Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Применимо к: Выделенные пулы SQL Azure Synapse Analytics
Когда пользователи запрашивают таблицу columnstore в выделенном пуле SQL, оптимизатор проверяет минимальное и максимальное значения, хранящиеся в каждом сегменте. Сегменты, находящиеся вне границ предиката запроса, не считываются с диска в память. Запрос может быть выполнен быстрее, если количество сегментов для чтения и их общий размер невелики.
Примечание.
Эта статья относится к выделенным пулам SQL Azure Synapse Analytics. Сведения о упорядоченных индексах columnstore в SQL Server и других платформах SQL см. в разделе "Настройка производительности с упорядоченными кластеризованными индексами columnstore".
Упорядоченный и неупорядоченный кластеризованный индекс columnstore
По умолчанию для каждой таблицы, созданной без параметра индекса, внутренний компонент (построитель индексов) создает на нем неупорядоченный кластеризованный индекс columnstore (CCI). Даные в каждом столбце сжимаются в отдельный сегмент строковой группы CCI. Существуют метаданные для диапазона значений каждого сегмента, поэтому сегменты, находящиеся вне границ предиката запроса, не считываются с диска во время выполнения запроса. CCI обеспечивает наивысший уровень сжатия данных и уменьшает размер сегментов для чтения, чтобы запросы могли выполняться быстрее. Однако поскольку построитель индексов не сортирует данные перед их сжатием в сегменты, могут возникать сегменты с перекрывающимися диапазонами значений. Это приводит к тому, что запросы считывают больше сегментов с диска и на завершение процесса уходит больше времени.
Упорядоченные кластеризованные индексы Columnstore обеспечивают эффективное исключение сегментов, что приводит к значительно более быстрой производительности за счет пропуска большого количества упорядоченных данных, которые не соответствуют условию запроса. При создании упорядоченного CCI механизм пула SQL сортирует существующие данные в памяти по ключам порядка, прежде чем построитель индексов сжимает их в сегменты индекса. При использовании отсортированных данных перекрытие сегментов сокращается, позволяя запросам использовать более эффективное исключение сегментов и, следовательно, более высокую производительность, поскольку количество сегментов для чтения с диска меньше. Перекрытие сегментов можно избежать, если все данные могут быть отсортированы в памяти одновременно. В связи с большими таблицами в хранилищах данных этот сценарий происходит редко.
Чтобы проверить диапазоны сегментов для столбца, выполните следующую команду с именами ваших таблицы и столбца:
SELECT o.name, pnp.index_id,
cls.row_count, pnp.data_compression_desc,
pnp.pdw_node_id, pnp.distribution_id, cls.segment_id,
cls.column_id,
cls.min_data_id, cls.max_data_id,
cls.max_data_id-cls.min_data_id as difference
FROM sys.pdw_nodes_partitions AS pnp
JOIN sys.pdw_nodes_tables AS Ntables ON pnp.object_id = NTables.object_id AND pnp.pdw_node_id = NTables.pdw_node_id
JOIN sys.pdw_table_mappings AS Tmap ON NTables.name = TMap.physical_name AND substring(TMap.physical_name,40, 10) = pnp.distribution_id
JOIN sys.objects AS o ON TMap.object_id = o.object_id
JOIN sys.pdw_nodes_column_store_segments AS cls ON pnp.partition_id = cls.partition_id AND pnp.distribution_id = cls.distribution_id
JOIN sys.columns as cols ON o.object_id = cols.object_id AND cls.column_id = cols.column_id
WHERE o.name = '<Table Name>' and cols.name = '<Column Name>' and TMap.physical_name not like '%HdTable%'
ORDER BY o.name, pnp.distribution_id, cls.min_data_id;
Примечание.
В упорядоченной таблице CCI новые данные, полученные в результате выполнения операций загрузки одного и того же пакета DML или данных, сортируются в пределах этого пакета, поэтому в таблице не существует глобальной сортировки по всем данным. Пользователи могут ПЕРЕСТРОИТЬ упорядоченные CCI для сортировки всех данных в таблице. В выделенном SQL пуле перестроение columnstore индекса является оффлайн-операцией. Для секционированных таблиц перестроение выполняется по одному разделу за раз. Данные в разделе, который перестраивается, находятся в автономном режиме и недоступны до завершения REBUILD для этого раздела.
Производительность запросов
Увеличение производительности запроса от упорядоченного CCI зависит от шаблонов запросов, размера данных, качества сортировки данных, физической структуры сегментов, а также класса DWU и ресурсов, выбранных для выполнения запроса. Прежде чем выбирать столбцы для упорядочивания при проектировании упорядоченной таблицы CCI, пользователям следует ознакомиться со всеми этими факторами.
Запросы с этими шаблонами обычно выполняются быстрее при использовании упорядоченного CCI.
- Запросы имеют предикаты равенства, неравенства или диапазона
- Столбцы предиката и упорядоченные столбцы CCI одинаковы.
В этом примере в таблице T1 имеется кластеризованный индекс columnstore, упорядоченный в последовательности Col_C, Col_B и Col_A.
CREATE CLUSTERED COLUMNSTORE INDEX MyOrderedCCI ON T1
ORDER (Col_C, Col_B, Col_A);
Производительность запроса 1 и запроса 2 может выиграть от упорядоченной CCI больше, чем производительность других запросов, поскольку они используют все упорядоченные столбцы CCI.
-- Query #1:
SELECT * FROM T1 WHERE Col_C = 'c' AND Col_B = 'b' AND Col_A = 'a';
-- Query #2
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_C = 'c' AND Col_A = 'a';
-- Query #3
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_A = 'a';
-- Query #4
SELECT * FROM T1 WHERE Col_A = 'a' AND Col_C = 'c';
Производительность загрузки данных
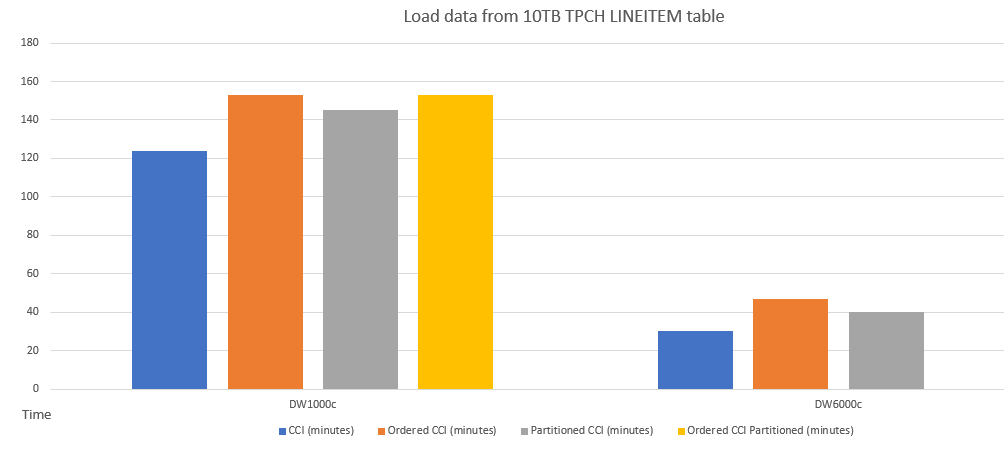
Производительность загрузки данных в упорядоченную таблицу CCI аналогична секционированной таблице. Загрузка данных в упорядоченную таблицу CCI может занять больше времени, чем в неупорядоченную таблицу CCI, из-за операции сортировки данных, однако запросы могут выполняться быстрее с упорядоченным CCI.
Ниже приведен пример сравнения производительности загрузки данных в таблицы с различными схемами.
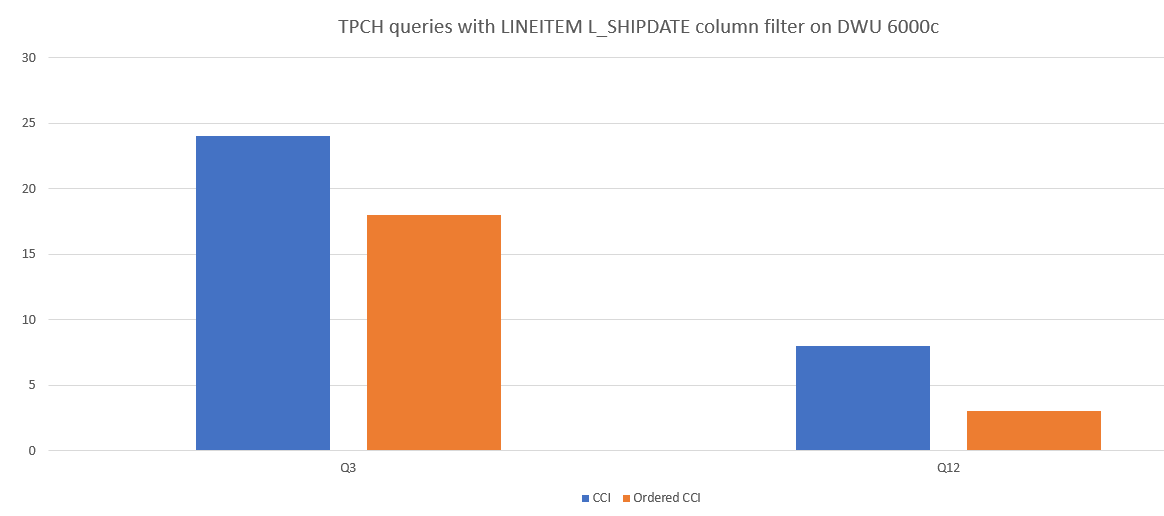
Ниже приведен пример сравнения производительности запросов между CCI и упорядоченной CCI.
Уменьшение перекрытия сегментов
Число перекрывающихся сегментов зависит от размера данных для сортировки, объема доступной памяти и параметра максимальной степени параллелизма (MAXDOP) во время создания упорядоченного CCI. Следующие стратегии сокращают перекрытие сегментов при создании упорядоченной CCI.
Используйте класс ресурсов
xlargercв более высоком классе DWU, чтобы обеспечить больше памяти для сортировки данных перед тем, как построитель индексов будет сжимать данные в сегменты. В сегменте индекса невозможно изменить физическое расположение данных. Сортировка данных внутри сегмента или между сегментами отсутствует.Создайте упорядоченную CCI с
OPTION (MAXDOP = 1)помощью. Каждый поток, используемый для создания упорядоченного CCI, работает с подмножеством данных и сортирует их локально. Глобальная сортировка данных, отсортированных различными потоками, отсутствует. Использование параллельных потоков позволяет сократить время создания упорядоченного CCI, но при этом будет создано больше пересекающихся сегментов, чем при использовании одного потока. Использование однопоточной операции обеспечивает высочайшее качество сжатия. Рассмотрим пример.
CREATE TABLE Table1 WITH (DISTRIBUTION = HASH(c1), CLUSTERED COLUMNSTORE INDEX ORDER(c1) )
AS SELECT * FROM ExampleTable
OPTION (MAXDOP 1);
Примечание.
В настоящее время в выделенных пулах SQL в Azure Synapse Analytics параметр MAXDOP поддерживается только при создании упорядоченной таблицы CCI с помощью CREATE TABLE AS SELECT команды. Создание упорядоченной CCI с помощью CREATE INDEX или CREATE TABLE команд не поддерживает параметр MAXDOP. Это ограничение не применяется к SQL Server 2022 и более поздним версиям, где можно указать MAXDOP с помощью команд CREATE INDEX или CREATE TABLE.
- Предварительная сортировка данных по ключам сортировки перед их загрузкой в таблицы.
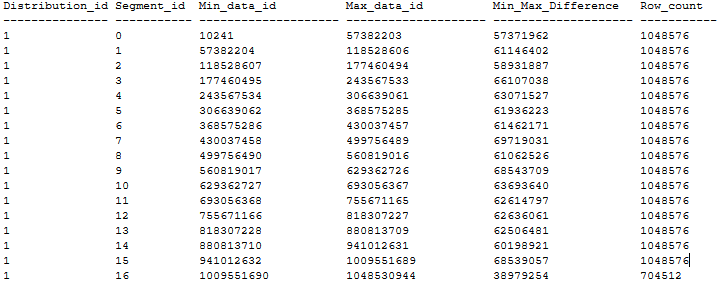
Ниже приведен пример упорядоченного распределения таблиц CCI без перекрытия сегментов, соответствующего приведенным выше рекомендациям. Упорядоченная таблица CCI создается в базе данных DWU1000c с помощью CTAS из таблицы кучи размером 20 ГБ с помощью MAXDOP 1 и xlargerc. CCI упорядоченный в столбце типа BIGINT без дубликатов.
Создавайте упорядоченную CCI на больших таблицах
Создание упорядоченной CCI — это автономная операция. Для таблиц без секций данные не будут доступны пользователям до тех пор, пока не завершится процесс создания упорядоченного CCI. Для секционированных таблиц, поскольку подсистема создает упорядоченный CCI по каждой секции, пользователи могут по-прежнему обращаться к данным в тех секциях, где создание упорядоченного CCI не выполняется. С помощью этого параметра можно сократить время простоя при создании упорядоченного CCI в больших таблицах:
- Создайте разделы в целевой большой таблице (с именем
Table_A). - Создайте пустую упорядоченную таблицу CCI (с именем
Table_B) с той же таблицей и схемой секционирования, что и вTable_A. - Переместите одну секцию из
Table_AвTable_B. - Выполните
ALTER INDEX <Ordered_CCI_Index> ON <Table_B> REBUILD PARTITION = <Partition_ID>, чтобы перестроить подключаемый раздел наTable_B. - Повторите шаги 3 и 4 для каждого раздела в
Table_A. - После переключения всех секций с
Table_AнаTable_Bи их перестроения удалитеTable_Aи переименуйтеTable_BвTable_A.
Tip
Для выделенной таблицы пула SQL с упорядоченной CCI, ALTER INDEX ПЕРЕСТРОЙКА повторно отсортирует данные с помощью tempdb. Контролируйте tempdb во время операций перестроения. Если вам необходимо больше места в базе данных tempdb, можно увеличить размер пула. Можно уменьшить масштаб после завершения перестроения индекса.
Для выделенной таблицы пула SQL с упорядоченной CCI ALTER INDEX REORGANIZE не выполняет повторную сортировку данных. Чтобы отсортировать данные, используйте ALTER INDEX REBUILD.
Дополнительные сведения о упорядоченном обслуживании CCI см. в разделе "Оптимизация кластеризованных индексов columnstore".
Отличия возможностей SQL Server 2022
В выпуске SQL Server 2022 (16.x) появились упорядоченные кластеризованные индексы columnstore, аналогичные соответствующей возможности выделенных пулов SQL Azure Synapse.
- В настоящее время только SQL Server 2022 (16.x) и более поздние версии поддерживают кластеризованные возможности columnstore для устранения сегментов для строковых, двоичных и guid типов данных, а также для типа данных datetimeoffset с масштабом больше двух. Ранее это исключение сегмента применяется к числовым, датовым и временным типам данных, а также к типу данных datetimeoffset с масштабированием меньше или равно двум.
- В настоящее время только SQL Server 2022 (16.x) и более поздние версии поддерживают исключение групп строк кластеризованного столбцового хранилища по префиксу предикатов, например
LIKE. Исключение сегментов не поддерживается для использования LIKE вне контекста префикса, напримерcolumn LIKE '%string'.
Дополнительные сведения см. в разделе Новые возможности индексов Columnstore.
Примеры
A. Чтобы проверить упорядоченные столбцы и порядковый номер, выполните следующее:
SELECT object_name(c.object_id) table_name, c.name column_name, i.column_store_order_ordinal
FROM sys.index_columns i
JOIN sys.columns c ON i.object_id = c.object_id AND c.column_id = i.column_id
WHERE column_store_order_ordinal <>0;
В. Чтобы изменить порядок столбцов, добавьте или удалите колонки из списка порядка либо замените CCI на упорядоченный CCI:
CREATE CLUSTERED COLUMNSTORE INDEX InternetSales ON dbo.InternetSales
ORDER (ProductKey, SalesAmount)
WITH (DROP_EXISTING = ON);
Следующие шаги
- Дополнительные советы по разработке приведены в обзоре разработки.
- Обзор индексов Columnstore
- Что нового в колоночных индексах
- Руководство по проектированию колонковых индексов
- Индексы columnstore - производительность запросов