Учебник. Использование Pandas для чтения и записи данных Azure Data Lake Storage 2-го поколения в бессерверном пуле Apache Spark в Synapse Analytics
Узнайте, как использовать Pandas для чтения и записи данных в Azure Data Lake Storage 2-го поколения (ADLS) в бессерверном пуле Apache Spark в Azure Synapse Analytics. В примерах этого учебника показано, как считывать данные CSV с помощью Pandas в Synapse, а также в файлах Excel и Parquet.
Из этого руководства вы узнаете, как выполнять следующие задачи:
- Чтение и запись данных ADLS 2-го поколения с помощью Pandas в сеансе Spark.
Если у вас нет подписки Azure, создайте бесплатную учетную запись, прежде чем приступить к работе.
Необходимые компоненты
Рабочая область Azure Synapse Analytics с учетной записью хранения Azure Data Lake Storage 2-го поколения, настроенной в качестве хранилища по умолчанию (или основном хранилище). При работе с файловой системой Data Lake Storage 2-го поколения требуются права участника данных Хранилища BLOB-объектов.
Бессерверный пул Apache Spark в рабочей области Azure Synapse Analytics. Дополнительные сведения см. в статье Создание пула Spark в Azure Synapse.
Настройте дополнительную учетную запись Azure Data Lake Storage 2-го поколения (не используемую по умолчанию для рабочей области Synapse). При работе с файловой системой Data Lake Storage 2-го поколения требуются права участника данных Хранилища BLOB-объектов.
Создание связанных служб. В Azure Synapse Analytics связанная служба определяет сведения о подключении к службе. В этом учебнике показано, как добавить Azure Synapse Analytics и Azure Data Lake Storage 2-го поколения в качестве связанных служб.
- Откройте Azure Synapse Studio и перейдите на вкладку Управление.
- В разделе Внешние подключения выберите Связанные службы.
- Чтобы добавить связанную службу, выберите Создать.
- Выберите плитку Azure Data Lake Storage 2-го поколения в списке и щелкните Продолжить.
- Введите учетные данные для проверки подлинности. В настоящее время поддерживаются такие типы проверки подлинности, как ключ учетной записи, субъект-служба, учетные данные и идентификатор управляемой службы (MSI). Прежде чем выбирать их для проверки подлинности, необходимо убедиться, что хранилищу субъекта-службы и MSI назначен участник данных BLOB-объектов хранилища. Проверьте подключение, чтобы убедиться в правильности учетных данных. Нажмите кнопку создания.
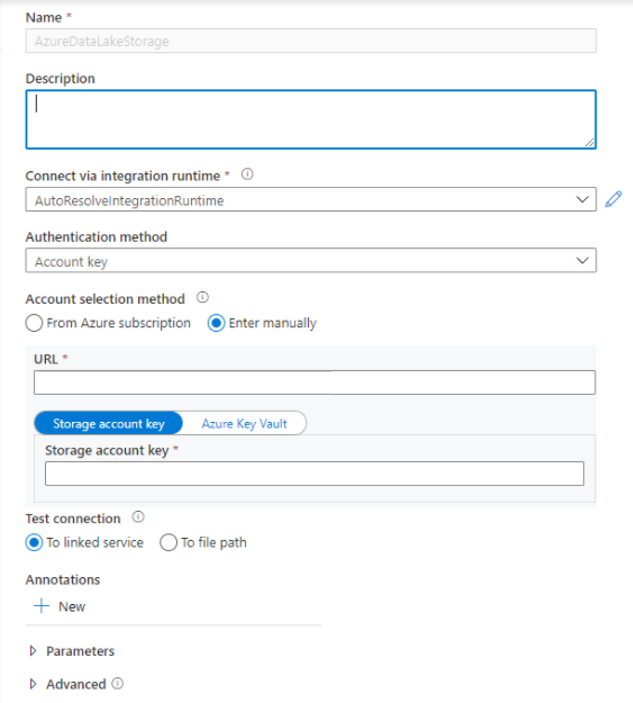
Важно!
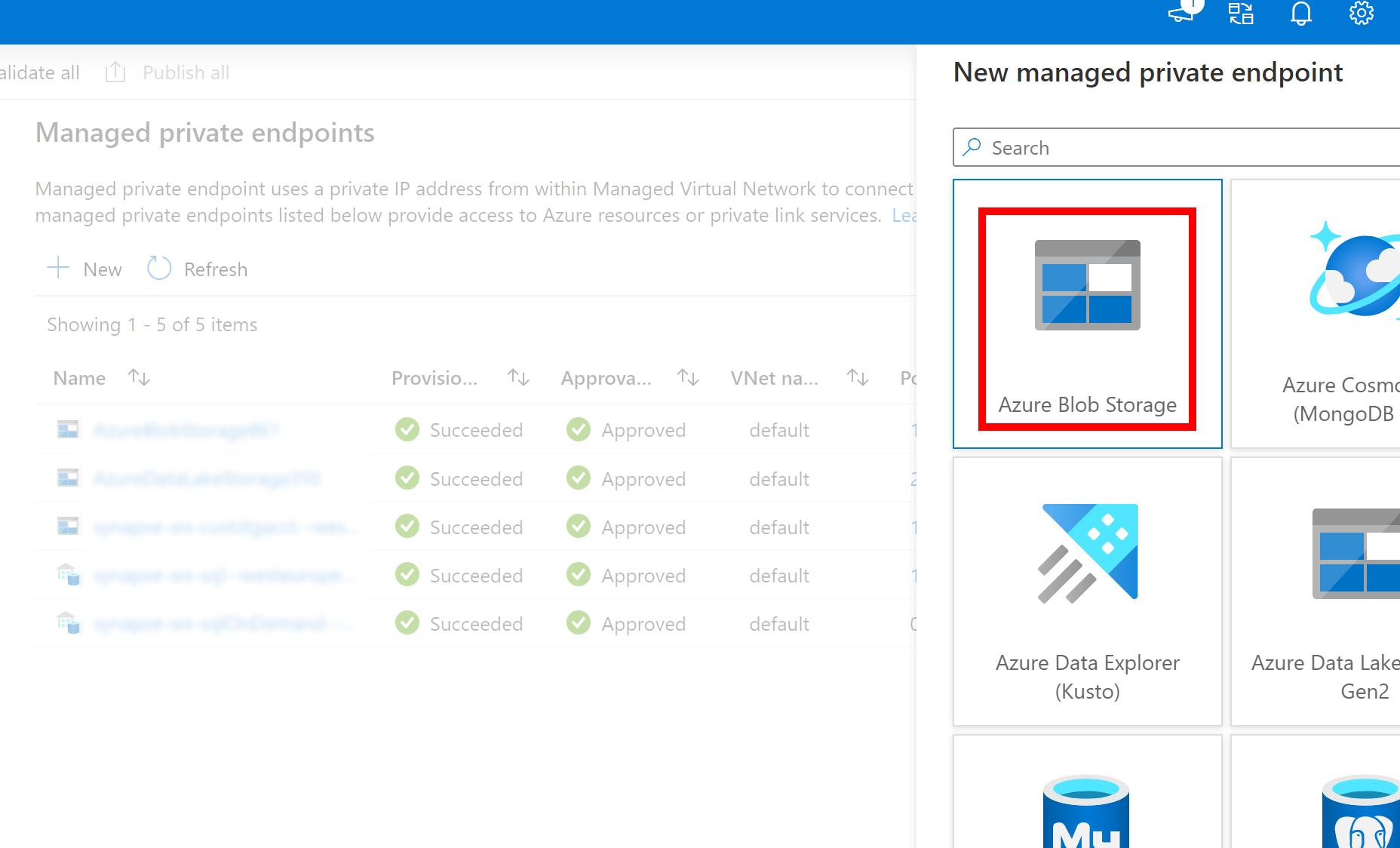
- Если созданная выше связанная служба для Azure Data Lake Storage 2-го поколения использует управляемую частную конечную точку (с URI DFS), необходимо создать другую управляемую частную конечную точку с помощью параметра Хранилище BLOB-объектов Azure (с URI большого двоичного объекта), чтобы убедиться, что внутренний fsspec/adlfs код может подключаться с помощью интерфейса BlobServiceClient.
- Если вторичная управляемая частная конечная точка не настроена правильно, мы увидим сообщение об ошибке, например ServiceRequestError: не удается подключиться к узлу [storageaccountname].blob.core.windows.net:443 ssl:True [имя или служба не известно]
Примечание.
- Функция Pandas поддерживается в бессерверном пуле Apache Spark для Python 3.8 и Spark3 в Azure Synapse Analytics.
- Поддержка доступна для следующих версий: pandas 1.2.3, fsspec 2021.10.0, adlfs 0.7.7
- Предусмотрены возможности поддержки как URI Azure Data Lake Storage 2-го поколения (abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path) и FSSPEC short URL (abfs[s]://container_name/file_path).
Войдите на портал Azure
Войдите на портал Azure.
Чтение данных из учетной записи хранения ADLS по умолчанию для рабочей области Synapse и запись в нее
Pandas может считывать и записывать данные ADLS, напрямую указывая путь к файлу.
Выполните следующий код.
Примечание.
Обновите URL-адрес файла в этом скрипте перед его запуском.
#Read data file from URI of default Azure Data Lake Storage Gen2
import pandas
#read csv file
df = pandas.read_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path')
print(df)
#write csv file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path')
#Read data file from FSSPEC short URL of default Azure Data Lake Storage Gen2
import pandas
#read csv file
df = pandas.read_csv('abfs[s]://container_name/file_path')
print(df)
#write csv file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://container_name/file_path')
Чтение и запись данных с помощью дополнительной учетной записи ADLS
Pandas может считывать и записывать данные дополнительной учетной записи ADLS:
- с помощью связанной службы (с такими вариантами проверки подлинности: ключ учетной записи хранения, субъект-служба, управление удостоверением службы и учетные данные);
- используя параметры хранилища для непосредственной передачи идентификатора клиента и секрета, ключа SAS, ключа учетной записи хранения и строки подключения.
Использование связанной службы
Выполните следующий код.
Примечание.
Обновите URL-адрес файла и имя связанной службы в этом скрипте перед его запуском.
#Read data file from URI of secondary Azure Data Lake Storage Gen2
import pandas
#read data file
df = pandas.read_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ file_path', storage_options = {'linked_service' : 'linked_service_name'})
print(df)
#write data file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path', storage_options = {'linked_service' : 'linked_service_name'})
#Read data file from FSSPEC short URL of default Azure Data Lake Storage Gen2
import pandas
#read data file
df = pandas.read_csv('abfs[s]://container_name/file_path', storage_options = {'linked_service' : 'linked_service_name'})
print(df)
#write data file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://container_name/file_path', storage_options = {'linked_service' : 'linked_service_name'})
Использование параметров хранилища для непосредственной передачи идентификатора клиента и секрета, ключа SAS, ключа учетной записи хранения и строки подключения.
Выполните следующий код.
Примечание.
Обновите URL-адрес файла и storage_options в этом скрипте перед его запуском.
#Read data file from URI of secondary Azure Data Lake Storage Gen2
import pandas
#read data file
df = pandas.read_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ file_path', storage_options = {'account_key' : 'account_key_value'})
## or storage_options = {'sas_token' : 'sas_token_value'}
## or storage_options = {'connection_string' : 'connection_string_value'}
## or storage_options = {'tenant_id': 'tenant_id_value', 'client_id' : 'client_id_value', 'client_secret': 'client_secret_value'}
print(df)
#write data file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path', storage_options = {'account_key' : 'account_key_value'})
## or storage_options = {'sas_token' : 'sas_token_value'}
## or storage_options = {'connection_string' : 'connection_string_value'}
## or storage_options = {'tenant_id': 'tenant_id_value', 'client_id' : 'client_id_value', 'client_secret': 'client_secret_value'}
#Read data file from FSSPEC short URL of default Azure Data Lake Storage Gen2
import pandas
#read data file
df = pandas.read_csv('abfs[s]://container_name/file_path', storage_options = {'account_key' : 'account_key_value'})
## or storage_options = {'sas_token' : 'sas_token_value'}
## or storage_options = {'connection_string' : 'connection_string_value'}
## or storage_options = {'tenant_id': 'tenant_id_value', 'client_id' : 'client_id_value', 'client_secret': 'client_secret_value'}
print(df)
#write data file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://container_name/file_path', storage_options = {'account_key' : 'account_key_value'})
## or storage_options = {'sas_token' : 'sas_token_value'}
## or storage_options = {'connection_string' : 'connection_string_value'}
## or storage_options = {'tenant_id': 'tenant_id_value', 'client_id' : 'client_id_value', 'client_secret': 'client_secret_value'}
Пример чтения и записи файла Parquet
Выполните следующий код.
Примечание.
Обновите URL-адрес файла в этом скрипте перед его запуском.
import pandas
#read parquet file
df = pandas.read_parquet('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ parquet_file_path')
print(df)
#write parquet file
df.to_parquet('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ parquet_file_path')
Пример чтения и записи файла Excel
Выполните следующий код.
Примечание.
Обновите URL-адрес файла в этом скрипте перед его запуском.
import pandas
#read excel file
df = pandas.read_excel('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ excel_file_path')
print(df)
#write excel file
df.to_excel('abfs[s]://file_system_name@account_name.dfs.core.windows.net/excel_file_path')
Следующие шаги
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по