Перенос временных рядов Аналитика (TSI) 2-го поколения в Обозреватель данных Azure
Примечание.
Служба временных рядов Аналитика (TSI) больше не будет поддерживаться после марта 2025 года. Попробуйте перенести существующие среды TSI в альтернативные решения как можно скорее. Дополнительные сведения об устаревании и миграции см. в нашей документации.
Обзор
Рекомендации по миграции высокого уровня.
| Функция | Состояние 2-го поколения | Рекомендуемая миграция |
|---|---|---|
| Прием JSON из Концентратора с выравниванием и экранированием | Прием TSI | ADX — прием oneClick / мастер |
| Открытие холодного хранилища | Учетная запись служба хранилища клиента | Непрерывный экспорт данных в указанную клиентом внешнюю таблицу в ADLS. |
| PBI Подключение or | Закрытая предварительная версия | Используйте Подключение Подключение ADX PBI. Перезапись TSQ в KQL вручную. |
| Соединитель Spark | Закрытая предварительная версия. Запрос данных телеметрии. Запрос данных модели. | Перенос данных в ADX. Используйте соединитель ADX Spark для данных телеметрии и экспорта модели в JSON и загрузки в Spark. Перезапись запросов в KQL. |
| Массовая отправка | Закрытая предварительная версия | Используйте ADX OneClick Ingest и LightIngest. При необходимости настройте секционирование в ADX. |
| Модель временных рядов | Можно экспортировать как JSON-файл. Можно импортировать в ADX для выполнения соединений в KQL. | |
| Обозреватель TSI | Переключение теплого и холодного | Панели мониторинга ADX |
| Язык запросов | Запросы временных рядов (TSQ) | Перезапись запросов в KQL. Используйте пакеты SDK Kusto вместо TSI. |
Перенос телеметрии
Используйте PT=Time папку в учетной записи хранения, чтобы получить копию всех данных телеметрии в среде. Дополнительные сведения см. в служба хранилища данных.
Шаг миграции 1. Получение статистики о данных телеметрии
Data
- Обзор Env
- Идентификатор среды записи из первой части полного доменного имени доступа к данным (например, d390b0b0-1445-4c0c-8365-68d6382c1c2a from .env.crystal-dev.windows-int.net)
- Обзор env —> конфигурация служба хранилища —> учетная запись служба хранилища
- Использование Обозреватель службы хранилища для получения статистики папок
- Размер записи и количество больших двоичных
PT=Timeобъектов папки. Для клиентов в частной предварительной версии массового импорта такжеPT=Importразмер и количество больших двоичных объектов.
- Размер записи и количество больших двоичных
Шаг миграции 2. Перенос телеметрии в ADX
Создание кластера ADX
Определите размер кластера на основе размера данных с помощью средства оценки затрат ADX.
- Из метрик Центров событий (или Центр Интернета вещей) извлеките частоту приема данных в день. Из учетной записи служба хранилища, подключенной к среде TSI, извлеките объем данных в контейнере BLOB-объектов, используемом TSI. Эти сведения будут использоваться для вычисления идеального размера кластера ADX для вашей среды.
- Откройте Обозреватель оценки затрат Azure Обозреватель и заполните существующие поля найденными сведениями. Задайте для параметра "Тип рабочей нагрузки" значение "служба хранилища Оптимизировано" и "Горячие данные" с общим объемом запрашиваемых данных.
- После предоставления всех сведений azure Data Обозреватель Cost Estimator предложит размер виртуальной машины и количество экземпляров для кластера. Анализ размера активно запрашиваемых данных в горячем кэше. Умножьте количество экземпляров, предлагаемых размером кэша размера виртуальной машины, например:
- Предложение оценки затрат: 9x DS14 + 4 ТБ (кэш)
- Общее число предлагаемых горячих кэшей: 36 ТБ = [9x (экземпляры) x 4 ТБ (горячего кэша на узел)]
- Дополнительные факторы, которые следует учитывать:
- Рост среды: при планировании размера кластера ADX учитывайте рост данных по времени.
- Гидратация и секционирование: при определении количества экземпляров в кластере ADX следует учитывать дополнительные узлы (на 2–3x), чтобы ускорить гидратацию и секционирование.
- Дополнительные сведения о выборе вычислений см. в разделе "Выбор правильного номера SKU вычислений" для кластера Обозреватель данных Azure.
Чтобы лучше отслеживать кластер и прием данных, следует включить диагностические Параметры и отправить данные в рабочую область Log Analytics.
В колонке "Данные Azure Обозреватель" перейдите в раздел "Мониторинг | Параметры диагностики и нажмите кнопку "Добавить параметр диагностики"
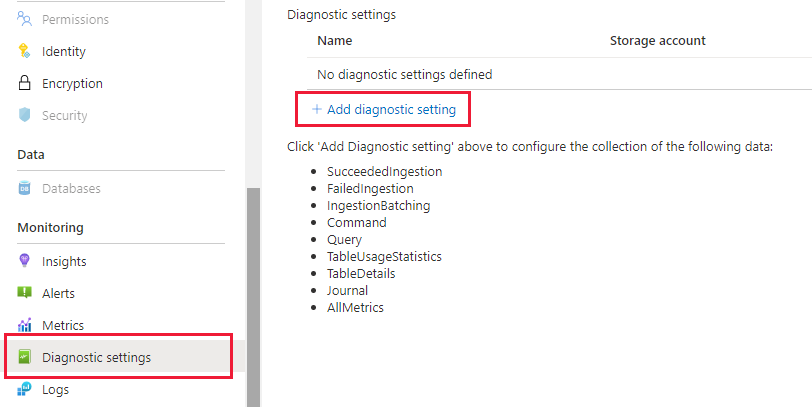
Заполните следующую команду:
- Имя параметра диагностики: отображаемое имя для этой конфигурации
- Журналы: по крайней мере выберите SucceededIngestion, FailedIngestion, IngestionBatching
- Выберите рабочую область Log Analytics, чтобы отправить данные в (если у вас нет одного, необходимо подготовить его перед этим шагом).
Секционирование данных.
- Для большинства наборов данных достаточно секционирования ADX по умолчанию.
- Секционирование данных полезно в очень определенном наборе сценариев и не должно применяться в противном случае:
- Улучшение задержки запросов в наборах больших данных, где большинство запросов фильтруется в столбце строки с высокой карта inality, например идентификатором временных рядов.
- При приеме данных вне порядка, например, когда события из прошлого могут быть приемом дней или недель после их создания в источнике.
- Дополнительные сведения см. в проверка политике секционирования данных ADX.


Подготовка к приему данных
Переход к https://dataexplorer.azure.com.
Перейдите на вкладку "Данные" и выберите "Прием из контейнера BLOB-объектов"
Выберите кластер, базу данных и создайте таблицу с именем, выбранной для данных TSI
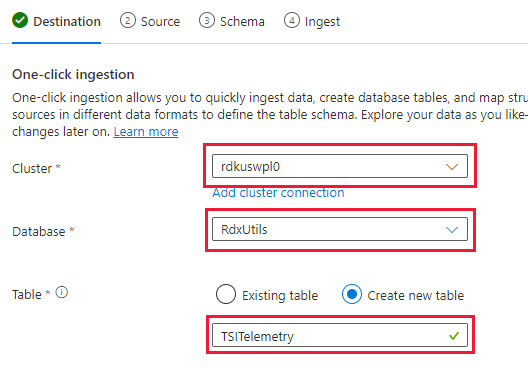
Выберите Далее: Источник.
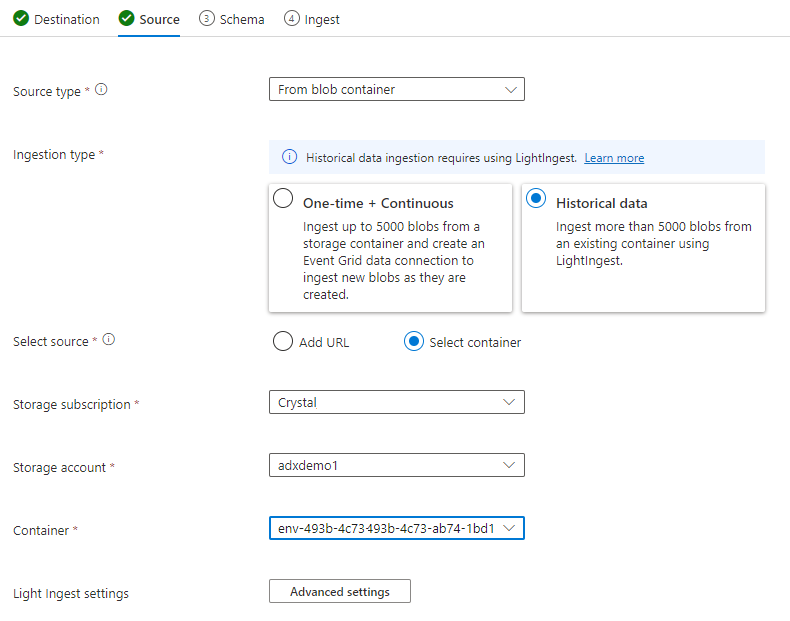
На вкладке "Источник" выберите:
- Данные журнала
- "Выбор контейнера"
- Выберите подписку и учетную запись служба хранилища для данных TSI
- Выберите контейнер, который коррелирует с средой TSI
Выбор дополнительных параметров
- Шаблон времени создания: '/'yyyyMMddHHmmssfff'_'
- Шаблон имени BLOB-объекта: *.parquet
- Выберите "Не ждать завершения приема"
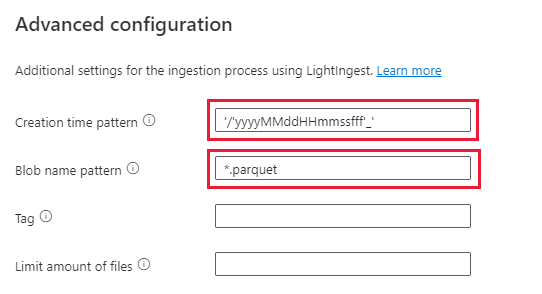
В разделе "Фильтры файлов" добавьте путь к папке
V=1/PT=Time
Выберите Далее: Схема.
Примечание.
TSI применяет некоторые плоские и экранирование при сохранении столбцов в файлах Parquet. Дополнительные сведения см. в следующих ссылках: выравнивание и экранирование правил, обновление правил приема.






Если схема неизвестна или изменяется
Удалите все столбцы, которые редко запрашиваются, оставляя по крайней мере метку времени и столбцы TSID.
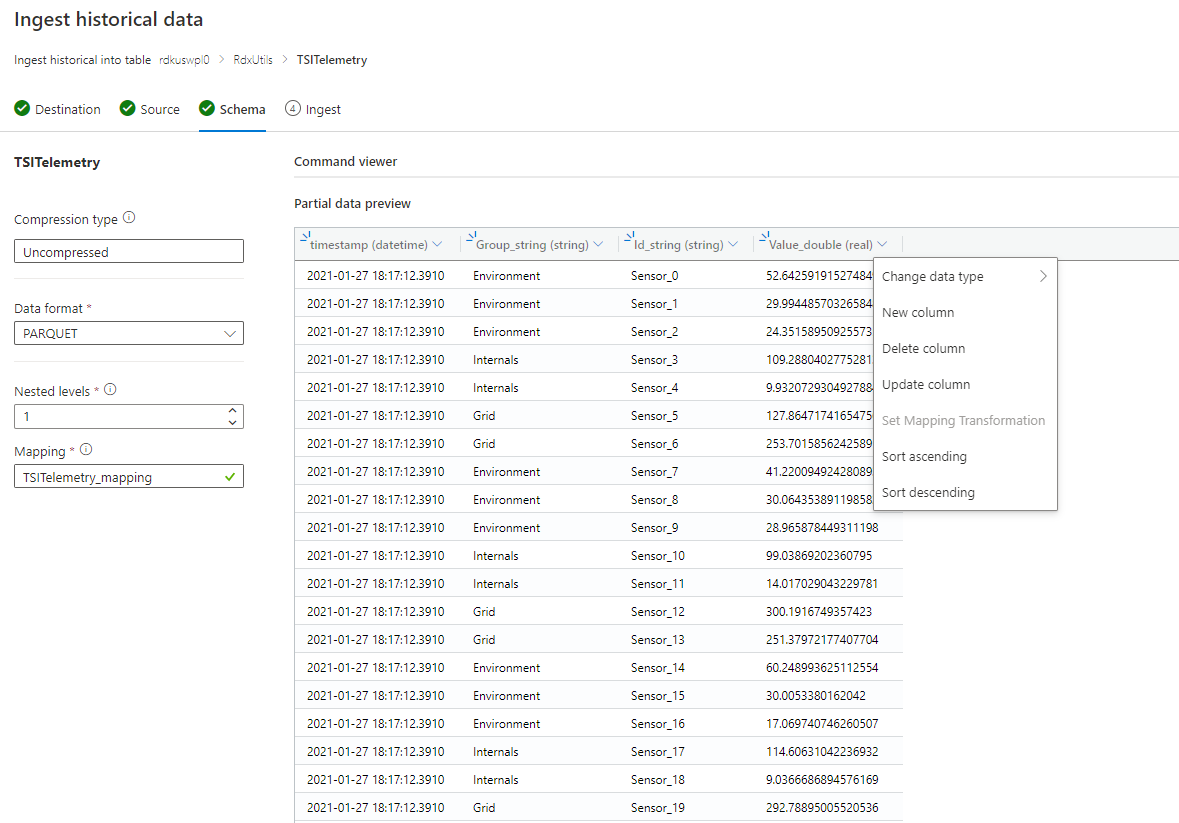
Добавьте новый столбец динамического типа и сопоставийте его со всей записью с помощью пути $.
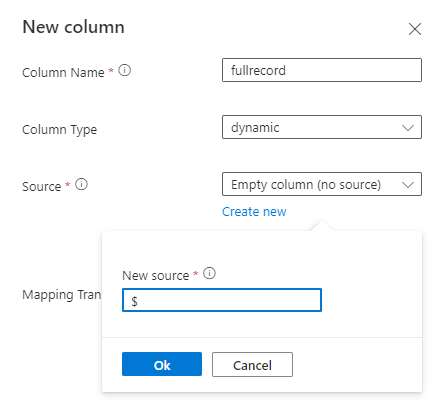
Пример:
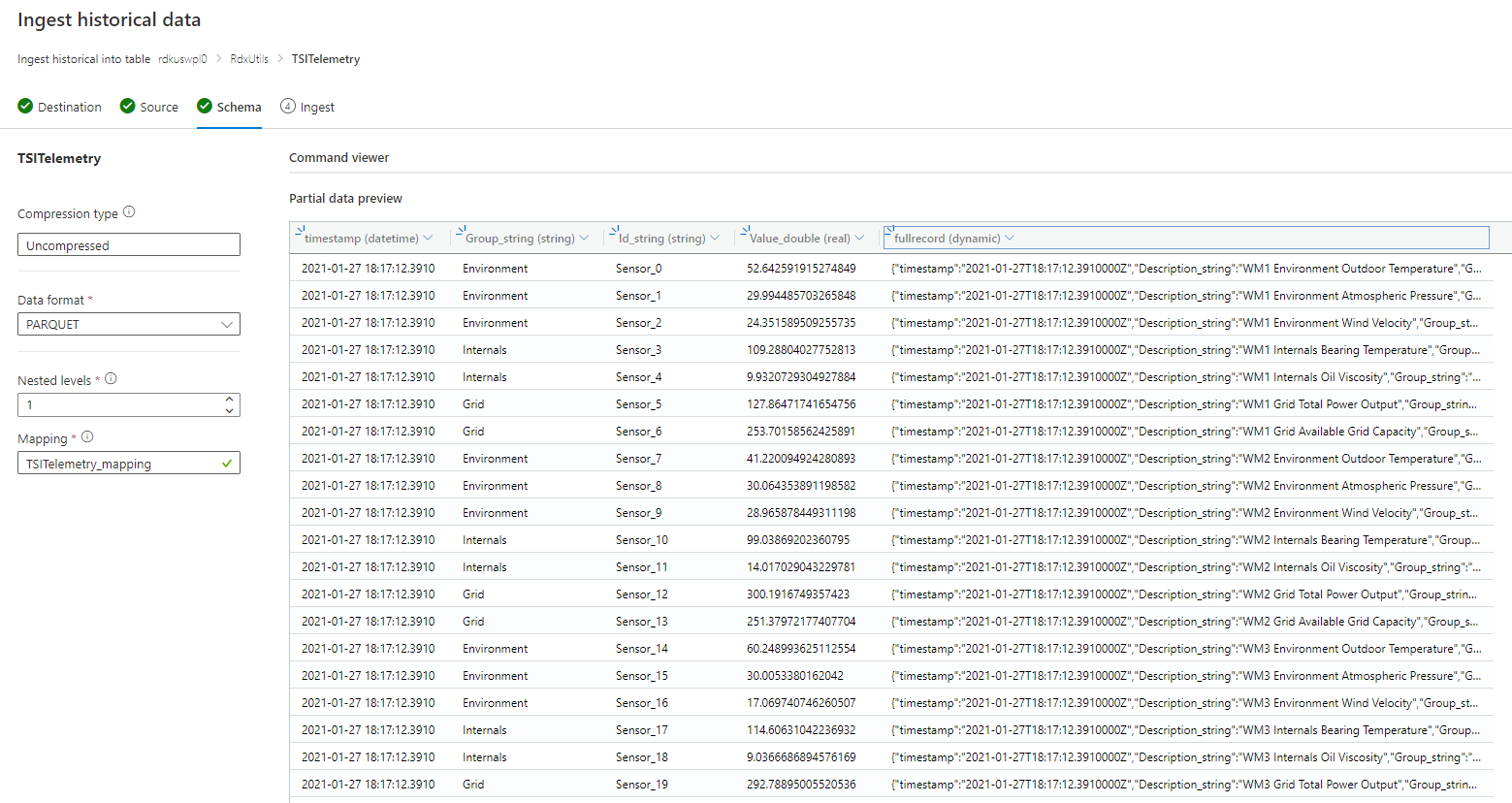
Если схема известна или исправлена
- Убедитесь, что данные выглядят правильно. При необходимости исправьте все типы.
- Нажмите кнопку "Далее": сводка



Скопируйте команду LightIngest и сохраните ее где-то, чтобы ее можно было использовать на следующем шаге.

Прием данных
Перед приемом данных необходимо установить средство LightIngest. Команда, созданная из средства one-Click, включает маркер SAS. Лучше всего создать новый, чтобы у вас был контроль над истечением срока действия. На портале перейдите к контейнеру BLOB-объектов для среды TSI и выберите "Общий маркер доступа"

Примечание.
Кроме того, рекомендуется увеличить масштаб кластера, прежде чем начать прием больших данных. Например, D14 или D32 с 8+ экземплярами.
Задайте следующее.
- Разрешения: чтение и список
- Срок действия. Задайте для вас период, когда будет выполнена миграция данных.
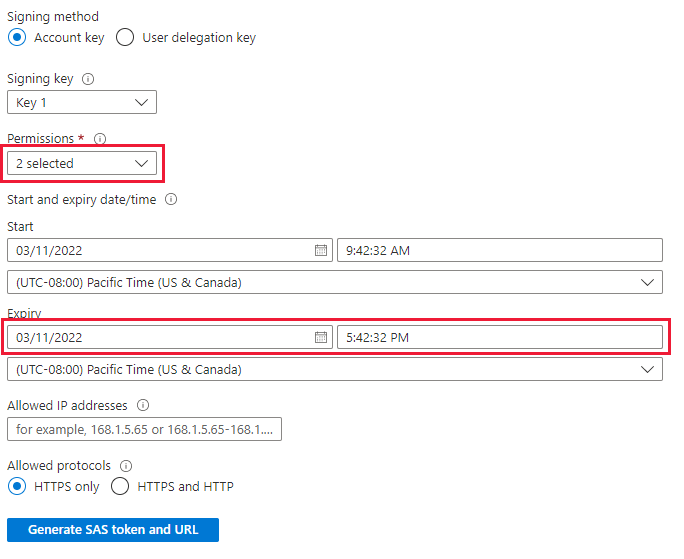
Выберите "Создать маркер SAS и URL-адрес" и скопируйте URL-адрес SAS BLOB-объектов.

Перейдите к команде LightIngest, скопированной ранее. Замените параметр -source в команде этим URL-адресом BLOB-объекта SAS.
Вариант 1. Прием всех данных. Для небольших сред можно принять все данные с помощью одной команды.
- Откройте командную строку и перейдите в каталог, в котором извлекается средство LightIngest. После этого вставьте команду LightIngest и выполните ее.

Вариант 2. Прием данных по годам или месяцам. Для больших сред или для тестирования на меньшем наборе данных можно отфильтровать команду "Освещение".
По годам: изменение параметра -префикса
- До:
-prefix:"V=1/PT=Time" - После:
-prefix:"V=1/PT=Time/Y=<Year>" - Пример:
-prefix:"V=1/PT=Time/Y=2021"
- До:
По месяцам: изменение параметра -префикса
- До:
-prefix:"V=1/PT=Time" - После:
-prefix:"V=1/PT=Time/Y=<Year>/M=<month #>" - Пример:
-prefix:"V=1/PT=Time/Y=2021/M=03"
- До:



После изменения команды выполните команду, как показано выше. Одно из завершенных приемов (с помощью параметра мониторинга ниже) измените команду в течение следующего года и месяца, который вы хотите принять.
Мониторинг приема
Команда LightIngest включала флаг -dontWait, чтобы сама команда не ждала завершения приема. Лучший способ отслеживать ход выполнения во время его выполнения — использовать вкладку "Аналитика" на портале. Откройте раздел "Данные Azure Обозреватель" на портале и перейдите к разделу "Мониторинг | Аналитика'

Вы можете использовать раздел "Прием (предварительная версия)" с приведенными ниже параметрами для отслеживания приема по мере его выполнения.
- Диапазон времени: последние 30 минут
- Просмотр успешных и по таблицам
- Если у вас возникли сбои, просмотрите "Сбой" и "Таблица"
Вы узнаете, что прием завершен после того, как вы увидите метрики, перейдите к 0 для таблицы. Если вы хотите просмотреть дополнительные сведения, можно использовать Log Analytics. В разделе "Данные Azure Обозреватель" выберите на вкладке "Журнал":

Полезные запросы
Общие сведения о схеме, если используется динамическая схема
| project p=treepath(fullrecord)
| mv-expand p
| summarize by tostring(p)
Доступ к значениям в массиве
| where id_string == "a"
| summarize avg(todouble(fullrecord.['nestedArray_v_double'])) by bin(timestamp, 1s)
| render timechart
Перенос модели временных рядов (TSM) в Обозреватель данных Azure
Модель можно скачать в формате JSON из среды TSI с помощью TSI Обозреватель UX или API пакетной службы TSM. Затем модель можно импортировать в другую систему, например azure Data Обозреватель.
Скачайте TSM из TSI UX.
Удалите первые три строки с помощью VSCode или другого редактора.
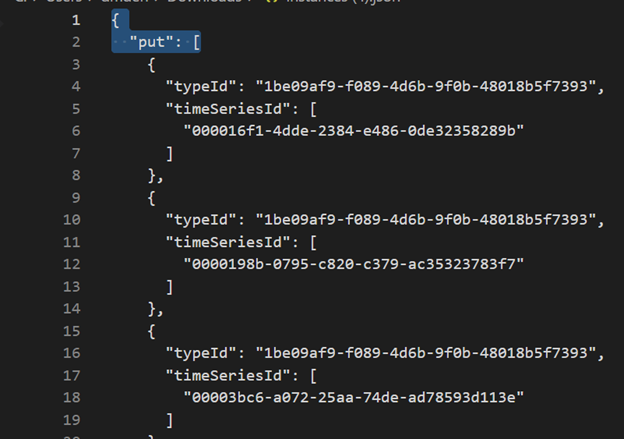
Использование VSCode или другого редактора, поиск и замена в качестве регулярного выражения
\},\n \{}{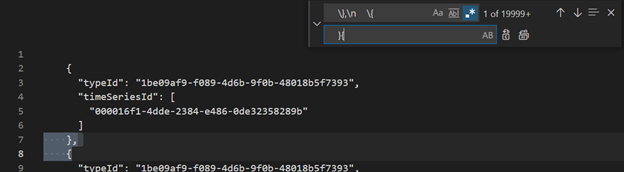
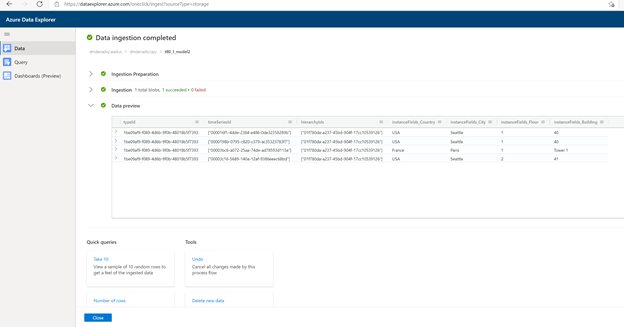
Прием как JSON в ADX в виде отдельной таблицы с помощью функции отправки из файлов.



Перевод запросов временных рядов (TSQ) в KQL
GetEvents
{
"getEvents": {
"timeSeriesId": [
"assest1",
"siteId1",
"dataId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:0.0000000Z",
"to": "2021-11-05T00:00:00.000000Z"
},
"inlineVariables": {},
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:0.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.000000Z)
| where assetId_string == "assest1" and siteId_string == "siteId1" and dataid_string == "dataId1"
| take 10000
GetEvents с фильтром
{
"getEvents": {
"timeSeriesId": [
"deviceId1",
"siteId1",
"dataId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:0.0000000Z",
"to": "2021-11-05T00:00:00.000000Z"
},
"filter": {
"tsx": "$event.sensors.sensor.String = 'status' AND $event.sensors.unit.String = 'ONLINE"
}
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:0.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.000000Z)
| where deviceId_string== "deviceId1" and siteId_string == "siteId1" and dataId_string == "dataId1"
| where ['sensors.sensor_string'] == "status" and ['sensors.unit_string'] == "ONLINE"
| take 10000
GetEvents с проецируемой переменной
{
"getEvents": {
"timeSeriesId": [
"deviceId1",
"siteId1",
"dataId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:0.0000000Z",
"to": "2021-11-05T00:00:00.000000Z"
},
"inlineVariables": {},
"projectedVariables": [],
"projectedProperties": [
{
"name": "sensors.value",
"type": "String"
},
{
"name": "sensors.value",
"type": "bool"
},
{
"name": "sensors.value",
"type": "Double"
}
]
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:0.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.000000Z)
| where deviceId_string== "deviceId1" and siteId_string == "siteId1" and dataId_string == "dataId1"
| take 10000
| project timestamp, sensorStringValue= ['sensors.value_string'], sensorBoolValue= ['sensors.value_bool'], sensorDoublelValue= ['sensors.value_double']
AggregateSeries
{
"aggregateSeries": {
"timeSeriesId": [
"deviceId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:00.0000000Z",
"to": "2021-11-05T00:00:00.0000000Z"
},
"interval": "PT1M",
"inlineVariables": {
"sensor": {
"kind": "numeric",
"value": {
"tsx": "coalesce($event.sensors.value.Double, todouble($event.sensors.value.Long))"
},
"aggregation": {
"tsx": "avg($value)"
}
}
},
"projectedVariables": [
"sensor"
]
}
events
| where timestamp >= datetime(2021-11-01T00:00:00.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.0000000Z)
| where deviceId_string == "deviceId1"
| summarize avgSensorValue= avg(coalesce(['sensors.value_double'], todouble(['sensors.value_long']))) by bin(IntervalTs = timestamp, 1m)
| project IntervalTs, avgSensorValue
Агрегаты с фильтром
{
"aggregateSeries": {
"timeSeriesId": [
"deviceId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:00.0000000Z",
"to": "2021-11-05T00:00:00.0000000Z"
},
"filter": {
"tsx": "$event.sensors.sensor.String = 'heater' AND $event.sensors.location.String = 'floor1room12'"
},
"interval": "PT1M",
"inlineVariables": {
"sensor": {
"kind": "numeric",
"value": {
"tsx": "coalesce($event.sensors.value.Double, todouble($event.sensors.value.Long))"
},
"aggregation": {
"tsx": "avg($value)"
}
}
},
"projectedVariables": [
"sensor"
]
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:00.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.0000000Z)
| where deviceId_string == "deviceId1"
| where ['sensors.sensor_string'] == "heater" and ['sensors.location_string'] == "floor1room12"
| summarize avgSensorValue= avg(coalesce(['sensors.value_double'], todouble(['sensors.value_long']))) by bin(IntervalTs = timestamp, 1m)
| project IntervalTs, avgSensorValue
Миграция с TSI Power BI Подключение or на ADX Power BI Подключение or
Действия вручную, связанные с этой миграцией
- Преобразование запроса Power BI в TSQ
- Преобразование запроса TSQ в KQL Power BI в TSQ: запрос Power BI, скопированный из TSI UX Обозреватель выглядит следующим образом:
Для необработанных данных (API GetEvents)
{"storeType":"ColdStore","isSearchSpanRelative":false,"clientDataType":"RDX_20200713_Q","environmentFqdn":"6988946f-2b5c-4f84-9921-530501fbab45.env.timeseries.azure.com", "queries":[{"getEvents":{"searchSpan":{"from":"2019-10-31T23:59:39.590Z","to":"2019-11-01T05:22:18.926Z"},"timeSeriesId":["Arctic Ocean",null],"take":250000}}]}
- Чтобы преобразовать его в TSQ, создайте JSON из приведенной выше полезных данных. Документация по API GetEvents также содержит примеры, чтобы лучше понять его. Запрос — выполнение — REST API (Аналитика временных рядов Azure) | Документация Майкрософт
- Преобразованный TSQ выглядит так, как показано ниже. Это полезные данные JSON внутри "запросов"
{
"getEvents": {
"timeSeriesId": [
"Arctic Ocean",
"null"
],
"searchSpan": {
"from": "2019-10-31T23:59:39.590Z",
"to": "2019-11-01T05:22:18.926Z"
},
"take": 250000
}
}
Для агградации данных (API агрегатных рядов)
- Для одной встроенной переменной PowerBI запрос из TSI UX Обозреватель выглядит следующим образом:
{"storeType":"ColdStore","isSearchSpanRelative":false,"clientDataType":"RDX_20200713_Q","environmentFqdn":"6988946f-2b5c-4f84-9921-530501fbab45.env.timeseries.azure.com", "queries":[{"aggregateSeries":{"searchSpan":{"from":"2019-10-31T23:59:39.590Z","to":"2019-11-01T05:22:18.926Z"},"timeSeriesId":["Arctic Ocean",null],"interval":"PT1M", "inlineVariables":{"EventCount":{"kind":"aggregate","aggregation":{"tsx":"count()"}}},"projectedVariables":["EventCount"]}}]}
- Чтобы преобразовать его в TSQ, создайте JSON из приведенной выше полезных данных. В документации по API AggregateSeries также приведены примеры, чтобы лучше понять его. Запрос — выполнение — REST API (Аналитика временных рядов Azure) | Документация Майкрософт
- Преобразованный TSQ выглядит так, как показано ниже. Это полезные данные JSON внутри "запросов"
{
"aggregateSeries": {
"timeSeriesId": [
"Arctic Ocean",
"null"
],
"searchSpan": {
"from": "2019-10-31T23:59:39.590Z",
"to": "2019-11-01T05:22:18.926Z"
},
"interval": "PT1M",
"inlineVariables": {
"EventCount": {
"kind": "aggregate",
"aggregation": {
"tsx": "count()"
}
}
},
"projectedVariables": [
"EventCount",
]
}
}
- Для нескольких встроенных переменных добавьте json в inlineVariables, как показано в примере ниже. Запрос Power BI для нескольких встроенных переменных выглядит следующим образом:
{"storeType":"ColdStore","isSearchSpanRelative":false,"clientDataType":"RDX_20200713_Q","environmentFqdn":"6988946f-2b5c-4f84-9921-530501fbab45.env.timeseries.azure.com","queries":[{"aggregateSeries":{"searchSpan":{"from":"2019-10-31T23:59:39.590Z","to":"2019-11-01T05:22:18.926Z"},"timeSeriesId":["Arctic Ocean",null],"interval":"PT1M", "inlineVariables":{"EventCount":{"kind":"aggregate","aggregation":{"tsx":"count()"}}},"projectedVariables":["EventCount"]}}, {"aggregateSeries":{"searchSpan":{"from":"2019-10-31T23:59:39.590Z","to":"2019-11-01T05:22:18.926Z"},"timeSeriesId":["Arctic Ocean",null],"interval":"PT1M", "inlineVariables":{"Magnitude":{"kind":"numeric","value":{"tsx":"$event['mag'].Double"},"aggregation":{"tsx":"max($value)"}}},"projectedVariables":["Magnitude"]}}]}
{
"aggregateSeries": {
"timeSeriesId": [
"Arctic Ocean",
"null"
],
"searchSpan": {
"from": "2019-10-31T23:59:39.590Z",
"to": "2019-11-01T05:22:18.926Z"
},
"interval": "PT1M",
"inlineVariables": {
"EventCount": {
"kind": "aggregate",
"aggregation": {
"tsx": "count()"
}
},
"Magnitude": {
"kind": "numeric",
"value": {
"tsx": "$event['mag'].Double"
},
"aggregation": {
"tsx": "max($value)"
}
}
},
"projectedVariables": [
"EventCount",
"Magnitude",
]
}
}
- Если вы хотите запросить последние данные("isSearchSpanRelative": true), вручную вычислите область поиска как упоминание ниже.
- Найдите разницу между "от" и "до" от полезных данных Power BI. Давайте называем это различие как "D", где "D" = "from" - "to"
- Возьмите текущую метку времени (T) и вычитайте разницу, полученную на первом шаге. Он будет новым "from"(F) searchSpan, где "F" = "T" - "D"
- Теперь новое значение "from" — "F", полученное на шаге 2, а новое "to" — "T"(текущая метка времени)