Блокирование больших документов для решений поиска векторов в службе "Поиск ИИ Azure"
Секционирование больших документов на небольшие блоки может помочь вам оставаться под максимальными ограничениями ввода маркеров для внедрения моделей. Например, максимальная длина входного текста для модели Azure OpenAI с внедрением текста ada-002 составляет 8 191 токенов. Учитывая, что каждый маркер составляет около четырех символов текста для распространенных моделей OpenAI, это максимальное ограничение эквивалентно около 6000 слов текста. Если вы используете эти модели для создания внедрения, важно, чтобы входной текст оставался под ограничением. Секционирование содержимого на блоки гарантирует, что данные можно обрабатывать с помощью моделей внедрения и что данные не теряются из-за усечения.
Рекомендуется интегрировать векторизацию для встроенного фрагментирования и внедрения данных. Встроенная векторизация зависит от индексаторов, наборов навыков, навыка разделения текста и навыка внедрения, например навыка внедрения Azure OpenAI. Если вы не можете использовать встроенную векторизацию, в этой статье описываются некоторые подходы к фрагментации содержимого.
Распространенные методы блокирования
Блокирование требуется только в том случае, если исходные документы слишком большие для максимального размера входных данных, введенных моделями.
Ниже приведены некоторые распространенные методы блокирования, начиная с наиболее широко используемого метода:
Блоки фиксированного размера: определите фиксированный размер, достаточный для семантически значимых абзацев (например, 200 слов) и позволяет перекрывать (например, 10–15 % содержимого) может создавать хорошие блоки в качестве входных данных для внедрения генераторов векторов.
Блоки размера переменной размера на основе содержимого: секционирование данных на основе характеристик контента, таких как знаки препинания конца предложения, маркеры конца строки или использование функций в библиотеках обработки естественного языка (NLP). Структуру языка Markdown также можно использовать для разделения данных.
Настройте или выполните итерацию по одному из описанных выше методов. Например, при работе с большими документами можно использовать блоки размера переменной размера, но также добавить заголовок документа в блоки с середины документа, чтобы предотвратить потерю контекста.
Рекомендации по перекрытию содержимого
При фрагментации данных перекрывание небольшого количества текста между блоками может помочь сохранить контекст. Рекомендуется начинать с перекрытия примерно 10 %. Например, учитывая фиксированный размер блока 256 маркеров, вы начнете тестирование с перекрытием 25 токенов. Фактическое количество перекрытий зависит от типа данных и конкретного варианта использования, но мы обнаружили, что 10–15 % работает для многих сценариев.
Факторы для блокирования данных
Когда дело доходит до блокирования данных, думайте об этих факторах:
Форма и плотность документов. Если вам нужен нетронутый текст или фрагменты, большие блоки и блоки переменной, сохраняющие структуру предложения, могут привести к улучшению результатов.
Запросы пользователей: большие блоки и перекрывающиеся стратегии помогают сохранять контекст и семантические возможности для запросов, предназначенных для конкретных сведений.
Крупные языковые модели (LLM) имеют рекомендации по производительности для размера блока. Необходимо задать размер блока, который лучше всего подходит для всех моделей, которые вы используете. Например, если вы используете модели для суммирования и внедрения, выберите оптимальный размер блока, который работает для обоих.
Как фрагментирование вписывается в рабочий процесс
Если у вас есть большие документы, необходимо вставить шаг фрагментирования в рабочие процессы индексирования и запроса, которые разбиваются на большой текст. При использовании встроенной векторизации применяется стратегия блокирования по умолчанию с помощью навыка разделения текста. Вы также можете применить настраиваемую стратегию блокирования с помощью пользовательского навыка. Некоторые библиотеки, предоставляющие блоки, включают:
Большинство библиотек предоставляют распространенные методы блокирования для фиксированного размера, размера переменной или сочетания. Можно также указать перекрытие, дублирующее небольшое количество содержимого в каждом блоке для сохранения контекста.
Примеры фрагментирования
В следующих примерах показано, как стратегии фрагментирования применяются к Файлу PDF электронной книги НАСА в ночное время:
Пример навыка разделения текста
Встроенные фрагменты данных с помощью навыка разделения текста обычно доступны.
В этом разделе описаны встроенные блоки данных с помощью подхода на основе навыков и параметров навыка разделения текста.
Пример записной книжки для этого примера можно найти в репозитории azure-search-vector-samples .
Установите textSplitMode для разбиения содержимого на небольшие блоки:
pages(по умолчанию). Блоки состоят из нескольких предложений.sentences. Блоки состоят из отдельных предложений. То, что представляет собой "предложение", зависит от языка. На английском языке стандартное предложение заканчивается препинанием, например.или!используется. Язык управляется параметромdefaultLanguageCode.
Параметр pages добавляет дополнительные параметры:
maximumPageLengthопределяет максимальное число символов 1 или токенов 2 в каждом блоке. Разделитель текста избегает разбиения предложений, поэтому фактическое число символов зависит от содержимого.pageOverlapLengthопределяет количество символов из конца предыдущей страницы в начале следующей страницы. Если задано, это должно быть меньше половины максимальной длины страницы.maximumPagesToTakeопределяет, сколько страниц и блоков требуется принимать из документа. Значение по умолчанию — 0, что означает получение всех страниц или блоков из документа.
1 Символы не соответствуют определению маркера. Количество маркеров, измеряемых LLM, может отличаться от размера символа, измеряемого навыком разделения текста.
2 Фрагментирование маркеров доступно в предварительной версии 2024-09-01-preview и включает дополнительные параметры для указания токенизатора и любых маркеров, которые не должны быть разделены во время блокирования.
В следующей таблице показано, как выбор параметров влияет на общее количество блоков от Земли в ночной электронной книге:
textSplitMode |
maximumPageLength |
pageOverlapLength |
Общее количество блоков |
|---|---|---|---|
pages |
1000 | 0 | 172 |
pages |
1000 | 200 | 216 |
pages |
2000 | 0 | 85 |
pages |
2000 | 500 | 113 |
pages |
5000 | 0 | 34 |
pages |
5000 | 500 | 38 |
sentences |
Неприменимо | Неприменимо | 13361 |
textSplitMode pages Использование результатов в большинстве блоков с общим числом символов близко кmaximumPageLength. Количество символов фрагментов зависит от различий в том, где границы предложения попадают в блок. Длина маркера блока зависит от различий в содержимом блока.
В следующих гистограммах показано, как распределение длины символов фрагмента сравнивается с длиной токена блока для gpt-35-turbo при использовании pagestextSplitMode maximumPageLength 2000 и pageOverlapLength 500 на Земле в ночной электронной книге:
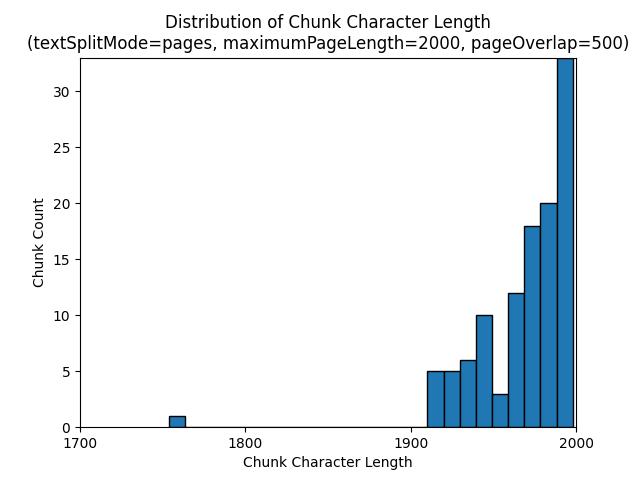
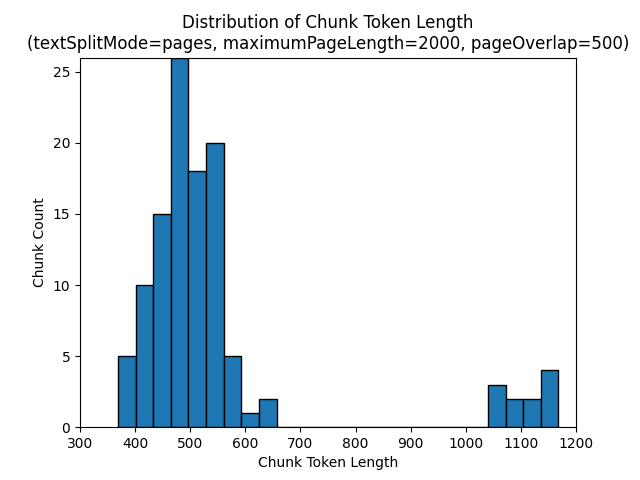
textSplitMode sentences Использование результатов в большом количестве блоков, состоящих из отдельных предложений. Эти блоки значительно меньше, чем pagesсозданные, и число маркеров блоков более тесно соответствует подсчетам символов.
Следующие гистограммы показывают, как распределение длины символов блока сравнивается с длиной токена блока для gpt-35-turbo при использовании textSplitMode sentences на Земле в ночной электронной книге:
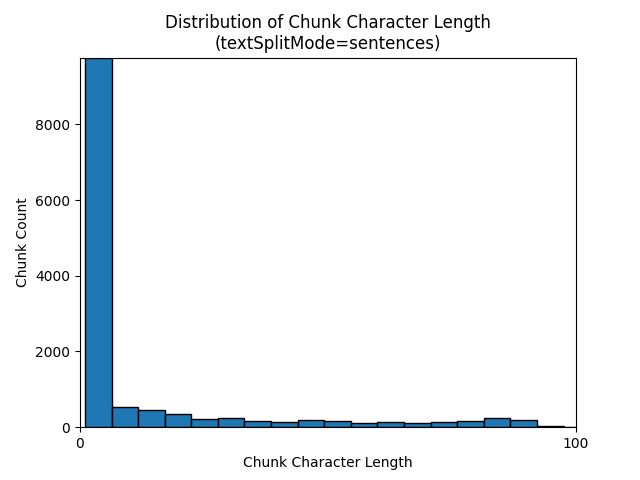
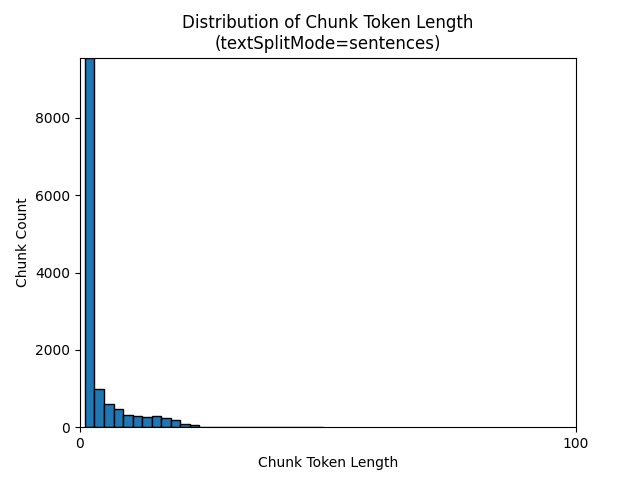
Оптимальный выбор параметров зависит от того, как будут использоваться блоки. Для большинства приложений рекомендуется начать со следующих параметров по умолчанию:
textSplitMode |
maximumPageLength |
pageOverlapLength |
|---|---|---|
pages |
2000 | 500 |
Пример фрагментирования данных LangChain
LangChain предоставляет загрузчики документов и разделители текста. В этом примере показано, как загрузить PDF-файл, получить количество маркеров и настроить разделитель текста. Получение счетчиков маркеров помогает принять обоснованное решение по размеру блока.
Пример записной книжки для этого примера можно найти в репозитории azure-search-vector-samples .
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("./data/earth_at_night_508.pdf")
pages = loader.load()
print(len(pages))
Выходные данные указывают на 200 документов или страниц в ФОРМАТЕ PDF.
Чтобы получить предполагаемое количество маркеров для этих страниц, используйте TikToken.
import tiktoken
tokenizer = tiktoken.get_encoding('cl100k_base')
def tiktoken_len(text):
tokens = tokenizer.encode(
text,
disallowed_special=()
)
return len(tokens)
tiktoken.encoding_for_model('gpt-3.5-turbo')
# create the length function
token_counts = []
for page in pages:
token_counts.append(tiktoken_len(page.page_content))
min_token_count = min(token_counts)
avg_token_count = int(sum(token_counts) / len(token_counts))
max_token_count = max(token_counts)
# print token counts
print(f"Min: {min_token_count}")
print(f"Avg: {avg_token_count}")
print(f"Max: {max_token_count}")
Выходные данные указывают на то, что на страницах нет нулевых маркеров, средняя длина токена на страницу составляет 189 маркеров, а максимальное количество маркеров любой страницы — 1583.
Знание среднего и максимального размера маркера дает представление о настройке размера блока. Хотя вы можете использовать стандартную рекомендацию 2000 символов с перекрывающимся символом 500 символов, в этом случае имеет смысл снизить число маркеров примера документа. На самом деле установка слишком большого значения перекрытия может привести к тому, что перекрытие не отображается вообще.
from langchain.text_splitter import RecursiveCharacterTextSplitter
# split documents into text and embeddings
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
is_separator_regex=False
)
chunks = text_splitter.split_documents(pages)
print(chunks[20])
print(chunks[21])
Выходные данные для двух последовательных блоков показывают текст из первого блока, перекрывающегося на второй блок. Выходные данные легко редактируются для удобства чтения.
'x Earth at NightForeword\nNASA’s Earth at Night explores the brilliance of our planet when it is in darkness. \n It is a compilation of stories depicting the interactions between science and \nwonder, and I am pleased to share this visually stunning and captivating exploration of \nour home planet.\nFrom space, our Earth looks tranquil. The blue ethereal vastness of the oceans \nharmoniously shares the space with verdant green land—an undercurrent of gentle-ness and solitude. But spending time gazing at the images presented in this book, our home planet at night instantly reveals a different reality. Beautiful, filled with glow-ing communities, natural wonders, and striking illumination, our world is bustling with activity and life.**\nDarkness is not void of illumination. It is the contrast, the area between light and'** metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
'**Darkness is not void of illumination. It is the contrast, the area between light and **\ndark, that is often the most illustrative. Darkness reminds me of where I came from and where I am now—from a small town in the mountains, to the unique vantage point of the Nation’s capital. Darkness is where dreamers and learners of all ages peer into the universe and think of questions about themselves and their space in the cosmos. Light is where they work, where they gather, and take time together.\nNASA’s spacefaring satellites have compiled an unprecedented record of our \nEarth, and its luminescence in darkness, to captivate and spark curiosity. These missions see the contrast between dark and light through the lenses of scientific instruments. Our home planet is full of complex and dynamic cycles and processes. These soaring observers show us new ways to discern the nuances of light created by natural and human-made sources, such as auroras, wildfires, cities, phytoplankton, and volcanoes.' metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
Пользовательский навык
Пример создания блоков фиксированного размера и внедрения демонстрирует создание блоков и векторного внедрения с помощью моделей внедрения Azure OpenAI . В этом примере используется пользовательский навык поиска ИИ Azure в репозитории Power Skills для упаковки шага фрагментирования.