Размеры виртуальных машин серии HBv2
Применимо к: ✔️ Виртуальные машины Linux ✔️ Виртуальные машины Windows ✔️ Универсальные масштабируемые наборы
Для разных размеров серии HBv2 было проведено несколько тестов производительности. Ниже приведены некоторые результаты этого тестирования производительности.
| Рабочая нагрузка | HBv2 |
|---|---|
| STREAM Triad | 350 ГБ/с (21-23 ГБ/с на КККС) |
| High-Performance Linpack (HPL) | 4 Тфлопс (пиковое, FP64), 8 Тфлопс (максимальное, FP32) |
| Задержка и пропускная способность RDMA | 1,2 мкс, 190 Гбит/с |
| FIO на локальном твердотельном накопителе NVMe | 2,7 ГБ/с для операций записи, 1,1 ГБ/с для операций чтения; 102 тыс. операций ввода-вывода для чтения, 115 тыс. операций ввода-вывода для записи |
| IOR на 8 * SSD Azure цен. категории "Премиум" (управляемые диски P40, конфигурация RAID0)** | 1,3 ГБ/с для операций записи, 2,5 ГБ/с для операций чтения; 101 тыс. операций ввода-вывода для чтения, 105 тыс. операций ввода-вывода для записи |
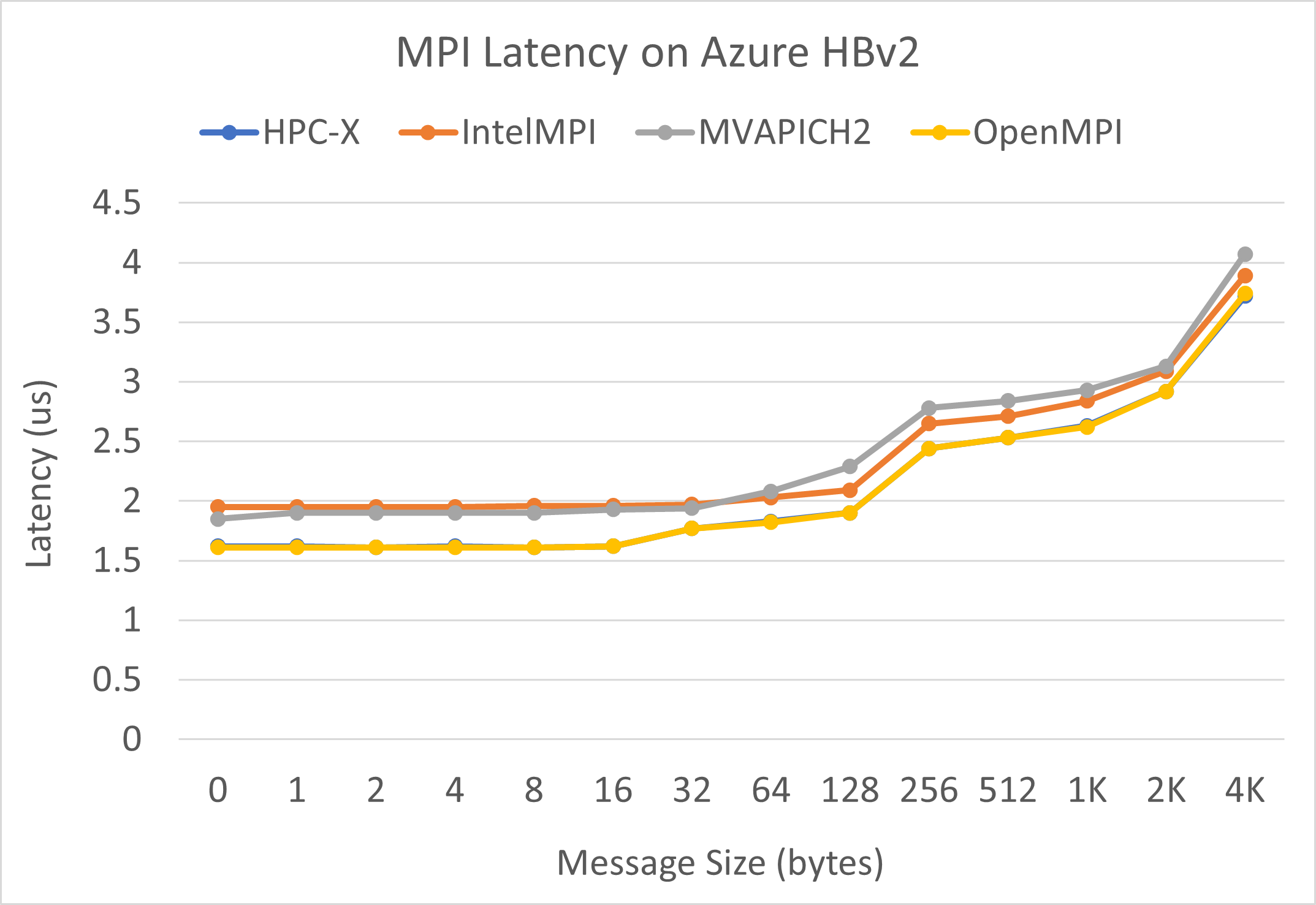
Задержка MPI
Выполнялся тест задержки MPI из набора OSU для микротестирования. Примеры использованных скриптов выложены на GitHub.
./bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=[INSERT CORE #] ./osu_latency
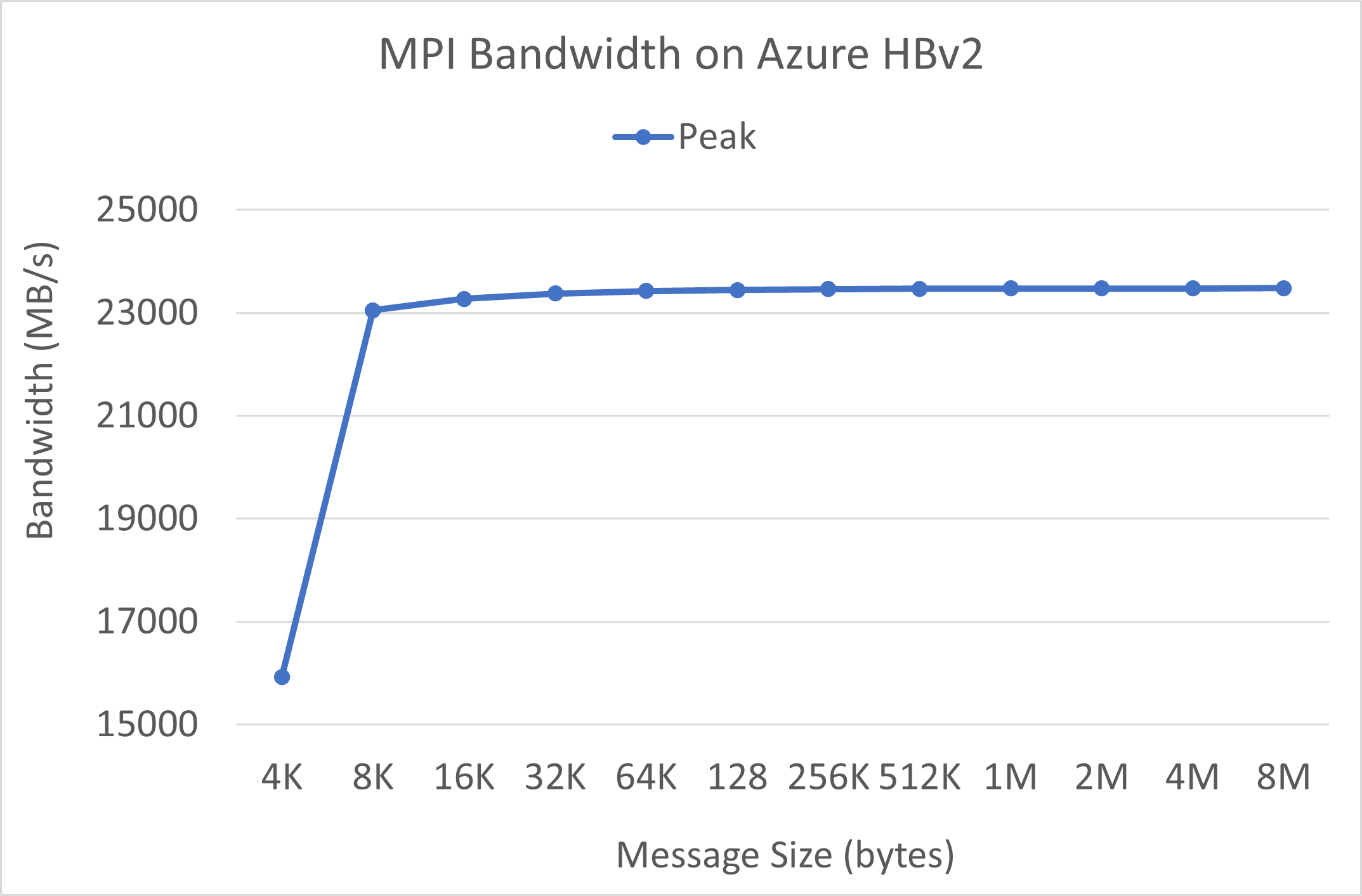
Пропускная способность MPI
Выполнялся тест пропускной способности MPI из набора OSU для микротестирования. Примеры использованных скриптов выложены на GitHub.
./mvapich2-2.3.install/bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=[INSERT CORE #] ./mvapich2-2.3/osu_benchmarks/mpi/pt2pt/osu_bw
Mellanox Perftest
Пакет Mellanox Perftest включает много тестов для InfiniBand, в том числе тесты задержки (ib_send_lat) и пропускной способности (ib_send_bw). Ниже приведен пример такой команды.
numactl --physcpubind=[INSERT CORE #] ib_send_lat -a
Следующие шаги
- Ознакомьтесь с последними объявлениями, примерами рабочей нагрузки HPC, а также результатами оценки производительности в блогах технического сообщества Вычислений Azure.
- Общие сведения об архитектурном представлении выполнения рабочих нагрузок HPC см. в статье Высокопроизводительные вычисления (HPC) в Azure.