Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье описывается, как получение дополненного поколения позволяет LLM обрабатывать источники данных как знания без необходимости обучения.
ЛМО имеют обширные базы знаний благодаря обучению. Для большинства сценариев можно выбрать LLM, предназначенный для ваших требований, но эти LLM по-прежнему требуют дополнительного обучения для понимания конкретных данных. Получение дополненного поколения позволяет сделать данные доступными для LLM, не обучая их в первую очередь.
Как работает RAG
Для выполнения генерации с дополнением извлечением вы создаете эмбеддинги для ваших данных вместе с часто задаваемыми о них вопросами. Это можно сделать на лету или создать и сохранить внедрения с помощью решения векторной базы данных.
Когда пользователь задает вопрос, LLM использует внедренные модули для сравнения вопроса пользователя с данными и поиска наиболее релевантного контекста. Этот контекст и вопрос пользователя затем передаются в LLM в виде запроса, и LLM предоставляет ответ на основе ваших данных.
Базовый процесс RAG
Для выполнения RAG необходимо обработать каждый источник данных, который требуется использовать для извлечения. Базовый процесс выглядит следующим образом:
- Разбивайте большие наборы данных на управляемые части.
- Преобразуйте блоки в формат, доступный для поиска.
- Сохраните преобразованные данные в расположении, позволяющем эффективному доступу. Кроме того, важно хранить соответствующие метаданные для цитирования или ссылок, когда LLM предоставляет ответы.
- Подайте преобразованные данные в обучающие языковые модели (LLM) посредством подсказок.
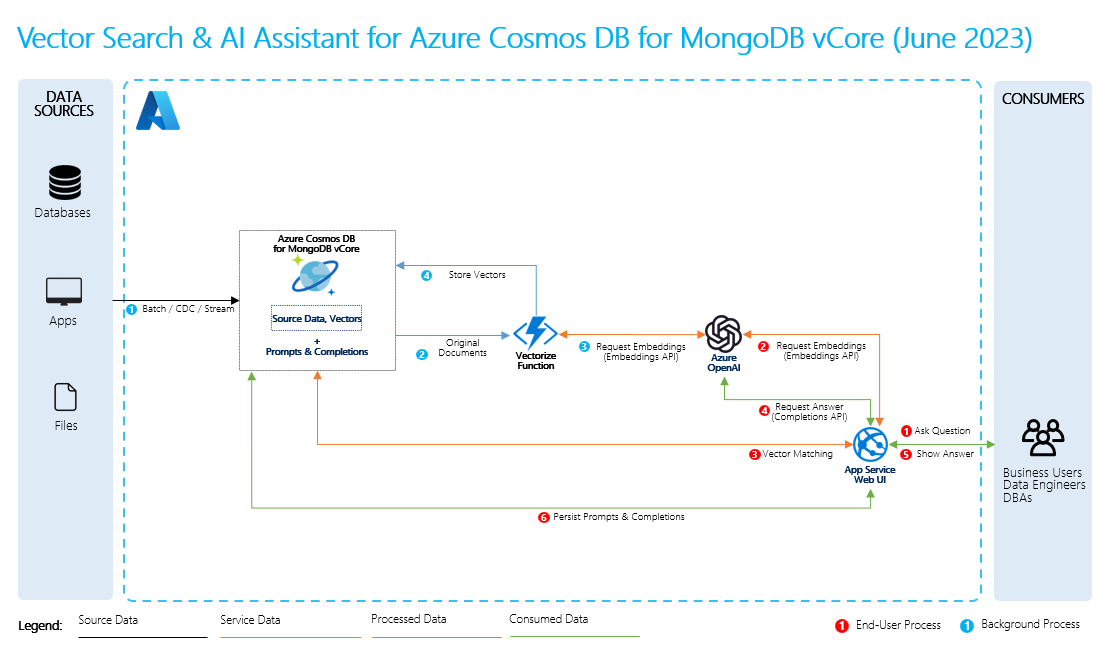
- Исходные данные: это место, где существуют данные. Это может быть файл или папка на вашем компьютере, файл в облачном хранилище, ресурс данных Azure Machine Learning, репозиторий Git или база данных SQL.
- Чанкирование данных: данные из вашего исходного источника необходимо преобразовать в обычный текст. Например, документы word или PDF-файлы должны быть открыты и преобразованы в текст. Затем текст фрагментируется на меньшие части.
- Преобразование текста в векторы: это эмбединги. Векторы — это числовые представления концепций, преобразованные в числовые последовательности. Такое преобразование упрощает понимание компьютером связей между понятиями.
- Связи между исходными данными и встраиваниями: Эта информация хранится в виде метаданных созданных блоков, которые затем используются для генерации ссылок при создании ответов.
См. также
Совместная работа с нами на GitHub
Источник этого содержимого можно найти на GitHub, где также можно создавать и просматривать проблемы и запросы на вытягивание. Дополнительные сведения см. в нашем руководстве для участников.