Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Аналитика документов Azure в средства Foundry — это средство Microsoft Foundry , которое позволяет создавать автоматизированное приложение для обработки данных с помощью технологии машинного обучения. Из этого руководства вы узнаете, как дополнить данные в Azure Synapse Analytics. Вы будете использовать аналитику документов для анализа форм и документов, извлечения текста и данных и возврата структурированных выходных данных JSON. Вы можете быстро получать точные результаты с учетом специфики содержимого, не выполняя избыточные операции вручную или продолжительную обработку и анализ данных.
В этом руководстве демонстрируется использование документной аналитики с SynapseML:
- Извлечение текста и сведений о макете из определенного документа
- Обнаружение и извлечение данных из квитанций
- Обнаружение и извлечение данных из визитных карточек
- Обнаружение и извлечение данных из счетов
- Обнаружение и извлечение данных из удостоверений личности
Если у вас нет подписки Azure, создайте бесплатную учетную запись, прежде чем приступить к работе.
Предварительные условия
- Рабочая область Azure Synapse Analytics с учетной записью хранения Azure Data Lake Storage 2-го поколения, настроенной в качестве хранилища по умолчанию. Вам необходимо быть участником данных BLOB-объектов хранилища для работы с файловой системой Data Lake Storage Gen2.
- Пул Spark в рабочей области Azure Synapse Analytics. Дополнительные сведения см. в статье Создание пула Spark в Azure Synapse.
- Инструкции по предварительной настройке, описанные в руководстве по настройке средств Foundry в Azure Synapse.
Начало работы
Откройте Synapse Studio и создайте записную книжку. Чтобы приступить к работе, импортируйте SynapseML.
import synapse.ml
from synapse.ml.cognitive import *
Настройка аналитики документов
Используйте связанную аналитику документов, настроенную на этапах предварительной настройки.
ai_service_name = "<Your linked service for Document Intelligence>"
Анализ макета
Извлекает текст и сведения о макете из заданного документа. Входной документ должен иметь один из поддерживаемых типов содержимого: application/pdf, image/jpeg, image/png или image/tiff.
Пример входных данных

from pyspark.sql.functions import col, flatten, regexp_replace, explode, create_map, lit
imageDf = spark.createDataFrame([
("<replace with your file path>/layout.jpg",)
], ["source",])
analyzeLayout = (AnalyzeLayout()
.setLinkedService(ai_service_name)
.setImageUrlCol("source")
.setOutputCol("layout")
.setConcurrency(5))
display(analyzeLayout
.transform(imageDf)
.withColumn("lines", flatten(col("layout.analyzeResult.readResults.lines")))
.withColumn("readLayout", col("lines.text"))
.withColumn("tables", flatten(col("layout.analyzeResult.pageResults.tables")))
.withColumn("cells", flatten(col("tables.cells")))
.withColumn("pageLayout", col("cells.text"))
.select("source", "readLayout", "pageLayout"))
Ожидаемые результаты
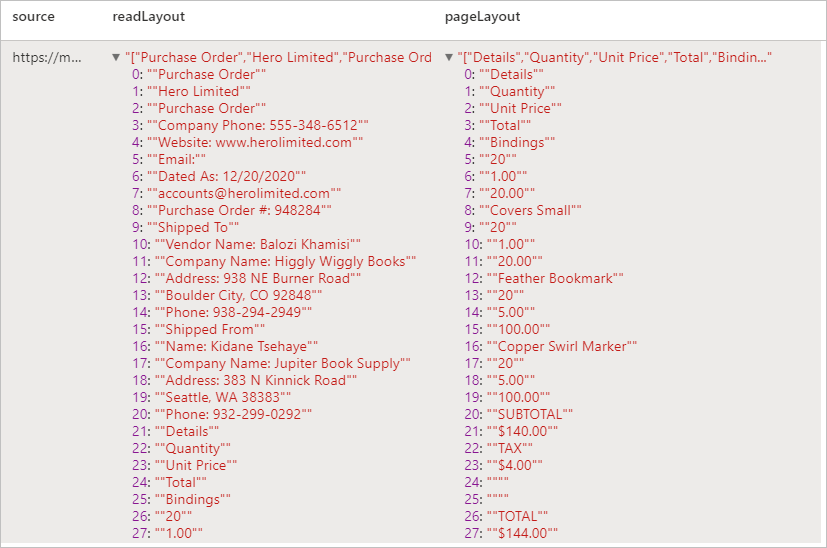
Анализ квитанций
Служба может находить и извлекать данные из квитанций с помощью функции оптического распознавания символов (OCR) и нашей модели квитанций, которая позволяет легко обнаруживать в подобных документах такие структурированные данные, как имя или название продавца, номер его телефона, дата транзакции, сумма транзакция и т. д.
Пример входных данных

imageDf2 = spark.createDataFrame([
("<replace with your file path>/receipt1.png",)
], ["image",])
analyzeReceipts = (AnalyzeReceipts()
.setLinkedService(ai_service_name)
.setImageUrlCol("image")
.setOutputCol("parsed_document")
.setConcurrency(5))
results = analyzeReceipts.transform(imageDf2).cache()
display(results.select("image", "parsed_document"))
Ожидаемые результаты
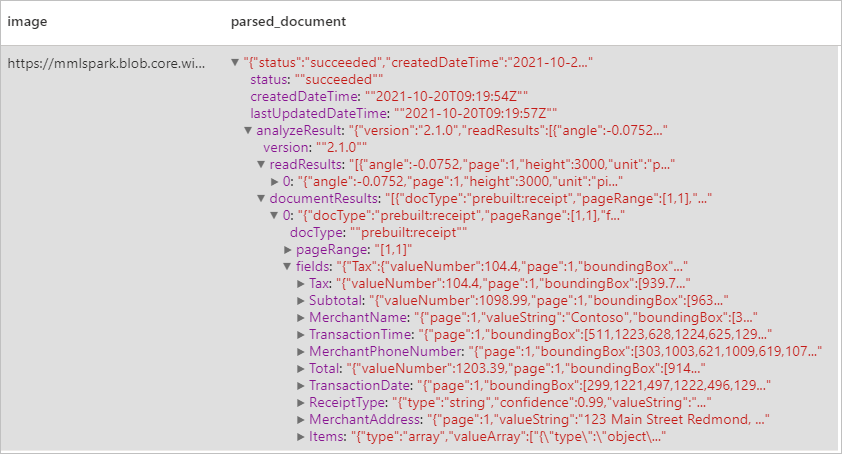
анализ визитных карточек;
Вы можете находить и извлекать данные из визитных карточек с помощью функции оптического распознавания символов (OCR) и нашей модели визитной карточки, которая позволяет легко обнаруживать в подобных документах такие структурированные данные, как имена контактов, названия компаний, номера телефонов, адреса электронной почты и многое другое.
Пример входных данных

imageDf3 = spark.createDataFrame([
("<replace with your file path>/business_card.jpg",)
], ["source",])
analyzeBusinessCards = (AnalyzeBusinessCards()
.setLinkedService(ai_service_name)
.setImageUrlCol("source")
.setOutputCol("businessCards")
.setConcurrency(5))
display(analyzeBusinessCards
.transform(imageDf3)
.withColumn("documents", explode(col("businessCards.analyzeResult.documentResults.fields")))
.select("source", "documents"))
Ожидаемые результаты
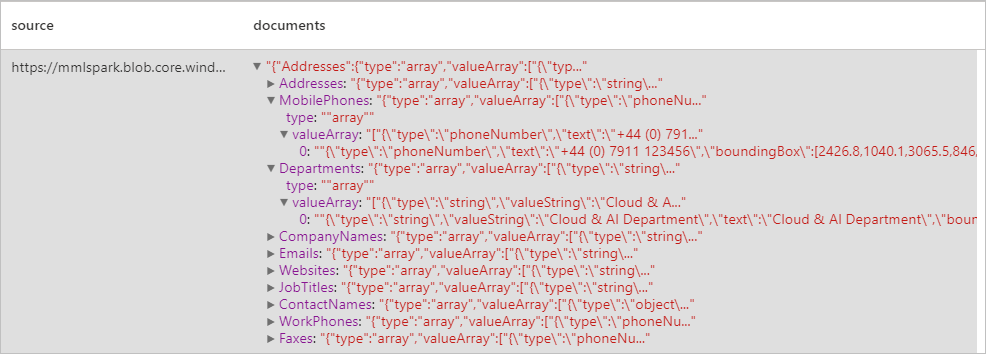
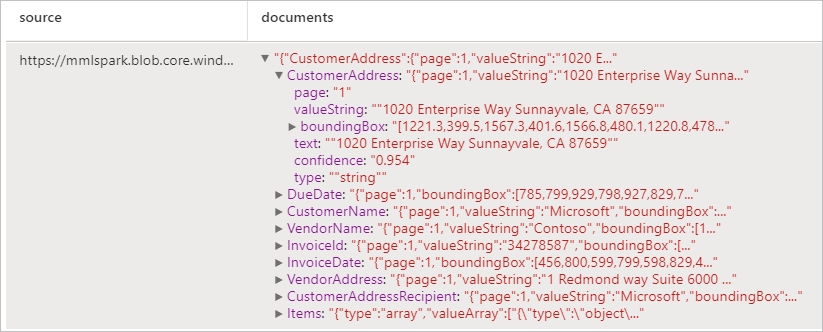
анализ счетов;
Обнаруживает и извлекает данные из счетов с помощью оптического распознавания символов (OCR) и наших моделей понимания счетов на основе глубокого обучения, что позволяет легко извлекать из них структурированные данные, такие как клиент, поставщик, идентификатор счета, срок оплаты, итоговая сумма, сумма к оплате, сумма налогов, адрес отправки, адрес выставления счета, позиции счета и многое другое.
Пример входных данных
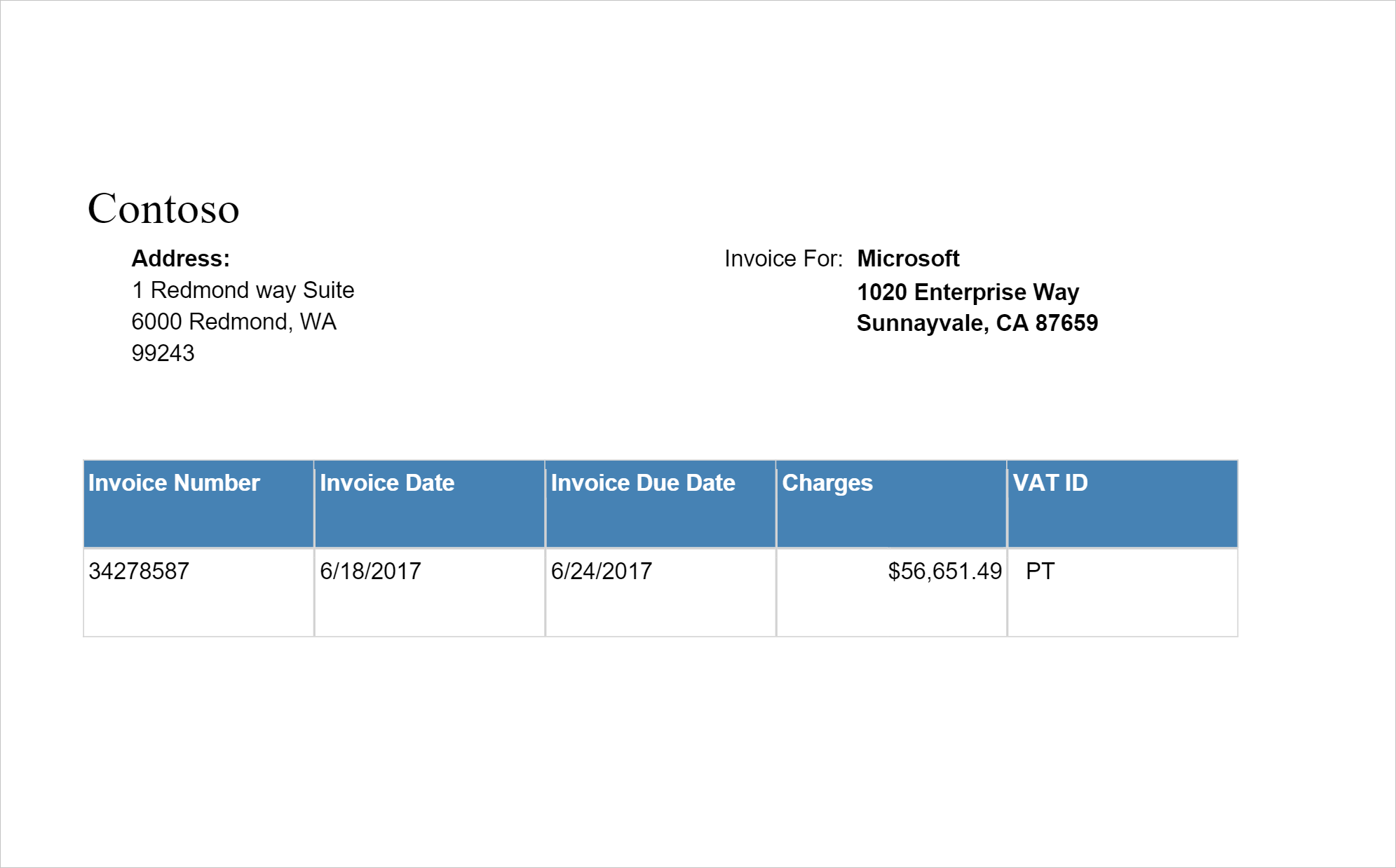
imageDf4 = spark.createDataFrame([
("<replace with your file path>/invoice.png",)
], ["source",])
analyzeInvoices = (AnalyzeInvoices()
.setLinkedService(ai_service_name)
.setImageUrlCol("source")
.setOutputCol("invoices")
.setConcurrency(5))
display(analyzeInvoices
.transform(imageDf4)
.withColumn("documents", explode(col("invoices.analyzeResult.documentResults.fields")))
.select("source", "documents"))
Ожидаемые результаты
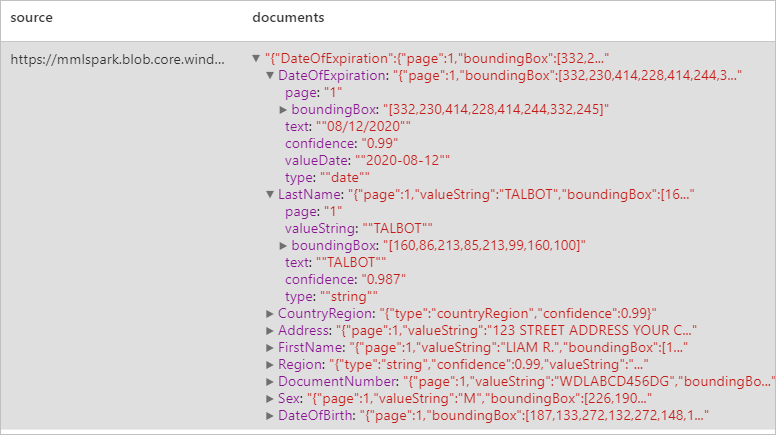
Анализ документов, удостоверяющих личность
Вы можете находить и извлекать данные из удостоверений личности с помощью функции оптического распознавания символов (OCR) и нашей модели для таких удостоверений, которая позволяет легко обнаруживать в подобных документах такие структурированные данные, как имя, фамилия, дата рождения, номер документа и т. д.
Пример входных данных

imageDf5 = spark.createDataFrame([
("<replace with your file path>/id.jpg",)
], ["source",])
analyzeIDDocuments = (AnalyzeIDDocuments()
.setLinkedService(ai_service_name)
.setImageUrlCol("source")
.setOutputCol("ids")
.setConcurrency(5))
display(analyzeIDDocuments
.transform(imageDf5)
.withColumn("documents", explode(col("ids.analyzeResult.documentResults.fields")))
.select("source", "documents"))
Ожидаемые результаты
Очистка ресурсов
Чтобы гарантировать завершение работы экземпляра Spark, закройте все подключенные сеансы (записные книжки). Пул Apache Spark завершит работу автоматически, когда истечет указанное для него время простоя. Можно также выполнить команду остановки сеанса из строки состояния в верхней правой части записной книжки.
