Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Прием данных — это процесс сбора, чтения и подготовки данных из разных источников, таких как файлы, базы данных, API или облачные службы, чтобы его можно было использовать в подчиненных приложениях. На практике этот процесс следует рабочему процессу extract-Transform-Load (ETL):
- Извлеките данные из исходного источника, будь то PDF, документ Word, звуковой файл или веб-API.
- Преобразование данных путем очистки, фрагментирования, обогащения или преобразования форматов.
- Загрузите данные в место назначения, например базу данных, векторное хранилище или модель ИИ для получения и анализа.
Для сценариев искусственного интеллекта и машинного обучения, особенно Retrieval-Augmented Generation (RAG), процесс поглощения данных — это не только преобразование данных из одного формата в другой. Речь идет о том, чтобы использовать данные для интеллектуальных приложений. Это означает представление документов таким образом, чтобы сохранять их структуру и смысл, разбивать их на управляемые части, обогащать метаданными или встраиваниями, и хранить их, чтобы их можно было быстро и точно извлекать.
Почему прием данных имеет важное значение для приложений ИИ
Представьте, что вы создаете чат-бот с поддержкой RAG, чтобы помочь сотрудникам найти информацию в обширной коллекции документов вашей компании. Эти документы могут включать PDF-файлы, файлы Word, презентации PowerPoint и веб-страницы, разбросанные по разным системам.
Ваш чат-бот должен понимать и искать тысячи документов, чтобы предоставить точные, контекстные ответы. Но необработанные документы не подходят для систем ИИ. Их необходимо преобразовать в формат, сохраняющий смысл при поиске и извлечении.
Это место, где прием данных становится критически важным. Необходимо извлечь текст из разных форматов файлов, разбить большие документы на небольшие блоки, которые соответствуют ограничениям модели ИИ, обогатить содержимое метаданными, создать внедрение для семантического поиска и сохранить все таким образом, чтобы обеспечить быстрое извлечение. Каждый шаг требует тщательного рассмотрения того, как сохранить исходное значение и контекст.
Библиотека Microsoft.Extensions.DataIngestion
Пакет📦 Microsoft.Extensions.DataIngestion предоставляет базовые стандартные блоки .NET для приема данных. Это позволяет разработчикам читать, обрабатывать и подготавливать документы для рабочих процессов искусственного интеллекта и машинного обучения, особенно в сценариях создания с возвратно-усиленной генерацией (RAG).
С помощью этих стандартных блоков можно создавать надежные, гибкие и интеллектуальные конвейеры приема данных, адаптированные для ваших потребностей приложения:
- Единое представление документа: Представляет любой тип файла (например, PDF, image или Microsoft Word) в согласованном формате, который хорошо работает с большими языковыми моделями.
- Гибкая загрузка данных: Чтение документов из облачных служб и локальных источников с использованием нескольких встроенных средств чтения, что упрощает перенос данных из любого источника.
- Встроенные усовершенствования ИИ: Автоматическое обогащение содержимого с помощью сводок, анализа тональности, извлечения ключевых слов и классификации, подготовки данных для интеллектуального рабочего процесса.
- Настраиваемые стратегии разбиения на фрагменты: Разделение документов на фрагменты с использованием подходов, основанных на токенах, разделах или семантике, чтобы оптимизировать извлечение и анализ данных.
- Хранилище, готовое к производству: хранение обработанных фрагментов в популярных векторных базах данных и хранилищах документов с поддержкой генерации эмбеддингов, что делает ваши конвейеры готовыми к реальным сценариям.
- Сквозная композиция конвейера: Связывайте средства чтения, процессоры, разделители и записыватели с APIIngestionPipeline<T>, устраняя шаблонный код и упрощая создание, настройку и расширение полных рабочих процессов.
- Производительность и масштабируемость: Предназначенные для масштабируемой обработки данных эти компоненты могут эффективно обрабатывать большие объемы данных, что делает их подходящими для корпоративных приложений.
Все эти компоненты открыты и расширяемы по дизайну. Вы можете добавить пользовательскую логику и новые соединители, а также расширить систему для поддержки новых сценариев ИИ. Стандартизируя представление, обработку и хранение документов, разработчики .NET могут создавать надежные, масштабируемые и поддерживаемые конвейеры данных, не изобретая велосипед заново для каждого проекта.
Построен на стабильных основаниях
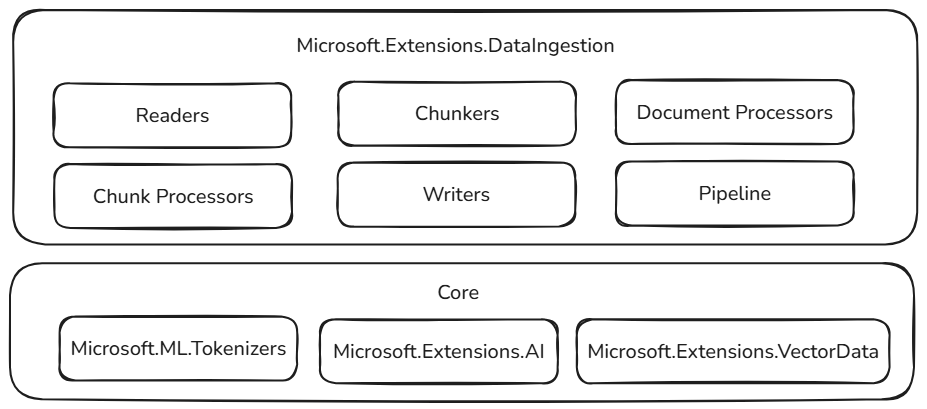
Эти стандартные блоки приема данных основаны на проверенных и расширяемых компонентах экосистемы .NET, обеспечивая надежность, взаимодействие и простую интеграцию с существующими рабочими процессами ИИ:
- Microsoft.ML.Tokenizers: Токенизаторы предоставляют основу для разбиения документов на основе токенов. Это позволяет точно разделить содержимое, важное для подготовки данных для больших языковых моделей и оптимизации стратегий извлечения.
- Microsoft.Extensions.AI: Этот набор библиотек поддерживает процессы обогащения с помощью больших языковых моделей. Он позволяет использовать такие функции, как суммирование, анализ тональности, извлечение ключевых слов и генерация встраиваний, что упрощает обогащение данных с помощью интеллектуальных сведений.
- Microsoft.Extensions.VectorData: Этот набор библиотек предлагает согласованный интерфейс для хранения обработанных блоков в различных векторных хранилищах, включая Qdrant, Azure SQL, CosmosDB, MongoDB, ElasticSearch и многое другое. Это гарантирует, что конвейеры данных готовы к промышленной эксплуатации и могут масштабироваться в разных хранилищах данных.
Помимо знакомых шаблонов и инструментов, эти абстракции создаются на уже расширяемых компонентах. Возможности подключаемых модулей и взаимодействие являются основными, поэтому по мере роста остальной части экосистемы ИИ .NET возможности компонентов приема данных также растут. Этот подход позволяет разработчикам легко встраивать новых поставщиков, обогащения и варианты хранения, сохраняя конвейеры, готовые к будущему и адаптируемые в изменяющихся сценариях ИИ.
Базовые элементы поглощения данных
Библиотека Microsoft.Extensions.DataIngestion основана на нескольких ключевых компонентах, которые работают вместе для создания полного конвейера обработки данных. В этом разделе рассматриваются все компоненты и их соответствие.
Документы и средства чтения документов
В основе библиотеки используется IngestionDocument тип, который предоставляет унифицированный способ представления любого формата файла без потери важных сведений.
IngestionDocument Ориентирован на Markdown, так как большие языковые модели лучше всего работают с форматированием Markdown.
Абстракция IngestionDocumentReader обрабатывает загрузку документов из различных источников, будь то локальные файлы или потоки. Доступны несколько читателей:
В будущем будут добавлены дополнительные читатели (включая LlamaParse и Azure Document Intelligence).
Это означает, что вы можете работать с документами из разных источников с помощью одного и того же единообразного API, что делает код более поддерживаемым и гибким.
Обработка документов
Обработчики документов применяют преобразования на уровне документа для улучшения и подготовки содержимого. Библиотека предоставляет ImageAlternativeTextEnricher класс как встроенный процессор, использующий большие языковые модели для создания описательного альтернативного текста для изображений в документах.
Блоки и стратегии разбиения на блоки
После загрузки документа обычно необходимо разбить его на небольшие части, называемые блоками. Блоки представляют подразделы документа, который может эффективно обрабатываться, храниться и извлекаться системами ИИ. Этот процесс фрагментирования является важным для сценариев создания дополненного с помощью извлечения, где необходимо быстро найти наиболее релевантные фрагменты информации.
Библиотека предоставляет несколько стратегий разбиения на части для соответствия различным вариантам использования.
- Чанкование на основе заголовков для разделения по заголовкам.
- Секционирование на основе разделов для разделения на разделы (например, страницы).
- Семантически-осознанное разбиение на фрагменты для сохранения полных мыслей.
Эти стратегии фрагментирования создаются в библиотеке Microsoft.ML.Tokenizers для интеллектуального разделения текста на соответствующие части, которые хорошо работают с большими языковыми моделями. Правильная стратегия разбиения на части зависит от типов документов и того, как вы планируете извлекать информацию.
Tokenizer tokenizer = TiktokenTokenizer.CreateForModel("gpt-5");
IngestionChunkerOptions options = new(tokenizer)
{
MaxTokensPerChunk = 2000,
OverlapTokens = 0
};
IngestionChunker<string> chunker = new HeaderChunker(options);
Обработка блоков и обогащение
После разделения документов на блоки можно применить процессоры для улучшения и обогащения содержимого. Блок-процессоры работают на отдельных элементах и могут выполнять:
-
Обогащение содержимого, включая автоматические сводки (), анализ тональности (
SummaryEnricherSentimentEnricher) и извлечение ключевых слов (KeywordEnricher). -
Классификация для автоматической классификации контента на основе предопределенных категорий (
ClassificationEnricher).
Эти процессоры используют Microsoft.Extensions.AI.Abstractions чтобы задействовать большие языковые модели для интеллектуального преобразования содержимого, делая ваши блоки более полезными для последующих приложений ИИ.
Программа для создания и хранения документов
IngestionChunkWriter<T> сохраняет обработанные блоки в хранилище данных для последующего извлечения. Библиотека, которая использует Microsoft.Extensions.AI и Microsoft.Extensions.VectorDataпредоставляет VectorStoreWriter<T> класс. Этот модуль записи поддерживает хранение блоков в любом векторном хранилище , поддерживаемом Microsoft.Extensions.VectorData.
Векторные хранилища включают популярные варианты, такие как Qdrant, SQL Server, CosmosDB, MongoDB и ElasticSearch. Для получения дополнительных сведений о поставщиках см. раздел Готовые провайдеры векторного хранилища. (Несмотря на включение "SemanticKernel" в имена пакетов, эти поставщики не имеют ничего общего с семантической ядром и доступны в любом месте в .NET, включая Agent Framework.)
Генератор также может автоматически создавать вектора для ваших блоков с помощью Microsoft.Extensions.AI, готовя их для семантического поиска и сценариев извлечения.
OpenAIClient openAIClient = new(
new ApiKeyCredential(Environment.GetEnvironmentVariable("GITHUB_TOKEN")!),
new OpenAIClientOptions { Endpoint = new Uri("https://models.github.ai/inference") });
IEmbeddingGenerator<string, Embedding<float>> embeddingGenerator =
openAIClient.GetEmbeddingClient("text-embedding-3-small").AsIEmbeddingGenerator();
using SqliteVectorStore vectorStore = new(
"Data Source=vectors.db;Pooling=false",
new()
{
EmbeddingGenerator = embeddingGenerator
});
// The writer requires the embedding dimension count to be specified.
// For OpenAI's `text-embedding-3-small`, the dimension count is 1536.
using VectorStoreWriter<string> writer = new(vectorStore, dimensionCount: 1536);
Конвейер обработки документов
IngestionPipeline<T> API позволяет объединить различные компоненты приема данных в полный рабочий процесс. Вы можете объединить:
- Читатели для загрузки документов из различных источников.
- Процессоры для преобразования и обогащения содержимого документа.
- Блоки для разбиения документов в управляемые части.
- Записывающие модули для сохранения окончательных результатов в выбранное вами хранилище данных.
Этот подход к конвейеру уменьшает стандартный код и упрощает сборку, тестирование и обслуживание сложных рабочих процессов приема данных.
using IngestionPipeline<string> pipeline = new(reader, chunker, writer, loggerFactory: loggerFactory)
{
DocumentProcessors = { imageAlternativeTextEnricher },
ChunkProcessors = { summaryEnricher }
};
await foreach (var result in pipeline.ProcessAsync(new DirectoryInfo("."), searchPattern: "*.md"))
{
Console.WriteLine($"Completed processing '{result.DocumentId}'. Succeeded: '{result.Succeeded}'.");
}
Сбой приема одного документа не должен приводить к сбою всего конвейера. Вот почему IngestionPipeline<T>.ProcessAsync реализует частичный успех, возвращая IAsyncEnumerable<IngestionResult>. Вызывающая сторона отвечает за обработку любых возможных сбоев (например, повторно обрабатывая несостоявшиеся документы или останавливаясь при первой ошибке).
Совместная работа с нами на GitHub
Источник этого содержимого можно найти на GitHub, где также можно создавать и просматривать проблемы и запросы на вытягивание. Дополнительные сведения см. в нашем руководстве для участников.