События
5 мар., 17 - 2 апр., 16
Присоединитесь к конечной 5-недельной поездке, чтобы узнать RAG!
Начните уже сегодняЭтот браузер больше не поддерживается.
Выполните обновление до Microsoft Edge, чтобы воспользоваться новейшими функциями, обновлениями для системы безопасности и технической поддержкой.
Поиск ИИ Azure может импортировать, анализировать и индексировать данные из нескольких источников данных в единый консолидированный индекс поиска.
В этом руководстве C# клиентская библиотека Azure.Search.Documents в пакете SDK azure для .NET используется для индексирования примеров данных отеля из экземпляра Azure Cosmos DB и слияние с сведениями о номере отеля, полученными из документов Хранилище BLOB-объектов Azure. Результатом является объединенный индекс поиска отеля, содержащий документы отеля, с номерами в виде сложных типов данных.
Вот какие шаги выполняются в этом учебнике:
Если у вас нет подписки Azure, создайте бесплатную учетную запись, прежде чем приступить к работе.
В этом руководстве используется Azure.Search.Documents для создания и запуска нескольких индексаторов. При прохождении этого учебника вы настроите два источника данных Azure таким образом, чтобы создать индексатор, который будет извлекать данные из обоих источников данных для заполнения одного индекса поиска. Для поддержки слияния оба набора данных должны иметь общее значение. В этом примере таким полем является идентификатор. Если для сопоставления есть поле, индексатор может объединить данные из разрозненных ресурсов: структурированные данные из SQL Azure, неструктурированные данные из хранилища BLOB-объектов или любое сочетание поддерживаемых источников данных в Azure.
Готовую версию кода для этого руководства можно найти в следующем проекте:
Примечание
Вы можете использовать бесплатную службу поиска для этого руководства. Уровень "Бесплатный" ограничивается тремя индексами, тремя индексаторами и тремя источниками данных. В этом руководстве создается по одному объекту из каждой категории. Перед началом работы убедитесь, что у службы есть достаточно места, чтобы принять новые ресурсы.
В этом руководстве используется поиск ИИ Azure для индексирования и запросов, Azure Cosmos DB для одного набора данных и Хранилище BLOB-объектов Azure для второго набора данных.
Желательно создать все службы в одном регионе и в одной группе ресурсов, чтобы упростить взаимодействие и управление. На практике службы могут находиться в любом регионе.
В этом примере используются два небольших набора данных, которые описывают семь вымышленных отелей. Один набор, который описывает сами отели, мы загрузим в базу данных Azure Cosmos DB. Другой набор с подробными сведениями о номерах в этих отелях предоставляется в виде семи отдельных файлов формата JSON, и его мы отправим в хранилище BLOB-объектов Azure.
Войдите на портал Azure и перейдите к странице обзора для учетной записи Azure Cosmos DB.
Выберите раздел Обозреватель данных, а затем — команду Новая база данных.
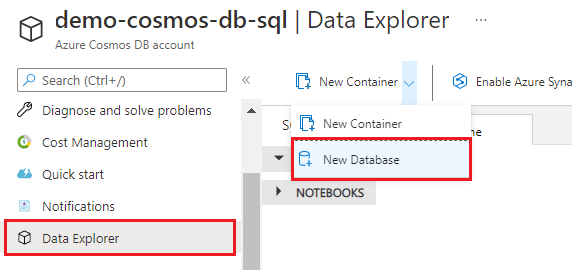
Введите имя hotel-rooms-db. Примите значения по умолчанию для остальных параметров.
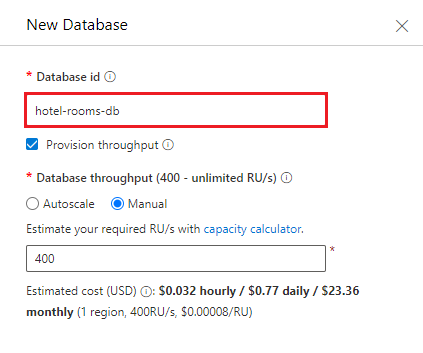
Создайте новый контейнер. Используйте имеющуюся базу данных, которую вы только что создали. В качестве имени контейнера введите hotels, а имени ключа секции — /HotelId.
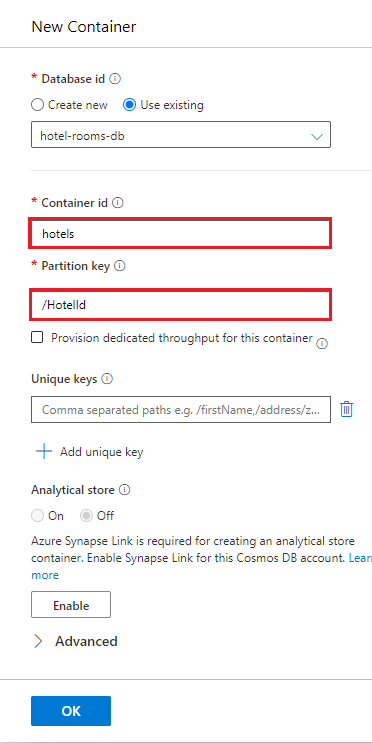
Выберите "Элементы " в отелях и нажмите кнопку "Отправить элемент " на панели команд. Перейдите к файлу cosmosdb/HotelsDataSubset_CosmosDb.json в папке проекта и выберите его.

С помощью кнопки "Обновить" освежите представление элементов в коллекции hotels. Вы увидите в списке семь новых документов базы данных.
Скопируйте строку подключения со страницы Ключи в блокнот. Это значение потребуется для appsettings.json на следующем шаге. Если вы не использовали предлагаемое имя базы данных "hotel-rooms-db", скопируйте имя базы данных.
Войдите в портал Azure, перейдите к учетной записи хранения Azure, выберите большие двоичные объекты и нажмите кнопку +Контейнер.
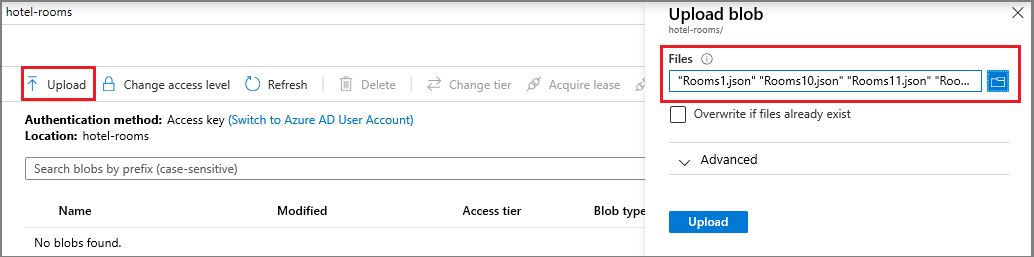
Создайте контейнер больших двоичных объектов с именем hotel-rooms, в котором будут храниться JSON-файлы с примерами данных о номерах отелей. Можно задать любое из допустимых значений уровня общего доступа.

Откройте контейнер после создания и на панели команд выберите Загрузить. Перейдите к папке, содержащей примеры файлов. Выберите все из них и нажмите кнопку "Отправить".
Скопируйте имя учетной записи хранения и строка подключения на странице "Ключи доступа" в Блокнот. Вам потребуется оба значения для appsettings.json на следующем шаге.
Третий компонент — поиск ИИ Azure, который можно создать в портал Azure или найти существующую службу поиска в ресурсах Azure.
Чтобы пройти проверку подлинности в службе поиска, вам потребуется URL-адрес службы и ключ доступа.
Войдите на портал Azure и на странице обзора службы поиска получите URL-адрес. Пример конечной точки может выглядеть так: https://mydemo.search.windows.net.
В разделе Параметры>Ключи получите ключ администратора, чтобы обрести полные права на службу. Существуют два взаимозаменяемых ключа администратора, предназначенных для обеспечения непрерывности бизнес-процессов на случай, если вам потребуется сменить один из них. Вы можете использовать первичный или вторичный ключ для выполнения запросов на добавление, изменение и удаление объектов.
Если есть действительный ключ, для каждого запроса устанавливаются отношения доверия между приложением, которое отправляет запрос, и службой, которая его обрабатывает.
Запустите Visual Studio. В меню Средства выберите Диспетчер пакетов NuGet, а затем — Управление пакетами NuGet для решения....
Во вкладке Обзор найдите и установите Azure.Search.Documents (версия 11.0 или более поздняя).
Найдите и установите пакеты NuGet Microsoft.Extensions.Configuration и Microsoft.Extensions.Configuration.Json.
Откройте файл решения /v11/AzureSearchMultipleDataSources.sln.
В обозревателе решений измените файл appsettings.json, добавив сведения о подключении.
{
"SearchServiceUri": "<YourSearchServiceURL>",
"SearchServiceAdminApiKey": "<YourSearchServiceAdminApiKey>",
"BlobStorageAccountName": "<YourBlobStorageAccountName>",
"BlobStorageConnectionString": "<YourBlobStorageConnectionString>",
"CosmosDBConnectionString": "<YourCosmosDBConnectionString>",
"CosmosDBDatabaseName": "hotel-rooms-db"
}
Первые две записи содержат URL-адрес и ключи администратора службы поиска. Используйте полную конечную точку, например: https://mydemo.search.windows.net.
Следующие записи содержат имена учетных записей и строки подключения для хранилища BLOB-объектов Azure и источников данных Azure Cosmos DB.
Для объединения содержимого требуется, чтобы оба потока данных использовали одни и те же документы в индексе поиска.
В поиске ИИ Azure ключевое поле однозначно идентифицирует каждый документ. Каждый индекс поиска должен содержать только одно поле ключа типа Edm.String. Это поле ключа должно присутствовать в источнике данных для каждого документа, который добавляется к индексу. (Фактически, это единственное обязательное для заполнения поле.)
При индексировании данных из нескольких источников данных убедитесь, что каждая входная строка или входной документ содержит общий ключ документа для объединения данных из двух физически различных исходных документов в новый документ поиска в комбинированном индексе.
Зачастую приходится потратить некоторое время, чтобы заранее составить разумный ключ документа для создаваемого индекса и убедиться, что он существует в обоих источниках данных. В этой демонстрации HotelId ключ для каждого отеля в Azure Cosmos DB также присутствует в комнатах BLOB-объектов JSON в хранилище BLOB-объектов.
Индексаторы поиска ИИ Azure могут использовать сопоставления полей для переименования и даже переформатирования полей данных во время процесса индексирования, чтобы исходные данные могли быть перенаправлены в правильное поле индекса. Например, в Azure Cosmos DB идентификатор отеля вызывается HotelId. Но в файлах JSON больших двоичных объектов с информацией о номерах отелей этот идентификатор именуется Id. Программа обрабатывает это несоответствие путем сопоставления Id поля из больших двоичных объектов с HotelId ключевым полем индексатора.
Примечание
В большинстве случаев автоматически сформированные ключи документов, например стандартные ключи некоторых индексаторов, плохо подходят для объединенных индексов. Обычно вам нужны содержательные и уникальные значения ключей, которые уже существуют в источниках данных и (или) легко могут быть добавлены к ним.
Когда вы завершите отправку данных и настройку параметров конфигурации, пример программы /v11/AzureSearchMultipleDataSources.sln будет готов к сборке и запуску.
Это простое консольное приложение для C#/.NET выполняет следующие задачи:
Перед выполнением этой программы вам стоит изучить ее код и определения индекса и индексатора, настроенные для нашего примера. Соответствующий код находится в двух файлах:
В этом примере программы для определения и создания индекса поиска ИИ Azure используется CreateIndexAsync . С помощью FieldBuilder из класса C# модели данных программа создает структуру индекса.
Модель данных определяется в классе Hotel, который содержит также ссылки на классы Address и Room. FieldBuilder углубляется в структуру определений нескольких классов, создавая на их основе сложную структуру данных для индекса. Теги метаданных применяются для определения атрибутов каждого поля, например сведений о поддержке поиска или сортировки.
Перед созданием индекса программа также удаляет существующий индекс с тем же именем на случай, если вы будете выполнять этот пример более одного раза.
В следующих фрагментах кода из файла Hotel.cs отображаются отдельные поля, за которым следует ссылка на другой класс модели данных, Room[], который, в свою очередь, определен в файле Room.cs (не показан).
. . .
[SimpleField(IsFilterable = true, IsKey = true)]
public string HotelId { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true)]
public string HotelName { get; set; }
. . .
public Room[] Rooms { get; set; }
. . .
В файле Program.cs для SearchIndex определяется имя и коллекция полей, созданных методом FieldBuilder.Build, а затем этот индекс создается, как показано ниже:
private static async Task CreateIndexAsync(string indexName, SearchIndexClient indexClient)
{
// Create a new search index structure that matches the properties of the Hotel class.
// The Address and Room classes are referenced from the Hotel class. The FieldBuilder
// will enumerate these to create a complex data structure for the index.
FieldBuilder builder = new FieldBuilder();
var definition = new SearchIndex(indexName, builder.Build(typeof(Hotel)));
await indexClient.CreateIndexAsync(definition);
}
Далее основая программа включает логику для создания источника данных Azure Cosmos DB, где будут храниться данные об отелях.
Сначала она объединяет имя базы данных Azure Cosmos DB и строку подключения. Затем определяет объект SearchIndexerDataSourceConnection.
private static async Task CreateAndRunCosmosDbIndexerAsync(string indexName, SearchIndexerClient indexerClient)
{
// Append the database name to the connection string
string cosmosConnectString =
configuration["CosmosDBConnectionString"]
+ ";Database="
+ configuration["CosmosDBDatabaseName"];
SearchIndexerDataSourceConnection cosmosDbDataSource = new SearchIndexerDataSourceConnection(
name: configuration["CosmosDBDatabaseName"],
type: SearchIndexerDataSourceType.CosmosDb,
connectionString: cosmosConnectString,
container: new SearchIndexerDataContainer("hotels"));
// The Azure Cosmos DB data source does not need to be deleted if it already exists,
// but the connection string might need to be updated if it has changed.
await indexerClient.CreateOrUpdateDataSourceConnectionAsync(cosmosDbDataSource);
После создания источника данных программа настраивает индексатор Azure Cosmos DB с именем hotel-rooms-cosmos-indexer.
Программа обновляет все существующие индексаторы с одинаковыми названиями, перезаписывая существующий индексатор содержимым приведенного выше кода. Она также содержит команды сброса и выполнения, если вы хотите несколько раз запустить пример.
Следующий пример определяет для индексатора расписание, согласно которому он будет выполняться один раз в день. Вы можете удалить из вызова свойство расписания, если вам не нужно автоматически выполнять индексатор в будущем.
SearchIndexer cosmosDbIndexer = new SearchIndexer(
name: "hotel-rooms-cosmos-indexer",
dataSourceName: cosmosDbDataSource.Name,
targetIndexName: indexName)
{
Schedule = new IndexingSchedule(TimeSpan.FromDays(1))
};
// Indexers keep metadata about how much they have already indexed.
// If we already ran the indexer, it "remembers" and does not run again.
// To avoid this, reset the indexer if it exists.
try
{
await indexerClient.GetIndexerAsync(cosmosDbIndexer.Name);
// Reset the indexer if it exists.
await indexerClient.ResetIndexerAsync(cosmosDbIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
// If the indexer does not exist, 404 will be thrown.
}
await indexerClient.CreateOrUpdateIndexerAsync(cosmosDbIndexer);
Console.WriteLine("Running Azure Cosmos DB indexer...\n");
try
{
// Run the indexer.
await indexerClient.RunIndexerAsync(cosmosDbIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 429)
{
Console.WriteLine("Failed to run indexer: {0}", ex.Message);
}
Этот пример содержит простой блок try-catch, чтобы информировать о любых ошибках в процессе выполнения.
После выполнения индексатора Azure Cosmos DB полученный индекс поиска будет содержать полный набор документов с примерами данных об отелях. Но при этом поле rooms для каждого отеля будет содержать пустой массив, поскольку источник данных Azure Cosmos DB не содержит сведения о номерах. После этого программа выполняет запрос к хранилищу BLOB-объектов на загрузку данных о номерах для объединения с остальными данными.
Чтобы получить сведения о номерах, программа прежде всего настраивает Хранилище BLOB-объектов в качестве источника данных, из которого будет использовать набор JSON-файлов с большими двоичными объектами.
private static async Task CreateAndRunBlobIndexerAsync(string indexName, SearchIndexerClient indexerClient)
{
SearchIndexerDataSourceConnection blobDataSource = new SearchIndexerDataSourceConnection(
name: configuration["BlobStorageAccountName"],
type: SearchIndexerDataSourceType.AzureBlob,
connectionString: configuration["BlobStorageConnectionString"],
container: new SearchIndexerDataContainer("hotel-rooms"));
// The blob data source does not need to be deleted if it already exists,
// but the connection string might need to be updated if it has changed.
await indexerClient.CreateOrUpdateDataSourceConnectionAsync(blobDataSource);
После создания источника данных программа настраивает для него индексатор с именем hotel-rooms-blob-indexer, как показано ниже.
Большие двоичные объекты в формате JSON содержат поля ключа с именем Id вместо HotelId. В коде используется класс FieldMapping, сообщающий индексатору о необходимости направить значения поля Id в ключ документа HotelId в индексе.
Индексаторы Хранилища BLOB-объектов могут использовать IndexingParameters для определения режима анализа. Вам понадобится задать различные режимы анализа в зависимости от того, представляет большой двоичный объект один документ или несколько документов. В нашем примере каждый большой двоичный объект представляет один документ JSON, поэтому в коде используется режим анализа json. Дополнительные сведения о параметрах индексатора для анализа больших двоичных объектов JSON см. в этой статье.
Этот пример определяет для индексатора расписание, согласно которому он будет выполняться один раз в день. Вы можете удалить из вызова свойство расписания, если вам не нужно автоматически выполнять индексатор в будущем.
IndexingParameters parameters = new IndexingParameters();
parameters.Configuration.Add("parsingMode", "json");
SearchIndexer blobIndexer = new SearchIndexer(
name: "hotel-rooms-blob-indexer",
dataSourceName: blobDataSource.Name,
targetIndexName: indexName)
{
Parameters = parameters,
Schedule = new IndexingSchedule(TimeSpan.FromDays(1))
};
// Map the Id field in the Room documents to the HotelId key field in the index
blobIndexer.FieldMappings.Add(new FieldMapping("Id") { TargetFieldName = "HotelId" });
// Reset the indexer if it already exists
try
{
await indexerClient.GetIndexerAsync(blobIndexer.Name);
await indexerClient.ResetIndexerAsync(blobIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404) { }
await indexerClient.CreateOrUpdateIndexerAsync(blobIndexer);
try
{
// Run the indexer.
await searchService.Indexers.RunAsync(blobIndexer.Name);
}
catch (CloudException e) when (e.Response.StatusCode == (HttpStatusCode)429)
{
Console.WriteLine("Failed to run indexer: {0}", e.Response.Content);
}
Так как индекс уже был заполнен данными об отелях из базы данных Azure Cosmos DB, индексатор больших двоичных объектов просто обновляет существующие документы в индексе, добавляя в них сведения о номерах.
Примечание
Если в обоих источниках данных есть одинаковые поля, не являющиеся ключевыми, и данные в этих полях не совпадают, то итоговый индекс будет содержать значения от того индексатора, который выполнялся последним. В нашем примере оба источники данных содержат поля HotelName. Если по какой-либо причине данные в этом поле различаются, то для документов с одинаковым значением ключа будет сохранено значение HotelName из того источника данных, который был проиндексирован позднее.
Вы можете изучить заполненный индекс поиска после запуска программы с помощью обозревателя поиска в портал Azure.
На портале Azure откройте страницу Обзор для службы поиска и найдите в списке Индексы созданный индекс hotel-rooms-sample.

Выберите в списке индекс номера отеля. Вы увидите интерфейс обозревателя поиска для индекса. Введите запрос для поиска термина, например Luxury. Вы увидите результат поиска с хотя бы одним документом, в котором отображается список объектов номеров из массива rooms.
На ранних экспериментальных этапах разработки наиболее практический подход к итерации проектирования заключается в удалении объектов из службы "Поиск ИИ Azure" и их перестроении. Имена ресурсов являются уникальными. Удаление объекта позволяет воссоздать его с использованием того же имени.
Пример кода проверяет наличие объектов и удаляет или обновляет их, так чтобы вы могли повторно выполнить программу.
Вы также можете использовать портал Azure для удаления индексов, индексаторов и источников данных.
Если вы работаете в своей подписке, после завершения проекта целесообразно удалить созданные ресурсы, которые вам больше не потребуются. Ресурсы, которые продолжат работать, могут быть платными. Вы можете удалить ресурсы по отдельности либо удалить всю группу ресурсов.
Ресурсы можно найти и управлять ими в портал Azure, используя ссылку "Все ресурсы" или "Группы ресурсов" в области навигации слева.
Теперь, когда вы знакомы с понятием приема данных из нескольких источников, давайте рассмотрим конфигурацию индексатора, начиная с Azure Cosmos DB.
События
5 мар., 17 - 2 апр., 16
Присоединитесь к конечной 5-недельной поездке, чтобы узнать RAG!
Начните уже сегодня