Политики сети Azure Kubernetes
Политики сети обеспечивают микро-сегментацию для модулей pod так же, как группы безопасности сети (NSG) обеспечивают микро-сегментацию для виртуальных машин. Реализация Диспетчера сетевых политик Azure поддерживает стандартную спецификацию политики сети Kubernetes. Можно использовать метки для выбора групп модулей pod и определить список правил для входящего и исходящего трафика, чтобы фильтровать входящий и исходящий трафик для этих модулей pod. Дополнительные сведения о политиках сети Kubernetes см. в документации по Kubernetes.
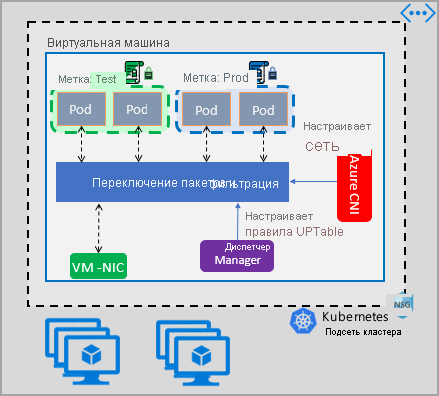
Реализация управления политиками сети Azure работает с Azure CNI, которая обеспечивает интеграцию виртуальной сети для контейнеров. Диспетчер политик сети поддерживается в Linux и Windows Server. Реализация применяет фильтрацию трафика путем настройки правил разрешения и запрета IP-адресов на основе определенных политик в IPTables Linux или ACLPolicies узла (HNS) для Windows Server.
Планирование безопасности для кластера Kubernetes
При реализации безопасности для кластера используйте группы безопасности сети (NSG), чтобы фильтровать входящий и исходящий трафик кластера (трафик "север/юг"). Используйте диспетчер сетевых политик Azure для трафика между модулями pod в кластере (трафик на востоке запада).
Использование диспетчера политик сети Azure
Диспетчер сетевых политик Azure можно использовать следующим образом, чтобы обеспечить микро-сегментацию для модулей pod.
Служба Azure Kubernetes (AKS)
Диспетчер сетевых политик доступен изначально в AKS и может быть включен во время создания кластера.
Дополнительные сведения см. в статье Secure traffic between pods using network policies in Azure Kubernetes Service (AKS) (Защита трафика между контейнерами pod с использованием политик сети в Azure Kubernetes Service (AKS)).
Самостоятельное (DIY) создание кластеров Kubernetes в Azure
В случае кластеров DIY сначала нужно установить подключаемый модуль CNI и включить его на каждой виртуальной машине в кластере. Подробные инструкции см. в разделе Развертывание подключаемого модуля для кластера Kubernetes.
После развертывания кластера выполните следующую kubectl команду, чтобы скачать и применить управляющая программа Диспетчера политик сети Azure к кластеру.
Для Linux.
kubectl apply -f https://raw.githubusercontent.com/Azure/azure-container-networking/master/npm/azure-npm.yaml
Для Windows:
kubectl apply -f https://raw.githubusercontent.com/Azure/azure-container-networking/master/npm/examples/windows/azure-npm.yaml
Это решение с открытым исходным кодом, и код доступен в репозитории работы с контейнером Azure в сети.
Мониторинг и визуализация конфигураций сети с помощью Azure NPM
Диспетчер политик сети Azure поддерживает информационные метрики Prometheus, позволяющие отслеживать и лучше понимать конфигурацию сети. NPM предоставляет встроенные визуализации либо в портал Azure, либо в Grafana Labs. Сбор этих метрик можно начать с помощью Azure Monitor либо сервера Prometheus.
Преимущества метрик Диспетчера сетевых политик Azure
Пользователи ранее смогли узнать о своей сетевой конфигурации и iptablesipset командах, выполняемых внутри узла кластера, что приводит к подробному и сложному пониманию выходных данных.
В целом метрики предоставляют:
Количество политик, правил ACL, ipset, записей ipset и записей в любом заданном ipset
Время выполнения для отдельных вызовов ОС и обработки событий ресурсов Kubernetes (медиана, 90-й процентиль и 99-й процентиль)
Сведения о сбое обработки событий ресурсов Kubernetes (эти события ресурсов завершаются сбоем при вызове ОС)
Примеры вариантов использования метрик
Оповещения через AlertManager Prometheus
См. конфигурацию для этих оповещений следующим образом.
Оповещение о сбое диспетчера сетевых политик с вызовом ОС или при переводе политики сети.
Оповещение о том, что среднее время применения изменений для события создания составило более 100 миллисекунд.
Визуализации и отладка с помощью панели мониторинга Grafana или книги Azure Monitor
Узнайте, сколько правил IPTables создают политики (с большим количеством правил IPTables может немного увеличить задержку).
Соотносите количество кластеров (например, списки управления доступом) со временем выполнения.
Получите понятное для человека имя ipset в заданном правиле IPTables (например,
azure-npm-487392представляетpodlabel-role:database).
Все поддерживаемые метрики
Ниже приведен список поддерживаемых метрик. Любая метка quantile имеет возможные значения 0.5, 0.9 и 0.99. Любая метка had_error имеет возможные значения false и true, показывая была ли операция успешной или неудачной.
| Имя метрики | Description | Тип метрики Prometheus | Наклейки |
|---|---|---|---|
npm_num_policies |
Число сетевых политик | Показатели | - |
npm_num_iptables_rules |
Число правил IPTables | Показатели | - |
npm_num_ipsets |
Число наборов IPSets | Показатели | - |
npm_num_ipset_entries |
Число записей IP-адресов во всех наборах IPSets | Показатели | - |
npm_add_iptables_rule_exec_time |
Среда выполнения для добавления правила IPTables | Итоги | quantile |
npm_add_ipset_exec_time |
Среда выполнения для добавления IPSet | Итоги | quantile |
npm_ipset_counts (дополнительно) |
Число записей в каждом отдельном наборе IPSet | GaugeVec |
set_name & set_hash |
npm_add_policy_exec_time |
Среда выполнения для добавления сетевой политики | Итоги |
quantile & had_error |
npm_controller_policy_exec_time |
Среда выполнения для обновления или удаления сетевой политики | Итоги |
quantile & & had_erroroperation (со значениями update или delete) |
npm_controller_namespace_exec_time |
Среда выполнения для создания, обновления или удаления пространства имен | Итоги |
quantile& & operationhad_error (со значениямиcreate, updateили delete) |
npm_controller_pod_exec_time |
Среда выполнения для создания, обновления или удаления модуля pod | Итоги |
quantile& & operationhad_error (со значениямиcreate, updateили delete) |
Для каждой сводной метрики exec_time также предусмотрены метрики exec_time_count и exec_time_sum.
Метрики могут быть извлечены с помощью Azure Monitor для контейнеров или с помощью Prometheus.
Настройка для Azure Monitor
Первым шагом является включение Azure Monitor для контейнеров в кластере Kubernetes. Действия можно найти в статье Общие сведения об Azure Monitor для контейнеров. После включения Azure Monitor для контейнеров настройте Azure Monitor для контейнеров ConfigMap , чтобы включить интеграцию и сбор метрик Диспетчера сетевых политик Prometheus.
В Azure Monitor для контейнеров ConfigMap есть integrations раздел с параметрами для сбора метрик Диспетчера политик сети.
По умолчанию в ConfigMap эти параметры отключены. Включение базового параметра collect_basic_metrics = trueсобирает базовые метрики диспетчера политик сети. Включение расширенного параметра collect_advanced_metrics = true собирает дополнительные метрики в дополнение к базовым метрикам.
После изменения сохраните ConfigMap локально и примените ConfigMap к кластеру следующим образом.
kubectl apply -f container-azm-ms-agentconfig.yaml
Следующий фрагмент кода представлен из Azure Monitor для контейнеров ConfigMap, в котором показана интеграция диспетчера политик сети с расширенными коллекциями метрик.
integrations: |-
[integrations.azure_network_policy_manager]
collect_basic_metrics = false
collect_advanced_metrics = true
Дополнительные метрики являются необязательными, и включение их автоматически включает коллекцию базовых метрик. Дополнительные метрики в настоящее время включают только Network Policy Manager_ipset_counts.
Дополнительные сведения о параметрах коллекции контейнеров в карте конфигурации см. в Azure Monitor.
Параметры визуализации для Azure Monitor
После включения сбора метрик диспетчера сетевых политик можно просмотреть метрики в портал Azure с помощью аналитики контейнеров или в Grafana.
Просмотр портал Azure в разделе "Аналитика" для кластера
Откройте портал Azure. После получения аналитических сведений в кластере перейдите к книгам и откройте конфигурацию Диспетчера политик сети (Диспетчер политик сети).
Помимо просмотра книги, вы также можете напрямую запрашивать метрики Prometheus в разделе "Журналы". Например, этот запрос возвращает все собранные метрики.
| where TimeGenerated > ago(5h)
| where Name contains "npm_"
Вы также можете запросить аналитику журналов непосредственно для метрик. Дополнительные сведения см. в статье "Начало работы с запросами Log Analytics".
Просмотр на панели мониторинга Grafana
Настройте сервер Grafana и настройте источник данных log analytics, как описано здесь. Затем импортируйте Панель мониторинга Grafana с серверной частью Log Analytics в Grafana Labs.
Панель мониторинга содержит визуальные элементы, аналогичные книге Azure. Панели можно добавлять на диаграмму и визуализировать метрики диспетчера сетевых политик из таблицы InsightsMetrics.
Настройка сервера Prometheus
Некоторые пользователи могут собирать метрики с сервером Prometheus вместо Azure Monitor для контейнеров. Вам просто нужно добавить два задания в конфигурацию скребка для сбора метрик диспетчера сетевых политик.
Чтобы установить сервер Prometheus, добавьте этот репозиторий helm в кластер:
helm repo add stable https://kubernetes-charts.storage.googleapis.com
helm repo update
затем добавьте сервер
helm install prometheus stable/prometheus -n monitoring \
--set pushgateway.enabled=false,alertmanager.enabled=false, \
--set-file extraScrapeConfigs=prometheus-server-scrape-config.yaml
где prometheus-server-scrape-config.yaml состоит из следующих элементов:
- job_name: "azure-npm-node-metrics"
metrics_path: /node-metrics
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
action: replace
regex: ([^:]+)(?::\d+)?
replacement: "$1:10091"
target_label: __address__
- job_name: "azure-npm-cluster-metrics"
metrics_path: /cluster-metrics
kubernetes_sd_configs:
- role: service
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
regex: kube-system
action: keep
- source_labels: [__meta_kubernetes_service_name]
regex: npm-metrics-cluster-service
action: keep
# Comment from here to the end to collect advanced metrics: number of entries for each IPSet
metric_relabel_configs:
- source_labels: [__name__]
regex: npm_ipset_counts
action: drop
Можно также заменить azure-npm-node-metrics задание следующим содержимым или включить его в предварительно существующее задание для модулей pod Kubernetes:
- job_name: "azure-npm-node-metrics-from-pod-config"
metrics_path: /node-metrics
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
regex: kube-system
action: keep
- source_labels: [__meta_kubernetes_pod_annotationpresent_azure_Network Policy Manager_scrapeable]
action: keep
- source_labels: [__address__]
action: replace
regex: ([^:]+)(?::\d+)?
replacement: "$1:10091"
target_label: __address__
Настройка оповещений для AlertManager
Если вы используете сервер Prometheus, вы можете настроить AlertManager так. Ниже приведен пример конфигурации для двух правил генерации оповещений, описанных ранее:
groups:
- name: npm.rules
rules:
# fire when Network Policy Manager has a new failure with an OS call or when translating a Network Policy (suppose there's a scraping interval of 5m)
- alert: AzureNetwork Policy ManagerFailureCreatePolicy
# this expression says to grab the current count minus the count 5 minutes ago, or grab the current count if there was no data 5 minutes ago
expr: (npm_add_policy_exec_time_count{had_error='true'} - (npm_add_policy_exec_time_count{had_error='true'} offset 5m)) or npm_add_policy_exec_time_count{had_error='true'}
labels:
severity: warning
addon: azure-npm
annotations:
summary: "Azure Network Policy Manager failed to handle a policy create event"
description: "Current failure count since Network Policy Manager started: {{ $value }}"
# fire when the median time to apply changes for a pod create event is more than 100 milliseconds.
- alert: AzurenpmHighControllerPodCreateTimeMedian
expr: topk(1, npm_controller_pod_exec_time{operation="create",quantile="0.5",had_error="false"}) > 100.0
labels:
severity: warning
addon: azure-Network Policy Manager
annotations:
summary: "Azure Network Policy Manager controller pod create time median > 100.0 ms"
# could have a simpler description like the one for the alert above,
# but this description includes the number of pod creates that were handled in the past 10 minutes,
# which is the retention period for observations when calculating quantiles for a Prometheus Summary metric
description: "value: [{{ $value }}] and observation count: [{{ printf `(npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'} - (npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'} offset 10m)) or npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'}` $labels.pod $labels.pod $labels.pod | query | first | value }}] for pod: [{{ $labels.pod }}]"
Параметры визуализации для Prometheus
При использовании сервера Prometheus поддерживается только панель мониторинга Grafana.
Если вы еще не сделали этого, настройте сервер Grafana и настройте источник данных Prometheus. Затем импортируйте Панель мониторинга Grafana с серверной частью Prometheus в Grafana Labs.
Визуальные элементы для этой панели мониторинга идентичны панели мониторинга с серверной частью аналитики контейнеров или log analytics.
Примеры панелей мониторинга
Ниже приведены примеры панелей мониторинга для метрик диспетчера сетевых политик в аналитике контейнеров (CI) и Grafana.
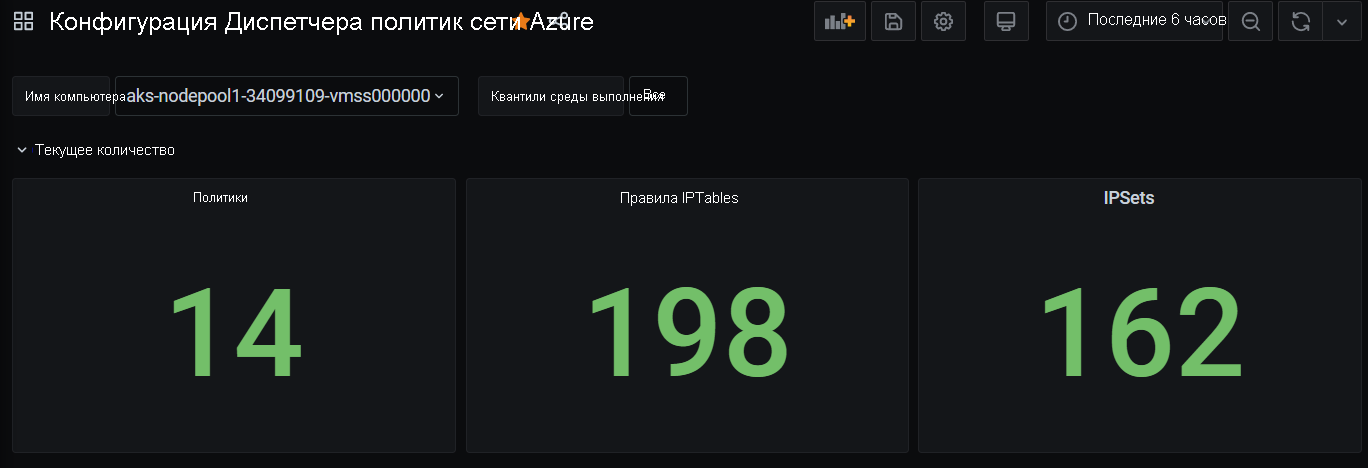
Суммарные счетчики CI
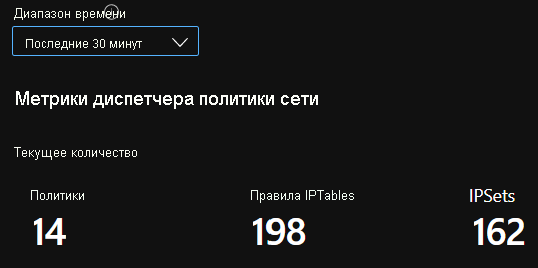
Количество CI с течением времени

Записи CI IPSet

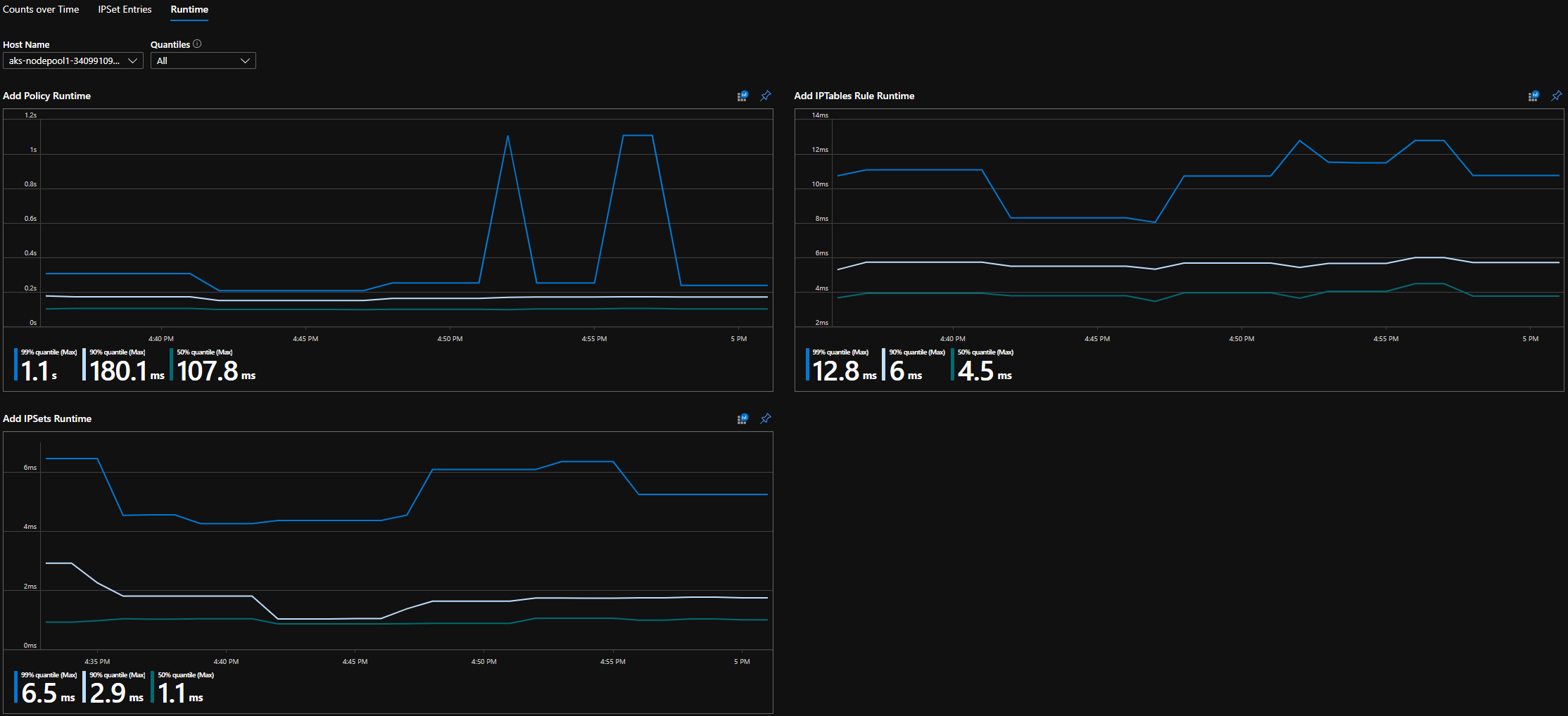
Квантили среды выполнения CI
Сводка панелей мониторинга Grafana
Количество панелей мониторинга Grafana с течением времени

Записи IPSet панели мониторинга Grafana

Квантили среды выполнения панели мониторинга Grafana

Следующие шаги
Дополнительные сведения о Службе Azure Kubernetes.
Дополнительные сведения о работе с контейнерами в сети.
Развертывание подключаемого модуля для кластеров Kubernetes и контейнеров Docker.