Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье показано, как отлаживать приложение, использующее ускоренный массовый параллелизм C++ (C++ AMP), чтобы воспользоваться преимуществами графической обработки (GPU). В нем используется программа параллельного сокращения, которая суммирует большой массив целых чисел. В этом пошаговом руководстве рассматриваются следующие задачи:
- Запуск отладчика GPU.
- Проверка потоков GPU в окне потоков GPU.
- Использование окна Parallel Stacks для одновременного наблюдения за стеками вызовов нескольких потоков GPU.
- Использование окна Parallel Watch для проверки значений одного выражения в нескольких потоках одновременно.
- Маркировка, замораживание, размораживание и группировка потоков GPU.
- Выполнение всех потоков плитки в определенное место в коде.
Необходимые условия
Перед началом работы с этим пошаговом руководстве выполните следующие действия.
Замечание
Заголовки C++ AMP устарели начиная с Visual Studio 2022 версии 17.0.
Включение любых заголовков AMP приведет к возникновению ошибок сборки. Определите _SILENCE_AMP_DEPRECATION_WARNINGS перед включением всех заголовков AMP, чтобы подавить предупреждения.
- Прочитайте Обзор C++ AMP.
- Убедитесь, что номера строк отображаются в текстовом редакторе. Дополнительные сведения см. в разделе "Практическое руководство. Отображение номеров строк в редакторе".
- Убедитесь, что вы используете по крайней мере Windows 8 или Windows Server 2012 для поддержки отладки в эмуляторе программного обеспечения.
Замечание
Отображаемые на компьютере имена или расположения некоторых элементов пользовательского интерфейса Visual Studio могут отличаться от указанных в следующих инструкциях. Выпуск Visual Studio, который у вас есть, и параметры, которые вы используете, определяют эти элементы. Дополнительные сведения см. в разделе Персонализация среды IDE.
Создание примера проекта
Инструкции по созданию проекта зависят от используемой версии Visual Studio. Убедитесь, что на этой странице выбрана правильная версия документации из области над оглавлением.
Создание примера проекта в Visual Studio
В строке меню выберите Файл>Создать>Проект, чтобы открыть диалоговое окно Создание проекта.
В верхней части диалогового окна задайте для параметра Язык значение C++, для параметра Платформа значение Windows, а для Типа проекта — Консоль.
В отфильтрованном списке типов проектов щелкните Консольное приложение, а затем нажмите кнопку Далее. На следующей странице введите
AMPMapReduceполе "Имя ", чтобы указать имя проекта, и укажите расположение проекта, если требуется другой.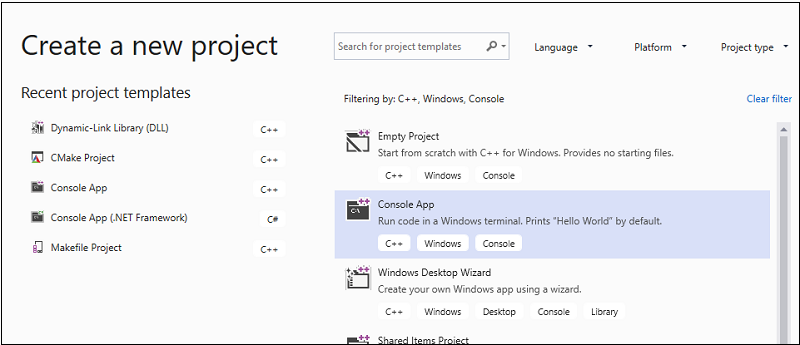
Нажмите кнопку Создать, чтобы создать клиентский проект.
Далее.
Откройте AMPMapReduce.cpp и замените его содержимое следующим кодом.
// AMPMapReduce.cpp defines the entry point for the program. // The program performs a parallel-sum reduction that computes the sum of an array of integers. #include <stdio.h> #include <tchar.h> #include <amp.h> const int BLOCK_DIM = 32; using namespace concurrency; void sum_kernel_tiled(tiled_index<BLOCK_DIM> t_idx, array<int, 1> &A, int stride_size) restrict(amp) { tile_static int localA[BLOCK_DIM]; index<1> globalIdx = t_idx.global * stride_size; index<1> localIdx = t_idx.local; localA[localIdx[0]] = A[globalIdx]; t_idx.barrier.wait(); // Aggregate all elements in one tile into the first element. for (int i = BLOCK_DIM / 2; i > 0; i /= 2) { if (localIdx[0] < i) { localA[localIdx[0]] += localA[localIdx[0] + i]; } t_idx.barrier.wait(); } if (localIdx[0] == 0) { A[globalIdx] = localA[0]; } } int size_after_padding(int n) { // The extent might have to be slightly bigger than num_stride to // be evenly divisible by BLOCK_DIM. You can do this by padding with zeros. // The calculation to do this is BLOCK_DIM * ceil(n / BLOCK_DIM) return ((n - 1) / BLOCK_DIM + 1) * BLOCK_DIM; } int reduction_sum_gpu_kernel(array<int, 1> input) { int len = input.extent[0]; //Tree-based reduction control that uses the CPU. for (int stride_size = 1; stride_size < len; stride_size *= BLOCK_DIM) { // Number of useful values in the array, given the current // stride size. int num_strides = len / stride_size; extent<1> e(size_after_padding(num_strides)); // The sum kernel that uses the GPU. parallel_for_each(extent<1>(e).tile<BLOCK_DIM>(), [&input, stride_size] (tiled_index<BLOCK_DIM> idx) restrict(amp) { sum_kernel_tiled(idx, input, stride_size); }); } array_view<int, 1> output = input.section(extent<1>(1)); return output[0]; } int cpu_sum(const std::vector<int> &arr) { int sum = 0; for (size_t i = 0; i < arr.size(); i++) { sum += arr[i]; } return sum; } std::vector<int> rand_vector(unsigned int size) { srand(2011); std::vector<int> vec(size); for (size_t i = 0; i < size; i++) { vec[i] = rand(); } return vec; } array<int, 1> vector_to_array(const std::vector<int> &vec) { array<int, 1> arr(vec.size()); copy(vec.begin(), vec.end(), arr); return arr; } int _tmain(int argc, _TCHAR* argv[]) { std::vector<int> vec = rand_vector(10000); array<int, 1> arr = vector_to_array(vec); int expected = cpu_sum(vec); int actual = reduction_sum_gpu_kernel(arr); bool passed = (expected == actual); if (!passed) { printf("Actual (GPU): %d, Expected (CPU): %d", actual, expected); } printf("sum: %s\n", passed ? "Passed!" : "Failed!"); getchar(); return 0; }В строке меню выберите Файл>Сохранить все.
В Обозреватель решений откройте контекстное меню для AMPMapReduce и выберите пункт "Свойства".
В диалоговом окне "Страницы свойств" в разделе "Свойства конфигурации" выберите C/C++>Заголовки, компилируемые предварительно.
Для свойства предварительно скомпилированного заголовка нажмите кнопку "Не использовать предварительно скомпилированные заголовки", а затем нажмите кнопку "ОК".
На строке меню выберите Сборка>Построить решение.
Отладка кода ЦП
В этой процедуре вы будете использовать локальный отладчик Windows, чтобы убедиться, что код ЦП в этом приложении правильный. Сегмент кода процессора в этом приложении, который особенно интересен, - это for цикл в функции reduction_sum_gpu_kernel. Он управляет деревоподобным параллельным редуцированием, которое выполняется на GPU.
Отладка кода ЦП
В Обозреватель решений откройте контекстное меню для AMPMapReduce и выберите пункт "Свойства".
В диалоговом окне "Страницы свойств" в разделе "Свойства конфигурации" выберите "Отладка". Убедитесь, что в списке Отладчик для запуска выбран пункт Local Windows Debugger.
Вернитесь в редактор кода.
Установите точки останова на строках кода, показанных на следующем рисунке (приблизительно строки 67 строк 70).

Точки останова ЦПВ строке меню выберите Отладка>Начать отладку.
В окне "Локальные" просмотрите значение
stride_sizeдо достижения точки останова в строке 70.В строке меню выберите Отладка>Остановить отладку.
Отладка кода GPU
В этом разделе показано, как выполнить отладку кода GPU, который является кодом, содержащимся в sum_kernel_tiled функции. Код GPU вычисляет сумму целых чисел для каждого блока параллельно.
Отладка кода GPU
В Обозреватель решений откройте контекстное меню для AMPMapReduce и выберите пункт "Свойства".
В диалоговом окне "Страницы свойств" в разделе "Свойства конфигурации" выберите "Отладка".
В списке Загружаемый отладчик выберите Локальный отладчик Windows.
В списке типов отладчика убедитесь, что выбран параметр "Авто ".
Авто — это значение по умолчанию. В версиях до Windows 10 значение GPU Only является обязательным вместо Auto.
Нажмите кнопку ОК.
Задайте точку останова в строке 30, как показано на следующем рисунке.

Точка останова GPUВ строке меню выберите Отладка>Начать отладку. Точки останова в коде ЦП в строках 67 и 70 не выполняются во время отладки GPU, так как эти строки кода выполняются на ЦП.
Чтобы использовать окно потоков GPU
Чтобы открыть окно потоков GPU, в строке меню выберите "Отладкапотоков> GPU Windows".>
Вы можете проверить состояние потоков GPU в окне потоков GPU, которое отображается.
Закрепите окно потоков GPU в нижней части Visual Studio. Нажмите кнопку Развернуть переключатель потока, чтобы отобразить текстовые поля плитки и потока. В окне потоков GPU отображается общее количество активных и заблокированных потоков GPU, как показано на следующем рисунке.

Окно "Потоки GPU"313 плиток выделяются для этого вычисления. Каждая плитка содержит 32 потока. Так как локальная отладка GPU выполняется в эмуляторе программного обеспечения, существует четыре активных потока GPU. Четыре потока одновременно выполняют инструкции, а затем переходят вместе к следующей инструкции.
В окне потоков GPU активно четыре потока GPU, и 28 потоков GPU заблокированы в инструкции tile_barrier::wait, определенной примерно на строке 21 (
t_idx.barrier.wait();). Все 32 потока GPU принадлежат первой плитке.tile[0]Стрелка указывает на строку, содержащую текущий поток. Чтобы переключиться на другой поток, используйте один из следующих методов:В строке переключения на поток в окне GPU Threads откройте контекстное меню и выберите Переключиться на поток. Если строка представляет несколько потоков, переключитесь на первый поток в соответствии с координатами потока.
Введите значения плитки и потока в соответствующих текстовых полях, а затем нажмите кнопку Переключить поток.
В окне "Стек вызовов" отображается стек вызовов текущего потока GPU.
Использовать окно параллельных стеков
Чтобы открыть окно Параллельных стеков, в строке меню выберите Отладка>Windows>Параллельные стекы.
Окно Параллельных стеков можно использовать для одновременной проверки кадров стека нескольких потоков GPU.
Закрепите окно Параллельных стеков в нижней части Visual Studio.
Убедитесь, что в списке в левом верхнем углу выбраны Threads. На следующем рисунке в окне Параллельных стеков показывается вид стека вызовов потоков GPU, который вы видели в окне Потоки GPU.

Окно "Параллельные стеки"32 потока исполнения пошли из
_kernel_stubк инструкции lambda в вызове функцииparallel_for_each, а затем в функциюsum_kernel_tiled, где происходит параллельная редукция. 28 из 32 потоков прошли доtile_barrier::waitинструкции и остаются заблокированными на строке 22, а остальные четыре потока остаются активными в функцииsum_kernel_tiledна строке 30.Вы можете проверить свойства потока GPU. Они доступны в окне Потоки GPU в подробной подсказке данных окна Параллельные стеки. Чтобы увидеть их, наведите указатель на стековую рамку
sum_kernel_tiled. На следующем рисунке показан DataTip.
Подсказка данных для потока GPUДополнительные сведения о окне параллельных стеков см. в разделе "Использование окна параллельных стеков".
Параллельное окно наблюдения
Чтобы открыть окно "Параллельное наблюдение", на строке меню выберите Отладка>Окна>Параллельное наблюдение>Параллельное наблюдение 1.
Для проверки значений выражения в нескольких потоках можно использовать окно Parallel Watch .
Прикрепите окно Parallel Watch 1 к нижней части Visual Studio. В таблице окна Параллельного отслеживания есть 32 строки. Каждый соответствует потоку GPU, который появился как в окне потоков GPU, так и в окне параллельных стеков . Теперь можно ввести выражения, значения которых необходимо проверить во всех 32 потоках GPU.
Выберите заголовок столбца "Добавить наблюдение", введите
localIdx, а затем нажмите клавишу ENTER.Снова выберите заголовок столбца "Добавить контрольные значения", введите
globalIdxи нажмите клавишу ВВОД.Снова выберите заголовок столбца "Добавить контрольные значения", введите
localA[localIdx[0]]и нажмите клавишу ВВОД.Вы можете сортировать по указанному выражению, выбрав соответствующий заголовок столбца.
Выберите заголовок столбца localA[localIdx[0], чтобы отсортировать столбец. На следующем рисунке показаны результаты сортировки по localA[localIdx[0]].

Результаты сортировкиВы можете экспортировать содержимое в окне Параллельных часов в Excel, нажав кнопку Excel и выбрав команду "Открыть в Excel". Если на компьютере разработки установлен Excel, кнопка открывает лист Excel, содержащий содержимое.
В правом верхнем углу окна Parallel Watch есть элемент управления фильтра, который можно использовать для фильтрации содержимого с помощью логических выражений. Введите
localA[localIdx[0]] > 20000в текстовое поле элемента управления фильтром, а затем нажмите клавишу ВВОД.Теперь окно содержит только потоки, в которых
localA[localIdx[0]]значение больше 20000. Содержимое по-прежнему отсортировано по столбцуlocalA[localIdx[0]], что соответствует ранее выбранному вами действию сортировки.
Пометка потоков GPU
Вы можете пометить определенные потоки GPU, отметив их в окне потоков GPU, окне параллельного наблюдения или подсказке в окне параллельных стеков. Если строка в окне потоков GPU содержит несколько потоков, пометка этой строки помечает все потоки, содержащиеся в строке.
Пометить потоки GPU
Выберите заголовок столбца [Thread] в окне Parallel Watch 1, чтобы отсортировать по индексу плитки и индексу потока.
В строке меню выберите Отладка>Продолжить, что приводит к тому, что четыре активные потока достигают следующего барьера (определено в строке 32, AMPMapReduce.cpp).
Выберите символ флага в левой части строки, содержащей четыре потока, которые теперь активны.
На следующем рисунке показаны четыре активные помеченные потоки в окне потоков GPU.

Активные потоки в окне "Потоки GPU"Окно Параллельного наблюдения и подсказка DataTip окна параллельных стеков указывают на помеченные потоки.
Если вы хотите сосредоточиться на четырех потоках, помеченных вами, можно отобразить только помеченные потоки. Он ограничивает то, что вы видите в окнах потоков GPU, Parallel Watch и параллельных стэков.
Нажмите кнопку «Показать только отмеченные» на любом из окон или на панели инструментов «местоположение отладки». На следующем рисунке показана кнопка "Показать только помеченные" на панели инструментов "местоположения отладки".

Кнопка "Показать только отмеченные"Теперь окна потоков GPU, Параллельное наблюдение и Параллельные стеки отображают только помеченные потоки.
Замораживание и оттаивание потоков GPU
Вы можете заморозить (приостановить) и разморозить (возобновить) потоки GPU из окна потоков GPU или из окна параллельных часов. Вы можете заморозить и разморозить потоки ЦП таким же образом; для получения информации см. раздел "Практическое руководство: использование окна потоков".
Заморозка и разморозка потоков GPU
Нажмите кнопку "Показать только помеченные", чтобы отобразить все потоки.
В строке меню выберите "Продолжить отладку>".
Откройте контекстное меню активной строки и выберите "Закрепить".
На следующем рисунке окна потоков GPU показано, что все четыре потока приостановлены.

Замороженные потоки в окне потоков GPUАналогичным образом в окне Параллельный просмотр показано, что все четыре потока приостановлены.
В строке меню выберите "Продолжить отладку>", чтобы разрешить следующим четыре потокам GPU пройти мимо барьера в строке 22 и достичь точки останова в строке 30. В окне потоков GPU показано, что четыре ранее замороженных потока остаются замороженными и в активном состоянии.
В строке меню выберите "Отладка", "Продолжить".
Из окна Parallel Watch можно также разморозить отдельные или несколько потоков графического процессора.
Группировка потоков GPU
В контекстном меню для одного из потоков в окне потоков GPU выберите группировать по адресу.
Потоки в окне потоков GPU группируются по адресу. Адрес соответствует инструкции в дизассемблированном расположении каждой группы потоков. 24 потока находятся в строке 22, где выполняется метод tile_barrier::wait. 12 потоков находятся в инструкции по барьеру в строке 32. Четыре из этих потоков помечены. Восемь потоков находятся в точке останова в строке 30. Четыре из этих потоков заблокированы. На следующем рисунке показаны сгруппированные потоки в окне потоков GPU.

Сгруппированные потоки в окне потоков GPUВы также можете выполнить операцию Group By , открыв контекстное меню для сетки данных окна параллельных часов . Выберите Упорядочение по, а затем пункт меню, соответствующий вашему предпочтению группировки потоков.
Перенаправление всех потоков в определенное место в коде
Все потоки в заданной плитке будут запущены до строки, содержащей курсор, используя Запуск текущей плитки до курсора.
Запустить все потоки к позиции, помеченной курсором.
В контекстном меню для замороженных потоков выберите Разморозить.
В редакторе кода поместите курсор в строку 30.
В контекстном меню редактора кода выберите "Запустить текущую плитку к курсору".
24 потоки, которые ранее были заблокированы на барьере в строке 21, прошли до строки 32. Он показан в окно GPU Threads.
См. также
Обзор C++ AMP
Отладка кода GPU
Практическое руководство. Использование окна потоков GPU
Как использовать окно "Параллельное наблюдение"
Анализ кода C++ AMP с помощью визуализатора параллелизма