Управление пакетами на уровне сеанса
Помимо пакетов уровня пула, можно также указать библиотеки с областью действия сеанса в начале сеанса записной книжки. Библиотеки уровня сеанса позволяют указать и использовать пакеты Python, JAR и R в сеансе записной книжки.
При использовании библиотек уровня сеанса важно учитывать следующие моменты:
- При установке библиотек на уровне сеанса доступ к указанным библиотекам будет иметь только текущая записная книжка.
- Эти библиотеки не влияют на другие сеансы или задания, использующие тот же пул Spark.
- Эти библиотеки устанавливаются поверх базовых библиотек среды выполнения и пула и имеют наивысший приоритет.
- Библиотеки уровня сеанса не сохраняются в разных сеансах.
Пакеты Python на уровне сеанса
Управление пакетами Python для уровня сеанса с помощью файла environment.yml
Чтобы определить пакеты Python на уровне сеанса:
- Перейдите к выбранному пулу Spark и убедитесь, что вы включили библиотеки на уровне сеанса. Чтобы включить этот параметр, перейдите на вкладку Управление>Пул Apache Spark>Пакеты.
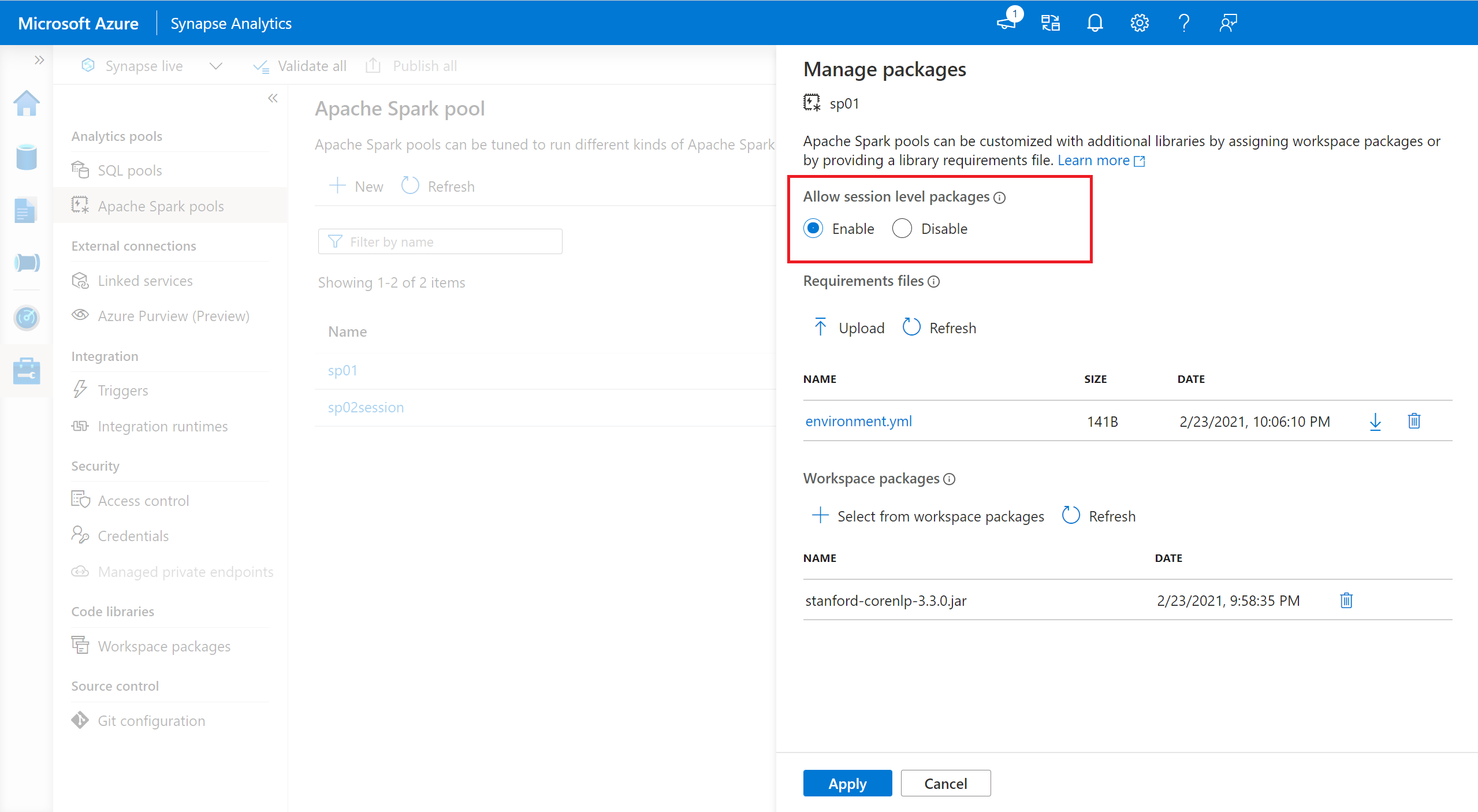
- После применения параметра можно открыть записную книжку и выбрать Настроитьпакеты сеансов>.

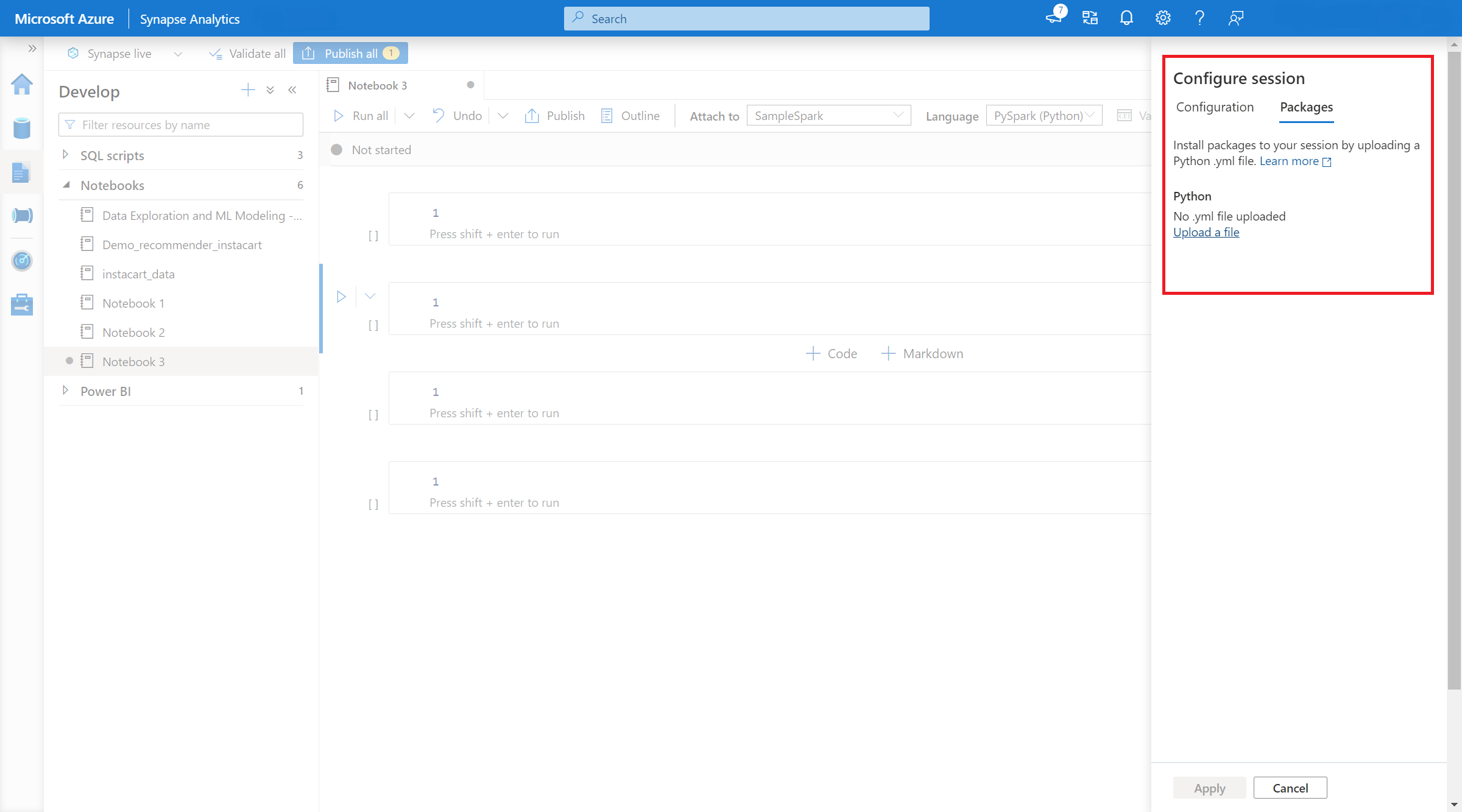
- Здесь можно отправить файл Conda environment.yml для установки или обновления пакетов в рамках сеанса. Указанные библиотеки присутствуют после запуска сеанса. Эти библиотеки больше не будут доступны после завершения сеанса.

Управление пакетами Python на уровне сеанса с помощью команд %pip и %conda
С помощью популярных команд %pip и %conda можно установить дополнительные сторонние библиотеки или пользовательские библиотеки во время сеанса записной книжки Apache Spark. В этом разделе мы используем команды %pip для демонстрации нескольких распространенных сценариев.
Примечание
- Если вы хотите установить новые библиотеки, рекомендуется поместить команды %pip и %conda в первую ячейку записной книжки. Интерпретатор Python будет перезапущен после управления библиотекой уровня сеанса, чтобы внести изменения в силу.
- Эти команды управления библиотеками Python будут отключены при выполнении заданий конвейера. Если вы хотите установить пакет в конвейере, необходимо использовать возможности управления библиотеками на уровне пула.
- Библиотеки Python на уровне сеанса автоматически устанавливаются как на драйвере, так и на рабочих узлах.
- Следующие команды %conda не поддерживаются: create, clean, compare, activate, deactivate, run, package.
- Полный список команд можно найти в разделе %pip commands и %conda commands .
Установка стороннего пакета
Вы можете легко установить библиотеку Python из PyPI.
# Install vega_datasets
%pip install altair vega_datasets
Чтобы проверить результат установки, можно выполнить следующий код для визуализации vega_datasets
# Create a scatter plot
# Plot Miles per gallon against the horsepower across different region
import altair as alt
from vega_datasets import data
cars = data.cars()
alt.Chart(cars).mark_point().encode(
x='Horsepower',
y='Miles_per_Gallon',
color='Origin',
).interactive()
Установка пакета wheel из учетной записи хранения
Чтобы установить библиотеку из хранилища, необходимо подключиться к учетной записи хранения, выполнив следующие команды.
from notebookutils import mssparkutils
mssparkutils.fs.mount(
"abfss://<<file system>>@<<storage account>.dfs.core.windows.net",
"/<<path to wheel file>>",
{"linkedService":"<<storage name>>"}
)
А затем можно использовать команду %pip install , чтобы установить необходимый пакет wheel.
%pip install /<<path to wheel file>>/<<wheel package name>>.whl
Установка другой версии встроенной библиотеки
Для просмотра встроенной версии определенного пакета можно использовать следующую команду. Мы используем pandas в качестве примера
%pip show pandas
Результатом будет следующий журнал:
Name: pandas
Version: **1.2.3**
Summary: Powerful data structures for data analysis, time series, and statistics
Home-page: https://pandas.pydata.org
... ...
Вы можете использовать следующую команду для переключения pandas на другую версию, скажем, 1.2.4.
%pip install pandas==1.2.4
Удаление библиотеки уровня сеанса
Если вы хотите удалить пакет, установленный в этом сеансе записной книжки, можно обратиться к приведенным ниже командам. Однако удалить встроенные пакеты невозможно.
%pip uninstall altair vega_datasets --yes
Использование команды %pip для установки библиотек из файлаrequirement.txt
%pip install -r /<<path to requirement file>>/requirements.txt
Пакеты Java или Scala на уровне сеанса
Чтобы указать пакеты Java или Scala с областью действия сеанса, можно использовать параметр %%configure:
%%configure -f
{
"conf": {
"spark.jars": "abfss://<<file system>>@<<storage account>.dfs.core.windows.net/<<path to JAR file>>",
}
}
Примечание
- Мы рекомендуем выполнить %%configure в начале записной книжки. Полный список допустимых параметров можно найти в этом документе.
Пакеты R уровня сеанса (предварительная версия)
Azure Synapse Пулы Аналитики включают множество популярных библиотек R. Вы также можете установить дополнительные сторонние библиотеки во время сеанса записной книжки Apache Spark.
Примечание
- Эти команды управления библиотеками R будут отключены при выполнении заданий конвейера. Если вы хотите установить пакет в конвейере, необходимо использовать возможности управления библиотеками на уровне пула.
- Библиотеки R уровня сеанса автоматически устанавливаются как на драйвере, так и на рабочих узлах.
Установка пакета
Вы можете легко установить библиотеку R из CRAN.
# Install a package from CRAN
install.packages(c("nycflights13", "Lahman"))
Вы также можете использовать моментальные снимки CRAN в качестве репозитория, чтобы каждый раз скачивать одну и ту же версию пакета.
install.packages("highcharter", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
Использование средств разработки для установки пакетов
Библиотека devtools упрощает разработку пакетов для ускорения выполнения общих задач. Эта библиотека устанавливается в среде выполнения Azure Synapse Analytics по умолчанию.
С помощью devtools можно указать определенную версию устанавливаемой библиотеки. Эти библиотеки будут установлены на всех узлах в кластере.
# Install a specific version.
install_version("caesar", version = "1.0.0")
Аналогичным образом можно установить библиотеку непосредственно из GitHub.
# Install a GitHub library.
install_github("jtilly/matchingR")
В настоящее время в Azure Synapse Analytics поддерживаются следующие devtools функции:
| Get-Help | Описание |
|---|---|
| install_github() | Устанавливает пакет R из GitHub. |
| install_gitlab() | Устанавливает пакет R из GitLab. |
| install_bitbucket() | Устанавливает пакет R из BitBucket. |
| install_url() | Устанавливает пакет R по произвольному URL-адресу. |
| install_git() | Установка из произвольного репозитория Git |
| install_local() | Установка из локального файла на диске |
| install_version() | Установка из определенной версии на CRAN |
Просмотр установленных библиотек
Вы можете запросить все библиотеки, установленные в сеансе library , с помощью команды .
library()
Для проверки версии библиотеки packageVersion можно использовать функцию :
packageVersion("caesar")
Удаление пакета R из сеанса
Функцию detach можно использовать для удаления библиотеки из пространства имен. Эти библиотеки остаются на диске до тех пор, пока не будут загружены снова.
# detach a library
detach("package: caesar")
Чтобы удалить пакет уровня сеанса из записной книжки remove.packages() , используйте команду . Это изменение библиотеки не влияет на другие сеансы в том же кластере. Пользователи не могут удалять встроенные библиотеки среды выполнения Azure Synapse Analytics по умолчанию.
remove.packages("caesar")
Примечание
Вы не можете удалить основные пакеты, такие как SparkR, SparklyR или R.
Библиотеки R на уровне сеанса и SparkR
Библиотеки с областью действия записной книжки доступны в рабочих роях SparkR.
install.packages("stringr")
library(SparkR)
str_length_function <- function(x) {
library(stringr)
str_length(x)
}
docs <- c("Wow, I really like the new light sabers!",
"That book was excellent.",
"R is a fantastic language.",
"The service in this restaurant was miserable.",
"This is neither positive or negative.")
spark.lapply(docs, str_length_function)
Библиотеки R на уровне сеанса и SparklyR
С помощью spark_apply() в SparklyR можно использовать любой пакет R внутри Spark. По умолчанию в sparklyr::spark_apply() аргумент packages имеет значение FALSE. При этом библиотеки в текущих libPaths копируются в рабочие роли, что позволяет импортировать и использовать их в рабочих ролей. Например, можно выполнить следующую команду, чтобы создать сообщение, зашифрованное с помощью цезаря, с помощью sparklyr::spark_apply():
install.packages("caesar", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
spark_version <- "3.2"
config <- spark_config()
sc <- spark_connect(master = "yarn", version = spark_version, spark_home = "/opt/spark", config = config)
apply_cases <- function(x) {
library(caesar)
caesar("hello world")
}
sdf_len(sc, 5) %>%
spark_apply(apply_cases, packages=FALSE)
Дальнейшие действия
- Просмотр библиотек по умолчанию: поддержка версий Apache Spark
- Управление пакетами за пределами портала Synapse Studio — Управление пакетами с помощью команд Az и REST API.