных, созданных преобразователями аналитики документов в SynapseML.
На следующем шаге ознакомьтесь с другими руководствами SynapseML, которые создают преобразованное содержимое, которое может потребоваться изучить с помощью поиска ИИ Azure: