Использование плиток
Вы можете использовать настойку для максимальной ускорения приложения. Плитка делит потоки на равные прямоугольные подмножества или плитки. Если вы используете соответствующий размер плитки и алгоритм плиток, вы можете получить еще больше ускорения из кода C++ AMP. Основными компонентами тилинга являются:
tile_staticПеременные. Основное преимущество при работе с плиткой — это повышение производительности доступаtile_static. Доступ к данным в памяти может быть значительно быстрее, чем доступ к данным вtile_staticглобальном пространстве (arrayилиarray_viewобъектах). Экземпляр переменной создается для каждойtile_staticплитки, а все потоки в плитке имеют доступ к переменной. В типичном алгоритме плитки данные копируются вtile_staticпамять один раз из глобальной памяти, а затем получают доступ к памяти много разtile_static.метод tile_barrier::wait. Вызов приостановки
tile_barrier::waitвыполнения текущего потока до тех пор, пока все потоки в одной плитке не достигают вызоваtile_barrier::wait. Вы не можете гарантировать порядок выполнения потоков, только если потоки в плитке не будут выполняться после вызоваtile_barrier::wait, пока все потоки не достигли вызова. Это означает, что с помощьюtile_barrier::waitметода можно выполнять задачи на основе плитки по плитке, а не по потоку. Типичный алгоритм облицовки имеет код для инициализацииtile_staticпамяти для всей плитки, за которой следует вызовtile_barrier::wait.tile_barrier::waitСледующий код содержит вычисления, требующие доступа ко всем значениямtile_static.Локальное и глобальное индексирование. У вас есть доступ к индексу потока относительно всего
array_viewилиarrayобъекта и индекса относительно плитки. Использование локального индекса позволяет упростить чтение и отладку кода. Как правило, для доступаarrayarray_viewкtile_staticпеременным и глобальным индексированием используется локальная индексация.класс tiled_extent и класс tiled_index. Вместо объекта в вызове
parallel_for_eachиспользуетсяtiled_extentобъектextent. Вместо объекта в вызовеparallel_for_eachиспользуетсяtiled_indexобъектindex.
Чтобы воспользоваться преимуществами наложения, алгоритм должен секционировать вычислительный домен на плитки, а затем скопировать данные плитки в tile_static переменные для быстрого доступа.
Пример глобальных, плиток и локальных индексов
Примечание.
Заголовки C++ AMP устарели начиная с Visual Studio 2022 версии 17.0.
Включение всех заголовков AMP приведет к возникновению ошибок сборки. Определите _SILENCE_AMP_DEPRECATION_WARNINGS перед включением всех заголовков AMP, чтобы замолчать предупреждения.
На следующей схеме представлена матрица 8x9 данных, упорядоченная на 2x3 плитках.
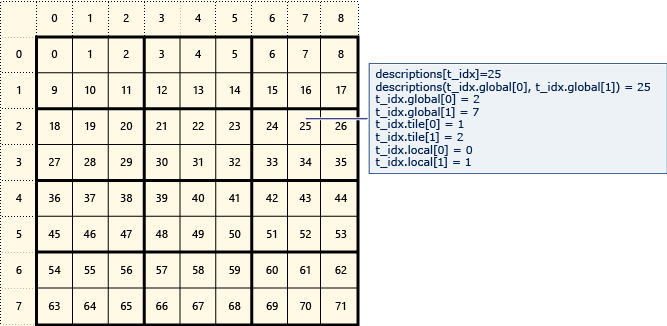
В следующем примере отображаются глобальные, плитки и локальные индексы этой плитки матрицы. Объект array_view создается с помощью элементов типа Description. Содержит Description глобальные, плитки и локальные индексы элемента в матрице. Код в вызове задает parallel_for_each значения глобальных, плиток и локальных индексов каждого элемента. Выходные данные отображают значения в структурах Description .
#include <iostream>
#include <iomanip>
#include <Windows.h>
#include <amp.h>
using namespace concurrency;
const int ROWS = 8;
const int COLS = 9;
// tileRow and tileColumn specify the tile that each thread is in.
// globalRow and globalColumn specify the location of the thread in the array_view.
// localRow and localColumn specify the location of the thread relative to the tile.
struct Description {
int value;
int tileRow;
int tileColumn;
int globalRow;
int globalColumn;
int localRow;
int localColumn;
};
// A helper function for formatting the output.
void SetConsoleColor(int color) {
int colorValue = (color == 0) 4 : 2;
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), colorValue);
}
// A helper function for formatting the output.
void SetConsoleSize(int height, int width) {
COORD coord;
coord.X = width;
coord.Y = height;
SetConsoleScreenBufferSize(GetStdHandle(STD_OUTPUT_HANDLE), coord);
SMALL_RECT* rect = new SMALL_RECT();
rect->Left = 0;
rect->Top = 0;
rect->Right = width;
rect->Bottom = height;
SetConsoleWindowInfo(GetStdHandle(STD_OUTPUT_HANDLE), true, rect);
}
// This method creates an 8x9 matrix of Description structures.
// In the call to parallel_for_each, the structure is updated
// with tile, global, and local indices.
void TilingDescription() {
// Create 72 (8x9) Description structures.
std::vector<Description> descs;
for (int i = 0; i < ROWS * COLS; i++) {
Description d = {i, 0, 0, 0, 0, 0, 0};
descs.push_back(d);
}
// Create an array_view from the Description structures.
extent<2> matrix(ROWS, COLS);
array_view<Description, 2> descriptions(matrix, descs);
// Update each Description with the tile, global, and local indices.
parallel_for_each(descriptions.extent.tile< 2, 3>(),
[=] (tiled_index< 2, 3> t_idx) restrict(amp)
{
descriptions[t_idx].globalRow = t_idx.global[0];
descriptions[t_idx].globalColumn = t_idx.global[1];
descriptions[t_idx].tileRow = t_idx.tile[0];
descriptions[t_idx].tileColumn = t_idx.tile[1];
descriptions[t_idx].localRow = t_idx.local[0];
descriptions[t_idx].localColumn= t_idx.local[1];
});
// Print out the Description structure for each element in the matrix.
// Tiles are displayed in red and green to distinguish them from each other.
SetConsoleSize(100, 150);
for (int row = 0; row < ROWS; row++) {
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Value: " << std::setw(2) << descriptions(row, column).value << " ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Tile: " << "(" << descriptions(row, column).tileRow << "," << descriptions(row, column).tileColumn << ") ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Global: " << "(" << descriptions(row, column).globalRow << "," << descriptions(row, column).globalColumn << ") ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Local: " << "(" << descriptions(row, column).localRow << "," << descriptions(row, column).localColumn << ") ";
}
std::cout << "\n";
std::cout << "\n";
}
}
int main() {
TilingDescription();
char wait;
std::cin >> wait;
}
Основная работа примера заключается в определении array_view объекта и вызове parallel_for_each.
Вектор
Descriptionструктур копируется в объект 8x9array_view.Метод
parallel_for_eachвызывается с объектом вtiled_extentкачестве вычислительного домена. Объектtiled_extentсоздается путем вызоваextent::tile()метода переменнойdescriptions. Параметры типа вызоваextent::tile(),<2,3>укажите, что создаются 2x3 плитки. Таким образом, матрица 8x9 состоит из 12 плиток, четырех строк и трех столбцов.Метод
parallel_for_eachвызывается с помощьюtiled_index<2,3>объекта (t_idx) в качестве индекса. Параметры типа индекса (t_idx) должны соответствовать параметрам типа вычислительного домена (descriptions.extent.tile< 2, 3>()).При выполнении каждого потока индекс
t_idxвозвращает сведения о том, в каком фрагменте находится поток (tiled_index::tileсвойство) и расположении потока в плитке (tiled_index::localсвойстве).
Синхронизация плиток— tile_static и tile_barrier::wait
В предыдущем примере показан макет плитки и индексы, но это не очень полезно. Наложение становится полезным, когда плитки являются неотъемлемой частью алгоритма и переменных эксплойтов tile_static . Так как все потоки на плитке имеют доступ к tile_static переменным, вызовы tile_barrier::wait используются для синхронизации доступа к tile_static переменным. Хотя все потоки на плитке имеют доступ к tile_static переменным, в плитке нет гарантированного порядка выполнения потоков на плитке. В следующем примере показано, как использовать tile_static переменные и tile_barrier::wait метод для вычисления среднего значения каждой плитки. Ниже приведены ключи для понимания примера:
Необработанные данные хранятся в матрице 8x8.
Размер плитки составляет 2x2. Это создает сетку 4x4 плиток, а средние значения можно хранить в матрице 4x4 с помощью
arrayобъекта. Существует только ограниченное количество типов, которые можно записать по ссылке в функции с ограничением AMP. Классarrayявляется одним из них.Размер матрицы и размер выборки определяются с помощью
#defineинструкций, так как параметры типа вarray,extentarray_viewиtiled_indexдолжны быть константными значениями. Вы также можете использоватьconst int staticобъявления. Как дополнительное преимущество, это тривиальное изменение размера выборки, чтобы вычислить среднее значение более 4x4 плиток.Для
tile_staticкаждой плитки объявляется массив 2x2 значений с плавающей запятой. Хотя объявление находится в пути кода для каждого потока, создается только один массив для каждой плитки в матрице.Существует строка кода для копирования значений на каждой плитке
tile_staticв массив. Для каждого потока после копирования значения в массив выполнение на поток останавливается из-за вызоваtile_barrier::wait.Когда все потоки на плитке достигли барьера, можно вычислить среднее значение. Так как код выполняется для каждого потока, существует оператор, который вычисляет
ifсреднее значение только в одном потоке. Среднее хранится в средней переменной. Барьер по сути является конструкцией, которая управляет вычислениями по плитке, так как можно использоватьforцикл.Данные в переменной
averages, так как этоarrayобъект, должны быть скопированы обратно в узел. В этом примере используется оператор преобразования векторов.В полном примере можно изменить SAMPLESIZE на 4, а код выполняется правильно без каких-либо других изменений.
#include <iostream>
#include <amp.h>
using namespace concurrency;
#define SAMPLESIZE 2
#define MATRIXSIZE 8
void SamplingExample() {
// Create data and array_view for the matrix.
std::vector<float> rawData;
for (int i = 0; i < MATRIXSIZE * MATRIXSIZE; i++) {
rawData.push_back((float)i);
}
extent<2> dataExtent(MATRIXSIZE, MATRIXSIZE);
array_view<float, 2> matrix(dataExtent, rawData);
// Create the array for the averages.
// There is one element in the output for each tile in the data.
std::vector<float> outputData;
int outputSize = MATRIXSIZE / SAMPLESIZE;
for (int j = 0; j < outputSize * outputSize; j++) {
outputData.push_back((float)0);
}
extent<2> outputExtent(MATRIXSIZE / SAMPLESIZE, MATRIXSIZE / SAMPLESIZE);
array<float, 2> averages(outputExtent, outputData.begin(), outputData.end());
// Use tiles that are SAMPLESIZE x SAMPLESIZE.
// Find the average of the values in each tile.
// The only reference-type variable you can pass into the parallel_for_each call
// is a concurrency::array.
parallel_for_each(matrix.extent.tile<SAMPLESIZE, SAMPLESIZE>(),
[=, &averages] (tiled_index<SAMPLESIZE, SAMPLESIZE> t_idx) restrict(amp)
{
// Copy the values of the tile into a tile-sized array.
tile_static float tileValues[SAMPLESIZE][SAMPLESIZE];
tileValues[t_idx.local[0]][t_idx.local[1]] = matrix[t_idx];
// Wait for the tile-sized array to load before you calculate the average.
t_idx.barrier.wait();
// If you remove the if statement, then the calculation executes for every
// thread in the tile, and makes the same assignment to averages each time.
if (t_idx.local[0] == 0 && t_idx.local[1] == 0) {
for (int trow = 0; trow < SAMPLESIZE; trow++) {
for (int tcol = 0; tcol < SAMPLESIZE; tcol++) {
averages(t_idx.tile[0],t_idx.tile[1]) += tileValues[trow][tcol];
}
}
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE * SAMPLESIZE);
}
});
// Print out the results.
// You cannot access the values in averages directly. You must copy them
// back to a CPU variable.
outputData = averages;
for (int row = 0; row < outputSize; row++) {
for (int col = 0; col < outputSize; col++) {
std::cout << outputData[row*outputSize + col] << " ";
}
std::cout << "\n";
}
// Output for SAMPLESIZE = 2 is:
// 4.5 6.5 8.5 10.5
// 20.5 22.5 24.5 26.5
// 36.5 38.5 40.5 42.5
// 52.5 54.5 56.5 58.5
// Output for SAMPLESIZE = 4 is:
// 13.5 17.5
// 45.5 49.5
}
int main() {
SamplingExample();
}
Конфликты
Может потребоваться создать tile_static переменную с именем total и увеличить ее для каждого потока, как показано ниже.
// Do not do this.
tile_static float total;
total += matrix[t_idx];
t_idx.barrier.wait();
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE* SAMPLESIZE);
Первая проблема с этим подходом заключается в том, что tile_static переменные не могут иметь инициализаторы. Вторая проблема заключается в том, что существует состояние гонки для назначения total, так как все потоки в плитке имеют доступ к переменной в определенном порядке. Вы можете запрограммировать алгоритм, чтобы разрешить доступ только к одному потоку на каждом барьере, как показано далее. Однако это решение не расширяемо.
// Do not do this.
tile_static float total;
if (t_idx.local[0] == 0&& t_idx.local[1] == 0) {
total = matrix[t_idx];
}
t_idx.barrier.wait();
if (t_idx.local[0] == 0&& t_idx.local[1] == 1) {
total += matrix[t_idx];
}
t_idx.barrier.wait();
// etc.
Заборы памяти
Существует два типа доступа к памяти, которые должны быть синхронизированы— глобальный доступ к памяти и tile_static доступ к памяти. Объект concurrency::array выделяет только глобальную память. Может concurrency::array_view ссылаться на глобальную память, tile_static память или оба, в зависимости от того, как она была создана. Существует два типа памяти, которые должны быть синхронизированы:
глобальная память
tile_static
Забор памяти гарантирует, что доступ к памяти доступен другим потокам в плитке потока и что доступ к памяти выполняется в соответствии с порядком программы. Чтобы обеспечить это, компиляторы и процессоры не переупорядочение операций чтения и записи через ограждение. В C++ AMP забор памяти создается вызовом одного из следующих методов:
метод tile_barrier::wait: создает ограждение как по всему миру, так и
tile_staticв памяти.метод tile_barrier::wait_with_all_memory_fence: создает ограждение как по всему миру, так и
tile_staticв памяти.метод tile_barrier::wait_with_global_memory_fence: создает ограждение только для глобальной памяти.
метод tile_barrier::wait_with_tile_static_memory_fence: создает ограждение вокруг только
tile_staticпамяти.
Вызов определенного забора, который требуется, может повысить производительность приложения. Тип барьера влияет на то, как компилятор и операторы переупорядочения оборудования. Например, если вы используете глобальный забор памяти, он применяется только к глобальным доступам к памяти, поэтому компилятор и оборудование могут переупорядочение tile_static операций чтения и записи в переменные на обеих сторонах ограждения.
В следующем примере барьер синхронизирует записи в tileValuesпеременную tile_static . В этом примере tile_barrier::wait_with_tile_static_memory_fence вызывается вместо tile_barrier::wait.
// Using a tile_static memory fence.
parallel_for_each(matrix.extent.tile<SAMPLESIZE, SAMPLESIZE>(),
[=, &averages] (tiled_index<SAMPLESIZE, SAMPLESIZE> t_idx) restrict(amp)
{
// Copy the values of the tile into a tile-sized array.
tile_static float tileValues[SAMPLESIZE][SAMPLESIZE];
tileValues[t_idx.local[0]][t_idx.local[1]] = matrix[t_idx];
// Wait for the tile-sized array to load before calculating the average.
t_idx.barrier.wait_with_tile_static_memory_fence();
// If you remove the if statement, then the calculation executes
// for every thread in the tile, and makes the same assignment to
// averages each time.
if (t_idx.local[0] == 0&& t_idx.local[1] == 0) {
for (int trow = 0; trow <SAMPLESIZE; trow++) {
for (int tcol = 0; tcol <SAMPLESIZE; tcol++) {
averages(t_idx.tile[0],t_idx.tile[1]) += tileValues[trow][tcol];
}
}
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE* SAMPLESIZE);
}
});
См. также
C++ AMP (C++ Accelerated Massive Parallelism)
Ключевое слово tile_static