Язык запросов Kusto в Microsoft Sentinel
Язык запросов Kusto — это язык, который используется для работы с данными в Microsoft Sentinel. Журналы, которые передаются в рабочую область, не имеют особой пользы, если их нельзя анализировать и получать важные сведения, скрытые в данных. Язык запросов Kusto не только предоставляет эффективные и гибкие возможности для извлечения этой информации, но и позволяет быстро приступить к работе благодаря своей простоте. Если у вас есть опыт работы со скриптами или базами данных, значительная часть содержимого этой статьи будут вам знакома. Если нет, не беспокойтесь: интуитивно понятная природа языка позволит быстро начать писать собственные запросы и получать ценность для вашей организации.
В этой статье рассматриваются основы языка запросов Kusto, включая некоторые из наиболее часто используемых функций и операторов, которых достаточно для написания 75–80 процентов стандартных запросов. Если вам нужны более глубокие знания или более сложные запросы, можно воспользоваться новой книгой Углубленное изучение KQL для Microsoft Sentinel (см. эту вводную запись в блоге). См. также официальную документацию по языку запросов Kusto, а также разнообразные курсы в Интернете (например, Pluralsight).
Зачем нужен язык запросов Kusto
Решение Microsoft Sentinel построено на основе службы Azure Monitor и использует ее рабочие области Log Analytics для хранения всех данных. К этим данным относятся следующие:
- данные, принятые из внешних источников в предварительно определенные таблицы с помощью соединителей данных Microsoft Sentinel;
- данные, принятые из внешних источников в пользовательские таблицы через пользовательские соединители данных, а также некоторые готовые соединители;
- данные, созданные самим решением Microsoft Sentinel в результате анализа, например оповещения, инциденты и сведения, связанные с UEBA;
- данные, переданные в Microsoft Sentinel с целью помочь в обнаружении и анализе, например веб-каналы аналитики угроз и списки видео к просмотру.
Язык запросов Kusto был разработан для службы Azure Data Explorer, поэтому он оптимизирован для поиска в больших хранилищах данных в облачной среде. Названный в честь прославленного исследователя морских глубин Жака Кусто, он предназначен для погружения в океаны ваших данных и поиска скрытых в них сокровищ.
Язык запросов Kusto также используется в Azure Monitor (и, следовательно, в Microsoft Sentinel), включая некоторые дополнительные компоненты Azure Monitor, и применяется для получения, визуализации и анализа данных в хранилищах данных Log Analytics. В Microsoft Sentinel вы используете инструменты на основе языка запросов Kusto каждый раз, когда визуализируете и анализируете данные либо ищете угрозы, независимо от того, применяете ли вы существующие правила и книги или создаете собственные.
Так как язык запросов Kusto применяется практически везде в Microsoft Sentinel, ясное понимание принципов его работы поможет вам использовать систему SIEM с гораздо большей эффективностью.
Что такое запрос
Запрос на языке запросов Kusto — это предназначенный только для чтения запрос, который обрабатывает данные и возвращает результаты — он не записывает никаких данных. Запросы работают с данными, организованными в иерархию баз данных, таблиц и столбцов, как в SQL.
Запросы формулируются на простом языке и используют модель потока данных, которая упрощает чтение, написание и автоматизацию синтаксиса. Далее мы поговорим об этом подробнее.
Запросы на языке запросов Kusto состоят из операторов, разделенных точкой с запятой. Существует множество типов операторов, но мы обсудим только два широко применяемых.
Операторы табличных выражений — это то, что мы обычно имеем в виду, когда говорим о запросах, то есть это само тело запроса. Об операторах табличных выражений важно знать то, что они принимают табличные входные данные (таблицу или другое табличное выражение) и создают табличные выходные данные. Необходим по крайней мере один из этих компонентов. Далее в этой статье будут в основном обсуждаться именно такие операторы.
Операторы let позволяют создавать и определять переменные и константы вне тела запроса, что упрощает чтение и повышает универсальность. Они являются необязательными и зависят от конкретных потребностей. Операторы такого типа мы обсудим в конце статьи.
Демонстрационная среда
Попрактиковаться в использовании операторов языка запросов Kusto, включая приведенные в этой статье, можно в демонстрационной среде Log Analytics на портале Azure. Плата за пользование этой средой не взимается, но для доступа к ней нужна учетная запись Azure.
Изучите демонстрационную среду. Как и Log Analytics в рабочей среде, ее можно использовать несколькими способами.
Выбор таблицы, на основе которой будет создан запрос. На вкладке Таблицы, открывающейся по умолчанию (обведена красным прямоугольником в левом верхнем углу), выберите таблицу из списка таблиц, сгруппированных по разделам (слева ниже). Разверните раздел, чтобы просмотреть отдельные таблицы. Кроме того, можно развернуть каждую таблицу, чтобы просмотреть все ее поля (столбцы). Если дважды щелкнуть имя таблицы или поля, они будут добавлены в месте нахождения курсора в окне запроса. Введите остальную часть запроса после имени таблицы согласно указаниям ниже.
Поиск существующего запроса для изучения или изменения. Выберите вкладку Запросы (обведена красным прямоугольником в левом верхнем углу), чтобы просмотреть список доступных запросов. Можно также нажать кнопку Запросы на панели кнопок в правом верхнем углу. Вы можете изучить запросы, которые поставляются с Microsoft Sentinel. Если дважды щелкнуть запрос, он будет добавлен полностью в месте нахождения курсора в окне запроса.
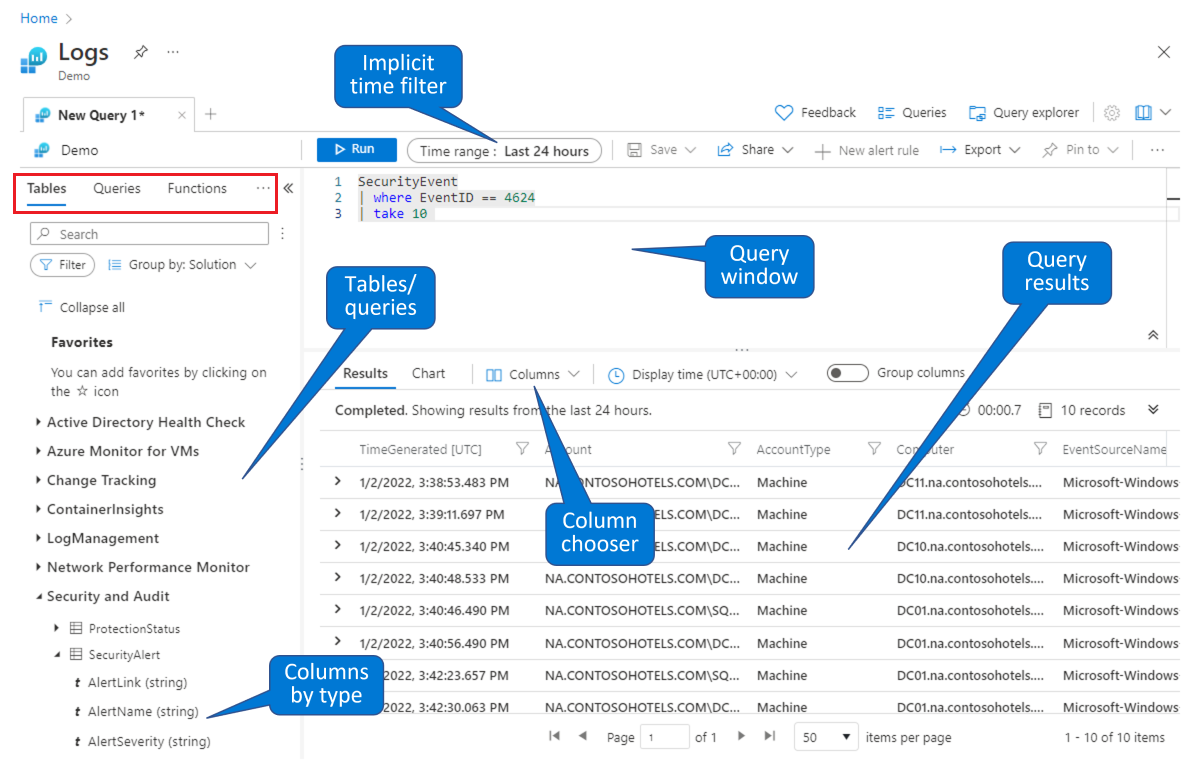
Как и в этой демонстрационной среде, вы можете запрашивать и фильтровать данные на странице Журналы в Microsoft Sentinel. Можно выбрать таблицу и просмотреть ее столбцы. Можно изменить столбцы, отображаемые по умолчанию, с помощью средства выбора столбцов, а также задать диапазон времени по умолчанию для запросов. Если диапазон времени явно определен в запросе, то фильтр времени будет недоступен (неактивен).
Структура запроса
Начать изучение языка запросов Kusto желательно с рассмотрения общей структуры запроса. Первое, на что вы обратите внимание в запросе Kusto, — это использование символа вертикальной черты (|). Структура запроса Kusto начинается с получения данных из источника и последующей их передачи по конвейеру, на каждом этапе которого данные каким-либо образом обрабатываются, а затем передаются на следующий этап. В конце конвейера будет получен окончательный результат. Таким образом, конвейер выглядит так:
Get Data | Filter | Summarize | Sort | Select
Концепция передачи данных по конвейеру делает структуру интуитивно понятной, так как на каждом шаге можно легко представить, что происходит с данными.
Чтобы проиллюстрировать это, давайте рассмотрим следующий запрос, который смотрит на журналы входа в Microsoft Entra. В каждой строке можно увидеть ключевые слова, которые указывают, что происходит с данными. В каждой строке дается описание соответствующего этапа конвейера в виде комментария.
Примечание.
Комментарии можно добавлять к любой строке запроса, предваряя их двойной косой чертой (//).
SigninLogs // Get data
| evaluate bag_unpack(LocationDetails) // Ignore this line for now; we'll come back to it at the end.
| where RiskLevelDuringSignIn == 'none' // Filter
and TimeGenerated >= ago(7d) // Filter
| summarize Count = count() by city // Summarize
| sort by Count desc // Sort
| take 5 // Select
Поскольку выходные данные каждого этапа служат в качестве входных данных для следующего этапа, порядок этапов может влиять на результаты запроса и его производительность. Важно выстраивать очередность этапов с учетом того, что вы хотите получить в результате.
Совет
- На практике обычно желательно фильтровать данные на ранних этапах, чтобы далее по конвейеру передавались только нужные данные. Это значительно повысит производительность и позволит избежать случайного включения ненужных данных в этапы формирования сводных данных.
- В этой статье будет приведен ряд других полезных рекомендаций. Более полный список см. в статье Рекомендации по запросам.
Надеемся, вы получили ясное представление об общей структуры запроса на языке запросов Kusto. Теперь давайте рассмотрим операторы, из которых строится запрос.
Типы данных
Прежде чем переходить к операторам запроса, давайте вкратце разберем типы данных. Как и в большинстве языков, тип данных определяет возможные действия и вычислительные операции со значением. Например, со значением типа string нельзя выполнять арифметические операции.
В языке запросов Kusto большинство типов данных соответствуют стандартным соглашениям, и их названия вам могут быть знакомы. Полный список представлен в таблице ниже.
Таблица типов данных
| Тип | Дополнительные имена | Эквивалентный тип .NET |
|---|---|---|
bool |
Boolean |
System.Boolean |
datetime |
Date |
System.DateTime |
dynamic |
System.Object |
|
guid |
uuid, uniqueid |
System.Guid |
int |
System.Int32 |
|
long |
System.Int64 |
|
real |
Double |
System.Double |
string |
System.String |
|
timespan |
Time |
System.TimeSpan |
decimal |
System.Data.SqlTypes.SqlDecimal |
Хотя большинство типов данных являются стандартными, такие типы, как dynamic, timespan и guid, могут оказаться для вас новыми.
Тип dynamic по своей структуре схож с JSON, но с одним ключевым отличием: он позволяет хранить типы данных, характерные для языка запросов Kusto, чего не может традиционный тип JSON. Например, это может быть вложенное значение dynamic или значение timespan. Вот пример типа dynamic:
{
"countryOrRegion":"US",
"geoCoordinates": {
"longitude":-122.12094116210936,
"latitude":47.68050003051758
},
"state":"Washington",
"city":"Redmond"
}
timespan — это тип данных, который ссылается на меру времени, например часы, дни или секунды. Не путайте тип timespan с типом datetime, значением которого является фактическая дата и время, а не мера времени. В таблице ниже приведен список суффиксов timespan.
Суффиксы timespan
| Function | Description |
|---|---|
D |
days |
H |
hours |
M |
minutes |
S |
с |
Ms |
мс |
Microsecond |
микросекунды |
Tick |
наносекунды |
guid — это тип данных, представляющий 128-разрядный глобальный уникальный идентификатор, имеющий стандартный формат [8]-[4]-[4]-[4]-[12], где каждое [число] представляет число символов, а каждый символ может находиться в диапазоне 0–9 или a–f.
Примечание.
В языке запросов Kusto есть как табличные, так и скалярные операторы. Далее в этой статье под словом "оператор", скорее всего, будет иметься в виду табличный оператор, если не указано иное.
Получение, ограничение, сортировка и фильтрация данных
Основной словарь языка запросов Kusto, который позволяет выполнять подавляющее большинство задач, — это набор операторов для фильтрации, сортировки и выбора данных. Для выполнения остальных задач потребуется расширить знания языка, чтобы удовлетворить более сложные потребности. Давайте немного остановимся на некоторых командах, использовавшихся в примере выше, и рассмотрим операторы take, sort и where.
Мы обсудим использование каждого из этих операторов в предыдущем примере SigninLogs и дадим полезный совет или рекомендацию.
Получение данных
В первой строке любого базового запроса указывается, с какой таблицей необходимо работать. В случае с Microsoft Sentinel, скорее всего, это будет имя типа журналов в рабочей области, например SigninLogs, SecurityAlert или CommonSecurityLog. Например:
SigninLogs
Обратите внимание, что в языке запросов Kusto в именах журналов учитывается регистр, поэтому SigninLogs и signinLogs — это не одно и то же. Тщательно выбирайте имена для пользовательских журналов, чтобы их можно было легко идентифицировать и нельзя было спутать с другими журналами.
Ограничение данных: take / limit
Оператор take (и идентичный оператор limit) используется для ограничения результатов: возвращается заданное число строк. За ним следует целое число, указывающее количество возвращаемых строк. Как правило, этот оператор используется в конце запроса после определения порядка сортировки. В таком случае он возвращает заданное число строк с начала отсортированного набора.
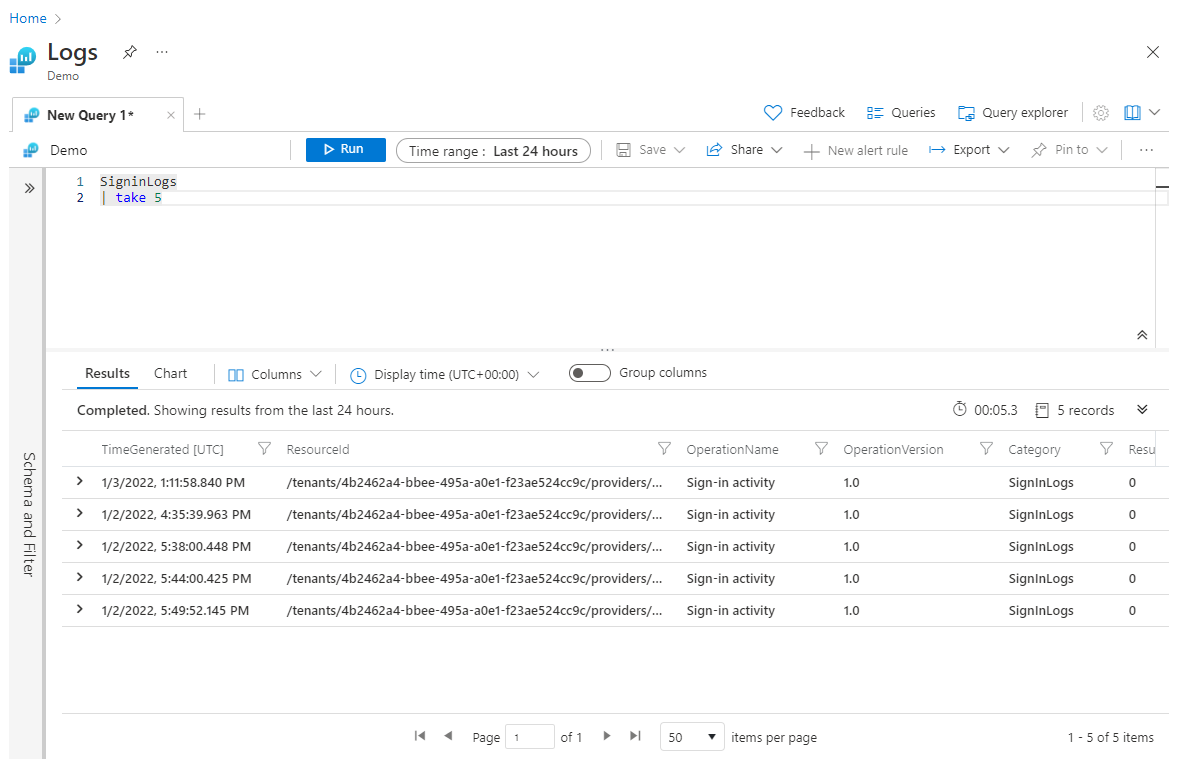
Оператор take может быть полезно использовать ранее в запросе в целях тестирования, чтобы не возвращать большие наборы данных. Однако если операция take находится перед всеми операциями sort, take возвращает строки, выбранные случайным образом, причем при каждом выполнении запроса наборы строк могут быть разными. Вот пример использования оператора take:
SigninLogs
| take 5
Совет
Если вы только начинаете создавать запрос и еще не знаете, каким он будет в итоге, может быть полезно поместить оператор take в начале, чтобы искусственно ограничить набор данных для ускорения обработки и проведения экспериментов. Когда вы будете удовлетворены запросом, можно будет удалить начальный шаг take.
Сортировка данных: sort / order
Оператор sort (и идентичный оператор order) служит для сортировки данных по указанному столбцу. В приведенном ниже примере результаты упорядочиваются по столбцу TimeGenerated в порядке убывания с помощью параметра desc, так что наибольшие значения будут находиться в начале. Для сортировку по возрастанию используется параметр asc.
Примечание.
По умолчанию сортировка выполняется по убыванию, поэтому порядок необходимо указывать, только если требуется отсортировать значения по возрастанию. Однако указание направления сортировки в любом случае делает ваш запрос более удобочитаемым.
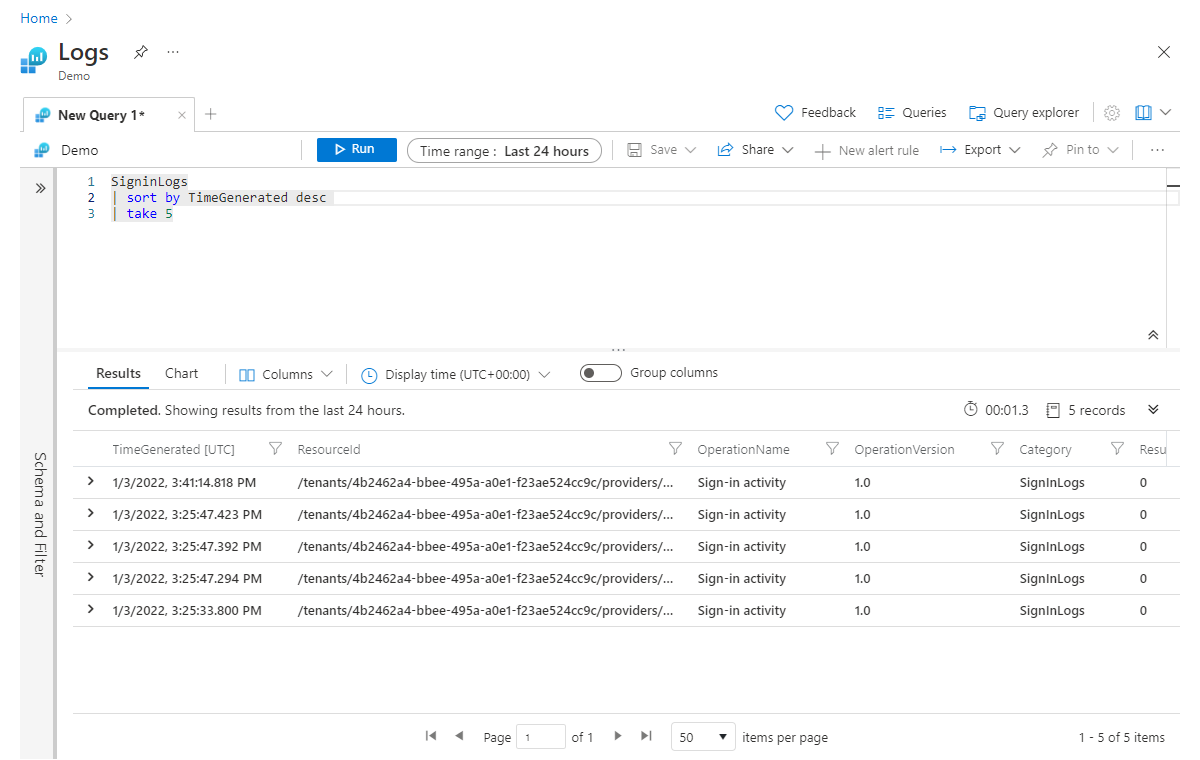
SigninLogs
| sort by TimeGenerated desc
| take 5
Как упоминалось ранее, оператор sort помещается перед оператором take. Сначала необходимо выполнить сортировку, чтобы получить нужные пять записей.
Top
Оператор top позволяет объединить операции sort и take в один оператор:
SigninLogs
| top 5 by TimeGenerated desc
В случаях, когда две или более записей имеют одинаковое значение в столбце, по которому выполняется сортировка, можно добавить дополнительные столбцы для сортировки. Дополнительные столбцы сортировки добавляются в виде списка с разделителями-запятыми после первого столбца сортировки, но перед ключевым словом порядка сортировки. Например:
SigninLogs
| sort by TimeGenerated, Identity desc
| take 5
Теперь, если значение в столбце TimeGenerated одинаково у нескольких записей, будет предпринята попытка выполнить сортировку по значениям в столбце Identity.
Примечание.
Когда следует использовать sort и take, а когда — top
Если сортировка выполняется только по одному полю, используйте
top, так при этом производительность будет выше, чем при использовании сочетанияsortиtake.Если необходимо выполнить сортировку более чем по одному полю (как в последнем примере выше), оператор
topне дает такой возможности, поэтому необходимо использоватьsortиtake.
Фильтрация данных: where
Оператор where является, пожалуй, наиболее важным, поскольку именно он позволяет работать только с тем подмножеством данных, которые актуальны в конкретной ситуации. Данные следует фильтровать как можно раньше в запросе, так как это позволит повысить производительность запроса за счет уменьшения объема данных, которые будут обрабатываться в последующих шагах. Кроме того, вычисления будут выполняться только на основе нужных данных. Дополнительные сведения см. в этом примере:
SigninLogs
| where TimeGenerated >= ago(7d)
| sort by TimeGenerated, Identity desc
| take 5
В операторе where указываются переменная, оператор сравнения (скалярный) и значение. В данном случае мы использовали >=, чтобы указать, что значение в столбце TimeGenerated должно быть больше (то есть позже) или равно семи дням назад.
В языке запросов Kusto есть два типа операторов сравнения: строковые и числовые. В таблице ниже приведен полный список числовых операторов.
Числовые операторы
| Operator | Description |
|---|---|
+ |
Дополнение |
- |
Вычитание |
* |
Умножение |
/ |
Подразделение |
% |
Остаток от деления |
< |
Меньше |
> |
Больше |
== |
Равно |
!= |
Не равно |
<= |
Меньше или равно |
>= |
Больше или равно |
in |
Соответствует одному из элементов |
!in |
Не равно ни одному из элементов |
Список строковых операторов гораздо длиннее, так как он включает перестановки для учета регистра, расположения подстрок, префиксов, суффиксов и многого другого. Оператор == является как числовым, так и строковым, то есть его можно использовать как для чисел, так и для текста. Например, оба следующих оператора where будут допустимыми:
| where ResultType == 0| where Category == 'SignInLogs'
Совет
Рекомендация. В большинстве случаев вам, вероятно, будет необходимо фильтровать данные по нескольким столбцам или фильтровать один и тот же столбец несколькими способами. В таких случаях следует помнить две рекомендации.
Несколько операторов where можно объединить в один шаг, используя ключевое слово and. Например:
SigninLogs
| where Resource == ResourceGroup
and TimeGenerated >= ago(7d)
При объединении нескольких фильтров в одном операторе where с помощью ключевого слова and, как показано выше, производительность будет выше, если в начале будут фильтры, которые ссылаются только на один столбец. Таким образом, приведенный выше запрос лучше записать так:
SigninLogs
| where TimeGenerated >= ago(7d)
and Resource == ResourceGroup
В этом примере первый фильтр ссылается на один столбец (TimeGenerated), а второй — на два столбца (Resource и ResourceGroup).
Получение сводных данных
Summarize — один из наиболее важных табличных операторов в языке запросов Kusto, но его освоение может представлять трудность, если вы еще не имеете опыта работы с языками запросов в целом. Задача summarize состоит в том, чтобы получить таблицу данных и вывести новую таблицу, агрегированную по одному или нескольким столбцам.
Структура оператора summarize
Базовая структура оператора summarize выглядит так:
| summarize <aggregation> by <column>
Например, следующий запрос возвращает количество записей для каждого значения CounterName в таблице Perf:
Perf
| summarize count() by CounterName
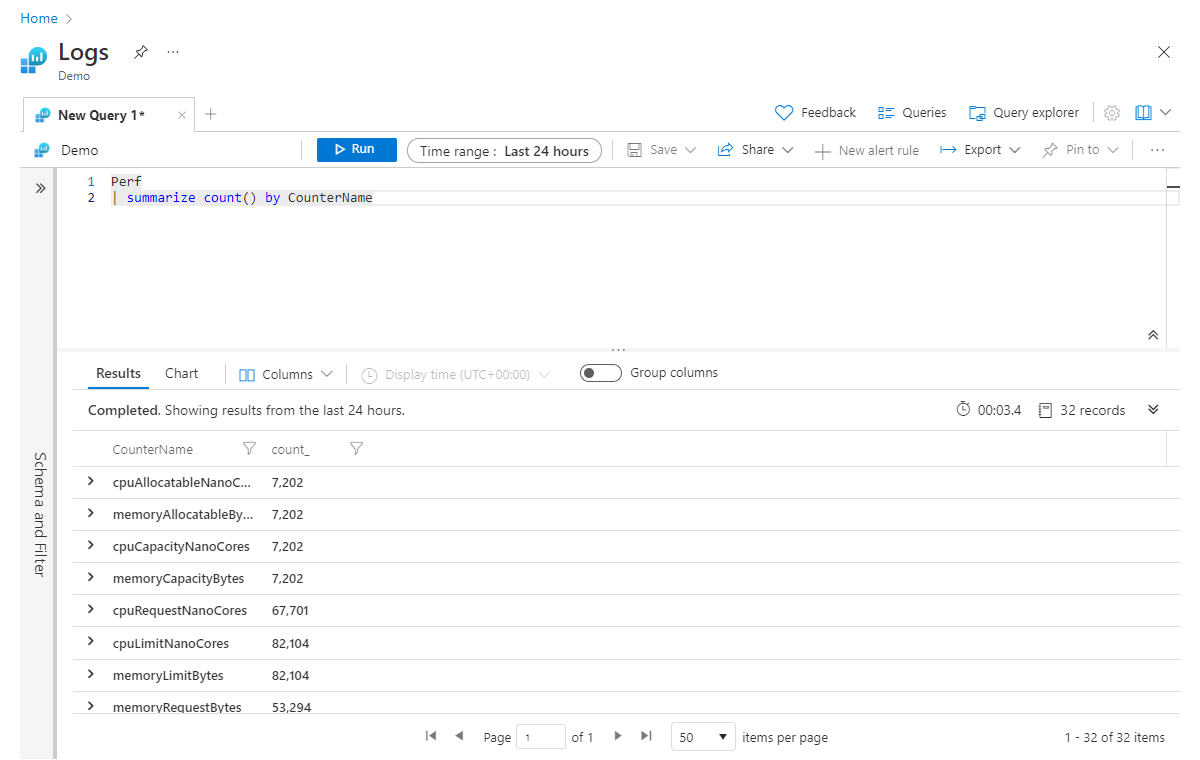
Поскольку выходные данные summarize являются новой таблицей, все столбцы, не указанные явно в операторе summarize, не передаются далее по конвейеру. Чтобы проиллюстрировать этот принцип, рассмотрим следующий пример:
Perf
| project ObjectName, CounterValue, CounterName
| summarize count() by CounterName
| sort by ObjectName asc
Во второй строке мы указываем, что нас интересуют только столбцы ObjectName, CounterValue и CounterName. Затем мы производим агрегирование, чтобы получить число записей в столбце CounterName, и, наконец, пытаемся отсортировать данные в порядке возрастания по столбцу ObjectName. К сожалению, этот запрос завершается ошибкой (с сообщением о том, что столбец ObjectName неизвестен), так как при агрегировании мы включили в новую таблицу только столбцы Count и CounterName. Чтобы избежать этой ошибки, можно просто добавить ObjectName в конец шага summarize, как в следующем примере:
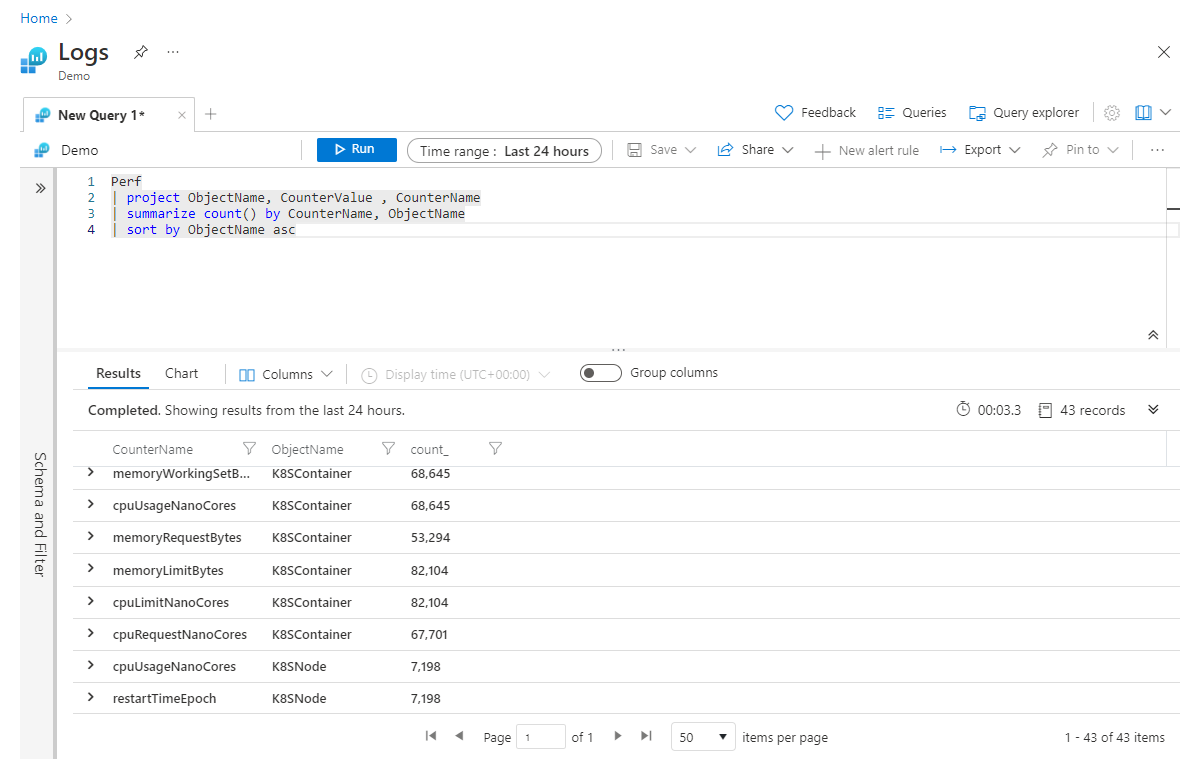
Perf
| project ObjectName, CounterValue , CounterName
| summarize count() by CounterName, ObjectName
| sort by ObjectName asc
Строка summarize означает следующее: "суммировать количество записей в CounterName и сгруппировать по ObjectName". Можно продолжить добавление столбцов через запятые в конец оператора summarize.
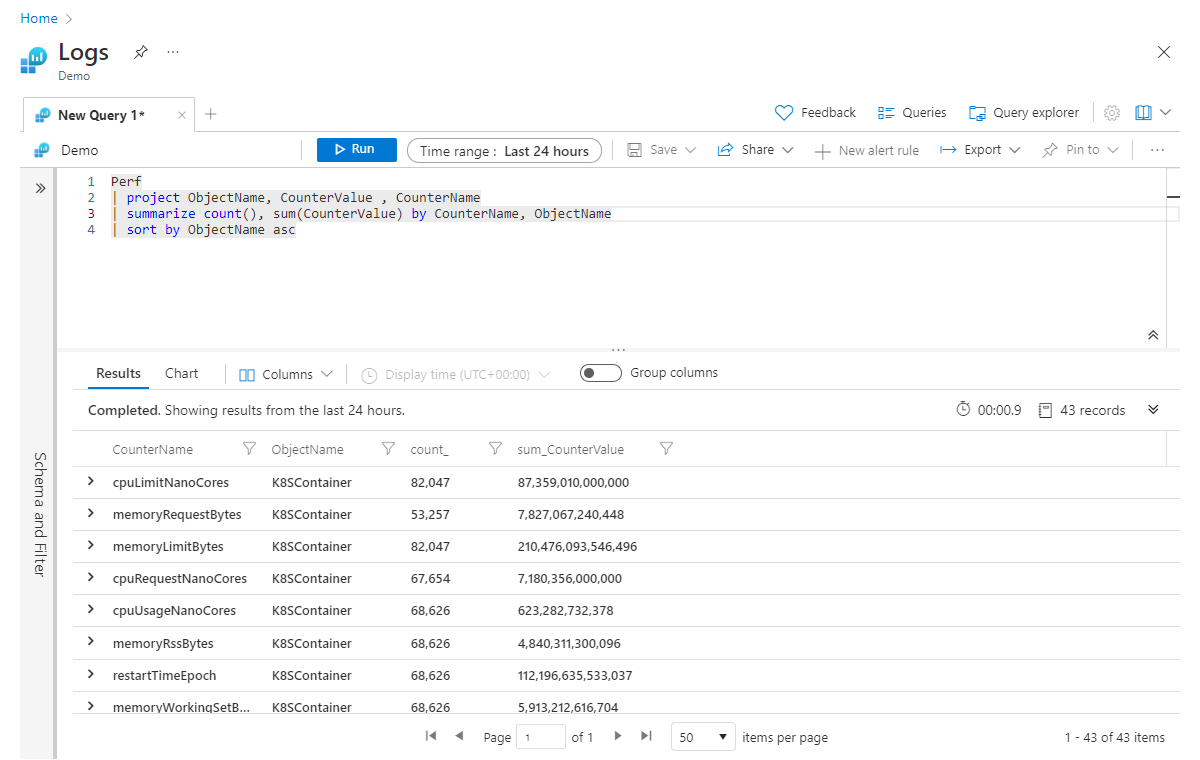
Продолжим предыдущий пример: если нам нужно агрегировать несколько столбцов одновременно, это можно сделать, добавив агрегаты в оператор summarize через запятую. В следующем примере мы получаем не только число всех записей, но и сумму значений в столбце CounterValue по всем записям (которые соответствуют любым фильтрам в запросе):
Perf
| project ObjectName, CounterValue , CounterName
| summarize count(), sum(CounterValue) by CounterName, ObjectName
| sort by ObjectName asc
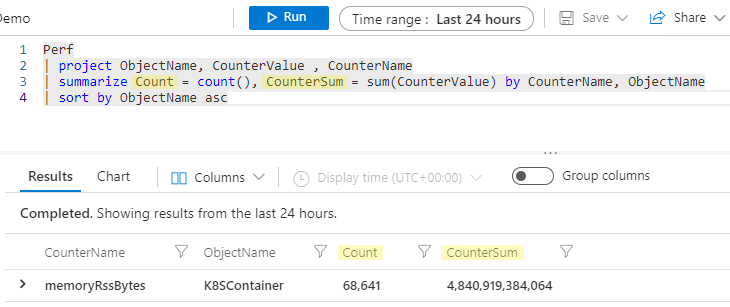
Переименование агрегированных столбцов
Самое время поговорить об именах для агрегированных столбцов. В начале этого раздела было сказано, что оператор summarize принимает таблицу данных и создает новую таблицу, причем далее по конвейеру передаются только столбцы, указанные в операторе summarize. Таким образом, если бы вы выполняли приведенный выше пример, итоговыми столбцами агрегирования были бы count_ и sum_CounterValue.
Подсистема Kusto автоматически создает имя столбца без вашего участия, но зачастую желательно присвоить новому столбцу более понятное имя. Вы можете легко переименовать столбец в операторе summarize, указав новое имя, за которым следует знак = и агрегат:
Perf
| project ObjectName, CounterValue , CounterName
| summarize Count = count(), CounterSum = sum(CounterValue) by CounterName, ObjectName
| sort by ObjectName asc
Теперь агрегированные столбцы будут называться Count и CounterSum.
У оператора summarize гораздо больше возможностей, и мы не сможем рассказать здесь о всех них, но вам следует уделить время их изучению, поскольку это ключевой компонент любого анализа данных в Microsoft Sentinel.
Справка по агрегированию
Существует множество функций агрегирования, но чаще всего применяются sum(), count() и avg(). Ниже приведен частичный список (полный список см. здесь).
Агрегатные функции
| Function | Description |
|---|---|
arg_max() |
Возвращает одно или несколько выражений, если аргумент достигает максимума |
arg_min() |
Возвращает одно или несколько выражений, если аргумент достигает минимума |
avg() |
Возвращает среднее значение в группе |
buildschema() |
Возвращает минимальную схему, которая допускает все значения динамических входных данных |
count() |
Возвращает число для группы |
countif() |
Возвращает число с предикатом для группы |
dcount() |
Возвращает приблизительное число уникальных элементов в группе |
make_bag() |
Возвращает контейнер свойств динамических значений в группе |
make_list() |
Возвращает список всех значений в группе |
make_set() |
Возвращает набор несовпадающих значений в группе |
max() |
Возвращает максимальное значение в группе |
min() |
Возвращает минимальное значение в группе |
percentiles() |
Возвращает приблизительное значение процентиля группы |
stdev() |
Возвращает стандартное отклонение в группе |
sum() |
Возвращает сумму элементов в группе |
take_any() |
Возвращает случайное непустое значение в группе |
variance() |
Возвращает вариантность в группе. |
Выбор: добавление и удаление столбцов
При работе с запросами может оказаться так, что у вас больше информации, чем нужно (то есть в таблице слишком много столбцов). Либо наоборот, вам может потребоваться больше информации, чем у вас есть (то есть необходимо добавить новый столбец, содержащий результаты анализа других столбцов). Рассмотрим несколько основных операторов для операций со столбцами.
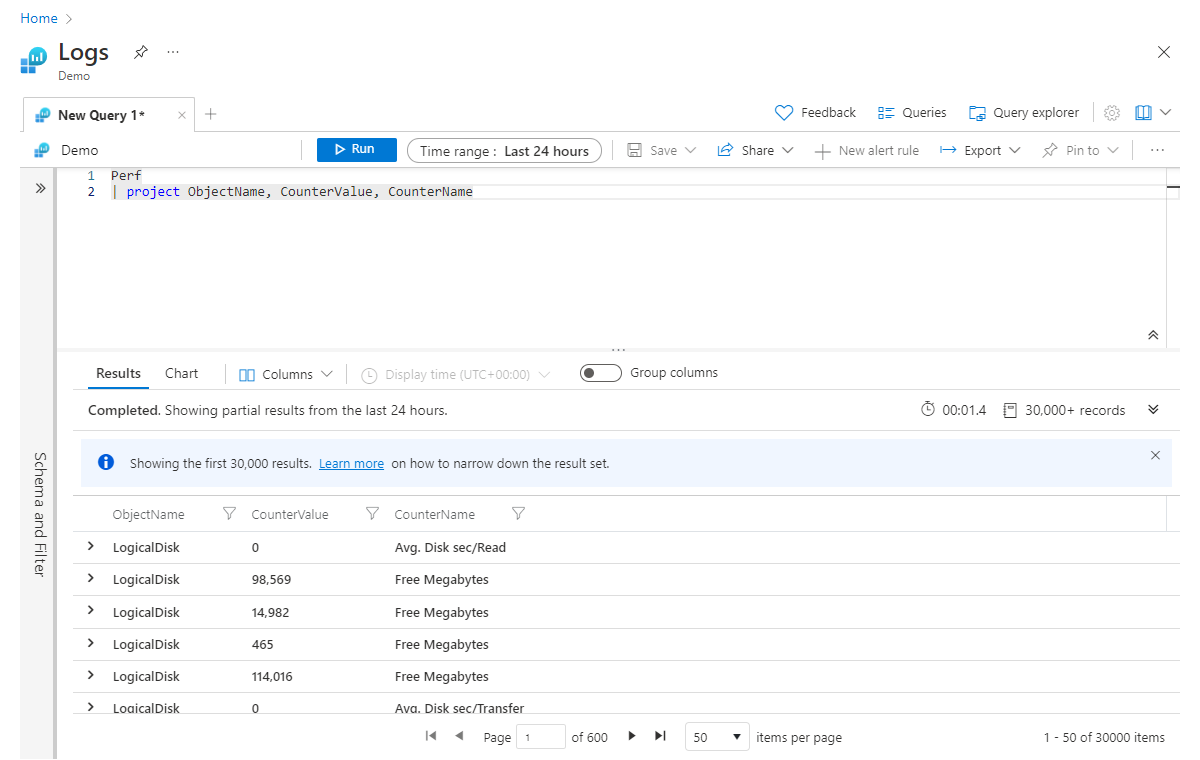
Project и project-away
Оператор project примерно соответствует оператору select во многих других языках. Он позволяет выбирать столбцы, которые следует оставить. Возвращаться столбцы будут в том порядке, в каком они перечислены в операторе project, как показано в следующем примере:
Perf
| project ObjectName, CounterValue, CounterName
Как можно себе представить, при работе с очень большими наборами данных может потребоваться оставить много столбцов. Чтобы указать их все по имени, нужно будет вводить много текста. Для таких случаев есть оператор project-away, который позволяет указать, какие столбцы следует исключить, а не оставить:
Perf
| project-away MG, _ResourceId, Type
Совет
Может быть полезно использовать оператор project в двух местах в запросе: в начале и еще раз в конце. Использование project на раннем этапе запроса позволяет повысить производительность за счет удаления больших фрагментов данных, которые не нужно передавать по конвейеру. Повторное использование в конце позволяет избавиться от столбцов, которые могли быть созданы на предыдущих шагах и не требуются в выходных данных.
Расширить
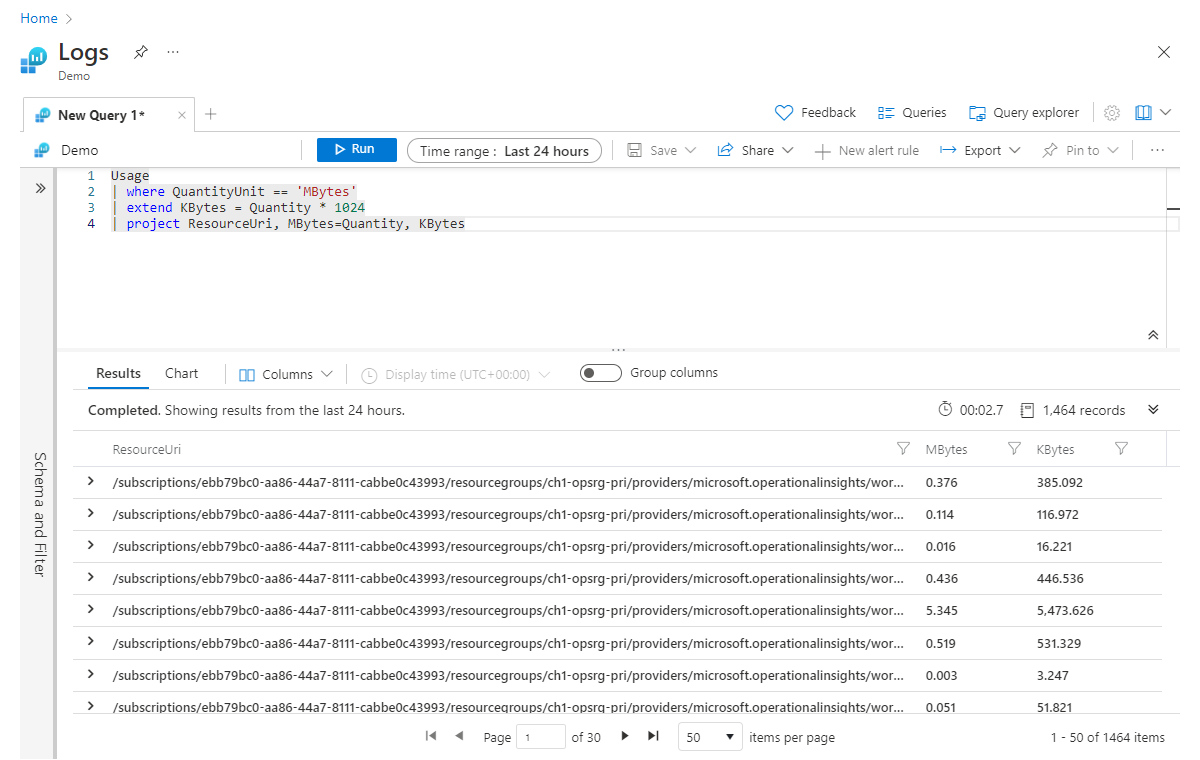
Оператор extend служит для создания нового вычисляемого столбца. Это может быть полезно, если требуется выполнить вычисление на основе существующих столбцов и просмотреть выходные данные для каждой строки. Рассмотрим простой пример, в котором вычисляется новый столбец с именем Kbytes путем умножения значения МБ (в существующем столбце Quantity) на 1024.
Usage
| where QuantityUnit == 'MBytes'
| extend KBytes = Quantity * 1024
| project ResourceUri, MBytes=Quantity, KBytes
В последней строке в операторе project столбец Quantity переименовывается в Mbytes, чтобы можно было легко определить, какая единица измерения относится к каждому столбцу.
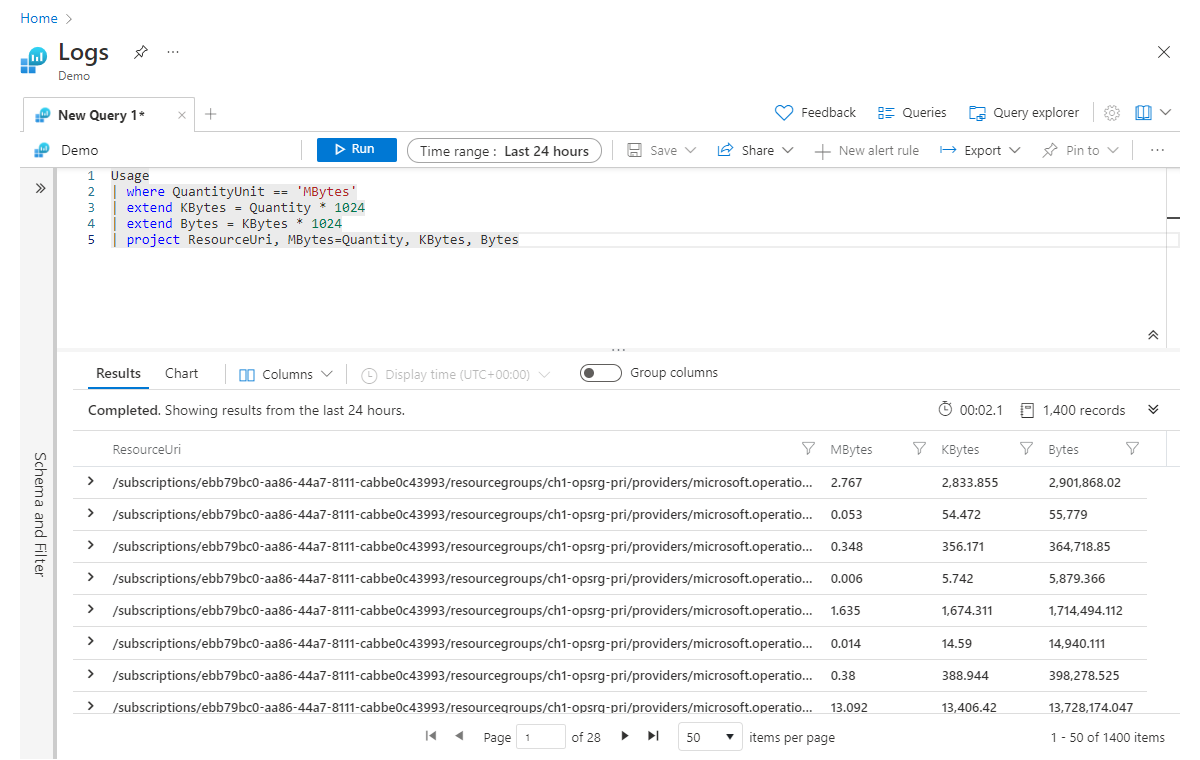
Стоит отметить, что extend также работает с уже вычисленными столбцами. Например, можно добавить еще один столбец с именем Bytes, который вычисляется на основе Kbytes:
Usage
| where QuantityUnit == 'MBytes'
| extend KBytes = Quantity * 1024
| extend Bytes = KBytes * 1024
| project ResourceUri, MBytes=Quantity, KBytes, Bytes
Соединение таблиц
Значительная часть работы в Microsoft Sentinel может быть выполнена с использованием одного типа журналов, но бывают случаи, когда необходимо сопоставить данные или выполнить поиск по другому набору данных. Как и большинство языков запросов, язык запросов Kusto предлагает несколько операторов для выполнения различных типов объединений. В этом разделе мы рассмотрим наиболее часто используемые операторы: union и join.
Union
Оператор union просто принимает две или более таблиц и возвращает все строки. Например:
OfficeActivity
| union SecurityEvent
Этот запрос возвращает все строки из таблиц OfficeActivity и SecurityEvent. Union предлагает несколько параметров, которые можно использовать для настройки объединения. Два наиболее полезных — withsource и kind:
OfficeActivity
| union withsource = SourceTable kind = inner SecurityEvent
Параметр withsource позволяет указать имя нового столбца, значение которого в определенной строке будет именем таблицы, из которой получена строка. В приведенном выше примере мы назвали столбец SourceTable, и в зависимости от строки значением будет либо OfficeActivity, либо SecurityEvent.
Еще был указан параметр kind, который имеет два значения: inner или outer. В приведенном выше примере мы указали inner, то есть во время объединения будут оставлены только те столбцы, которые есть в обеих таблицах. Если бы мы указали outer (то есть значение по умолчанию), были бы возвращены все столбцы из обеих таблиц.
Присоединение
Оператор join работает аналогично union за исключением того, что вместо объединения таблиц для создания новой таблицы объединяются строки. Как и в большинстве языков баз данных, существует несколько типов объединений. Общий синтаксис для join имеет следующий вид:
T1
| join kind = <join type>
(
T2
) on $left.<T1Column> == $right.<T2Column>
После оператора join мы указываем kind, то есть нужный тип объединения, за которым следует открывающая круглая скобка. В круглых скобках указывается таблица, которую необходимо объединить, а также другие необходимые операторы запроса для этой таблицы. После закрывающей скобки мы используем ключевое слово on, за которым следуют левый (ключевое слово $left.<имяСтолбца>) и правый ($right.<имяСтолбца>) столбцы, разделенные оператором ==. Вот пример кода внутреннего соединения:
OfficeActivity
| where TimeGenerated >= ago(1d)
and LogonUserSid != ''
| join kind = inner (
SecurityEvent
| where TimeGenerated >= ago(1d)
and SubjectUserSid != ''
) on $left.LogonUserSid == $right.SubjectUserSid
Примечание.
Если имена объединяемых столбцов в двух таблицах совпадают, использовать $left и $right не нужно. Вместо этого можно просто указать имя столбца. Однако использование $left и $right делает синтаксис более явным и считается более правильным.
Для справки в таблице ниже приведен список доступных типов объединений.
Типы соединений
| Тип соединения | Description |
|---|---|
inner |
Возвращает одну строку для каждого сочетания совпадающих строк из обеих таблиц. |
innerunique |
Возвращает строки из левой таблицы с уникальными значениями в связанном поле, которые имеют соответствие в правой таблице. Это тип объединения по умолчанию, если не указан иной. |
leftsemi |
Возвращает из левой таблицы все записи, имеющие совпадение в правой таблице. Возвращаются столбцы только из левой таблицы. |
rightsemi |
Возвращает из правой таблицы все записи, имеющие совпадение в левой таблице. Возвращаются только столбцы из правой таблицы. |
leftanti/leftantisemi |
Возвращает из левой таблицы все записи, не имеющие совпадения в правой таблице. Возвращаются столбцы только из левой таблицы. |
rightanti/rightantisemi |
Возвращает из правой таблицы все записи, не имеющие совпадения в левой таблице. Возвращаются только столбцы из правой таблицы. |
leftouter |
Возвращает все записи из левой таблицы. Для записей, не имеющих совпадений в правой таблице, ячейки будут иметь значение NULL. |
rightouter |
Возвращает все записи из правой таблицы. Для записей, не имеющих совпадений в левой таблице, ячейки будут иметь значение NULL. |
fullouter |
Возвращает все записи из левой и правой таблиц независимо от совпадения. Несовпадающие значения будут иметь значение NULL. |
Совет
Рекомендуется помещать самую маленькую таблицу слева. В некоторых случаях соблюдение этого правила может существенно повысить производительность в зависимости от типов выполняемых объединений и размера таблиц.
Вычислить
Как вы помните, в первом примере в одной из строк был оператор evaluate. Оператор evaluate используется реже, чем рассмотренные ранее. Однако изучению принципов работы оператора evaluate также стоит посвятить время. Приведем еще раз тот первый запрос, где evaluate встречается во второй строке.
SigninLogs
| evaluate bag_unpack(LocationDetails)
| where RiskLevelDuringSignIn == 'none'
and TimeGenerated >= ago(7d)
| summarize Count = count() by city
| sort by Count desc
| take 5
Этот оператор позволяет вызывать доступные подключаемые модули (по сути встроенные функции). Многие из этих подключаемых модулей предназначены для обработки и анализа данных, например autocluster, diffpatterns и sequence_detect. Они позволяют проводить расширенный анализ и выявлять статистические аномалии и выбросы.
В приведенном выше примере используется подключаемый модуль bag_unpack, который позволяет легко получить блок данных типа dynamic и преобразовать его в столбцы. Помните, что dynamic — это тип данных, который очень похож на JSON, как показано в следующем примере:
{
"countryOrRegion":"US",
"geoCoordinates": {
"longitude":-122.12094116210936,
"latitude":47.68050003051758
},
"state":"Washington",
"city":"Redmond"
}
В этом случае нам нужно суммировать данные по городу, но city (город) содержится в качестве свойства в столбце LocationDetails. Чтобы использовать свойство city в запросе, необходимо сначала преобразовать его в столбец с помощью bag_unpack.
Напомним, что наш исходный конвейер состоял из следующих этапов:
Get Data | Filter | Summarize | Sort | Select
Теперь с добавлением оператора evaluate в конвейере появляется еще один этап:
Get Data | Parse | Filter | Summarize | Sort | Select
Существует множество других примеров операторов и функций, которые можно использовать для анализа источников данных и их перевода в более удобный для восприятия и обработки формат. Ознакомиться с ними и другими особенностями языка запросов Kusto можно в полной документации и книге.
Инструкции let
Теперь, когда мы рассмотрели многие основные операторы и типы данных, давайте перейдем к оператору let, который помогает упростить понимание, изменение и обслуживание запросов.
Оператор let позволяет создать и задать переменную либо присвоить имя выражению. Выражением может быть как отдельное значение, так и целый запрос. Вот простой пример.
let aWeekAgo = ago(7d);
SigninLogs
| where TimeGenerated >= aWeekAgo
Здесь мы указали имя aWeekAgo и присвоили ему выходные данные функции timespan, которая возвращает значение типа datetime. Затем мы завершили оператор let точкой с запятой. Теперь у нас есть новая переменная с именем aWeekAgo, которую можно использовать в любом месте запроса.
Как мы только что упоминали, оператор let можно использовать применительно ко всему запросу и присвоить результату имя. Так как результаты запросов, будучи табличными выражениями, могут использоваться в качестве входных данных других запросов, этот именованный результат можно рассматривать как таблицу для выполнения другого запроса к ней. Ниже предыдущий пример немного изменен:
let aWeekAgo = ago(7d);
let getSignins = SigninLogs
| where TimeGenerated >= aWeekAgo;
getSignins
В этом случае мы создали второй оператор let, заключающий весь запрос в новую переменную с именем getSignins. Как и раньше, мы завершаем этот оператор let точкой с запятой. Затем мы вызываем эту переменную в последней строке, чтобы выполнить запрос. Обратите внимание, что во второй инструкции let мы смогли использовать переменную aWeekAgo. Это связано с тем, что она была указана в предыдущей строке. Если бы мы поменяли местами операторы let, так что переменная getSignins оказалась бы в начале, произошла бы ошибка.
Теперь мы можем использовать getSignins в качестве основы для другого запроса (в том же окне):
let aWeekAgo = ago(7d);
let getSignins = SigninLogs
| where TimeGenerated >= aWeekAgo;
getSignins
| where level >= 3
| project IPAddress, UserDisplayName, Level
Операторы let позволяют более эффективно и гибко организовывать запросы. Операторы let можно использовать для определения скалярных и табличных значений, а также для создания пользовательских функций. Они оказываются очень кстати при организации сложных запросов со множеством объединений.
Следующие шаги
Хотя в этой статье была затронута лишь вершина айсберга, теперь у вас есть необходимая основа. Мы рассмотрели элементы, которые вы будете использовать в ходе работы с Microsoft Sentinel чаще всего.
Книга "Углубленное изучение KQL для Microsoft Sentinel"
Воспользуйтесь книгой по языку запросов Kusto прямо в Microsoft Sentinel: Углубленное изучение KQL для Microsoft Sentinel. Она содержит пошаговые инструкции и множество примеров ситуаций, которые, скорее всего, будут встречаться вам в ходе повседневной работы по обеспечению безопасности. В ней также приводится много готовых к использованию примеров правил аналитики, книг, правил поиска и других элементов с запросами Kusto. Запустите эту книгу из колонки Книги в Microsoft Sentinel.
Книга "Углубленное изучение KQL" — освойте все тонкости языка KQL — отличная запись в блоге, в которой показано, как использовать эту книгу.
Дополнительные ресурсы
Ознакомьтесь с этой коллекцией материалов для обучения и развития навыков, чтобы расширить и углубить свои познания о языке запросов Kusto.