Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В решениях поиска строки, имеющие сложные шаблоны или специальные символы, могут быть сложными для работы, так как анализатор по умолчанию удаляет или неправильно интерпретирует значимые части шаблона. Это приводит к плохому поиску, в котором пользователи не могут найти информацию, которую они ожидают. Номера телефонов — это классический пример строк, которые сложно проанализировать. Они входят в различные форматы и включают специальные символы, которые анализатор по умолчанию игнорирует.
С номерами телефонов в качестве темы в этом руководстве используются REST API службы поиска для решения шаблонных проблем с данными с помощью пользовательского анализатора. Этот подход можно использовать как для номеров телефонов, так и для полей с теми же характеристиками (шаблонными специальными символами), такими как URL-адреса, электронные письма, почтовые коды и даты.
Изучив это руководство, вы:
- Определение проблемы
- Разработка начального пользовательского анализатора для обработки номеров телефонов
- Тестирование пользовательского анализатора
- Итерацию по пользовательскому конструктору анализатора для дальнейшего улучшения результатов
Предварительные условия
Учетная запись Azure с активной подпиской. Создайте учетную запись бесплатно .
Загрузка файлов
Исходный код для этого руководства находится в файле custom-analyzer.rest в репозитории GitHub Azure-Samples/azure-search-rest-samples .
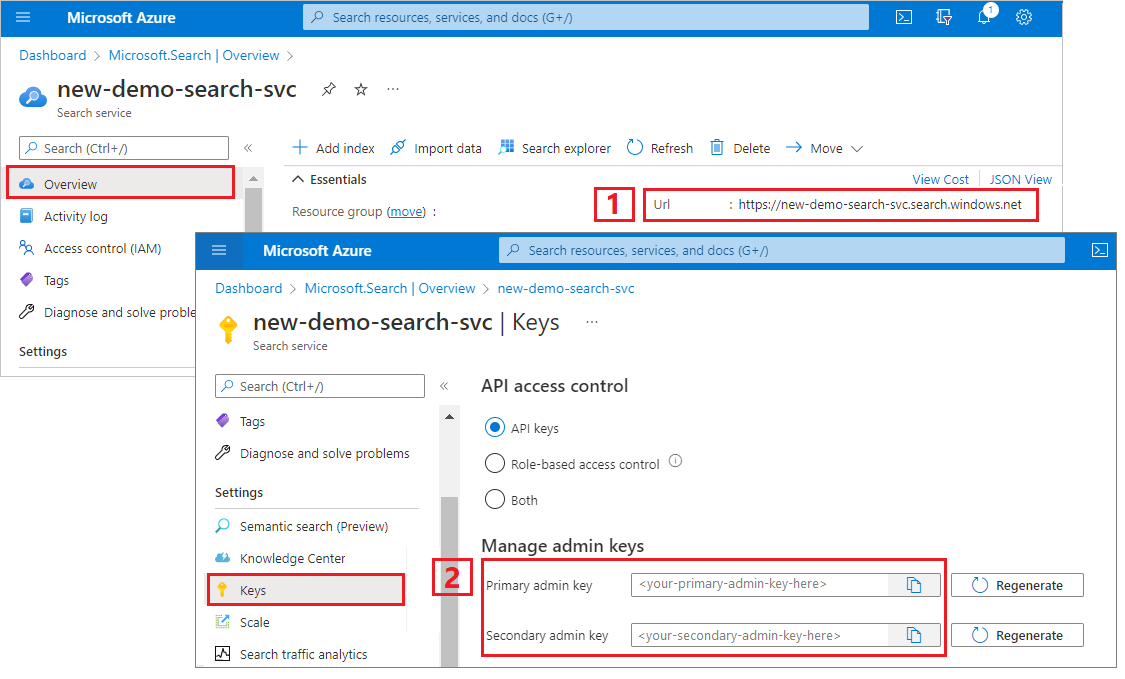
Копирование ключа администратора и URL-адреса
Вызовы REST в этом руководстве требуют конечной точки службы поиска и ключа API администратора. Эти значения можно получить из портал Azure.
Перейдите в службу поиска в портал Azure.
В левой области выберите "Обзор " и скопируйте конечную точку. Он должен быть в следующем формате:
https://my-service.search.windows.netВ левой панели выберите Параметры> и Ключи, затем скопируйте администраторский ключ для полного доступа к службе. Существуют два взаимозаменяемых ключа администратора, предназначенных для обеспечения непрерывности бизнес-процессов на случай, если вам потребуется сменить один из них. Вы можете использовать либо один из ключей для запросов чтобы добавлять, изменять или удалять объекты.
Создание начального индекса
Откройте новый текстовый файл в Visual Studio Code.
Задайте переменные конечной точке поиска и ключ API, собранный в предыдущем разделе.
@baseUrl = PUT-YOUR-SEARCH-SERVICE-URL-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HEREСохраните файл с расширением
.restфайла.Вставьте следующий пример, чтобы создать небольшой индекс
phone-numbers-indexс двумя полями:idиphone_number.### Create a new index POST {{baseUrl}}/indexes?api-version=2026-04-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false } ] }Вы еще не определили анализатор, поэтому
standard.luceneанализатор используется по умолчанию.Щелкните Отправить запрос. Должен быть
HTTP/1.1 201 Createdответ, а текст ответа должен содержать представление JSON схемы индекса.Загрузите данные в индекс с помощью документов, содержащих различные форматы номеров телефонов. Это тестовые данные.
### Load documents POST {{baseUrl}}/indexes/phone-numbers-index/docs/index?api-version=2026-04-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "value": [ { "@search.action": "upload", "id": "1", "phone_number": "425-555-0100" }, { "@search.action": "upload", "id": "2", "phone_number": "(321) 555-0199" }, { "@search.action": "upload", "id": "3", "phone_number": "+1 425-555-0100" }, { "@search.action": "upload", "id": "4", "phone_number": "+1 (321) 555-0199" }, { "@search.action": "upload", "id": "5", "phone_number": "4255550100" }, { "@search.action": "upload", "id": "6", "phone_number": "13215550199" }, { "@search.action": "upload", "id": "7", "phone_number": "425 555 0100" }, { "@search.action": "upload", "id": "8", "phone_number": "321.555.0199" } ] }Попробуйте выполнить запросы, которые пользователь может ввести. Например, пользователь может выполнять поиск
(425) 555-0100в любом количестве форматов и по-прежнему ожидать возврата результатов. Сначала выполните поиск(425) 555-0100.### Search for a phone number POST {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2026-04-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "search": "(425) 555-0100" }Запрос возвращает три из четырех ожидаемых результатов, но также возвращает два непредвиденных результата.
{ "value": [ { "@search.score": 0.05634898, "phone_number": "+1 425-555-0100" }, { "@search.score": 0.05634898, "phone_number": "425 555 0100" }, { "@search.score": 0.05634898, "phone_number": "425-555-0100" }, { "@search.score": 0.020766128, "phone_number": "(321) 555-0199" }, { "@search.score": 0.020766128, "phone_number": "+1 (321) 555-0199" } ] }Повторите попытку без форматирования:
4255550100### Search for a phone number POST {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2026-04-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "search": "4255550100" }Этот запрос гораздо хуже, возвращая только одно из четырех правильных совпадений.
{ "value": [ { "@search.score": 0.6015292, "phone_number": "4255550100" } ] }
Если это кажется вам нелогичным, вы не одиноки. В следующем разделе объясняется, почему вы получаете эти результаты.
Узнайте, как работают анализаторы
Чтобы понять эти результаты поиска, необходимо понять, что делает анализатор. Оттуда можно протестировать анализатор по умолчанию с помощью API анализа, предоставляя основу для разработки анализатора, который лучше соответствует вашим потребностям.
Анализатор является компонентом полнотекстовой поисковой системы, ответственной за обработку текста в строках запроса и индексированных документах. Различные анализаторы по-разному обрабатывают текст в зависимости от сценария. В этом сценарии нам нужно создать анализатор, настроенный для работы с телефонными номерами.
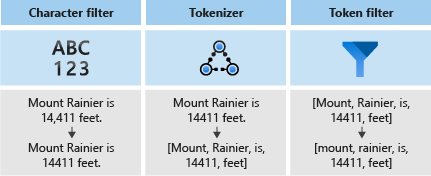
Анализаторы включают три компонента:
- Фильтры символов, которые удаляют или замещают отдельные символы во входных текстовых данных.
- Токенизатор, который разбивает входной текст на маркеры, которые становятся ключами в индексе поиска.
- Фильтры маркеров, которые обрабатывают маркеры, созданные создателем маркеров.
На следующей схеме показано, как эти три компонента работают вместе для маркеризации предложения.
Затем эти маркеры сохраняются в инвертированном индексе, который позволяет выполнять быстрый полнотекстовый поиск. Инвертированный индекс обеспечивает поддержку полнотекстового поиска благодаря сопоставлению всех уникальных терминов, извлеченных во время лексического анализа, с документами, в которых они встречаются. Пример можно увидеть на следующей схеме:

Все операции поиска сводятся к поиску терминов в инвертированном индексе. Когда пользователь отправляет запрос:
- Запрос обрабатывается с анализом терминов запроса.
- Инвертированный индекс сканируется на документы с совпадающими терминами.
- Алгоритм оценки ранжирует извлеченные документы.
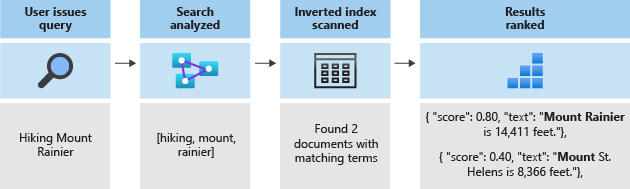
Если термины запроса не соответствуют терминам в инвертированном индексе, результаты не возвращаются. Дополнительные сведения о работе запросов см. в статье " Полнотекстовый поиск" в службе "Поиск ИИ Azure".
Примечание.
Запросы с частичными терминами являются важным исключением из этого правила. В отличие от обычных запросов, эти запросы (префиксный запрос, запрос с подстановочными знаками и запрос с использованием регулярных выражений) обходят процесс лексического анализа. Частичные термины переводятся в нижний регистр только при сопоставлении с терминами в индексе. Если анализатор не настроен для поддержки этих типов запросов, часто возникают непредвиденные результаты, так как соответствующие термины не существуют в индексе.
Тестируйте анализаторы с помощью интерфейса API для анализа
Служба поиска Azure AI предоставляет API для анализа текста, которое позволяет тестировать анализаторы, чтобы понять, как они обрабатывают текст.
ВызовИТЕ API анализа с помощью следующего запроса:
### Test analyzer
POST {{baseUrl}}/indexes/phone-numbers-index/analyze?api-version=2026-04-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "(425) 555-0100",
"analyzer": "standard.lucene"
}
API возвращает маркеры, извлеченные из текста, с помощью указанного анализатора. Стандартный анализатор Lucene разделяет номер телефона на три отдельных токена.
{
"tokens": [
{
"token": "425",
"startOffset": 1,
"endOffset": 4,
"position": 0
},
{
"token": "555",
"startOffset": 6,
"endOffset": 9,
"position": 1
},
{
"token": "0100",
"startOffset": 10,
"endOffset": 14,
"position": 2
}
]
}
Напротив, номер телефона 4255550100 без каких-либо знаков пунктуации токенизируется в один токен.
{
"text": "4255550100",
"analyzer": "standard.lucene"
}
Ответ:
{
"tokens": [
{
"token": "4255550100",
"startOffset": 0,
"endOffset": 10,
"position": 0
}
]
}
Помните, что оба термина запроса и индексированные документы проходят анализ. Думая о результатах поиска на предыдущем шаге, вы можете начать понимать, почему эти результаты возвращаются.
В первом запросе возвращаются непредвиденные номера телефонов из-за того, что один из их токенов, 555, совпадает с одним из терминов, которые вы искали. Во втором запросе возвращается только одно число, так как это единственная запись, которая соответствует маркеру 4255550100.
Создание пользовательского анализатора
Теперь, когда вы понимаете результаты, которые видите, создайте настраиваемый анализатор для улучшения логики токенизации.
Его предназначение — сделать поиск телефонных номеров более интуитивно понятным независимо от формата запросов или индексированных строк. Чтобы добиться этого результата, укажите фильтр символов, токенизатор и фильтр маркеров.
Фильтры символов
Фильтры символов обрабатывают текст перед его вводом в токенизатор. Часто используются фильтры символов, отфильтровывая элементы HTML и заменяя специальные символы.
Для номеров телефонов необходимо удалить пробелы и специальные символы, так как не все форматы номеров телефонов содержат одинаковые специальные символы и пробелы.
"charFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.MappingCharFilter",
"name": "phone_char_mapping",
"mappings": [
"-=>",
"(=>",
")=>",
"+=>",
".=>",
"\\u0020=>"
]
}
]
Фильтр удаляет и пробелы -()+. из входных данных.
| Входные данные | Выходные данные |
|---|---|
(321) 555-0199 |
3215550199 |
321.555.0199 |
3215550199 |
Токенизаторы
Токенизаторы разбивают текст на токены и удаляют некоторые символы, например знаки пунктуации. Во многих случаях цель токенизации заключается в разделении предложения на отдельные слова.
Для этого сценария используйте токенизатор ключевых слов, keyword_v2чтобы записать номер телефона в виде одного термина. Это не единственный способ решить эту проблему, как описано в разделе "Альтернативные подходы ".
Токенизаторы ключевых слов всегда выводят тот же текст, который им передан, в виде одного токена.
| Входные данные | Выходные данные |
|---|---|
The dog swims. |
[The dog swims.] |
3215550199 |
[3215550199] |
Фильтры токенов
Фильтры маркеров изменяют или фильтруют маркеры, созданные токенизатором. Некоторые из распространенных способов использования таких фильтров заключаются в переводе всех символов в нижний регистр с помощью специального фильтра Другое частое использование — фильтрация стоп-слов, таких как the, andили is.
Хотя для этого сценария не требуется использовать ни один из этих фильтров, используйте фильтр маркера nGram, чтобы разрешить частичный поиск номеров телефонов.
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2",
"name": "custom_ngram_filter",
"minGram": 3,
"maxGram": 20
}
]
NGramTokenFilterV2
Фильтр маркеров nGram_v2 разделяет маркеры на N-граммы заданного размера с учетом параметров minGram и maxGram.
Для анализатора телефонов minGram установлено значение 3, так как это самая короткая подстрока, которую пользователи, вероятно, будут искать.
maxGram установлен на 20, чтобы все номера телефонов, даже с добавочными, помещались в одну n-грамму.
Неблагоприятный побочный эффект n-граммов заключается в том, что некоторые ложные положительные результаты выдаются. Вы исправите это на следующем шаге, создав отдельный анализатор для поиска, который не включает фильтр токенов n-грамм.
| Входные данные | Выходные данные |
|---|---|
[12345] |
[123, 1234, 12345, 234, 2345, 345] |
[3215550199] |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
Анализатор
С фильтрами символов, токенизатором и фильтрами токенов вы готовы определить анализатор.
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer",
"tokenizer": "keyword_v2",
"tokenFilters": [
"custom_ngram_filter"
],
"charFilters": [
"phone_char_mapping"
]
}
]
В API анализа, учитывая следующие входные данные, выходные данные пользовательского анализатора приведены следующим образом:
| Входные данные | Выходные данные |
|---|---|
12345 |
[123, 1234, 12345, 234, 2345, 345] |
(321) 555-0199 |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
Все маркеры в выходном столбце существуют в индексе. Если запрос содержит любой из этих терминов, возвращается номер телефона.
Перестройте с использованием нового анализатора
Удалите текущий индекс.
### Delete the index DELETE {{baseUrl}}/indexes/phone-numbers-index?api-version=2026-04-01 HTTP/1.1 api-key: {{apiKey}}Повторно создайте индекс с помощью нового анализатора. Эта схема индекса добавляет пользовательское определение анализатора и назначение пользовательского анализатора для поля номера телефона.
### Create a new index POST {{baseUrl}}/indexes?api-version=2026-04-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index-2", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false, "analyzer": "phone_analyzer" } ], "analyzers": [ { "@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer", "name": "phone_analyzer", "tokenizer": "keyword_v2", "tokenFilters": [ "custom_ngram_filter" ], "charFilters": [ "phone_char_mapping" ] } ], "charFilters": [ { "@odata.type": "#Microsoft.Azure.Search.MappingCharFilter", "name": "phone_char_mapping", "mappings": [ "-=>", "(=>", ")=>", "+=>", ".=>", "\\u0020=>" ] } ], "tokenFilters": [ { "@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2", "name": "custom_ngram_filter", "minGram": 3, "maxGram": 20 } ] }
Тестирование пользовательского анализатора
После повторного создания индекса проверьте анализатор с помощью следующего запроса:
### Test custom analyzer
POST {{baseUrl}}/indexes/phone-numbers-index-2/analyze?api-version=2026-04-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "+1 (321) 555-0199",
"analyzer": "phone_analyzer"
}
Теперь вы увидите коллекцию токенов, полученных из номера телефона.
{
"tokens": [
{
"token": "132",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "1321",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "13215",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
...
...
...
]
}
Изменение пользовательского анализатора для обработки ложных срабатываний
После использования пользовательского анализатора для создания примеров запросов к индексу вы увидите, что полнота улучшилась и теперь возвращаются все совпадающие номера телефонов. Однако фильтр токенов n-грамм также приводит к возврату некоторых ложных срабатываний. Это распространенный побочный эффект фильтра токенов n-грамм.
Чтобы предотвратить ложные срабатывания, создайте отдельный анализатор для запросов. Этот анализатор идентичен предыдущему, за исключением того, что он опускает custom_ngram_filter.
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_search",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [],
"charFilters": [
"phone_char_mapping"
]
}
В определении индекса укажите как a indexAnalyzer , так и a searchAnalyzer.
{
"name": "phone_number",
"type": "Edm.String",
"sortable": false,
"searchable": true,
"filterable": false,
"facetable": false,
"indexAnalyzer": "phone_analyzer",
"searchAnalyzer": "phone_analyzer_search"
}
С этим изменением все готово. Ниже приведены дальнейшие действия.
Удалите индекс.
Повторно создайте индекс после добавления нового пользовательского анализатора (
phone_analyzer-search) и назначьте этот анализатор свойствуphone-numberполяsearchAnalyzer.Перезагрузите данные.
Повторно проверьте запросы, чтобы убедиться, что поиск работает должным образом. Если вы используете пример файла, этот шаг создает третий индекс с именем
phone-number-index-3.
Альтернативные подходы
Анализатор, описанный в предыдущем разделе, предназначен для повышения гибкости поиска. Но она достигается за счет хранения множества потенциально ненужных терминов в индексе.
В следующем примере показан альтернативный анализатор, который эффективнее в токенизации, но он имеет недостатки.
Учитывая входные данные 14255550100, анализатор не может логически разделить номер телефона на части. Например, он не может отделять код страны от 1кода области. 425 Это несоответствие приводит к тому, что номер телефона не возвращается, если пользователь не включает код страны в поиск.
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_shingles",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [
"custom_shingle_filter"
]
}
],
"tokenizers": [
{
"@odata.type": "#Microsoft.Azure.Search.StandardTokenizerV2",
"name": "custom_tokenizer_phone",
"maxTokenLength": 4
}
],
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.ShingleTokenFilter",
"name": "custom_shingle_filter",
"minShingleSize": 2,
"maxShingleSize": 6,
"tokenSeparator": ""
}
]
В следующем примере номер телефона разбивается на блоки в том виде, в каком его обычно ищут пользователи.
| Входные данные | Выходные данные |
|---|---|
(321) 555-0199 |
[321, 555, 0199, 321555, 5550199, 3215550199] |
В зависимости от ваших требований это может быть более эффективным подходом к проблеме.
Общие выводы
В этом руководстве демонстрируется процесс создания и тестирования пользовательского анализатора. Вы создали индекс, проиндексировали данные, а затем выполнили запросы к индексу для оценки результатов поиска. Затем вы использовали API анализа для просмотра лексического анализа в действии.
Хотя анализатор, определенный в этом руководстве, предлагает простое решение для поиска по номерам телефонов, этот же процесс можно использовать для создания пользовательского анализатора для любого сценария, который использует аналогичные характеристики.
Очистка ресурсов
Если вы работаете в своей подписке, то после завершения проекта хорошая идея — удалить ресурсы, которые вам больше не нужны. Ресурсы, которые оставлены в рабочем состоянии, могут стоить вам денег. Вы можете удалить ресурсы по отдельности либо удалить всю группу ресурсов.
Ресурсы можно найти и управлять ими в портал Azure, используя ссылку "Все ресурсы" или "Группы ресурсов" в области навигации слева.
Следующие шаги
Теперь, когда вы знаете, как создать пользовательский анализатор, ознакомьтесь со всеми различными фильтрами, токенизаторами и анализаторами, доступными для создания расширенного интерфейса поиска: