Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В службе "Поиск по искусственному интеллекту Azure" семантический ранжатор — это функция, которая измеримо улучшает релевантность поиска с помощью моделей понимания языка Майкрософт для повторного ранжирования результатов поиска. В этой статье приведены общие сведения о поведении и преимуществах семантического ранжирования.
Семантический рангер — это функция уровня "Премиум", оплачиваемая по использованию. Мы рекомендуем использовать эту статью для фона, но если вы предпочитаете начать работу, выполните следующие действия.
Примечание.
Семантический рангировщик не использует генерированный ИИ или векторы для ранжирования вторичного уровня 2 (L2). Если вы ищете векторы и поиск сходства, см. векторный поиск в службе "Поиск ИИ Azure".
Что такое семантический рейтинг?
Семантический рангировщик — это коллекция возможностей на стороне запроса, которые повышают качество исходного BM25-ранжированного или ранжированного RRF результата поиска для текстовых запросов, текстовой части векторных запросов и гибридных запросов. Семантическое ранжирование расширяет конвейер выполнения запросов тремя способами:
Во-первых, он всегда добавляет вторичный рейтинг над первоначальным набором результатов, который был оценен с помощью BM25 или Обратного ранжирования Фьюжн (RRF). Этот вторичный рейтинг использует многоязычные модели глубокого обучения, адаптированные от Microsoft Bing для повышения наиболее семантически релевантных результатов.
Во-вторых, он возвращает субтитры и при необходимости извлекает ответы, которые можно отобразить на странице поиска, чтобы улучшить поисковый опыт пользователя.
В-третьих, если включить перезапись запросов, она расширяет начальную строку запроса на несколько семантически похожих строк запроса.
Вторичное ранжирование и "ответы" применяются к ответу запроса. Перезапись запросов является частью процесса запроса.
Вот возможности семантического переранжировщика.
| Возможность | Описание |
|---|---|
| Рейтинг L2 | Использует контекст или семантический смысл запроса для вычисления новой оценки релевантности по сравнению с предварительно настроенными результатами. |
| Семантические заголовки и выделения | Извлекает подробные предложения и фразы из полей, которые лучше всего суммируют содержимое, с выделением ключевых фрагментов для простого сканирования. Заголовки, которые суммируют результат, полезны, если отдельные поля контента слишком плотны для страницы результатов поиска. Выделенный текст повышает уровень наиболее значимых терминов и фраз, чтобы пользователи могли быстро определить, почему совпадение было признано релевантным. |
| Семантические ответы | Необязательная и дополнительная подструктура, возвращаемая из семантического запроса. Обеспечивает прямой ответ на запрос, который выглядит, как вопрос. Для этого требуется, чтобы документ содержит текст с характеристиками ответа. |
| Перезапись запросов | При использовании текстовых запросов или текстовой части векторного запроса семантика создает до 10 вариантов запроса, возможно исправление опечаток или ошибок орфографии или повторение запроса с помощью созданных синонимов. Перезаписанный запрос выполняется в поисковой системе. Результаты оцениваются с помощью оценки BM25 или RRF, а затем пересматриваются семантическим ранкером. |
Как работает семантический рангер
Семантический рангер передает запрос и результаты для моделей распознавания речи, размещенных корпорацией Майкрософт, и проверяет наличие более качественных совпадений.
На следующем рисунке объясняется понятие. Рассмотрим термин "капитал". Он имеет разные значения в зависимости от того, является ли контекст финансы, закон, география или грамматика. С помощью распознавания речи семантический рангировщик может обнаруживать контекст и повышать результаты, которые соответствуют намерению запроса.
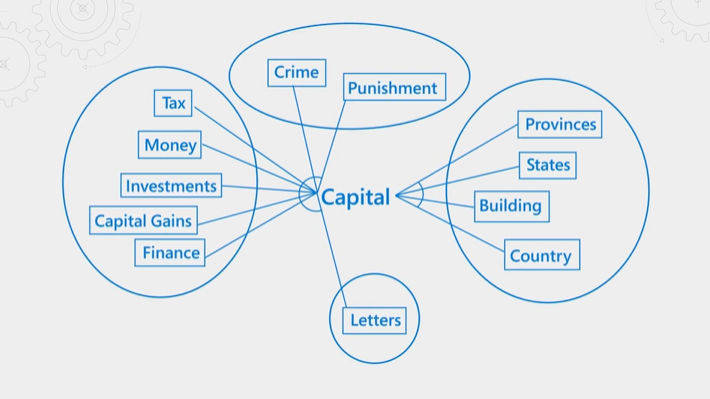
Семантические ранжирование требует ресурсов и времени. Чтобы завершить обработку в пределах ожидаемой задержки операции запроса, входные данные для семантического ранжировщика объединяются и сокращаются для ускорения шага повторного ранжирования, чтобы этот этап можно было выполнить как можно быстрее.
Существует три шага для семантического ранжирования:
- Сбор и сводка входных данных
- Оценка результатов с помощью семантического рангера
- Выходные результаты с пересмотренной оценкой, заголовки и ответы
Сбор и обобщение входных данных
В семантическом ранжировании подсистема запросов передает результаты поиска в качестве входных данных для суммирования и ранжирования моделей. Так как модели ранжирования имеют ограничения на размер входных данных и требуют интенсивной обработки, результаты поиска должны быть оптимизированы по размеру и структуре (обобщены) для эффективной обработки.
Семантический рангировщик начинается с результата BM25, ранжированного из текстового запроса или результата RRF, ранжированного из вектора или гибридного запроса. В упражнении по переоценке ранжирования используется только текст, и только 50 лучших результатов переходят в семантическое ранжирование, даже если результаты содержат больше 50 элементов. Как правило, поля, используемые в семантическом ранжировании, являются информационными и описательными.
Для каждого документа в результатах поиска модель суммирования принимает до 2000 маркеров, где маркер составляет около 10 символов. Входные данные собираются из полей title, keyword и content, перечисленных в семантической конфигурации.
Слишком длинные строки обрезаются, чтобы общая длина соответствовала входным требованиям шага суммирования. Это упражнение по обрезке показывает, почему важно добавлять поля в семантическую конфигурацию в порядке приоритета. В очень больших документах с полями, содержащими большие объемы текста, все данные, превышающие лимит, игнорируются.
Семантическое поле Ограничение количества токенов заголовок 128 токенов "Ключевые слова 128 токенов содержание оставшиеся токены Выходные данные суммирования — это сводная строка для каждого документа, состоящая из наиболее релевантных сведений из каждого поля. Сводные строки отправляются в систему ранжирования для оценки, а также в модели машинного понимания текста для создания подписей и ответов.
По состоянию на ноябрь 2024 года максимальная длина каждой созданной сводной строки, передаваемой семантическому ранжировщику, составляет 2048 токенов. Ранее это было 256 токенов.
Как оценивается ранжирование
Оценка производится по всей подписи, а также по любому другому содержимому из сводной строки, доводящему заполнение до 2048 токенов.
Заголовки оцениваются с точки зрения концептуальной и семантической релевантности относительно предоставленного запроса.
@search.rerankerScore назначается каждому документу на основе семантической релевантности документа для данного запроса. Оценки варьируются от 4 до 0 (высокий и низкий), где более высокая оценка указывает на более высокую релевантность.
Балл Значение 4.0 Документ весьма релевантн и полностью отвечает на этот вопрос, хотя отрывок может содержать дополнительный текст, не связанный с вопросом. 3.0 Документ имеет смысл, но не хватает подробностей, которые бы сделали его завершенным. 2.0 Документ имеет несколько релевантных сведений; он отвечает на вопрос частично или только решает некоторые аспекты вопроса. 1.0 Документ связан с вопросом, и он отвечает на небольшую часть этого вопроса. 0,0 Документ не имеет значения. Совпадения перечислены в порядке убывания по оценке и включены в полезную нагрузку ответа на запрос. Полезная нагрузка включает в себя ответы, обычный текст и подсвеченные подписи, а также все поля, помеченные как извлекаемые или указанные в операторе SELECT.
Примечание.
Для любого конкретного запроса дистрибутивы @search.rerankerScore могут проявлять незначительные вариации из-за условий на уровне инфраструктуры. Известно, что обновления модели ранжирования также могут влиять на распределение. По этим причинам, если вы пишете пользовательский код для минимальных пороговых значений или задаете пороговое свойство для векторных и гибридных запросов, не используйте слишком детализированные ограничения.
Выходные данные семантического рангера
Из каждой сводной строки модели чтения машинного чтения находят фрагменты, которые являются наиболее репрезентативными.
Выходные данные:
Семантический заголовок для документа. Каждый заголовок доступен в виде простой текстовой версии и версии с выделением, и часто составляет менее 200 слов на документ.
Необязательный семантический ответ, при условии, что вы указали
answersпараметр, запрос был задан как вопрос, и в длинной строке найден фрагмент текста, содержащий вероятный ответ на вопрос.
Подписи и ответы всегда представляют собой дословный текст из вашего индекса. В этом операционном процессе нет генеративной модели искусственного интеллекта, которая создает или составляет новое содержимое.
Семантические возможности и ограничения
Что может сделать семантический рангировщик:
Продвигать совпадения, которые семантически ближе к намерению исходного запроса.
Поиск строк для использования в качестве подписей и ответов. Заголовки и ответы возвращаются в ответе и могут отображаться на странице результатов поиска.
Семантический рангировщик не может повторно выполнить запрос по всему корпусу, чтобы найти семантически релевантные результаты. Семантическое ранжирование переоценивает существующий набор результатов, состоящий из первых 50 результатов, оценённых алгоритмом ранжирования по умолчанию. Кроме того, семантический рангировщик не может создавать новые сведения или строки. Подписи и ответы извлекаются дословно из вашего содержимого, поэтому если результаты не включают в себя текст, похожий на ответ, языковые модели не будут его генерировать.
Хотя семантический рейтинг не является полезным в каждом сценарии, определенное содержимое может значительно воспользоваться его возможностями. Языковые модели в семантическом ранжировании лучше всего подходят для поискового контента, который является информационно насыщенным и структурированным в виде прозы. База знаний, онлайн-документация или документы, содержащие описательное содержимое, видят большую выгоду от возможностей семантического ранжирования.
Базовая технология разработана Bing и Microsoft Research и интегрирована в инфраструктуру поисковой системы ИИ Azure как дополнительная функция. Дополнительные сведения об исследованиях и инвестициях в искусственный интеллект, обуславливающих работу семантического ранжировщика, см. в статье О том, как ИИ Bing способствует работе Azure AI Search (блог Microsoft Research).
В следующем видео представлен обзор возможностей.
Как семантический рангер использует карты синонимов
Если вы уже включили поддержку карт синонимов, связанных с полем в своем поисковом индексе, и это поле включено в конфигурацию семантического ранжировщика, семантический ранжировщик автоматически применит настроенные синонимы в процессе повторного ранжирования.
Доступность и цены
Семантический рангировщик доступен в службах поиска на уровнях "Базовый" и "Выше", при условии региональной доступности.
При настройке семантического ранжирования выберите план ценообразования для функции:
- При меньших объемах запросов (менее 1000 в месяц) семантический рейтинг предоставляется бесплатно.
- В более высоких объемах запросов выберите стандартный тарифный план.
На странице цен Azure Search на базе искусственного интеллекта отображается тариф для разных валют и интервалов.
Плата за семантический рангировщик взимается, если запросы включают в себя queryType=semantic , и строка поиска не пуста (например, search=pet friendly hotels in New York). Если строка поиска пуста (search=*), плата не взимается, даже если для типа запроса задана семантика.
Начало работы с семантическим рангером
Проверьте региональную доступность.
Войдите в портал Azure, чтобы убедиться, что служба поиска является базовой или более поздней.
Настройте семантический рангировщик для службы поиска, выбрав план ценообразования.
Настройте запросы для возврата семантических субтитров и выделений.