Руководство по проектированию для использования реплицированных таблиц в пуле Synapse SQL
В данной статье представлены рекомендации по проектированию реплицированных таблиц в схеме пула Synapse SQL. Данные рекомендации позволяют повысить производительность запросов за счет уменьшения перемещения данных и упрощения запросов.
Необходимые компоненты
В этой статье предполагается, что вы знакомы с основными понятиями, связанными с распределением данных и перемещением данных в пуле SQL. Дополнительные сведения см. в статье об архитектуре.
При проектировании таблиц необходимо максимально четко понять, как устроены данные и как выполняются запросы к данным. Например, для этого можно использовать следующие вопросы:
- Каков размер таблицы?
- Как часто она обновляется?
- Существуют ли в моем пуле SQL таблицы фактов и измерений?
Что такое реплицированная таблица?
Реплицированная таблица содержит полную копию таблицы, которая доступна на каждом вычислительном узле. Репликация таблицы устраняет необходимость передавать данные между вычислительными узлами перед операциями соединения или агрегирования. Поскольку в таблице имеется несколько копий, реплицированные таблицы наиболее эффективны, когда размер таблицы в сжатом состоянии менее 2 ГБ. Ограничение в 2 ГБ не является жестким. Если данные являются статическими и не меняются, можно реплицировать таблицы большего размера.
На схеме ниже показана реплицированная таблица, которая доступна на каждом вычислительном узле. В случае пула SQL реплицируемая таблица полностью копируется в базу данных распространителя на каждом вычислительном узле.

Реплицированные таблицы отлично подходят для таблиц измерения в схеме типа "звезда". Таблицы измерения обычно объединяются с таблицами фактов, которые распределяются иначе, чем таблица измерения. Размер измерений обычно таков, что позволяет хранить и поддерживать несколько копий. В измерениях хранятся описательные данные, которые изменяются редко, например имя и адрес клиента, а также сведения о продукте. Такое свойство данных способствует тому, что обслуживание реплицированной таблицы также происходит реже.
Реплицированные таблицы подходят в ситуациях, когда:
- Размер таблицы на диске менее 2 ГБ, независимо от количества строк. Чтобы определить размер таблицы, можно использовать команду DBCC PDW_SHOWSPACEUSED:
DBCC PDW_SHOWSPACEUSED('ReplTableCandidate'). - Таблица используется в соединениях, для которых в противном случае требуется перемещение данных. При соединении таблиц, которые не распределены по одному и тому же столбцу, например при объединении хэш-распределенной таблицы с таблицу с распределением методом циклического перебора, для выполнения запроса требуется перемещение данных. Если одна из таблиц достаточно мала, рассмотрите возможность использования реплицированной таблицы. В большинстве случаев вместо таких таблиц рекомендуется использовать реплицированные таблицы. Чтобы просмотреть операции перемещения данных в планах запросов, используйте sys.dm_pdw_request_steps. BroadcastMoveOperation является типичной операцией перемещения данных, которую можно устранить, используя реплицированную таблицу.
Реплицированные таблицы не гарантируют лучшую производительность, когда:
- Таблица содержит частые операции вставки, обновления и удаления. Эти операции языка обработки данных (DML) требуют перестроения реплицированной таблицы. Зачастую перестроение приводит к снижению производительности.
- Пул SQL часто масштабируется. Масштабирование пула SQL приводит к изменению количества вычислительных узлов, и это влечет за собой перестроение реплицированной таблицы.
- Таблица содержит много столбцов, однако операции с данными обычно обращаются только к небольшому числу столбцов. В этом случае вместо репликации всей таблицы лучше всего использовать распределение таблицы, а затем создать индекс для часто используемых столбцов. Если запрос требует перемещения данных, то пул SQL перемещает только данные для запрошенных столбцов.
Совет
Дополнительные рекомендации по индексации и реплика таблицам см. в памятке по выделенному пулу SQL (ранее — хранилище данных SQL) в Azure Synapse Analytics.
Использование реплицированных таблиц с предикатами простого запроса
Прежде чем выбрать распространение или репликацию таблицы, выберите типы запросов, которые планируется выполнять к таблице. Когда это возможно:
- Используйте реплицированные таблицы для запросов с предикатами простого запроса, например равенства или неравенства.
- Используйте распределенные таблицы для запросов с предикатами сложного запроса, например LIKE или NOT LIKE.
Ресурсоемкие запросы лучше всего использовать в случаях, когда работа распределяется по всем вычислительным узлам. Например, запросы, которые запускают вычисления для каждой строки таблицы, выполняются более эффективно в распределенных таблицах, чем реплицированных. Поскольку реплицированные таблицы хранятся в полном объеме на каждом вычислительном узле, ресурсоемкие запросы к реплицированной таблице применяются ко всей таблице на каждом вычислительном узле. Лишние вычисления могут снизить производительность запроса.
Например, в этом запросе содержится сложный предикат. Он выполняется быстрее, когда данные хранятся в распределенной, а не реплицированной таблице. В этом примере для данных может использоваться распределение методом циклического перебора.
SELECT EnglishProductName
FROM DimProduct
WHERE EnglishDescription LIKE '%frame%comfortable%';
Преобразование существующих циклических таблиц в реплицированные таблицы
Если имеются циклические таблицы, их рекомендуется преобразовать в реплицированные таблицы, если они удовлетворяют критериям, обозначенным в этой статье. Реплицированные таблицы эффективнее по сравнению с циклическими таблицами, поскольку они исключают необходимость в перемещении данных. Для соединений в циклической таблице всегда требуется перемещение данных.
В этом примере используется CTAS для изменения таблицы DimSalesTerritory в реплицированную таблицу. В данном примере неважно, была ли таблица DimSalesTerritory хэш-распределена или распределена методом циклического перебора.
CREATE TABLE [dbo].[DimSalesTerritory_REPLICATE]
WITH
(
HEAP,
DISTRIBUTION = REPLICATE
)
AS SELECT * FROM [dbo].[DimSalesTerritory]
OPTION (LABEL = 'CTAS : DimSalesTerritory_REPLICATE')
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[DimSalesTerritory_REPLICATE] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
Пример производительности запросов для циклической и реплицированной таблиц
Поскольку вся таблица уже существует на каждом вычислительном узле, для реплицированной таблицы не требуется перемещать данные для соединений. Если таблицы измерений распределены методом циклического перебора, соединение копирует таблицу измерения в полном объеме на каждом вычислительном узле. Чтобы переместить данные, план запроса содержит операцию, которая называется BroadcastMoveOperation. Операции перемещения данных данного типа снижают производительность запросов. Устранить это можно с помощью реплицированных таблиц. Чтобы просмотреть действия плана запроса, используйте представление системного каталога sys.dm_pdw_request_steps.
Например, в следующем запросе к схеме AdventureWorks таблица FactInternetSales хэш-распределена. Таблицы DimDate и DimSalesTerritory являются таблицами измерений меньшего размера. Этот запрос возвращает общий объем продаж в Северной Америке за 2004 финансовый год:
SELECT [TotalSalesAmount] = SUM(SalesAmount)
FROM dbo.FactInternetSales s
INNER JOIN dbo.DimDate d
ON d.DateKey = s.OrderDateKey
INNER JOIN dbo.DimSalesTerritory t
ON t.SalesTerritoryKey = s.SalesTerritoryKey
WHERE d.FiscalYear = 2004
AND t.SalesTerritoryGroup = 'North America'
Мы повторно создали таблицы DimDate и DimSalesTerritory как циклические таблицы. В результате запрос показал следующий план запроса, в котором имеется несколько операций широковещательного переноса:
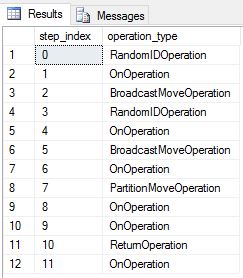
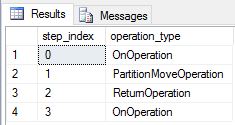
Мы повторно создали таблицы DimDate и DimSalesTerritory как в реплицированные таблицы, а затем снова выполнили запрос. Результирующий план запроса намного короче, а также в нем нет широковещательного переноса.
Рекомендации по повышению производительности для изменения реплицированных таблиц
Пул SQL реализует реплицированную таблицу путем сохранения главной версии таблицы. Для этого он копирует главную версию в первую базу данных распространителя на каждом вычислительном узле. В случае изменения сначала обновляется главная версия, а затем выполняется перестроение таблиц на каждом из вычислительных узлов. Перестроение реплицированной таблицы включает в себя копирование таблицы на каждый вычислительный узел и последующее перестроение индексов. Например, у реплицированной таблицы на DW2000c имеются 5 копий данных. Мастер-копия и полные копии на каждом вычислительном узле. Все данные хранятся в базах данных распространителя. Пул SQL использует эту модель для поддержки более быстрых инструкций изменения данных и гибких операций масштабирования.
Асинхронные перестроения активируются за счет первого запроса к реплицированной таблице после следующих событий.
- Загрузка или изменение данных
- Масштабирование экземпляра Synapse SQL до другого уровня.
- Обновление определения таблицы
Перестроение не требуется после следующего:
- Выполнение операции приостановки
- Выполнение операции возобновления
Перестроение не происходит сразу после изменения данных. Вместо этого оно выполняется при первом выборе запросом данных из таблицы. Запрос, который активирует перестроение, немедленно считывает данные из основной версии таблицы, пока данные асинхронно копируются на каждый вычислительный узел. До завершения копирования данных последующие запросы будут использовать основную версию таблицы. В случае, если возникает какое-либо действие с реплицированной таблицей, которое вызывает дополнительное перестроение, копирование данных становится недействительным и следующая инструкция SELECT активирует повторное копирование данных.
Консервативный подход к использованию индексов
В отношении реплицированных таблиц применяется стандартный подход к индексированию. В процессе перестроения пул SQL перестраивает индекс каждой реплицированной таблицы. Индексы следует использовать только в том случае, если для повышения производительности целесообразно перестроить индексы.
Пакетная загрузка данных
При загрузке данных в реплицированные таблицы попробуйте минимизировать перестроения путем пакетной загрузки. Выполните все пакетные загрузки перед выполнением инструкции SELECT.
Например, ниже представлен шаблон загрузки данных из четырех источников и запуска четырех операций перестроения.
- Загрузка из источника 1.
- Инструкция SELECT вызывает перестроение 1.
- Загрузка из источника 2.
- Инструкция SELECT вызывает перестроение 2.
- Загрузка из источника 3.
- Инструкция SELECT вызывает перестроение 3.
- Загрузка из источника 4.
- Инструкция SELECT вызывает перестроение 4.
Например, ниже представлен шаблон загрузки данных из четырех источников и запуска только одной операции перестроения.
- Загрузка из источника 1.
- Загрузка из источника 2.
- Загрузка из источника 3.
- Загрузка из источника 4.
- Инструкция SELECT вызывает перестроение.
Перестроение реплицированной таблицы после пакетной загрузки
Чтобы обеспечить согласованное время выполнение запросов, рекомендуется принудительно перестроить реплицированные таблицы после пакетной загрузки. В противном случае для выполнения первого запроса по-прежнему будет использоваться перемещение данных.
В ходе операции "Сборка кэша таблицы репликации" возможно выполнять до двух операций одновременно. Например, если вы пытаетесь перестроить кэш для пяти таблиц, система будет использовать статическийrc20 (который не может быть изменен) для параллельной сборки двух таблиц в то время. Поэтому рекомендуется избегать использования больших таблиц репликации, превышающих 2 ГБ, так как это может замедлить перестроение кэша на узлах и увеличить общее время.
В этом запросе используется динамическое административное представление sys.pdw_replicated_table_cache_state для отображения реплицированных таблиц, которые были изменены, но не перестроены.
SELECT SchemaName = SCHEMA_NAME(t.schema_id)
, [ReplicatedTable] = t.[name]
, [RebuildStatement] = 'SELECT TOP 1 * FROM ' + '[' + SCHEMA_NAME(t.schema_id) + '].[' + t.[name] +']'
FROM sys.tables t
JOIN sys.pdw_replicated_table_cache_state c
ON c.object_id = t.object_id
JOIN sys.pdw_table_distribution_properties p
ON p.object_id = t.object_id
WHERE c.[state] = 'NotReady'
AND p.[distribution_policy_desc] = 'REPLICATE'
Чтобы активировать перестроение, выполните следующую инструкцию для каждой таблицы в предыдущих выходных данных.
SELECT TOP 1 * FROM [ReplicatedTable]
Примечание.
Если вы планируете перестроить статистику без кэширования реплика таблицы, обязательно обновите статистику перед активацией кэша. Обновление статистики приведет к недопустимости кэша, поэтому последовательность важна.
Пример. Начните с UPDATE STATISTICS, а затем активируйте перестроение кэша. В следующих примерах правильный пример обновляет статистику, а затем запускает перестроение кэша.
-- Incorrect sequence. Ensure that the rebuild operation is the last statement within the batch.
BEGIN
SELECT TOP 1 * FROM [ReplicatedTable]
UPDATE STATISTICS [ReplicatedTable]
END
-- Correct sequence. Ensure that the rebuild operation is the last statement within the batch.
BEGIN
UPDATE STATISTICS [ReplicatedTable]
SELECT TOP 1 * FROM [ReplicatedTable]
END
Для мониторинга процесса перестроения можно использовать sys.dm_pdw_exec_requests, где command начнется сборка BuildReplicatedTableCache. Например:
-- Monitor Build Replicated Cache
SELECT *
FROM sys.dm_pdw_exec_requests
WHERE command like 'BuildReplicatedTableCache%'
Совет
Запросы размера таблицы можно использовать для проверки того, какие таблицы имеют реплика политику распространения и размер которой превышает 2 ГБ.
Следующие шаги
Чтобы создать реплицированную таблицу, воспользуйтесь одной из следующих инструкций:
Обзор распределенных таблиц см. в разделе Распределенные таблицы.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по