Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Это важно
Обозреватель данных Azure Synapse Analytics (предварительная версия) будет прекращен 7 октября 2025 г. После этой даты рабочие нагрузки, работающие в Synapse Data Explorer, будут удалены, а связанные данные приложения будут потеряны. Мы настоятельно рекомендуем мигрировать в Eventhouse на платформе Microsoft Fabric.
Программа Microsoft Cloud Migration Factory (CMF) предназначена для поддержки клиентов при миграции в Fabric. Программа предлагает практические ресурсы клавиатуры без затрат для клиента. Эти ресурсы назначаются в течение 6–8 недель с предопределенной и согласованной областью. Номинации клиентов принимаются от команды учетных записей Microsoft или непосредственно путем отправки запроса на помощь команде CMF.
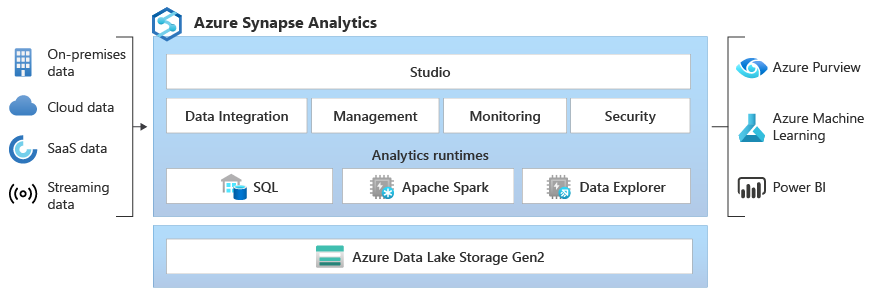
Azure Synapse Data Explorer предоставляет клиентам интерактивные запросы для разблокировки аналитических сведений из данных журналов и данных телеметрии. Чтобы дополнить существующие подсистемы среды выполнения аналитики SQL и Apache Spark, среда выполнения аналитики Data Explorer оптимизирована для эффективной аналитики журналов с помощью мощных технологий индексирования, чтобы автоматически индексировать свободный текст и полуструктурированные данные, часто найденные в данных телеметрии.
Дополнительные сведения см. в следующем видео:
Что делает Azure Synapse Data Explorer уникальным?
Простой прием данных - Data Explorer предлагает встроенные интеграции для приема данных без программирования или с минимальным программированием, c высокой пропускной способностью и кэшированием данных из источников в режиме реального времени. Данные можно получать из таких источников, как Центры событий Azure, Kafka, Azure Data Lake, агенты с открытым кодом, такие как Fluentd/Fluent Bit, а также широкий спектр облачных и локальных источников данных.
Нет сложного моделирования данных . С помощью Обозревателя данных нет необходимости создавать сложные модели данных и не требуется сложного скрипта для преобразования данных перед его использованием.
Отсутствие необходимости в обслуживании индекса — Нет необходимости выполнять задачи по обслуживанию для оптимизации данных с целью увеличения производительности запросов и в обслуживании индекса. При использовании Обозревателя данных все необработанные данные доступны сразу, что позволяет выполнять высокопроизводительные и многопоточные запросы как с потоковыми, так и с постоянными данными. Эти запросы можно использовать для создания панелей мониторинга и оповещений практически в режиме реального времени и подключения данных операционной аналитики с остальной частью платформы аналитики данных.
Демократизация аналитики данных . Обозреватель данных демократизирует самостоятельную аналитику больших данных с помощью интуитивно понятного языка запросов Kusto (KQL), который обеспечивает экспрессивность и силу SQL с простотой Excel. KQL оптимизирован для изучения необработанных данных телеметрии и временных рядов путем использования передовой технологии индексирования текста в классе Data Explorer для эффективного поиска свободного текста и регулярных выражений, а также комплексных возможностей парсинга для запросов трассировок и текстовых данных, и полуструктурированных данных JSON, включая массивы и вложенные структуры. KQL предлагает расширенную поддержку временных рядов для создания, управления и анализа нескольких временных рядов с поддержкой выполнения Python в подсистеме для оценки моделей.
Проверенная технология в масштабировании петабайтов — обозреватель данных — это распределенная система с вычислительными ресурсами и хранилищем, которые могут масштабироваться независимо, что позволяет анализировать гигабайты или петабайты данных.
Интеграция в Azure Synapse Analytics обеспечивает взаимодействие между данными с Data Explorer, Apache Spark и SQL-подсистемами, позволяя инженерам данных, ученым по данным и аналитикам данных легко и безопасно получать доступ и сотрудничать с одними и теми же данными в озере данных.
Когда следует использовать Azure Synapse Data Explorer?
Используйте Data Explorer в качестве платформы данных для создания решений аналитики журналов в режиме реального времени и Интернета вещей:
Консолидация и сопоставление данных журналов и событий между локальными, облачными и сторонними источниками данных.
Ускорьте развитие в области операций с ИИ (распознавание шаблонов, обнаружение аномалий, прогнозирование и многое другое).
Замените решения поиска по журналам на основе инфраструктуры, чтобы сэкономить затраты и повысить производительность.
Создайте решения аналитики Интернета вещей для данных Интернета вещей.
Создайте решения SaaS для аналитики для предоставления услуг внутренним и внешним клиентам.
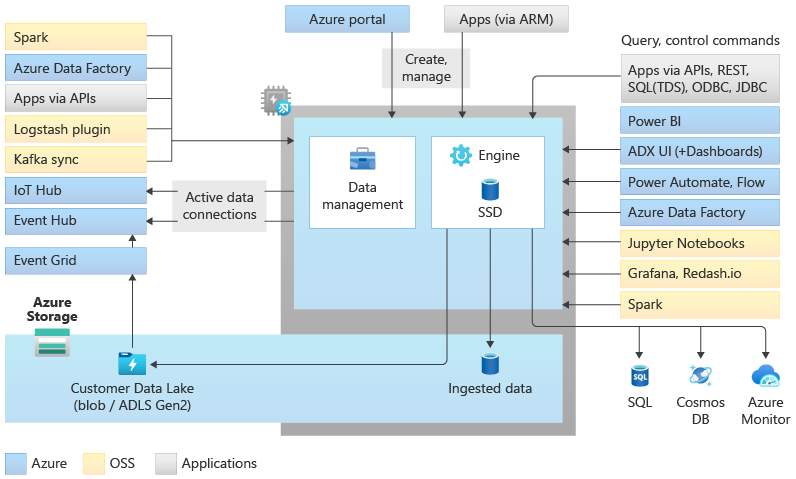
Архитектура пула Data Explorer
Пулы Обозревателя данных реализуют архитектуру горизонтального масштабирования, разделив вычислительные ресурсы и ресурсы хранилища. Это позволяет независимо масштабировать каждый ресурс и, например, запускать несколько вычислений только для чтения в одних и том же данных. Пулы обозревателя данных состоят из набора вычислительных ресурсов под управлением подсистемы, ответственной за автоматическое индексирование, сжатие, кэширование и обслуживание распределенных запросов. Кроме того, у них есть второй набор вычислительных ресурсов, работающих в службе управления данными, ответственной за фоновые системные задания, а также управление и прием данных в очереди. Все данные сохраняются в учетных записях управляемого блоб-хранилища с использованием сжатого колонкового формата.
Пулы Data Explorer поддерживают богатую экосистему для приема данных с помощью коннекторов, пакетов SDK, REST API и других управляемых возможностей. Он предлагает различные способы использования данных для нерегламентированных запросов, отчетов, панелей мониторинга, оповещений, REST API и пакетов SDK.
Data Explore обладает множеством уникальных возможностей, которые делают его лучшим аналитическим механизмом для аналитики журналов и временных рядов в Azure.
В следующих разделах выделены ключевые отличия.
Индексирование данных со свободным текстом и полуструктурированных данных позволяет практически в режиме реального времени обеспечивать высокопроизводительные и высоко параллельные запросы.
Обозреватель данных индексирует полуструктурированные данные (JSON) и неструктурированные данные (свободный текст), что делает выполнение запросов хорошо работающими на этом типе данных. По умолчанию каждое поле индексируется во время приема данных с параметром использовать политику кодирования низкого уровня для точной настройки или отключения индекса для определенных полей. Область индекса — это один сегмент данных.
Реализация индекса зависит от типа поля следующим образом:
| Тип поля | Реализация индексирования |
|---|---|
| String | Модуль создает инвертированные индексы терминов для строковых значений столбцов. Каждое строковое значение анализируется и разбивается на нормализованные термины, а для каждого термина записывается упорядоченный список логических позиций, содержащих порядковые номера записей. Результирующий отсортированный список терминов и их соответствующих позиций хранится в виде неизменяемого B-дерева. |
|
Числовой DateTime TimeSpan |
Движок создает простой прямой индекс на основе диапазонов. Индекс записывает значения min/max для каждого блока, для группы блоков и для всего столбца в сегменте данных. |
| Динамичный | Процесс приема перечисляет все "атомарные" элементы в динамическом значении, такие как имена свойств, значения и элементы массива, а также перенаправляет их в построитель индексов. Динамические поля имеют тот же инвертированные индекс терминов, что и строковые поля. |
Эти эффективные возможности индексирования позволяют анализу данных предоставлять данные практически в режиме реального времени для запросов высокой производительности и высокой параллелизма. Система автоматически оптимизирует сегменты данных для повышения производительности.
Kusto Query Language — язык запросов Kusto
KQL имеет большое, растущее сообщество с быстрым внедрением Azure Monitor Log Analytics и Application Insights, Microsoft Sentinel, Azure Data Explorer и других предложений Майкрософт. Язык хорошо разработан с простым и легко читаемым синтаксисом и обеспечивает плавный переход от простых однострочных к сложным запросам по обработке данных. Это позволяет Data Explorer предоставлять многофункциональную поддержку Intellisense и широкий набор языковых конструкций и встроенных возможностей для агрегирования, временных рядов и аналитики пользователей, которые недоступны в SQL для быстрого изучения данных телеметрии.