Руководство. Визуальное распознавание с помощью служб ИИ Azure
Визуальное распознавание ИИ Azure — это служба ИИ Azure , которая позволяет обрабатывать изображения и возвращать информацию на основе визуальных функций. В этом руководстве описано, как использовать Визуальное распознавание ИИ Azure для анализа изображений в Azure Synapse Analytics.
В этом руководстве демонстрируется использование функции анализа текста с SynapseML для выполнения следующих задач:
- Извлечение визуальных признаков из содержимого изображения
- Распознавание символов на изображениях (OCR)
- Анализ содержимого изображения и создание эскиза
- Обнаружение и определение на изображении содержимого, относящегося к определенной предметной области
- Создание тегов, связанных с изображением
- Формирование описания всего изображения на удобочитаемом языке
Анализ изображения
Вы можете извлекать из содержимого изображения широкий набор визуальных признаков, например объектов, лиц, содержимого для взрослых и автоматически создаваемых текстовых описаний.
Пример входных данных

# Create a dataframe with the image URLs
df = spark.createDataFrame([
("<replace with your file path>/dog.jpg", )
], ["image", ])
# Run the Azure AI Vision service. Analyze Image extracts infortmation from/about the images.
analysis = (AnalyzeImage()
.setLinkedService(ai_service_name)
.setVisualFeatures(["Categories","Color","Description","Faces","Objects","Tags"])
.setOutputCol("analysis_results")
.setImageUrlCol("image")
.setErrorCol("error"))
# Show the results of what you wanted to pull out of the images.
display(analysis.transform(df).select("image", "analysis_results.description.tags"))
Ожидаемые результаты
["dog","outdoor","fence","wooden","small","brown","building","sitting","front","bench","standing","table","walking","board","beach","holding","bridge"]
Оптическое распознавание текста (OCR)
Вы можете извлекать печатный или рукописный текст, цифры и символы валют из изображений, таких как фото вывесок и продуктов, а также документов, таких как счета, ведомости, финансовые отчеты, статьи и т. д. Служба оптимизирована для извлечения текста из изображений с большим объемом текста и многостраничных PDF-документов на различных языках. API поддерживает обнаружение печатного и рукописного текста в одном изображении или документе.
Пример входных данных

df = spark.createDataFrame([
("<replace with your file path>/ocr.jpg", )
], ["url", ])
ri = (ReadImage()
.setLinkedService(ai_service_name)
.setImageUrlCol("url")
.setOutputCol("ocr"))
display(ri.transform(df))
Ожидаемые результаты

Создание эскизов
Анализ содержимого изображения, чтобы создать для него соответствующий эскиз. Служба визуального распознавания сначала создает высококачественный эскиз, а затем анализирует объекты на изображении, чтобы определить интересующую область. Затем зрение обрезает изображение в соответствии с требованиями интересующей области. Для удовлетворения потребностей пользователя созданный эскиз можно пропорционально изменять в размерах.
Пример входных данных

df = spark.createDataFrame([
("<replace with your file path>/satya.jpeg", )
], ["url", ])
gt = (GenerateThumbnails()
.setLinkedService(ai_service_name)
.setHeight(50)
.setWidth(50)
.setSmartCropping(True)
.setImageUrlCol("url")
.setOutputCol("thumbnails"))
thumbnails = gt.transform(df).select("thumbnails").toJSON().first()
import json
img = json.loads(thumbnails)["thumbnails"]
displayHTML("<img src='data:image/jpeg;base64," + img + "'>")
Ожидаемые результаты

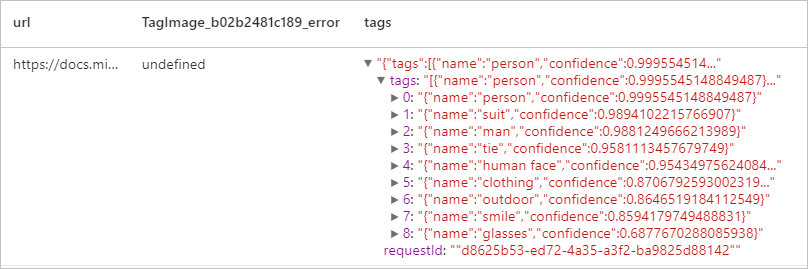
Добавление тегов к изображениям
Создает список слов или тегов, относящихся к содержимому предоставленного изображения. Теги возвращаются на основе тысяч распознаваемых объектов, живых существ, элементов пейзажа и действий, обнаруженных на изображении. Теги могут содержать указания, позволяющие избежать неясности или предоставляющие контекст, например тег "аскомицет" может сопровождаться указанием "грибок".
Дайте продолжить использовать фотографию Сатьи в качестве примера.
df = spark.createDataFrame([
("<replace with your file path>/satya.jpeg", )
], ["url", ])
ti = (TagImage()
.setLinkedService(ai_service_name)
.setImageUrlCol("url")
.setOutputCol("tags"))
display(ti.transform(df))
Ожидаемый результат
Описание изображения
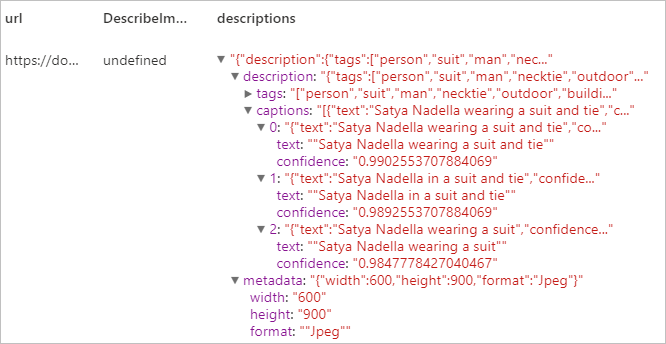
Создание описания всего изображения на удобочитаемом языке с использованием полных предложений. Алгоритмы службы визуального распознавания создают различные описания на основе объектов, определенных на изображении. Каждое описание оценивается и получает оценку достоверности. Затем возвращается список, упорядоченный от наибольшей оценки достоверности к наименьшей.
Дайте продолжить использовать фотографию Сатьи в качестве примера.
df = spark.createDataFrame([
("<replace with your file path>/satya.jpeg", )
], ["url", ])
di = (DescribeImage()
.setLinkedService(ai_service_name)
.setMaxCandidates(3)
.setImageUrlCol("url")
.setOutputCol("descriptions"))
display(di.transform(df))
Ожидаемый результат
Распознавание содержимого из определенной предметной области
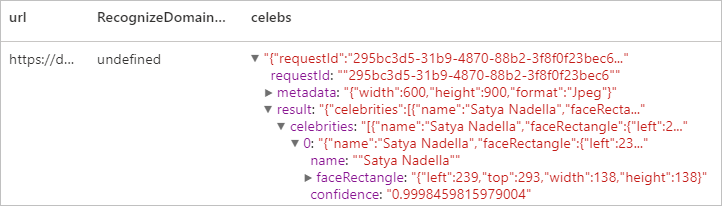
Использование модели предметной области для обнаружения и идентификации отдельного предметного содержимого в изображении, например знаменитостей и достопримечательностей. Например, если изображение содержит людей, vision может использовать модель предметной области для знаменитостей, чтобы определить, являются ли люди, обнаруженные на изображении, известными знаменитостями.
Дайте продолжить использовать фотографию Сатьи в качестве примера.
df = spark.createDataFrame([
("<replace with your file path>/satya.jpeg", )
], ["url", ])
celeb = (RecognizeDomainSpecificContent()
.setLinkedService(ai_service_name)
.setModel("celebrities")
.setImageUrlCol("url")
.setOutputCol("celebs"))
display(celeb.transform(df))
Ожидаемый результат
Очистка ресурсов
Чтобы правильно завершить работу экземпляра Spark, завершите все подключенные сеансы (записные книжки). Пул Apache Spark завершит работу автоматически, когда истечет указанное для него время простоя. Можно также выполнить команду остановки сеанса из строки состояния в верхней правой части записной книжки.
