Заметка
Доступ к этой странице требует авторизации. Вы можете попробовать войти в систему или изменить каталог.
Доступ к этой странице требует авторизации. Вы можете попробовать сменить директорию.
Понимая, как хранятся, организованы и используются большие двоичные объекты и контейнеры в рабочей среде, вы можете оптимизировать компромиссы между затратами и производительностью.
В этом руководстве показано, как создавать и визуализировать статистику, например рост данных с течением времени, количество измененных файлов, размер моментальных снимков BLOB-объектов, шаблоны доступа по каждому уровню и распределение данных как в данный момент, так и с течением времени (например, данные между уровнями, типами файлов, в контейнерах и типах BLOB-объектов).
В этом руководстве описано следующее:
- Создание отчета инвентаризации BLOB-объектов
- Настройка рабочей области Synapse
- Настройка Synapse Studio
- Создание аналитических данных в Synapse Studio
- визуализация результатов в Power BI.
Необходимые компоненты
Подписка Azure— создание учетной записи бесплатно
Учетная запись хранения Azure — создание учетной записи хранения
Убедитесь, что удостоверение пользователя назначено роли участника данных BLOB-объектов хранилища.
Создание отчета инвентаризации
Включите отчеты инвентаризации BLOB-объектов для учетной записи хранения. См. раздел "Включить служба хранилища Azure отчеты инвентаризации BLOB-объектов".
Возможно, вам придется ждать до 24 часов после включения отчетов инвентаризации для создания первого отчета.
Настройка рабочей области Synapse
созданию рабочей области Azure Synapse. См. статью "Создание рабочей области Azure Synapse".
Примечание.
В рамках создания рабочей области вы создадите учетную запись хранения с иерархическим пространством имен. Azure Synapse хранит таблицы Spark и журналы приложений в этой учетной записи. Azure Synapse ссылается на эту учетную запись как основную учетную запись хранения. Чтобы избежать путаницы, в этой статье используется учетная запись отчета инвентаризации терминов для ссылки на учетную запись , содержащую отчеты инвентаризации.
В рабочей области Synapse назначьте роль участника идентификатору пользователя. См . роль владельца azure RBAC для рабочей области.
Предоставьте рабочей области Synapse разрешение на доступ к отчетам инвентаризации в учетной записи хранения, перейдя к учетной записи отчета инвентаризации, а затем назначьте роль участника данных BLOB-объектов хранилища системе управляемому удостоверению рабочей области. См. статью о назначении ролей Azure с помощью портала Azure.
Перейдите к основной учетной записи хранения и назначьте роль участника хранилища BLOB-объектов идентификатору пользователя.
Настройка Synapse Studio
Откройте рабочую область Synapse в Synapse Studio. См . раздел Open Synapse Studio.
В Synapse Studio убедитесь, что удостоверение назначено роли администратора Synapse. См . статью Synapse RBAC: роль администратора Synapse для рабочей области.
Создайте пул Apache Spark. См. статью "Создание бессерверного пула Apache Spark".
Настройка и запуск примера записной книжки
В этом разделе вы создадите статистические данные, которые будут визуализироваться в отчете. Чтобы упростить это руководство, в этом разделе используется пример файла конфигурации и пример записной книжки PySpark. Записная книжка содержит коллекцию запросов, выполняемых в Azure Synapse Studio.
Изменение и отправка примера файла конфигурации
Скачайте файл BlobInventoryStorageAccountConfiguration.json.
Обновите следующие заполнители этого файла:
Задайте
storageAccountNameимя учетной записи отчета инвентаризации.Задайте
destinationContainerимя контейнера, в котором хранятся отчеты инвентаризации.Задайте
blobInventoryRuleNameимя правила отчета инвентаризации, создающего результаты, которые вы хотите проанализировать.Задайте
accessKeyдля ключа учетной записи отчета инвентаризации.
Отправьте этот файл в контейнер в основной учетной записи хранения, указанной при создании рабочей области Synapse.
Импорт примера записной книжки PySpark
Скачайте пример записной книжки ReportAnalysis.ipynb .
Примечание.
Сохраните этот файл с расширением
.ipynb.Откройте рабочую область Synapse в Synapse Studio. См . раздел Open Synapse Studio.
В Synapse Studio выберите вкладку "Разработка ".
Выберите знак плюса (+), чтобы добавить элемент.
Выберите "Импорт", перейдите к примеру файла, который вы скачали, выберите этот файл и нажмите кнопку "Открыть".
Откроется диалоговое окно Свойства.
В диалоговом окне "Свойства" выберите ссылку "Настройка сеанса".
Откроется диалоговое окно "Настройка сеанса ".
В раскрывающемся списке "Подключение к подключению" диалогового окна "Настройка сеанса" выберите пул Spark, созданный ранее в этой статье. Затем нажмите кнопку "Применить ".
Изменение записной книжки Python
В первой ячейке записной книжки Python задайте значение
storage_accountпеременной имя основной учетной записи хранения.Обновите значение переменной
container_nameдо имени контейнера в этой учетной записи, указанной при создании рабочей области Synapse.Нажмите кнопку Опубликовать.
Запуск записной книжки PySpark
В записной книжке PySpark выберите "Выполнить все".
Для начала сеанса Spark потребуется несколько минут, а еще несколько минут для обработки отчетов инвентаризации. Первый запуск может занять некоторое время, если есть множество отчетов инвентаризации для обработки. Последующие запуски обрабатывают только новые отчеты инвентаризации, созданные с момента последнего выполнения.
Примечание.
Если вы внесете изменения в записную книжку, будет запущена записная книжка, обязательно опубликуйте эти изменения с помощью кнопки "Опубликовать ".
Убедитесь, что записная книжка успешно запущена, выбрав вкладку "Данные ".
База данных с именем reportdata должна отображаться на вкладке "Рабочая область " области данных . Если эта база данных не отображается, может потребоваться обновить веб-страницу.
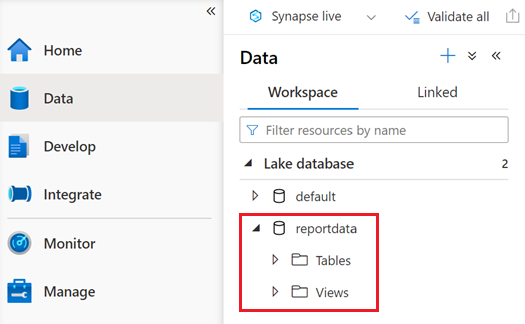
База данных содержит набор таблиц. Каждая таблица содержит сведения, полученные путем выполнения запросов из записной книжки PySpark.
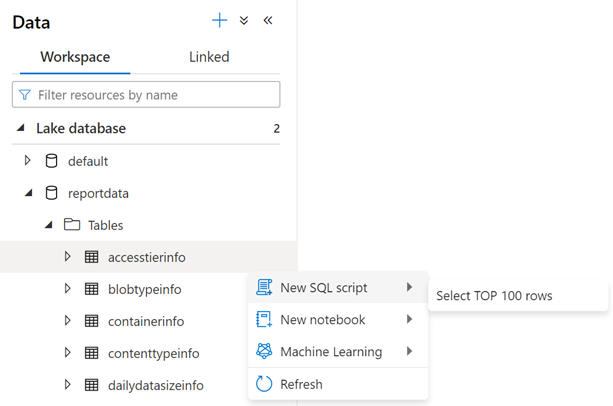
Чтобы проверить содержимое таблицы, разверните папку "Таблицы" базы данных отчетов. Затем щелкните таблицу правой кнопкой мыши и выберите сценарий SQL, а затем выберите top 100 строк.
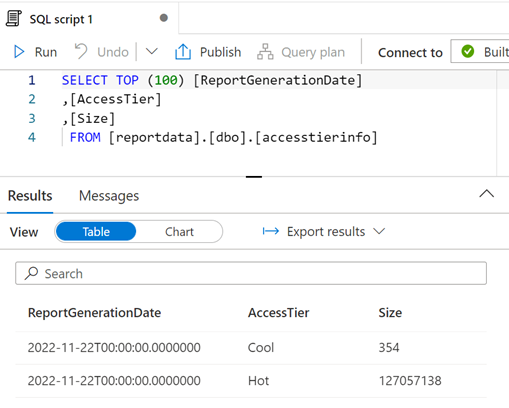
Вы можете изменить запрос по мере необходимости, а затем нажать кнопку "Выполнить ", чтобы просмотреть результаты.
Визуализация данных
Запустите Power BI Desktop. Инструкции по установке см. в разделе "Получение Power BI Desktop".
В Power BI выберите "Файл", "Открыть отчет" и " Обзор отчетов".
В диалоговом окне "Открыть" измените тип файла на файлы шаблонов Power BI (*.pbit).

Перейдите к расположению скачаированного файла ReportAnalysis.pbit , а затем нажмите кнопку "Открыть".
Откроется диалоговое окно, которое запрашивает указать имя рабочей области Synapse и имя базы данных.
В диалоговом окне задайте для поля synapse_workspace_name имя рабочей области и задайте для поля database_name значение
reportdata. Затем нажмите кнопку "Загрузить ".
Появится отчет, предоставляющий визуализации данных, полученных записной книжкой. На следующих изображениях показаны типы диаграмм и графов, которые отображаются в этом отчете.
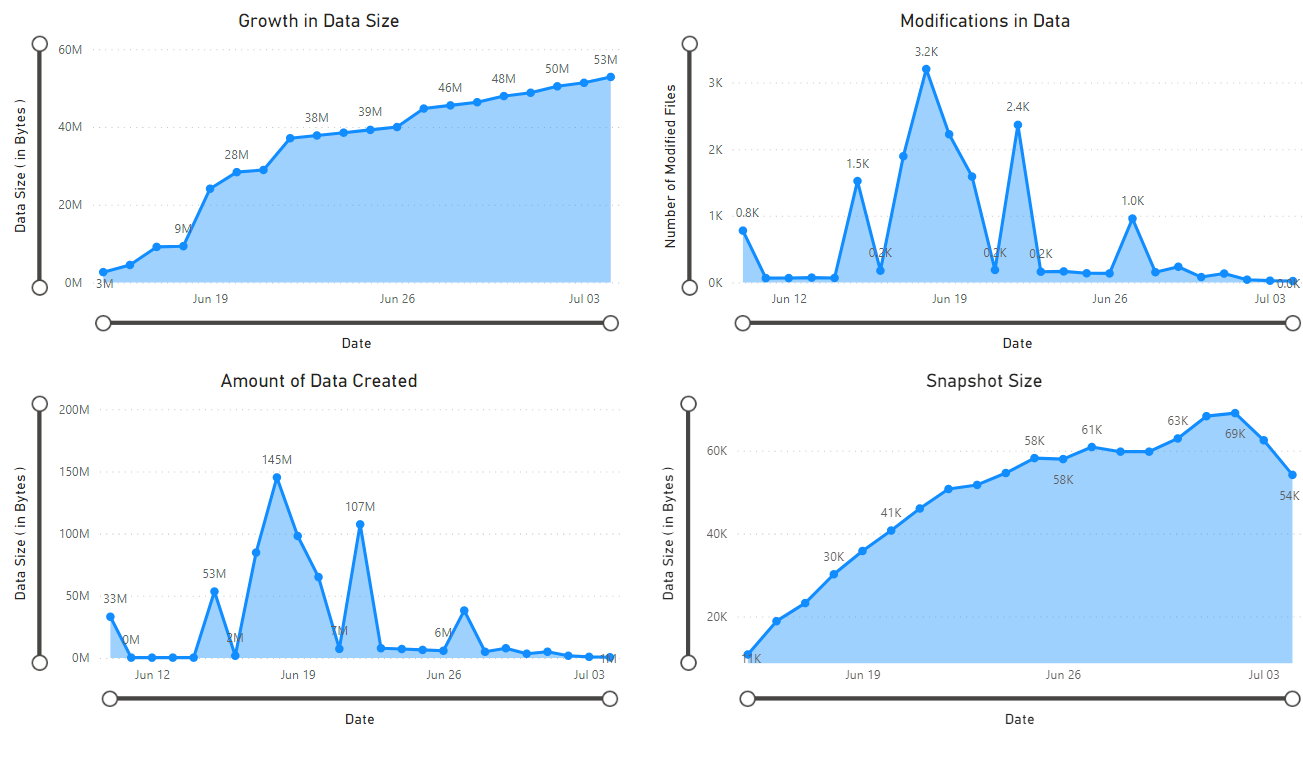
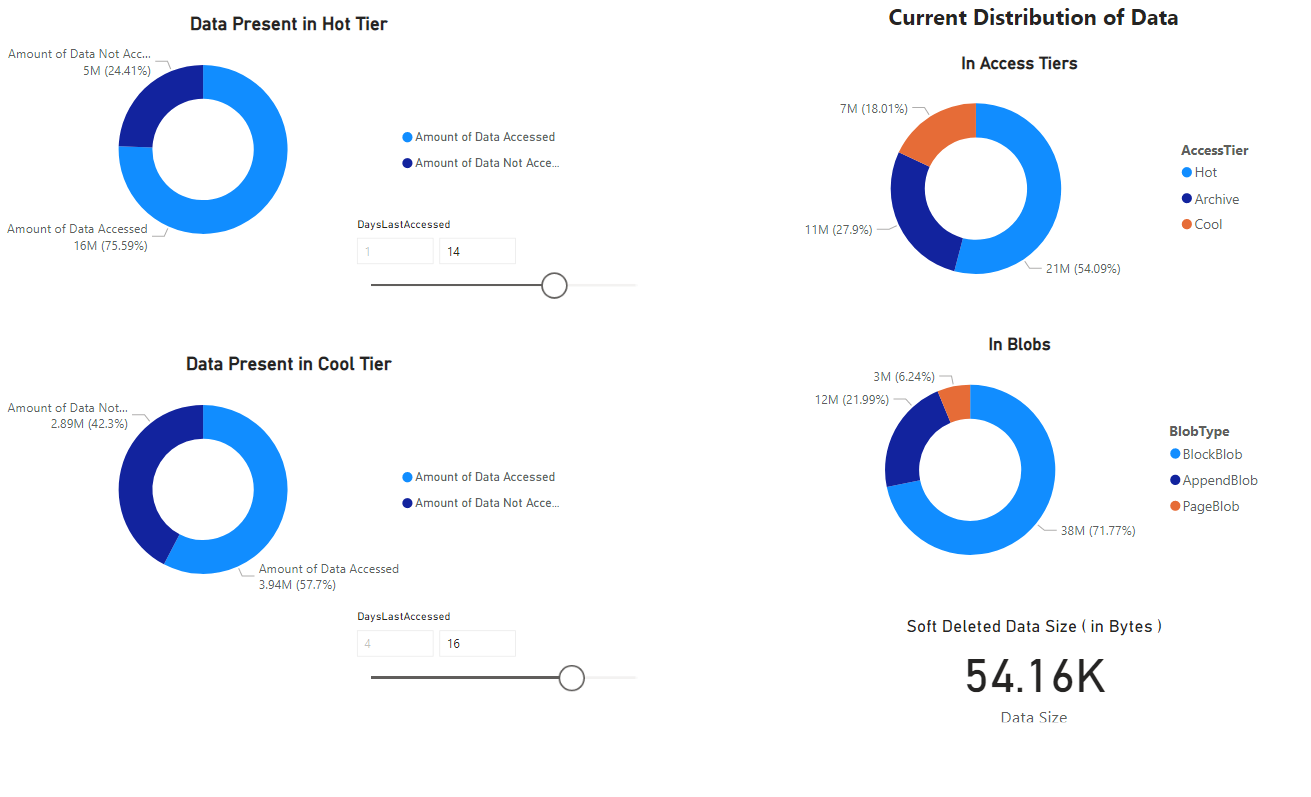
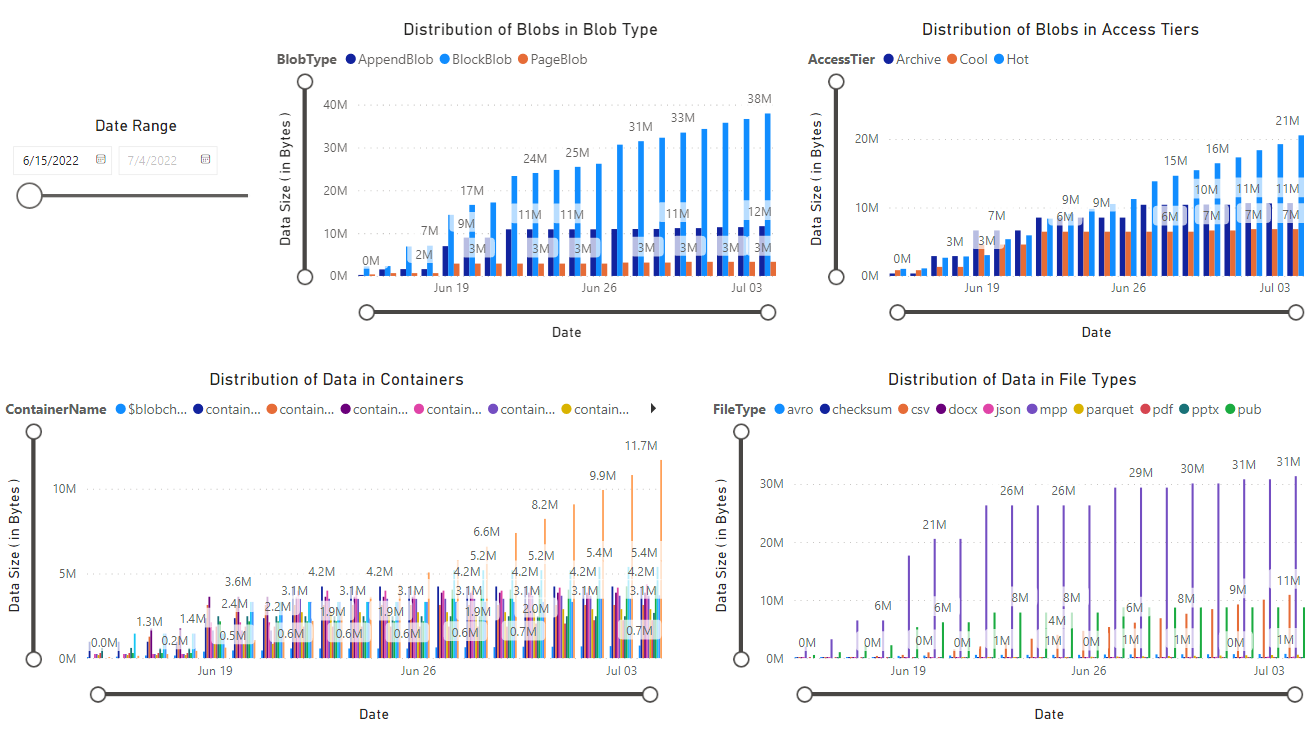
Следующие шаги
Настройте конвейер Azure Synapse для регулярного запуска записной книжки. Таким образом можно обрабатывать новые отчеты инвентаризации по мере их создания. После первоначального выполнения каждый из следующих запусков будет анализировать добавочные данные, а затем обновлять таблицы с результатами этого анализа. Инструкции см. в разделе "Интеграция с конвейерами".
Узнайте о способах анализа отдельных контейнеров в учетной записи хранения. См. следующие статьи:
Расчет числа BLOB-объектов и общего размера для контейнера с помощью инвентаризации хранилища Azure
Руководство. Вычисление статистики контейнеров с помощью Databricks
Узнайте о способах оптимизации затрат на основе анализа больших двоичных объектов и контейнеров. См. следующие статьи:
Планирование затрат и управление ими для Хранилища BLOB-объектов Azure
Оценка стоимости архивирования данных
Оптимизация затрат путем автоматического управления жизненным циклом данных