Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Tip
Microsoft Fabric Data Warehouse — это реляционное хранилище корпоративного масштаба на основе озера данных, с архитектурой, готовой к будущему, встроенной ИИ и новыми функциями. Если вы не знакомы с хранилищем данных, начните с Fabric Data Warehouse. Существующие рабочие нагрузки выделенного пула SQL могут обновляться до Fabric для доступа к новым возможностям в области науки о данных, аналитики в реальном времени и отчетности.
Из этой статьи вы узнаете, как запросить один CSV-файл с помощью бессерверного пула SQL в Azure Synapse Analytics. CSV-файлы могут иметь разные форматы:
- Со строкой заголовка и без нее
- Значения, разделённые запятыми и табуляцией
- Завершение строк в стиле Windows и UNIX
- Неквотированные и кавычные значения, а также экранирование символов
Все приведенные выше варианты будут рассмотрены ниже.
Пример для быстрого начала
Функция OPENROWSET позволяет считывать содержимое CSV-файла, предоставляя URL-адрес к файлу.
Чтение CSV-файла
Чтобы увидеть содержимое файла CSV, проще всего вызвать функцию OPENROWSET, передав ей URL-адрес нужного файла, значение "csv" для параметра FORMAT и значение "2.0" для параметра PARSER_VERSION. Если файл доступен в общедоступном виде или если удостоверение Microsoft Entra может получить доступ к этому файлу, вы сможете просмотреть содержимое файла с помощью запроса, как показано в следующем примере:
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2 ) as rows
Параметр firstrow используется для пропуска в CSV-файле первой строки, представляющей в этом случае заголовок. Убедитесь, что у вас есть доступ к этому файлу. Если файл защищен с помощью ключа SAS или пользовательского удостоверения, необходимо настроить учетные данные на уровне сервера для входа sql.
Внимание
Если CSV-файл содержит символы UTF-8, убедитесь, что вы используете параметры сортировки базы данных UTF-8 (например Latin1_General_100_CI_AS_SC_UTF8).
Несоответствие кодировки текста в файле и параметров сортировки может привести к непредвиденным ошибкам преобразования текста.
Параметры сортировки по умолчанию для текущей базы данных можно легко изменить с помощью такой инструкции T-SQL: alter database current collate Latin1_General_100_CI_AI_SC_UTF8.
Использование источника данных
В предыдущем примере используется полный путь к файлу. Или можно создать внешний источник данных с расположением, которое указывает на корневую папку хранилища:
create external data source covid
with ( location = 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases' );
Созданный источник данных и относительный путь к файлу можно использовать в функции OPENROWSET.
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) as rows
Если источник данных защищен с помощью ключа SAS или пользовательского удостоверения, можно настроить источник данных с учетными данными с областью базы данных.
Явное указание схемы
Функция OPENROWSET позволяет явным образом указывать, какие столбцы вы хотите считать из файла, с помощью предложения WITH:
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) with (
date_rep date 1,
cases int 5,
geo_id varchar(6) 8
) as rows
Числа после типа данных в предложении WITH представляют индекс столбца в CSV-файле.
Внимание
Если CSV-файл содержит символы UTF-8, убедитесь, что вы явно указываете некоторые параметры сортировки UTF-8 (например Latin1_General_100_CI_AS_SC_UTF8) для всех столбцов в WITH предложении или задайте некоторые параметры сортировки UTF-8 на уровне базы данных.
Несоответствие кодировки текста в файле и параметров сортировки может привести к непредвиденным ошибкам преобразования.
Параметры сортировки по умолчанию для текущей базы данных можно легко изменить с помощью такой инструкции T-SQL: .
alter database current collate Latin1_General_100_CI_AI_SC_UTF8 Параметры сортировки можно легко задать для типов столбцов с помощью следующего определения: geo_id varchar(6) collate Latin1_General_100_CI_AI_SC_UTF8 8
В следующих разделах показано, как выполнять запросы к различным типам CSV-файлов.
Предварительные требования
Для начала создайте базу данных, в которой будут созданы таблицы. Затем инициализируйте объекты, выполнив сценарий установки для этой базы данных. Этот сценарий установки создает источники данных, учетные данные области базы данных и форматы внешних файлов, которые используются в этих примерах.
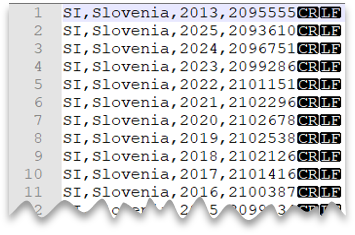
Новая строка в стиле Windows
Следующий запрос показывает, как считать CSV-файл без строки заголовка, с новой строкой в стиле Windows и столбцами с разделителями-запятыми.
Предварительный просмотр файла:
SELECT *
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
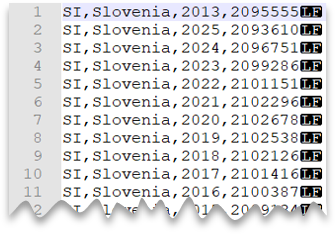
Новая строка в стиле Unix
Следующий запрос показывает, как считать CSV-файл без строки заголовка, с новой строкой в стиле Unix и столбцами с разделителями-запятыми. Обратите внимание на другое расположение файла по сравнению с другими примерами.
Предварительный просмотр файла:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
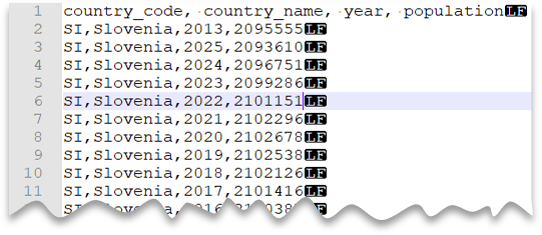
Строка заголовка
Следующий запрос показывает, как прочитать файл со строкой заголовка, с новой строкой в стиле Unix и столбцами, разделенными запятыми. Обратите внимание на другое расположение файла по сравнению с другими примерами.
Предварительный просмотр файла:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
HEADER_ROW = TRUE
) AS [r]
Параметр HEADER_ROW = TRUE приведет к чтению имен столбцов из строки заголовка в файле. Это отлично подходит для целей исследования, если вы не знакомы с содержимым файла. Сведения о наилучшей производительности см. в разделе "Использование соответствующих типов данных" в разделе "Рекомендации". Кроме того, подробнее о синтаксисе OPENROWSET можно прочитать здесь.
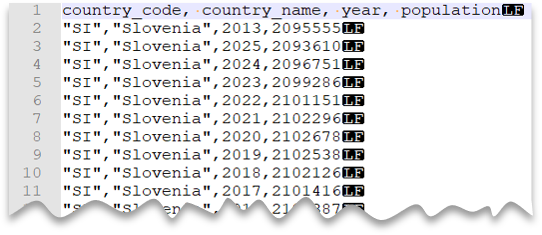
Настраиваемый значок кавычек
В следующем запросе показано, как считывать файл со строкой заголовка, с новой строкой в стиле Unix, столбцами, разделенными запятыми, и заключенными в кавычки значениями. Обратите внимание на другое расположение файла по сравнению с другими примерами.
Предварительный просмотр файла:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
FIELDQUOTE = '"'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
Примечание.
Этот запрос возвращает те же результаты, если пропущен параметр FIELDQUOTE, поскольку значение по умолчанию для FIELDQUOTE является двойной кавычкой.
Escape-символы
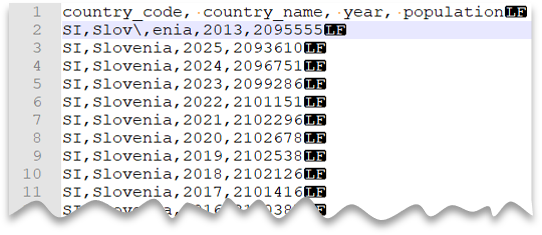
В следующем запросе показано, как считывать файл со строкой заголовка с новой строкой в стиле Unix, столбцами с разделителями-запятыми и escape-символом, используемым для разделителя полей (запятой) в значениях. Обратите внимание на другое расположение файла по сравнению с другими примерами.
Предварительный просмотр файла:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
ESCAPECHAR = '\\'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
Примечание.
Этот запрос завершится ошибкой, если ESCAPECHAR не указан, так как запятая в "Slov,enia" будет рассматриваться как разделитель полей вместо части имени страны или региона. "Slov,enia" будет рассматриваться как два столбца. Таким образом, конкретная строка будет иметь один столбец больше, чем другие строки, и один столбец больше, чем вы определили в предложении WITH.
Экранные символы с кавыками
В следующем запросе показано, как считывать файл со строкой заголовка с символом новой строки в стиле Unix, столбцами, разделенными запятыми, и экранированной двойной кавычкой в значениях. Обратите внимание на другое расположение файла по сравнению с другими примерами.
Предварительный просмотр файла:
В следующем запросе показано, как считывать файл со строкой заголовка, с символом новой строки в стиле Unix, столбцами, разделёнными запятыми, и экранированной двойной кавычкой в значениях.
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
Примечание.
Символ кавычек нужно экранировать другим символом кавычек. Символ кавычки может отображаться в значении столбца только в том случае, если значение инкапсулировано с помощью символов с кавычки.
Файлы с табуляцией
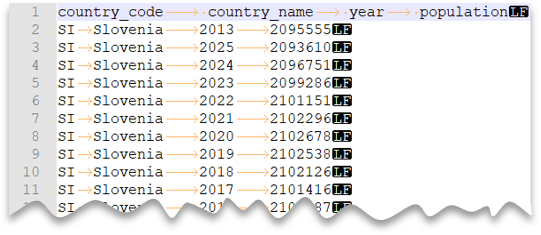
В следующем запросе показано, как считывать файл со строкой заголовка с новой строкой в стиле Unix и столбцами с разделителями табуляции. Обратите внимание на другое расположение файла по сравнению с другими примерами.
Предварительный просмотр файла:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-tsv/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR ='\t',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017
Возврат подмножества столбцов
До сих пор вы создавали схему CSV-файла с помощью WITH и перечисления всех столбцов. В запросе можно указать только те столбцы, которые действительно необходимы, используя порядковый номер для каждого столбца. Вы также пропускаете неважные столбцы.
Следующий запрос возвращает количество уникальных имен стран или регионов в файле, указывая только необходимые столбцы:
Примечание.
Взгляните на условие WITH в приведенном ниже запросе и обратите внимание на "2" (без кавычек) в конце строки, где определяется столбец [country_name]. Это означает, что столбец [country_name] является вторым столбцом в файле. Запрос будет игнорировать все столбцы файла, за исключением второго.
SELECT
COUNT(DISTINCT country_name) AS countries
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
--[country_code] VARCHAR (5),
[country_name] VARCHAR (100) 2
--[year] smallint,
--[population] bigint
) AS [r]
Запрос файлов, к которым можно добавлять данные
CSV-файлы, используемые в запросе, не должны быть изменены во время выполнения запроса. При длительных запросах пул SQL может повторять попытки чтения, читать части файлов или даже считывать файл несколько раз. Изменения содержимого файла приведут к неверным результатам. Таким образом, пул SQL завершает запрос с ошибкой, если он обнаруживает, что время изменения любого файла изменилось во время выполнения запроса.
В некоторых сценариях может требоваться чтение файлов, которые добавляются постоянно. Чтобы избежать сбоев запросов из-за постоянно добавляемых файлов, можно разрешить функции OPENROWSET игнорировать потенциальное несогласованное чтение, используя для этого параметр ROWSET_OPTIONS.
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2,
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}') as rows
Параметр чтения ALLOW_INCONSISTENT_READS отключит проверку времени изменения файлов во время жизненного цикла запроса и будет считывать все содержимое каждого файла. В добавляемых файлах существующий контент не обновляется и добавляются только новые строки. Таким образом, вероятность неверного результата сводится к минимуму по сравнению с обновляемыми файлами. Этот параметр позволяет считывать часто добавляемые файлы без обработки ошибок. В большинстве сценариев пул SQL просто игнорирует некоторые строки, добавляемые к файлам при выполнении запросов.
Связанный контент
В следующих статьях будет показано: