Интеллектуальный кэш в аналитике Azure Synapse Analytics
Интеллектуальный кэш легко работает в фоновом режиме и кэширует данные, чтобы ускорить выполнение Spark по мере чтения из озера данных ADLS 2-го поколения. Он также автоматически обнаруживает изменения в базовых файлах и автоматически обновляет файлы в кэше, предоставляя вам самые последние данные, и когда размер кэша достигает предела, кэш автоматически освобождает наименее прочитанные данные, чтобы освободить место для более новых данных. Эта функция снижает общую стоимость владения, повышая производительность до 65% при последующих считываниях файлов, хранящихся в доступном кэше для файлов Parquet, и на 50% для CSV-файлов.
При запросе файла или таблицы из озера данных обработчик Apache Spark в Synapse вызовет удаленное хранилище ADLS 2-го поколения для чтения базовых файлов. При каждом запросе на чтение одних и того же данных обработчик Spark должен выполнить вызов к удаленному хранилищу ADLS 2-го поколения. Этот избыточный процесс добавляет задержку к общему времени обработки. Spark предоставляет функцию кэширования, при которой необходимо вручную задать кэш и освободить кэш, чтобы свести к минимуму задержку и повысить общую производительность. Однако это может привести к тому, что результаты будут иметь устаревшие данные при изменении базовых данных.
Интеллектуальный кэш Synapse упрощает этот процесс путем автоматического кэширования каждого чтения в выделенном пространстве хранилища кэша на каждом узле Spark. Каждый запрос к файлу проверяет наличие файла в кэше и сравнивает тег из удаленного хранилища, чтобы определить, является ли файл устаревшим. Если файл не существует или устарел, Spark считывает файл и сохраняет его в кэше. При заполнении кэша файл с самым старым временем последнего доступа будет удален из кэша, чтобы освободить место для более новых файлов.
Кэш Synapse — это один кэш на узел. Если вы используете узел среднего размера и работаете с двумя небольшими исполнителями на одном узле среднего размера, эти два исполнителя будут совместно использовать один и тот же кэш.
Включение или отключение кэша
Размер кэша можно изменить на основе процента общего размера диска, доступного для каждого пула Apache Spark. По умолчанию для кэша задано значение "Отключено", но вы можете легко изменить это значение, перемещая ползунок с положения 0 (отключено) на нужный процент размера кэша, чтобы включить его. Мы резервируем не менее 20% свободного места на диске для перетасовки данных. Для ресурсоемких рабочих нагрузок при перетасовке данных можно минимизировать использование кэша или отключить его. Рекомендуется начинать с размера кэша 50% и настраивать его при необходимости. Важно отметить, что если для рабочей нагрузки требуется много места на локальном SSD-диске для кэширования перетасовок данных или кэширования RDD, рассмотрите возможность уменьшения размера кэша, чтобы снизить вероятность сбоя из-за нехватки места в хранилище. Фактический размер доступного хранилища и размера кэша на каждом узле будет зависеть от семейства узлов и размера узла.
Включение кэша для новых пулов Spark
При создании пула Spark перейдите на вкладку дополнительных параметров и при помощи ползунка интеллектуального кэша выберите предпочитаемый размер кэша, чтобы включить данную функцию.

Включение и отключение кэша для существующих пулов Spark
Чтобы включить существующие пулы Spark, в параметрах масштабирования выбранного пула Apache Spark установите ползунок в значение больше 0; чтобы отключить их, переместите ползунок в положение 0.
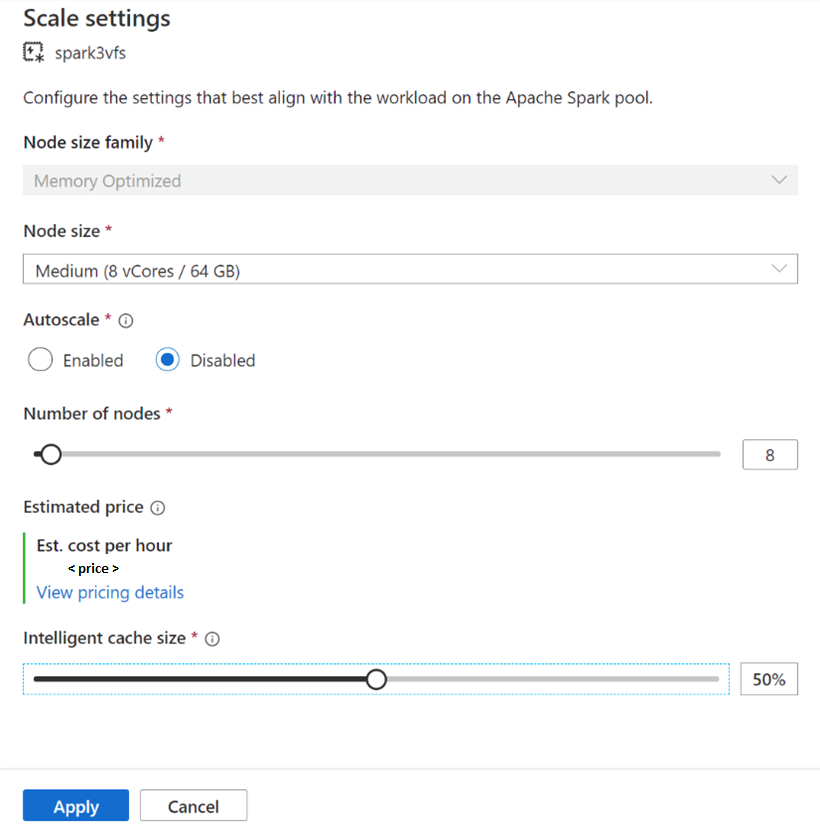
Изменение размера кэша для существующих пулов Spark
Чтобы изменить размер интеллектуального кэша пула, необходимо принудительно перезапустить пул, если в нем есть активные сеансы. Если в пуле Spark есть активный сеанс, отобразится принудительное применение новых параметров. Установите флажок и выберите "Применить", чтобы автоматически перезапустить сеанс.

Включение и отключение кэша в сеансе
Отключите интеллектуальный кэш в сеансе, выполнив следующий код в вашей записной книжке:
%spark
spark.conf.set("spark.synapse.vegas.useCache", "false")
%pyspark
spark.conf.set('spark.synapse.vegas.useCache', 'false')
Включите интеллектуальный кэш, выполнив команду:
%spark
spark.conf.set("spark.synapse.vegas.useCache", "true")
%pyspark
spark.conf.set('spark.synapse.vegas.useCache', 'true')
Когда использовать и не использовать интеллектуальный кэш?
Эта функция поможет вам, если:
Для рабочей нагрузки требуется несколько раз считывать один и тот же файл, а размер файла может соответствовать размеру кэша.
В рабочей нагрузке используются разностные таблицы, форматы файлов Parquet и CSV.
Вы используете Apache Spark версии 3 или новее в Azure Synapse.
Эта функция не будет полезна, если:
Вы считываете файл, размер которого превышает размер кэша, так как начальные фрагменты файлов могут удаляться, а последующие запросы должны будут заново получать данные из удаленного хранилища. В этом случае преимущества интеллектуального кэша не будут вам полезными, и может потребоваться увеличить размер кэша и/или размер узла.
Для рабочей нагрузки требуется большое количество перетасовок, в этом случае отключение интеллектуального кэша освободит доступное пространство, чтобы предотвратить сбой задания из-за нехватки дискового пространства.
Вы используете пул Spark 3.1, вам потребуется обновить пул до последней версии Spark.
Подробнее
Дополнительные сведения об Apache Spark см. в следующих статьях:
- Основные сведения об Apache Spark
- Основные понятия Apache Spark
- Среда выполнения Azure Synapse для Apache Spark 3.2
- Размер и конфигурации пула Apache Spark
Дополнительные сведения о настройке параметров сеанса Spark
Следующие шаги
Пул Apache Spark предоставляет вычислительные возможности с открытым кодом для обработки больших данных, позволяющие загружать, моделировать, обрабатывать и распределять данные для более быстрого получения аналитических сведений. Дополнительные сведения о создании конфигурации для запуска рабочей нагрузки Spark см. в следующих руководствах: