Общие сведения об API-интерфейсах подключения и отключения файлов в Azure Synapse Analytics
Команда Azure Synapse Studio создала два новых API подключения и отключения в пакете служебных программ Microsoft для Spark (mssparkutils). Эти API-интерфейсы можно использовать для подключения удаленного хранилища (Хранилища BLOB-объектов Azure или Azure Data Lake Storage 2-го поколения) ко всем рабочим узлам (узлу драйвера и рабочим узлам). После размещения хранилища можно использовать локальный API-интерфейс файлов для доступа к данным, как будто они хранятся в локальной файловой системе. Дополнительную информацию см. в статье Общие сведения о Microsoft Spark Utilities.
В этой статье показано, как использовать API-интерфейсы подключения и отключения в рабочей области. Вы узнаете:
- Как подключить Data Lake Storage 2-го поколения или Хранилище BLOB-объектов.
- Как получить доступ к файлам в точке подключения с помощью API локальной файловой системы.
- Как получить доступ к файлам в точке подключения с помощью API
mssparktuils fs. - Как получить доступ к файлам в точке подключения с помощью API Spark для чтения.
- Как отключить точку подключения.
Предупреждение
Подключение общей папки Azure временно отключено. Вместо этого можно использовать подключение Data Lake Storage 2-го поколения или Хранилища BLOB-объектов Azure, как описано в следующем разделе.
Azure Data Lake Storage 1-го поколения не поддерживается. Чтобы перейти на Data Lake Storage 2-го поколения, следуйте руководству по миграции Azure Data Lake Storage 1-го поколения во 2-е перед использованием API подключения.
Подключение хранилища
В этом разделе в качестве примера показано пошаговое подключение Data Lake Storage 2-го поколения. Подключение Хранилища BLOB-объектов работает аналогично.
В этом примере предполагается, что у вас есть одна учетная запись Data Lake Storage 2-го поколения с именем storegen2. У учетной записи есть один контейнер с именем mycontainer, который вы хотите подключить в /test в пуле Spark.
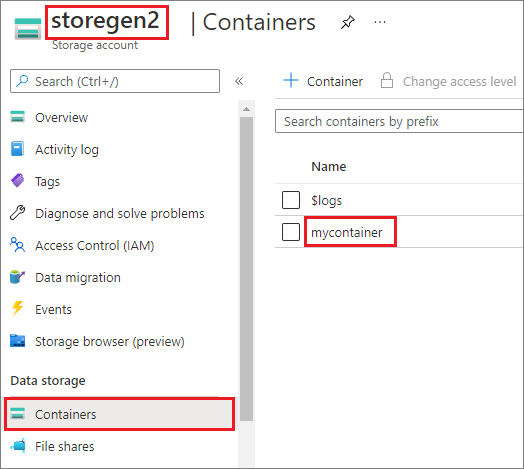
Чтобы подключить контейнер mycontainer, программе mssparkutils сначала необходимо проверить, есть ли у вас разрешение на доступ к контейнеру. В настоящее время Azure Synapse Analytics поддерживает три метода проверки подлинности для выполнения операции подключения: linkedService, accountKey и sastoken.
Подключение с помощью связанной службы (рекомендуется)
Рекомендуется выполнять подключение через связанную службу. Этот метод позволяет избежать утечек безопасности, так как mssparkutils не сохраняет значения секретов и проверки подлинности. Вместо этого mssparkutils всегда извлекает значения проверки подлинности из связанной службы для запроса данных BLOB-объектов из удаленного хранилища.
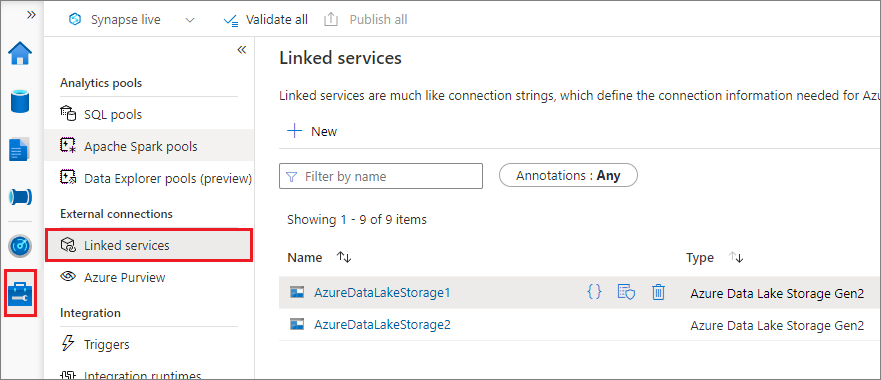
Связанную службу можно создать для Data Lake Storage 2-го поколения или Хранилища BLOB-объектов. В настоящее время Azure Synapse Analytics поддерживает два метода проверки подлинности при создании связанной службы.
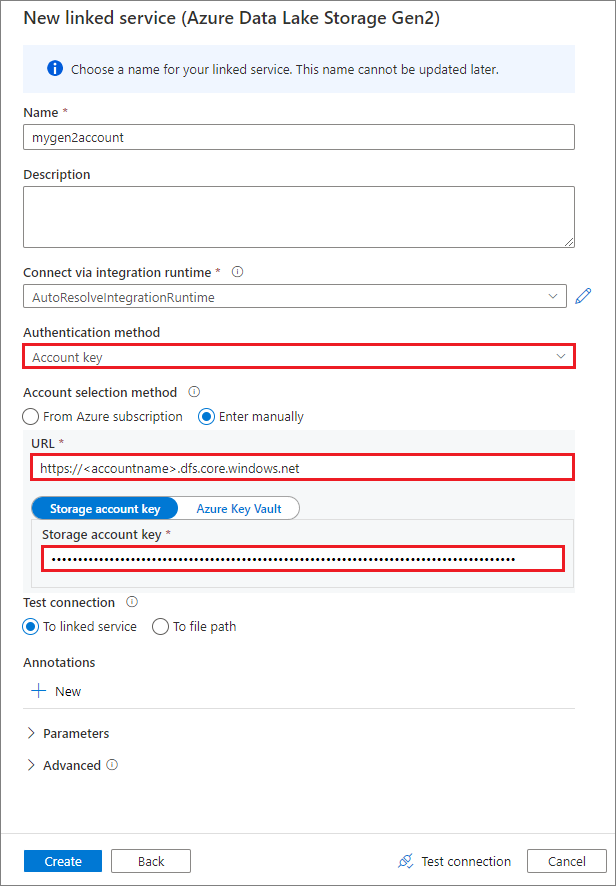
Создание связанной службы с помощью ключа учетной записи
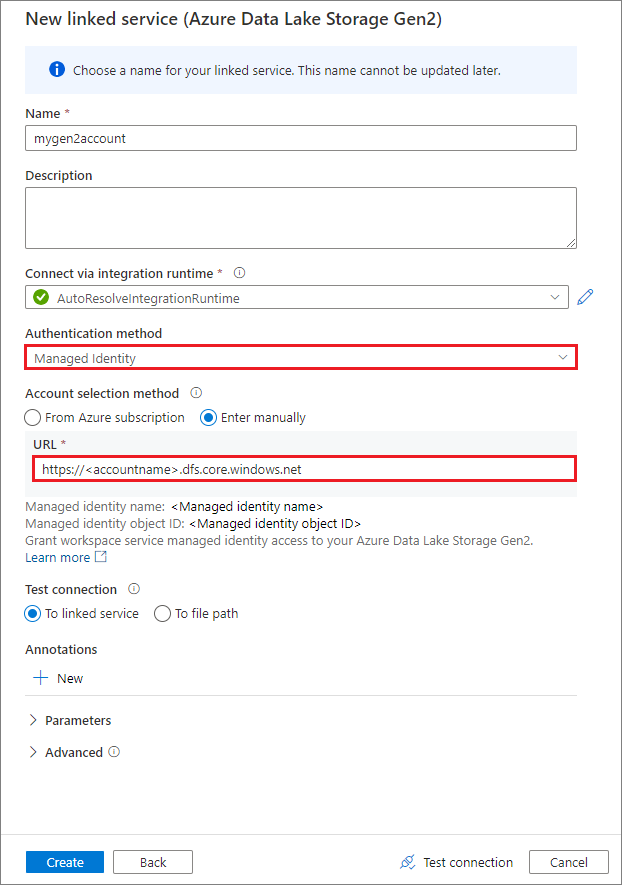
Создание связанной службы с помощью управляемого удостоверения
Внимание
- Если созданная выше связанная служба для Azure Data Lake Storage 2-го поколения использует управляемую частную конечную точку (с URI DFS), необходимо создать другую управляемую частную конечную точку с помощью параметра Хранилище BLOB-объектов Azure (с URI большого двоичного объекта), чтобы убедиться, что внутренний fsspec/adlfs код может подключаться с помощью интерфейса BlobServiceClient.
- Если вторичная управляемая частная конечная точка не настроена правильно, мы увидим сообщение об ошибке, например ServiceRequestError: не удается подключиться к узлу [storageaccountname].blob.core.windows.net:443 ssl:True [имя или служба не известно]
Примечание.
Если вы создаете связанную службу с помощью управляемого удостоверения в качестве способа проверки подлинности, убедитесь, что у MSI-файла рабочей области есть роль участника данных Хранилища BLOB-объектов подключенного контейнера.
После успешного создания связанной службы можно легко подключить контейнер к пулу Spark с помощью следующего кода Python:
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"linkedService": "mygen2account"}
)
Примечание.
Может потребоваться импортировать пакет mssparkutils, если он недоступен.
from notebookutils import mssparkutils
Не рекомендуется подключать корневую папку независимо от используемого метода проверки подлинности.
Параметры подключения:
- fileCacheTimeout: большие двоичные объекты будут кэшироваться в локальной папке temp в течение 120 секунд по умолчанию. В течение этого времени blbfuse не будет проверка актуальности файла. Параметр может быть задан для изменения времени ожидания по умолчанию. При одновременном изменении нескольких клиентов файлов, чтобы избежать несоответствий между локальными и удаленными файлами, рекомендуется сократить время кэша или даже изменить его на 0 и всегда получать последние файлы с сервера.
- время ожидания: время ожидания операции подключения составляет 120 секунд по умолчанию. Параметр может быть задан для изменения времени ожидания по умолчанию. При слишком большом количестве исполнителей или при истечении времени ожидания подключения рекомендуется увеличить значение.
- область: параметр область используется для указания область подключения. Значение по умолчанию — job. Если для область задано значение job, подключение отображается только в текущем кластере. Если для область задано значение "рабочая область", подключение отображается для всех записных книжек в текущей рабочей области, а точка подключения создается автоматически, если она не существует. Добавьте те же параметры в API отключения, чтобы отключить точку подключения. Подключение уровня рабочей области поддерживается только для проверки подлинности связанной службы.
Эти параметры можно использовать следующим образом:
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"linkedService":"mygen2account", "fileCacheTimeout": 120, "timeout": 120}
)
Подключение с помощью маркера подписанного URL-адреса или ключа учетной записи
Помимо подключения через связанную службу, mssparkutils поддерживает явную передачу ключа учетной записи или маркера подписанного URL-адреса (SAS) в качестве параметра для подключения целевого объекта.
По соображениям безопасности рекомендуется хранить ключи учетной записи или маркеры SAS в Azure Key Vault (как показано в следующем примере на снимке экрана). Затем их можно получить с помощью API mssparkutil.credentials.getSecret. См. сведения об управлении ключами учетной записи хранения с помощью Key Vault и Azure CLI (прежняя версия).
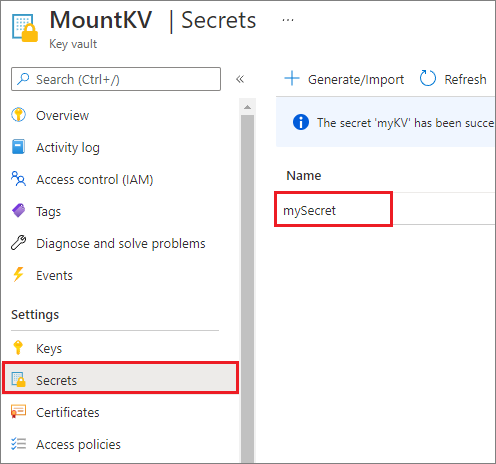
Ниже приведен пример кода.
from notebookutils import mssparkutils
accountKey = mssparkutils.credentials.getSecret("MountKV","mySecret")
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"accountKey":accountKey}
)
Примечание.
Для повышения безопасности не сохраняйте учетные данные в коде.
Доступ к файлам под точкой подключения с помощью API mssparkutils fs
Основная цель операции подключения — предоставить клиентам доступ к данным, хранящимся в удаленной учетной записи хранения, с помощью API локальной файловой системы. Доступ к данным также можно получить помощью API mssparkutils fs, передав подключенный путь в качестве параметра. Используемый здесь формат пути немного отличается.
Если вы подключили контейнер Data Lake Storage 2-го поколения mycontainer к /test с помощью API подключения. При доступе к данным через локальный API файловой системы:
- Для версий Spark меньше или равно 3.3 формат пути
/synfs/{jobId}/test/{filename}. - Для версий Spark больше или равно 3.4 формат пути
/synfs/notebook/{jobId}/test/{filename}.
Мы рекомендуем использовать точный mssparkutils.fs.getMountPath() путь:
path = mssparkutils.fs.getMountPath("/test")
Примечание.
При подключении хранилища с workspace область точка подключения создается в папке/synfs/workspace. И вам нужно использовать mssparkutils.fs.getMountPath("/test", "workspace") , чтобы получить точный путь.
Если вы хотите получить доступ к данным с помощью mssparkutils fs API, формат пути выглядит следующим образом: synfs:/notebook/{jobId}/test/{filename} В этом случае synfs используется как схема, а не как часть подключенного пути. Конечно, можно также использовать схему локальной файловой системы для доступа к данным. Например, file:/synfs/notebook/{jobId}/test/{filename}.
В следующих трех примерах показано, как получить доступ к файлу с помощью mssparkutils fs и пути к точке подключения.
Список каталогов:
mssparkutils.fs.ls(f'file:{mssparkutils.fs.getMountPath("/test")}')Чтение содержимого файла:
mssparkutils.fs.head(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.csv')Создание каталога:
mssparkutils.fs.mkdirs(f'file:{mssparkutils.fs.getMountPath("/test")}/myDir')
Доступ к файлам в точке подключения с помощью API чтения Spark
Можно предоставить параметр для доступа к данным через API чтения Spark. При использовании mssparkutils fs API используется тот же формат пути.
Чтение файла из подключенной учетной записи хранения Data Lake Storage 2-го поколения
В следующем примере предполагается, что учетная запись хранения Data Lake Storage 2-го поколения уже подключена, а вы затем считываете файл с помощью пути подключения:
%%pyspark
df = spark.read.load(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.csv', format='csv')
df.show()
Примечание.
При подключении хранилища с помощью связанной службы необходимо всегда явно задать конфигурацию связанной службы Spark перед использованием схемы synfs для доступа к данным. Дополнительные сведения см. в хранилище ADLS 2-го поколения с связанными службами .
Чтение файла из подключенной учетной записи Хранилища BLOB-объектов
Если вы подключили учетную запись Хранилища BLOB-объектов, а затем хотите получить к ней доступ с помощью mssparkutils или API Spark, вам необходимо явно настроить маркер SAS с помощью конфигурации Spark, прежде чем пытаться подключить контейнер с помощью API подключения.
Чтобы получить доступ к учетной записи Хранилища BLOB-объектов с помощью
mssparkutilsили API Spark после выполнения подключения, обновите конфигурацию Spark, как показано в следующем примере кода. Этот шаг можно пропустить, если после подключения вы хотите получить доступ к конфигурации Spark только с помощью локального файлового API.blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds("myblobstorageaccount") spark.conf.set('fs.azure.sas.mycontainer.<blobStorageAccountName>.blob.core.windows.net', blob_sas_token)Создайте связанную службу
myblobstorageaccountи подключите учетную запись Хранилища BLOB-объектов с помощью связанной службы:%%spark mssparkutils.fs.mount( "wasbs://mycontainer@<blobStorageAccountName>.blob.core.windows.net", "/test", Map("linkedService" -> "myblobstorageaccount") )Подключите контейнер Хранилища BLOB-объектов и считайте файл с помощью пути подключения через API локальных файлов:
# mount the Blob Storage container, and then read the file by using a mount path with open(mssparkutils.fs.getMountPath("/test") + "/myFile.txt") as f: print(f.read())Чтение данных из подключенного контейнера Хранилища BLOB-объектов с помощью API чтения Spark:
%%spark // mount blob storage container and then read file using mount path val df = spark.read.text(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.txt') df.show()
Отключение точки подключения
Используйте следующий код, чтобы отключить точку подключения (в этом примере /test):
mssparkutils.fs.unmount("/test")
Известные ограничения
Механизм отключения не является автоматическим. По завершении выполнения приложения, чтобы отключить точку подключения и освободить место на диске, вам нужно явно вызвать API отключения в своем коде. В противном случае точка подключения по-прежнему будет существовать в узле после завершения работы приложения.
Подключение учетной записи хранения Data Lake Storage 1-го поколения в настоящее время не поддерживается.
Известные проблемы:
- В Spark 3.4 точки подключения могут быть недоступны, если в одном кластере выполняется несколько активных сеансов. Вы можете подключиться с
workspaceпомощью область, чтобы избежать этой проблемы.
Следующие шаги
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по