Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
.NET для Apache Spark предоставляет бесплатную, кроссплатформенную поддержку .NET для Spark.
Он предоставляет привязки .NET для Spark, что позволяет получить доступ к API Spark через C# и F#. С помощью .NET для Apache Spark можно также создавать и выполнять определяемые пользователем функции для Spark, написанные в .NET. API .NET для Spark позволяют получить доступ ко всем аспектам кадров данных Spark, которые помогают анализировать данные, включая Spark SQL, Delta Lake и структурированную потоковую передачу.
Вы можете анализировать данные с помощью .NET для Apache Spark с помощью определений пакетного задания Spark или с помощью интерактивных записных книжек Azure Synapse Analytics. Из этой статьи вы узнаете, как использовать .NET для Apache Spark с Azure Synapse с помощью обоих методов.
Это важно
.NET для Apache Spark — это проект с открытым исходным кодом в .NET Foundation, который в настоящее время требует библиотеки .NET 3.1, которая достигла состояния вне поддержки. Мы хотели бы сообщить пользователям Azure Synapse Spark об удалении библиотеки .NET для Apache Spark в среде выполнения Azure Synapse для Apache Spark версии 3.3. Пользователи могут обратиться к политике поддержки .NET для получения дополнительных сведений об этом вопросе.
В результате пользователи больше не смогут использовать API Apache Spark через C# и F#, или выполнить код C# в записных книжках в Synapse или с помощью определений заданий Apache Spark в Synapse. Важно отметить, что это изменение влияет только на среду выполнения Azure Synapse для Apache Spark 3.3 и выше.
Мы будем продолжать поддерживать .NET для Apache Spark во всех предыдущих версиях среды выполнения Azure Synapse в соответствии с их этапами жизненного цикла. Однако у нас нет планов поддержки .NET для Apache Spark в Среде выполнения Azure Synapse для Apache Spark 3.3 и будущих версий. Рекомендуется перенести пользователей с существующими рабочими нагрузками, написанными на C# или F#, на Python или Scala. Пользователям рекомендуется учитывать эти сведения и планировать их соответствующим образом.
Отправка пакетных заданий с помощью определения задания Spark
Ознакомьтесь с руководством, чтобы узнать, как использовать Azure Synapse Analytics для создания определений заданий Apache Spark для пулов Synapse Spark. Если вы не упаковывали приложение для отправки в Azure Synapse, выполните следующие действия.
dotnetНастройте зависимости приложения для совместимости с Synapse Spark. Требуемая версия .NET Spark будет отмечена в интерфейсе Synapse Studio в конфигурации пула Apache Spark под панелью элементов управления.
Создайте проект как консольное приложение .NET, которое выводит исполняемый файл Ubuntu x86.
<Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <OutputType>Exe</OutputType> <TargetFramework>netcoreapp3.1</TargetFramework> </PropertyGroup> <ItemGroup> <PackageReference Include="Microsoft.Spark" Version="2.1.0" /> </ItemGroup> </Project>Выполните следующие команды, чтобы опубликовать приложение. Обязательно замените mySparkApp на путь к вашему приложению.
cd mySparkApp dotnet publish -c Release -f netcoreapp3.1 -r ubuntu.18.04-x64Запакуйте содержимое папки публикации,
publish.zipнапример, которая была создана в результате шага 1. Все сборки должны находиться в корне ZIP-файла, и не должно быть промежуточного слоя папок. Это означает, что при распаковкеpublish.zipвсе сборки извлекаются в текущий рабочий каталог.В Windows:
С помощью Windows PowerShell или PowerShell 7 создайте .zip из содержимого каталога публикации.
Compress-Archive publish/* publish.zip -UpdateВ Linux:
Откройте оболочку bash, перейдите в каталог bin со всеми опубликованными бинарными файлами и выполните следующую команду.
zip -r publish.zip
.NET для Apache Spark в записных книжках Azure Synapse Analytics
Записные книжки — отличный вариант для создания прототипов конвейеров и сценариев Apache Spark для .NET. Вы можете начать работу с, понимать, фильтровать, отображать и визуализировать данные быстро и эффективно.
Инженеры по обработке и анализу данных, специалисты по обработке и анализу данных, бизнес-аналитики и инженеры машинного обучения могут совместно работать над общим интерактивным документом. Вы увидите немедленные результаты исследования данных и можете визуализировать данные в одной записной книжке.
Использование .NET для записных книжек Apache Spark
При создании записной книжки вы выбираете ядро языка, которое вы хотите выразить бизнес-логику. Поддержка ядра доступна для нескольких языков, включая C#.
Чтобы использовать .NET для Apache Spark в записной книжке Azure Synapse Analytics, выберите .NET Spark (C#) в качестве ядра и подключите записную книжку к существующему бессерверному пулу Apache Spark.
Записная книжка .NET Spark основана на интерактивных интерфейсах .NET и предоставляет интерактивные возможности C# с возможностью использования .NET для Spark вне поля с уже предопределенной переменной spark сеанса Spark.
Установка пакетов NuGet в записных книжках
Вы можете установить выбранные пакеты NuGet в вашей записной книжке с помощью #r nuget магической команды перед именем пакета NuGet. На следующей схеме показан пример:
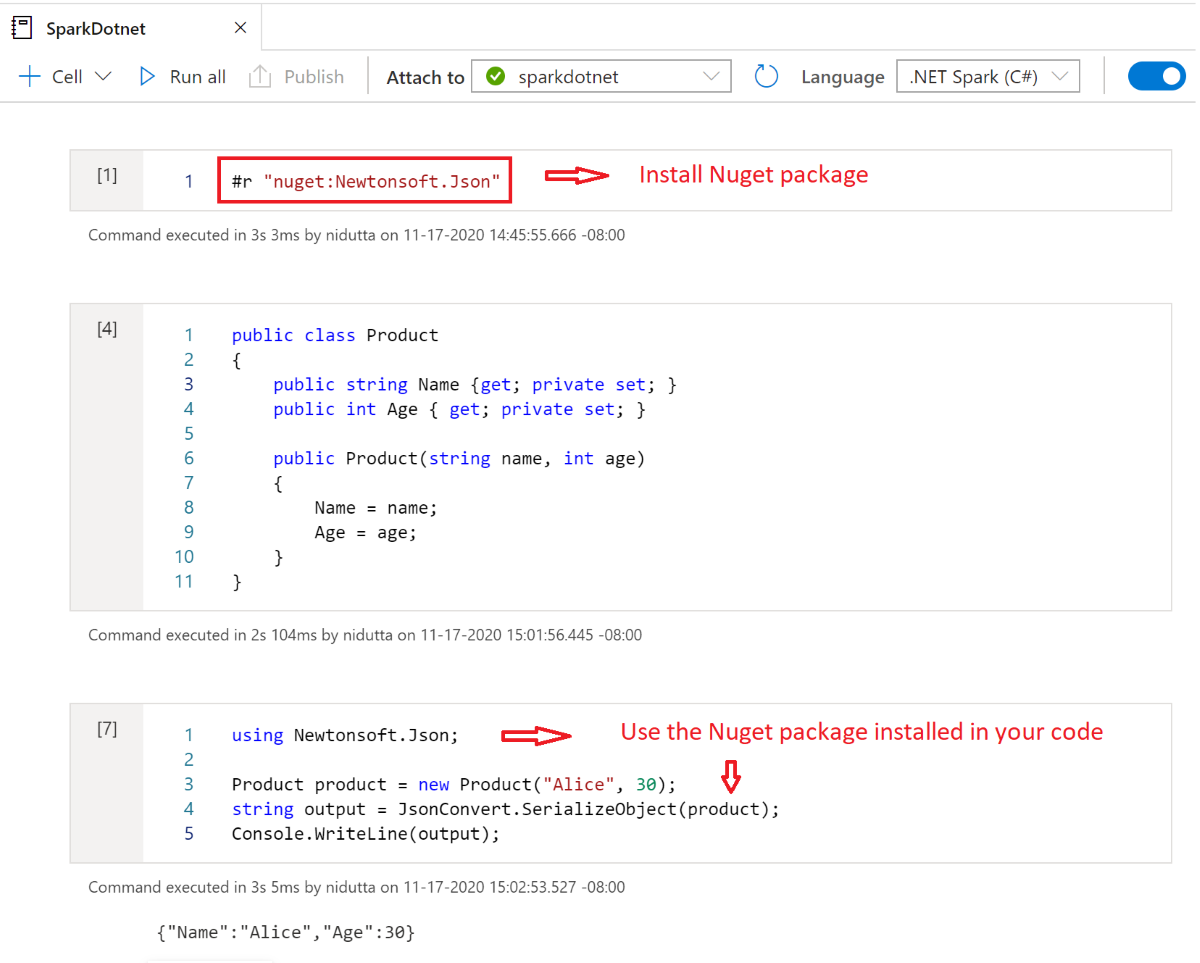
Дополнительные сведения о работе с пакетами NuGet в записных книжках см. в интерактивной документации по .NET.
Функции ядра .NET для Apache Spark C#
При использовании .NET для Apache Spark в записной книжке Azure Synapse Analytics доступны следующие функции:
- Декларативный HTML: создание выходных данных из ячеек с помощью синтаксиса HTML, таких как заголовки, маркированные списки и даже отображение изображений.
- Простые операторы C# (например, присваивания, вывод на консоль, генерация исключений и т. д.).
- Блоки кода C# с несколькими строками (например, операторы, циклы foreach, определения классов и т. д.).
- Доступ к стандартной библиотеке C# (например, System, LINQ, Enumerables и т. д.).
- Поддержка функций языка C# 8.0.
-
sparkв качестве предварительно определенной переменной для предоставления доступа к сеансу Apache Spark. - Поддержка определения определяемых пользователем функций .NET, которые могут выполняться в Apache Spark. Мы рекомендуем создавать и вызывать определяемые пользователем функции в .NET для интерактивных сред Apache Spark, чтобы изучить, как использовать определяемые пользователем функции в .NET для интерактивных интерфейсов Apache Spark.
- Поддержка визуализации результатов из заданий Spark с помощью различных диаграмм (таких как линейная, столбчатая или гистограмма) и расположений (таких как одинарные, наложенные и т. д.) с помощью библиотеки
XPlot.Plotly. - Возможность интегрировать пакеты NuGet в C# ноутбук.
Устранение неполадок
OutOfMemoryError: java heap space в org.apache.spark
Dotnet Spark 1.0.0 использует другую архитектуру отладки, чем 1.1.1+. Чтобы опубликовать версию, нужно использовать 1.0.0, а для локальной отладки — версию 1.1.1+.