Пулы с ускорением GPU Apache Spark в Azure Synapse Analytics (предварительная версия)
Apache Spark — это платформа параллельной обработки, которая поддерживает обработку в памяти, чтобы повысить производительность приложений для анализа больших данных. Apache Spark в Azure Synapse Analytics — это одна из реализаций Apache Spark в облаке, предоставляемая корпорацией Майкрософт.
Azure Synapse теперь предлагает возможность создания пулов Azure Synapse с поддержкой GPU для выполнения рабочих нагрузок Spark с помощью базовых библиотек RAPIDS, использующих высокую производительность параллельной обработки на GPU для более быстрого выполнения операций. Акселератор RAPIDS для Apache Spark позволяет запускать существующие приложения Spark без изменения кода, просто включив параметр конфигурации, предварительно настроенный для пула с поддержкой GPU. Вы можете включить или выключить ускорение GPU на основе RAPIDS для рабочей нагрузки или ее частей, задав следующую конфигурацию:
spark.conf.set('spark.rapids.sql.enabled','true/false')
Примечание.
Пулы Azure Synapse с поддержкой GPU в настоящее время доступны в виде общедоступной предварительной версии.
Предупреждение
- Предварительная версия gpu ограничена средой выполнения Apache Spark 3.2 (объявленная поддержка). Дата окончания поддержки, объявленная для среды выполнения Azure Synapse для Apache Spark 3.2, была объявлена 8 июля 2023 г. После завершения поддержки объявленные среды выполнения не будут иметь исправлений ошибок и компонентов. Исправления безопасности будут выборочно портироваться на устаревшие версии с учетом оценки рисков. Эта среда выполнения и соответствующая предварительная версия gpu с ускорением GPU в Spark 3.2 будут прекращены и отключены с 8 июля 2024 г.
- Предварительная версия ускорения GPU теперь не поддерживается в среде выполнения Azure Synapse 3.1 (неподдерживаемая версия). Среда выполнения Azure Synapse для Apache Spark 3.1 достигла срока поддержки с 26 января 2023 г. с официальной поддержкой, прекращенной с 26 января 2024 г., и никаких дальнейших обращений к запросам в службу поддержки, исправлений ошибок или обновлений системы безопасности после этой даты.
Ускоритель RAPIDS для Apache Spark
Ускоритель RAPIDS для Spark — это подключаемый модуль, который позволяет переопределять физический план задания Spark с помощью поддерживаемых операций GPU, а также выполнять эти операции на GPU, тем самым ускоряя обработку. Эта библиотека в настоящее время предлагается в виде общедоступной предварительной версии и не поддерживает все операции Spark (ниже приведен список поддерживаемых в настоящее время операторов, а поддержка других операторов будет последовательно добавляться в новых выпусках).
Параметры конфигурации кластера
Подключаемый модуль ускорителя RAPIDS поддерживает сопоставление между GPU и исполнителями только "один к одному". Это означает, что для задания Spark потребуется запросить ресурсы исполнителя и драйвера, которые поместятся в ресурсах пула (в соответствии с количеством доступных GPU и ядер ЦП). Чтобы выполнить это условие и обеспечить оптимальное использование всех ресурсов пула, требуется следующая конфигурация драйверов и исполнителей для приложения Spark, работающего в пулах с поддержкой GPU:
| Размер пула | Варианты размеров драйвера | Ядра драйверов | Память драйвера (ГБ) | Ядра исполнителя | Память исполнителя (ГБ) | Число исполнителей |
|---|---|---|---|---|---|---|
| GPU-Large | Небольшой драйвер | 4 | 30 | 12 | 60 | Количество узлов в пуле |
| GPU-Large | Средний драйвер | 7 | 30 | 9 | 60 | Количество узлов в пуле |
| GPU-XLarge | Средний драйвер | 8 | 40 | 14 | 80 | 4 * Количество узлов в пуле |
| GPU-XLarge | Большой драйвер | 12 | 40 | 13 | 80 | 4 * Количество узлов в пуле |
Рабочая нагрузка, которая не соответствует ни одной из указанных выше конфигураций, не будет принята. Это делается для того, чтобы задания Spark выполнялись с наиболее эффективной и производительной конфигурацией с использованием всех доступных ресурсов в пуле.
Пользователь может задать указанную выше конфигурацию в рабочей нагрузке. Для записных книжек пользователь может использовать магическую команду %%configure, чтобы установить одну из указанных выше конфигураций, как показано ниже.
Например, при использовании большого пула с тремя узлами:
%%configure -f
{
"driverMemory": "30g",
"driverCores": 4,
"executorMemory": "60g",
"executorCores": 12,
"numExecutors": 3
}
Выполнение примера задания Spark с помощью записной книжки в пуле Azure Synapse с ускорением GPU
Прежде чем продолжать работу с этим разделом, рекомендуем ознакомиться с основными понятиями использования записной книжки в Azure Synapse Analytics. Рассмотрим шаги для запуска приложения Spark с использованием ускорения GPU. Приложение Spark можно написать на любом из четырех языков, поддерживаемых Synapse: PySpark (Python), Spark (Scala), SparkSQL и .NET для Spark (C#).
Создайте пул с поддержкой GPU.
Создайте записную книжку и подключите ее к пулу с поддержкой GPU, созданному на первом шаге.
Задайте конфигурации, как описано в предыдущем разделе.
Создайте образец кадра данных, скопировав приведенный ниже код в первую ячейку записной книжки.
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.Row
import scala.collection.JavaConversions._
val schema = StructType( Array(
StructField("emp_id", IntegerType),
StructField("name", StringType),
StructField("emp_dept_id", IntegerType),
StructField("salary", IntegerType)
))
val emp = Seq(Row(1, "Smith", 10, 100000),
Row(2, "Rose", 20, 97600),
Row(3, "Williams", 20, 110000),
Row(4, "Jones", 10, 80000),
Row(5, "Brown", 40, 60000),
Row(6, "Brown", 30, 78000)
)
val empDF = spark.createDataFrame(emp, schema)
- Теперь составим статистическое выражение, чтобы получить максимальную зарплату по идентификатору отдела, и выведем результат на экран:
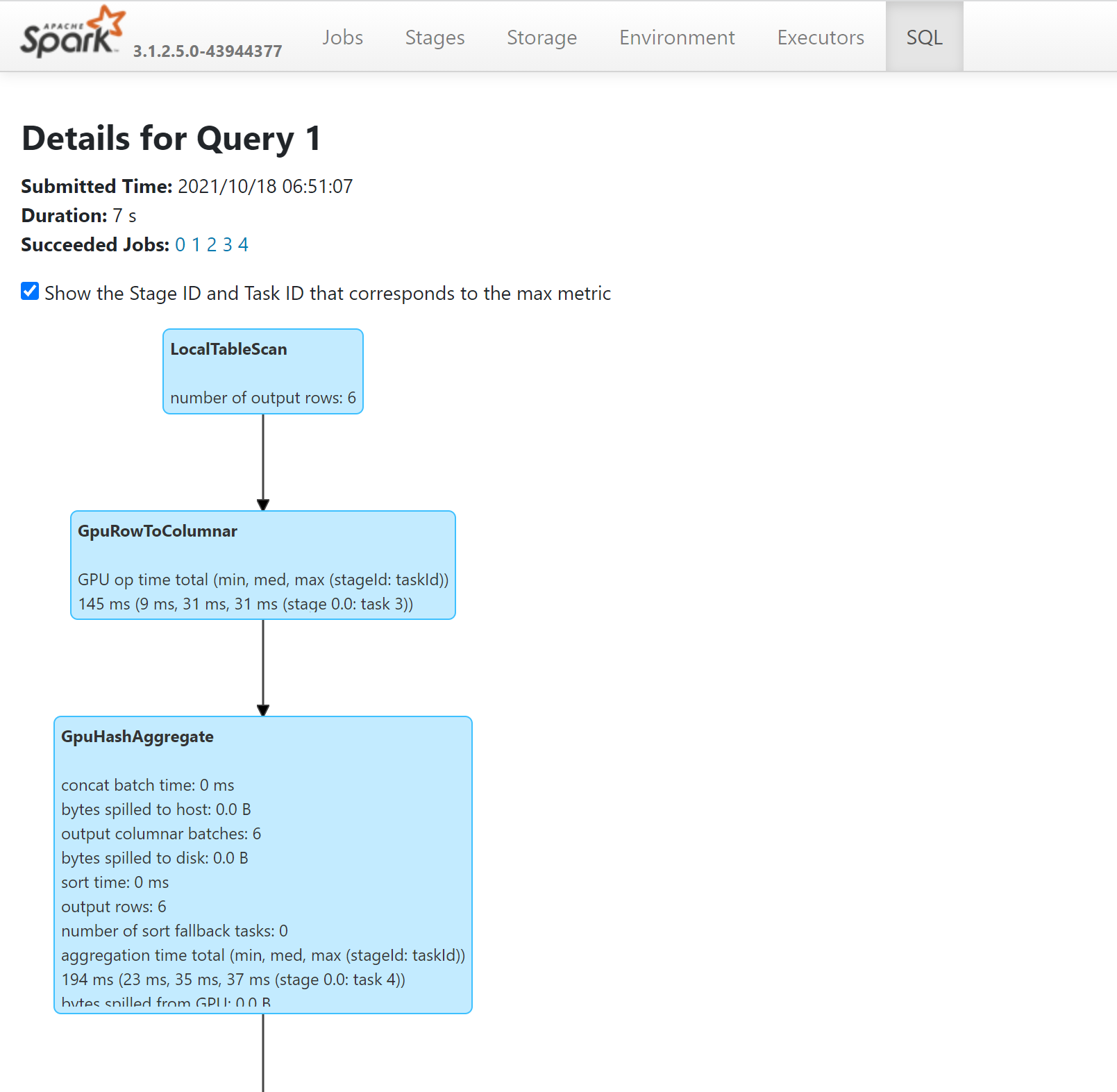
- Операции в запросе, запущенном на GPU, можно просмотреть план SQL с помощью сервера журнала Spark:
Настройка приложения для GPU
Производительность большинства заданий Spark можно повысить за счет изменения параметров конфигурации по умолчанию. То же справедливо для заданий, использующих подключаемый модуль акселератора RAPIDS для Apache Spark.
Квоты и ограничения ресурсов в пулах Azure Synapse с поддержкой GPU
Уровень рабочей области
Для каждой рабочей области Azure Synapse действует квота по умолчанию — 50 виртуальных ядер GPU. Чтобы увеличить квоту ядер GPU, отправьте запрос в службу поддержки через портал Azure.