Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Сдвиг вправо — это практика перемещения некоторых тестов позже в процессе DevOps для тестирования в рабочей среде. Тестирование в рабочей среде использует реальные развертывания для проверки и измерения поведения и производительности приложения в рабочей среде.
Один из способов, которые команды DevOps могут повысить скорость, — это стратегия тестирования влево . Shift влево отправляет большинство тестов в конвейере DevOps, чтобы сократить время для достижения рабочей среды и надежной работы.
Но хотя многие виды тестов, например модульные тесты, могут легко перемещаться влево, некоторые классы тестов не могут выполняться без развертывания части или всего решения. Развертывание в службе качества обслуживания или промежуточной службы может имитировать сравнимую среду, но не существует полной замены рабочей среды. Teams обнаружили, что в рабочей среде должны произойти определенные типы тестирования.
Тестирование в рабочей среде обеспечивает:
- Полный спектр и разнообразие рабочей среды.
- Реальная рабочая нагрузка трафика клиента.
- Профили и поведение по мере развития спроса на рабочую среду со временем.
Рабочая среда продолжает меняться. Даже если приложение не изменяется, инфраструктура, которую она использует, постоянно изменяется. Тестирование в рабочей среде проверяет работоспособность и качество заданного рабочего развертывания и постоянно меняющейся рабочей среды.
Переход вправо на тестирование в рабочей среде особенно важен для следующих сценариев:
Развертывания микрослужб
Решения на основе микрослужб могут иметь большое количество микрослужб, разработанных, развернутых и управляемых независимо. Переключение тестирования вправо особенно важно для этих проектов, так как различные версии и конфигурации могут достичь рабочей среды различными способами. Независимо от предварительного покрытия тестов, необходимо проверить совместимость в рабочей среде.
Обеспечение качества после развертывания
Выпуск в рабочую среду составляет всего половину доставки программного обеспечения. Другая половина обеспечивает качество в масштабе с реальной рабочей нагрузкой в рабочей среде. Так как среда продолжает меняться, команда никогда не выполняет тестирование в рабочей среде.
Тестовые данные из рабочей среды — это буквально результаты теста из реальной рабочей нагрузки клиента. Тестирование в рабочей среде включает мониторинг, тестирование отработки отказа и внедрение ошибок. Это тестирование отслеживает сбои, исключения, метрики производительности и события безопасности. Данные телеметрии теста также помогают обнаруживать аномалии.
Уровни развертывания
Чтобы защитить рабочую среду, команды могут развертывать изменения в прогрессивной и управляемой форме с помощью развертываний на основе уровней и флагов функций. Например, лучше поймать ошибку, которая препятствует покупателю завершить покупку, когда менее 1% клиентов находятся на этом уровне развертывания, чем после переключения всех клиентов одновременно. Значение функции с обнаруженными сбоями должно превышать чистые потери этих сбоев, измеряемые значимым образом для данного бизнеса.
Первый уровень должен быть наименьшим размером, необходимым для запуска стандартного набора интеграции. Тесты могут быть похожи на те, которые уже выполняются ранее в конвейере в других средах, но тестирование проверяет, что поведение одинаково в рабочей среде. Этот уровень определяет очевидные ошибки, такие как неправильные настройки, прежде чем они влияют на всех клиентов.
После проверки начального уровня следующий уровень может расшириться, чтобы включить подмножество реальных пользователей для тестового запуска. Если все выглядит хорошо, развертывание может выполняться на дополнительных уровнях и тестах, пока все не будут использовать его. Полное развертывание не означает, что тестирование завершается. Отслеживание телеметрии критически важно для тестирования в рабочей среде.
Внедрение ошибок
Команды часто используют внедрение ошибок и инженерию хаоса , чтобы узнать, как система работает в условиях сбоя. Эти методики помогают:
- Убедитесь, что на самом деле работают механизмы устойчивости.
- Убедитесь, что сбой в одной подсистеме содержится в этой подсистеме и не каскаден для создания серьезного сбоя.
- Докажите, что ремонтная работа для предыдущего инцидента имеет желаемый эффект, не ожидая другого инцидента.
- Создавайте более реалистичные тренировки для инженеров живых сайтов, чтобы они могли лучше подготовиться к работе с инцидентами.
Рекомендуется автоматизировать эксперименты по внедрению ошибок, так как они являются дорогостоящими тестами, которые должны выполняться в постоянно изменяющихся системах.
Проектирование хаоса может быть эффективным инструментом, но должно быть ограничено канарной средой , которая не оказывает влияния на клиента.
Тестирование отработки отказа
Одна из форм внедрения ошибок — тестирование отработки отказа для поддержки непрерывности бизнес-процессов и аварийного восстановления (BCDR). Teams должны иметь планы отработки отказа для всех служб и подсистем. Планы должны включать:
- Четкое объяснение влияния на работу службы.
- Карта всех зависимостей с точки зрения платформы, технологии и людей, создающих планы BCDR.
- Официальная документация по процедурам аварийного восстановления.
- Частота регулярного выполнения аварийного восстановления.
Тестирование сбоя разбиения цепи
Механизм останова цепи отключает заданный компонент из более крупной системы, как правило, чтобы предотвратить сбои в этом компоненте от распространения за пределы ее границ. Вы можете намеренно активировать средства разбиения цепи для тестирования следующих сценариев:
Работает ли резервный вариант при открытии выключателя. Резервный вариант может работать с модульными тестами, но единственный способ узнать, будет ли он вести себя должным образом в рабочей среде, чтобы внедрить ошибку для его активации.
Имеет ли средство разбиения цепи правильное пороговое значение конфиденциальности, которое необходимо открыть. Внедрение ошибок может привести к принудительной задержке или отключению зависимостей для наблюдения за скоростью реагирования на разрыв. Важно проверить не только правильность поведения, но и это происходит достаточно быстро.
Пример. Тестирование средства разбиения кэша Redis
Кэш Redis повышает производительность продукта, ускоряя доступ к часто используемым данным. Рассмотрим сценарий, который принимает некритичную зависимость от Redis. Если Redis выходит из строя, система должна продолжать работать, так как она может вернуться к использованию исходного источника данных для запросов. Чтобы убедиться, что сбой Redis активирует разбиение цепи и что резервный вариант работает в рабочей среде, периодически выполняйте тесты с этими поведением.
На следующей схеме показаны тесты для резервного режима останова канала Redis. Цель заключается в том, чтобы убедиться, что при открытии средства останова вызовы в конечном итоге переходят к SQL.
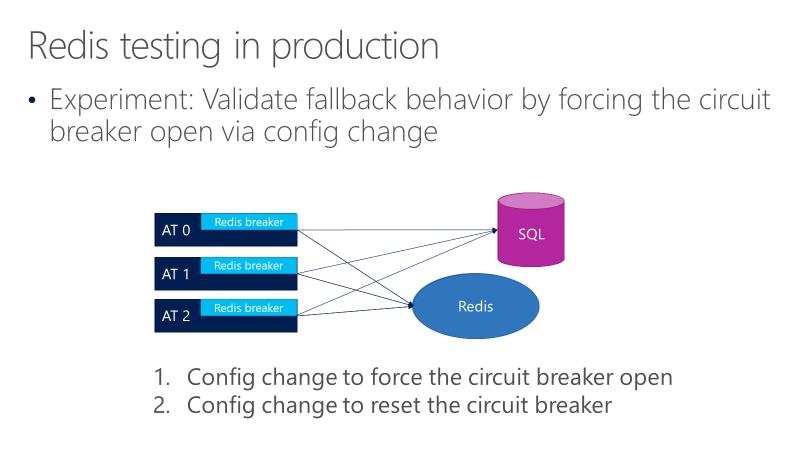
На приведенной выше схеме показаны три AT с разбиениями перед вызовами Redis. Один тест заставляет средство разбиения цепи открываться с помощью изменения конфигурации, а затем проверяет, будут ли вызовы переходить к SQL. Затем еще один тест проверяет противоположное изменение конфигурации, закрыв средство разбиения цепи, чтобы убедиться, что вызовы возвращаются обратно в Redis.
Этот тест проверяет, работает ли резервное поведение при открытии средства разбиения, но не проверяет, открывается ли конфигурация разбиения цепи, когда она должна. Для тестирования этого поведения требуется имитация фактических сбоев.
Агент сбоя может привести к сбоям в вызовах, которые будут отправляться в Redis. На следующей схеме показано тестирование с внедрением ошибок.
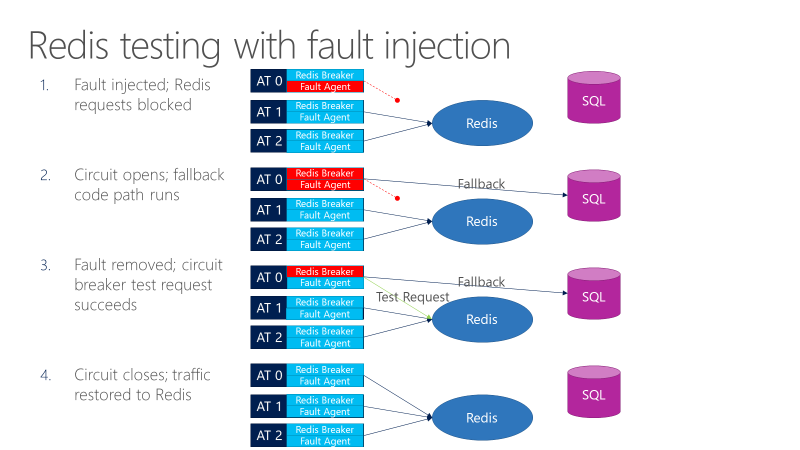
- Средство внедрения сбоя блокирует запросы Redis.
- Откроется средство разбиения цепи, и тест может наблюдать, работает ли резервный вариант.
- Ошибка удаляется, а средство останова канала отправляет тестовый запрос в Redis.
- Если запрос выполнен успешно, вызовы возвращаются обратно в Redis.
Дальнейшие шаги могут проверить чувствительность средства останова, слишком высокий или слишком низкий порог, а также то, вмешиваются ли другие системные ожидания в поведение разбиения цепи.
В этом примере, если средство останова не открывается или закрывается должным образом, это может привести к инциденту динамического сайта (LSI). Без тестирования внедрения ошибок проблема может оказаться незамеченной, так как это трудно сделать в лабораторной среде.
Дальнейшие шаги
- [Смена тестирования влево с модульными тестами]shift-left
- Что такое микрослужбы?
- Запуск тестовой отработки отказа (аварийное восстановление) в Azure
- Рекомендации по безопасному развертыванию
- Что такое мониторинг?
- Что такое проектирование платформы?