Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Доступно как в облаке, так и в Azure IoT Edge, Azure Stream Analytics предлагает встроенные возможности обнаружения аномалий на основе машинного обучения, которые можно использовать для мониторинга двух наиболее распространенных аномалий: временных и постоянных. С помощью функций AnomalyDetection_SpikeAndDip и AnomalyDetection_ChangePoint можно выполнять обнаружение аномалий непосредственно в задании Stream Analytics.
Модели машинного обучения предполагают однородную выборку временных рядов. Если временной ряд не является равномерным, вставьте шаг агрегирования со скользящим окном перед вызовом обнаружения аномалий.
Операции машинного обучения не поддерживают тенденции сезонности или многовариантные корреляции в настоящее время.
Обнаружение аномалий с помощью машинного обучения в Azure Stream Analytics
В следующем видео показано, как обнаружить аномалию в режиме реального времени с помощью функций машинного обучения в Azure Stream Analytics.
Поведение модели
Как правило, точность модели улучшается с большими данными в скользящем окне. Данные в указанном скользящем окне обрабатываются как часть обычного диапазона значений для этого интервала времени. Модель рассматривает только журнал событий в скользящем окне, чтобы проверить, является ли текущее событие аномальным. По мере перемещения скользящего окна старые значения вытесняются из процесса обучения модели.
Функции работают путем установления определенной нормы, исходя из того, что они видели до сих пор. Выбросы определяются путем сравнения с установленной нормой в пределах уровня доверия. Размер окна должен быть основан на минимальных событиях, необходимых для обучения модели для нормального поведения, чтобы при возникновении аномалии он мог бы распознать его.
Время отклика модели увеличивается с увеличением объема истории, так как необходимо сравнивать с большим числом прошлых событий. Для повышения производительности включите только необходимое количество событий.
Пробелы в временных рядах могут возникать, когда модель не получает события в определенные моменты времени. Stream Analytics обрабатывает эту ситуацию с помощью логики вменения. Размер истории и продолжительность времени для того же скользящего окна используются для вычисления средней скорости ожидаемого поступления событий.
Вы можете использовать генератор аномалий, чтобы подать данные в IoT Hub, содержащие различные шаблоны аномалий. Вы можете настроить задание Azure Stream Analytics, используя эти функции обнаружения аномалий для чтения из этого IoT Hub и обнаружения аномалий.
скачок и падение
Временные аномалии в потоке событий временных рядов называются пиками и спадами. Вы можете отслеживать пики и спады с помощью оператора на основе Machine Learning, AnomalyDetection_SpikeAndDip.
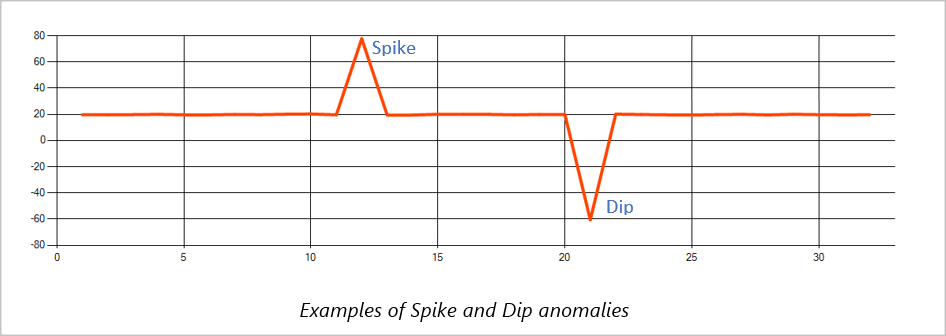
В том же скользящем окне, если второй всплеск меньше первого, вычисленная оценка для меньшего всплеска может быть недостаточно значительной по сравнению с оценкой для первого всплеска в рамках указанного уровня достоверности. Вы можете попытаться уменьшить уровень достоверности модели, чтобы обнаружить такие аномалии. Однако если вы начнете получать слишком много оповещений, используйте более высокий доверительный интервал.
В следующем примере запроса предполагается единая скорость ввода одного события в секунду в 2-минутном скользящем окне с историей 120 событий. Последняя инструкция SELECT извлекает и выводит оценку и статус аномалии с уровнем доверия 95%.
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_SpikeAndDip(CAST(temperature AS float), 95, 120, 'spikesanddips')
OVER(LIMIT DURATION(second, 120)) AS SpikeAndDipScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'Score') AS float) AS
SpikeAndDipScore,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'IsAnomaly') AS bigint) AS
IsSpikeAndDipAnomaly
INTO output
FROM AnomalyDetectionStep
Точка изменения
Постоянные аномалии в потоке событий временного ряда представляют собой изменения в распределении значений, такие как изменения уровней и тенденции. В Stream Analytics оператор Machine Learning на основе AnomalyDetection_ChangePoint обнаруживает эти аномалии.
Постоянные изменения длились гораздо дольше, чем пики и спады, и могут указывать на катастрофические события. Постоянные изменения обычно не видны невооруженным глазам, но оператор AnomalyDetection_ChangePoint может обнаружить их.
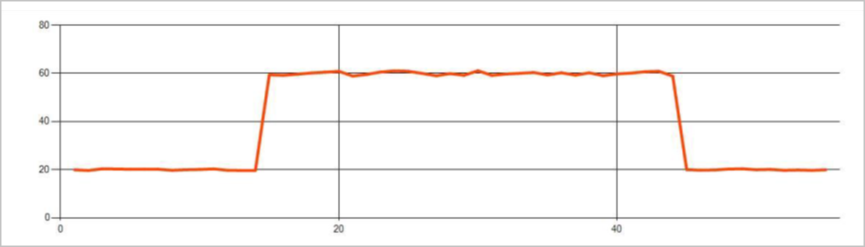
На следующем рисунке показан пример изменения уровня.
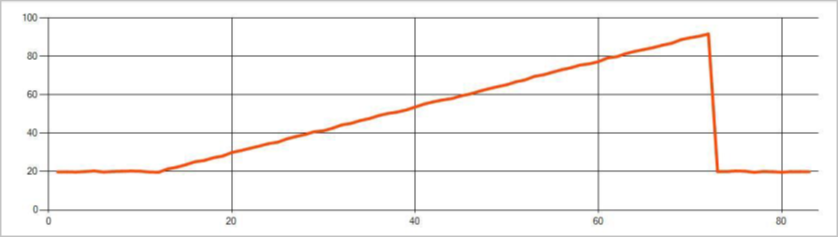
Следующее изображение является примером изменения тренда:
В следующем примере запроса предполагается единая скорость ввода одного события в секунду в 20-минутном скользящем окне с размером журнала 1200 событий. Последняя инструкция SELECT извлекает и выводит состояние оценки и аномалии с уровнем достоверности 80%.
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_ChangePoint(CAST(temperature AS float), 80, 1200)
OVER(LIMIT DURATION(minute, 20)) AS ChangePointScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(ChangePointScores, 'Score') AS float) AS
ChangePointScore,
CAST(GetRecordPropertyValue(ChangePointScores, 'IsAnomaly') AS bigint) AS
IsChangePointAnomaly
INTO output
FROM AnomalyDetectionStep
Характеристики производительности
Производительность этих моделей зависит от размера истории, длительности окна, загрузки событий и от того, используется ли секционирование на уровне функций. В этом разделе рассматриваются эти конфигурации и даны примеры, как поддерживать скорость поступления данных, равную 1 тысяче, 5 тысячам и 10 тысячам событий в секунду.
- Размер истории — эти модели показывают линейную зависимость от размера истории. Чем больше объём истории, тем дольше модели оценивают новое событие. Модели сравнивают новое событие с каждым из прошлых событий в буфере истории.
- Длительность окна — длительность окна должна отражать, сколько времени требуется для получения столько событий, сколько указано в размере истории. Без этого большого количества событий в окне Azure Stream Analytics будет вменять отсутствующие значения. Таким образом, потребление ЦП зависит от размера истории.
- Загрузка событий — чем больше нагрузка на события, тем больше работают модели, что влияет на потребление ЦП. Вы можете масштабировать задание, делая его полностью распараллеливаемым, если это имеет смысл с точки зрения бизнес-логики использовать больше входных разделов.
-
Секционирование на уровне функции — используйте
PARTITION BYв вызове функции обнаружения аномалий для выполнения секционирования на уровне функции. Этот тип секционирования добавляет дополнительные издержки, так как задание должно обеспечивать сохранение состояния для нескольких моделей в то же время. Используйте секционирование уровня функций в таких сценариях, как секционирование на уровне устройства.
Отношения
Размер журнала, длительность окна и общая загрузка событий связаны следующим образом:
windowDuration (в мс) = 1000 * historySize / (общее количество входных событий в секунду / число входных секций)
При секционировании функции по deviceId добавьте "PARTITION BY deviceId" в вызов функции обнаружения аномалий.
Наблюдения
В следующей таблице показаны наблюдения за пропускной способностью для одного узла (шесть SU) для непартиментированного случая:
| Размер истории (события) | Длительность окна (мс) | Общее количество входных событий в секунду |
|---|---|---|
| шестьдесят | 55 | 2 200 |
| 600 | 728 | 1,650 |
| 6000 | 10,910 | 1,100 |
В следующей таблице показаны наблюдения пропускной способности для одного узла (шесть SU) в случае разделенной конфигурации.
| Размер истории (события) | Длительность окна (мс) | Общее количество входных событий в секунду | Число устройств |
|---|---|---|---|
| шестьдесят | 1091 | 1,100 | 10 |
| 600 | 10,910 | 1,100 | 10 |
| 6000 | 218,182 | <550 | 10 |
| шестьдесят | 21,819 | 550 | 100 |
| 600 | 218,182 | 550 | 100 |
| 6000 | 2,181,819 | <550 | 100 |
Пример кода можно найти для запуска непартиментированных конфигураций в репозитории Streaming at Scale repo из примеров Azure. Код создает задание Stream Analytics без секционирования на уровне функции, которое использует Центры событий в качестве входных и выходных данных. Тестовые клиенты создают входную нагрузку. Каждое входное событие — это документ JSON размером 1 КБ. События имитируют устройство Интернета вещей, отправляющее данные JSON (до 1 K устройств). Размер журнала, длительность окна и общая нагрузка на события зависят от двух входных секций.
Замечание
Чтобы получить более точную оценку, настройте примеры в соответствии с имеющимся сценарием.
Определение узких мест
Чтобы определить узкие места в конвейере, используйте область метрик в задании Azure Stream Analytics. Просмотрите События ввода/вывода для пропускной способности и "Задержки водяного знака" или Накопленные события, чтобы узнать, соответствует ли задача скорости ввода. Для метрик Центров событий найдите Ограниченные запросы и настройте пороговые значения соответствующим образом. Для метрик Azure Cosmos DB просмотрите Максимальное количество потребленных единиц запроса в секунду на диапазон ключей секции в разделе "Пропускная способность", чтобы обеспечить равномерное использование диапазонов ключей секции. Для базы данных Azure SQL отслеживайте Log IO и CPU.
Демонстрационное видео
Дальнейшие шаги
- Introduction to Azure Stream Analytics
- Начать использовать Azure Stream Analytics
- Масштабируйте задания в Azure Stream Analytics
- Справочник по языку запросов Azure Stream Analytics
- Справочник по управлению Azure Stream Analytics с помощью REST API.