Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этом руководстве вы создадите приложение MSTest для оценки ответа чата модели OpenAI. Тестовое приложение использует Майкрософт. Extensions.AI.Evaluation библиотеки для выполнения вычислений, кэширования ответов модели и создания отчетов. В этом руководстве используются встроенные и пользовательские оценщики. Встроенные оценщики качества (из пакета Майкрософт.Extensions.AI.Evaluation.Quality) используют LLM для оценки; пользовательский оценщик не использует ИИ.
Предпосылки
- .NET 8 или более поздней версии
- Visual Studio Code (необязательно)
Настройка службы ИИ
Чтобы подготовить службу и модель Azure OpenAI с помощью портала Azure, выполните действия, описанные в статье Создание и развертывание ресурса Служба Azure OpenAI. На шаге "Развернуть модель" выберите модель gpt-5.
Создание тестового приложения
Выполните следующие действия, чтобы создать проект MSTest, который подключается к модели ИИ.
В окне терминала перейдите в каталог, в котором вы хотите создать приложение, и создайте новое приложение MSTest с
dotnet newпомощью команды:dotnet new mstest -o TestAIWithReportingПерейдите в каталог
TestAIWithReportingи добавьте необходимые пакеты в приложение:dotnet add package Azure.AI.OpenAI dotnet add package Azure.Identity dotnet add package Microsoft.Extensions.AI.Abstractions dotnet add package Microsoft.Extensions.AI.Evaluation dotnet add package Microsoft.Extensions.AI.Evaluation.Quality dotnet add package Microsoft.Extensions.AI.Evaluation.Reporting dotnet add package Microsoft.Extensions.AI.OpenAI dotnet add package Microsoft.Extensions.Configuration dotnet add package Microsoft.Extensions.Configuration.UserSecretsВыполните следующие команды, чтобы добавить секреты приложения для конечной точки и идентификатора арендатора Azure OpenAI:
dotnet user-secrets init dotnet user-secrets set AZURE_OPENAI_ENDPOINT <your-Azure-OpenAI-endpoint> dotnet user-secrets set AZURE_TENANT_ID <your-tenant-ID>(В зависимости от среды идентификатор клиента может быть не нужен. В этом случае удалите его из кода, создающего экземпляр DefaultAzureCredential.)
Откройте новое приложение в выбранном редакторе.
Добавление кода тестового приложения
Переименуйте файл Test1.cs на MyTests.cs, затем откройте этот файл и переименуйте класс, указав его имя в
MyTests. Удалите пустойTestMethod1метод.Добавьте необходимые
usingдирективы в начало файла.using Azure.AI.OpenAI; using Azure.Identity; using Microsoft.Extensions.AI.Evaluation; using Microsoft.Extensions.AI; using Microsoft.Extensions.Configuration; using Microsoft.Extensions.AI.Evaluation.Reporting.Storage; using Microsoft.Extensions.AI.Evaluation.Reporting; using Microsoft.Extensions.AI.Evaluation.Quality;TestContext Добавьте свойство в класс.
// The value of the TestContext property is populated by MSTest. public TestContext? TestContext { get; set; }Добавьте метод
GetAzureOpenAIChatConfiguration, который создает IChatClient инструмент, который оценщик использует для взаимодействия с моделью.private static ChatConfiguration GetAzureOpenAIChatConfiguration() { IConfigurationRoot config = new ConfigurationBuilder().AddUserSecrets<MyTests>().Build(); string endpoint = config["AZURE_OPENAI_ENDPOINT"]; string tenantId = config["AZURE_TENANT_ID"]; string model = "gpt-5"; // Get an instance of Microsoft.Extensions.AI's <see cref="IChatClient"/> // interface for the selected LLM endpoint. AzureOpenAIClient azureClient = new( new Uri(endpoint), new DefaultAzureCredential(new DefaultAzureCredentialOptions() { TenantId = tenantId })); IChatClient client = azureClient.GetChatClient(deploymentName: model).AsIChatClient(); // Create an instance of <see cref="ChatConfiguration"/> // to communicate with the LLM. return new ChatConfiguration(client); }Настройте функциональные возможности отчетов.
private string ScenarioName => $"{TestContext!.FullyQualifiedTestClassName}.{TestContext.TestName}"; private static string ExecutionName => $"{DateTime.Now:yyyyMMddTHHmmss}"; private static readonly ReportingConfiguration s_defaultReportingConfiguration = DiskBasedReportingConfiguration.Create( storageRootPath: "C:\\TestReports", evaluators: GetEvaluators(), chatConfiguration: GetAzureOpenAIChatConfiguration(), enableResponseCaching: true, executionName: ExecutionName);Имя сценария
Для имени сценария задано полное имя текущего метода тестирования. Однако при вызове CreateScenarioRunAsync(String, String, IEnumerable<String>, IEnumerable<String>, CancellationToken)его можно задать для любой строки. При выборе имени сценария учитывайте следующие факторы:
- При использовании дискового хранилища имя сценария используется в качестве имени папки, в которой хранятся соответствующие результаты оценки. Поэтому рекомендуется сохранить имя достаточно коротким и избежать символов, которые не разрешены в именах файлов и каталогов.
- По умолчанию созданный отчет об оценке разбивает имена сценариев на
., чтобы результаты отображались в иерархическом представлении с соответствующим группированием, вложением и агрегированием. Иерархическое представление особенно полезно, если имя сценария является полным именем соответствующего метода теста, так как оно группирует результаты по пространствам имен и именам классов в иерархии. Однако вы также можете воспользоваться этой функцией, включив периоды (.) в собственные пользовательские имена сценариев, чтобы создать иерархию отчетов, которая лучше всего подходит для ваших сценариев.
Имя выполнения
Название выполнения используется для группировки результатов оценки, которые являются частью одного и того же цикла оценки (или тестового выполнения) при хранении результатов оценки. Если при создании ReportingConfiguration не указать имя выполнения, все оценочные запуски используют одно и то же имя выполнения по умолчанию как
Default. В этом случае результаты одного запуска перезаписываются следующим, и вы утрачиваете возможность сравнивать результаты между разными запусками.В этом примере в качестве имени выполнения используется метка времени. Если в проекте есть несколько тестов, убедитесь, что результаты группируются правильно с помощью одного имени выполнения во всех конфигурациях отчетов, используемых в тестах.
В более прикладном сценарии может потребоваться использовать одно и то же имя выполнения в тестах для оценки, которые находятся в нескольких сборках и выполняются в различных процессах тестирования. В таких случаях можно использовать скрипт для обновления переменной среды с соответствующим именем выполнения (например, текущим номером сборки, назначенным системой CI/CD) перед выполнением тестов. Или, если система сборки создает монотонно увеличивающиеся версии файлов сборки модулей, вы можете прочитать AssemblyFileVersionAttribute в тестовом коде и использовать это в качестве имени для выполнения для сравнения результатов в разных версиях продукта.
Конфигурация отчетов
Элемент ReportingConfiguration идентифицирует:
- Набор вычислителей, которые должны вызываться для каждого ScenarioRun, создаваемого путем вызова CreateScenarioRunAsync(String, String, IEnumerable<String>, IEnumerable<String>, CancellationToken).
- Конечная точка LLM, которую должны использовать оценщики (см. ReportingConfiguration.ChatConfiguration).
- Как и где должны храниться результаты для выполнения сценария.
- Как следует кэшировать ответы LLM, связанные с выполнением сценария.
- Имя запуска, которое следует использовать при отчетности о результатах выполнения сценария.
В этом тесте используется дисковая конфигурация отчетов.
В отдельном файле добавьте
WordCountEvaluatorкласс, который является пользовательским оценщиком, реализующим IEvaluator.using System.Text.RegularExpressions; using Microsoft.Extensions.AI; using Microsoft.Extensions.AI.Evaluation; namespace TestAIWithReporting; public class WordCountEvaluator : IEvaluator { public const string WordCountMetricName = "Words"; public IReadOnlyCollection<string> EvaluationMetricNames => [WordCountMetricName]; /// <summary> /// Counts the number of words in the supplied string. /// </summary> private static int CountWords(string? input) { if (string.IsNullOrWhiteSpace(input)) { return 0; } MatchCollection matches = Regex.Matches(input, @"\b\w+\b"); return matches.Count; } /// <summary> /// Provides a default interpretation for the supplied <paramref name="metric"/>. /// </summary> private static void Interpret(NumericMetric metric) { if (metric.Value is null) { metric.Interpretation = new EvaluationMetricInterpretation( EvaluationRating.Unknown, failed: true, reason: "Failed to calculate word count for the response."); } else { if (metric.Value <= 100 && metric.Value > 5) metric.Interpretation = new EvaluationMetricInterpretation( EvaluationRating.Good, reason: "The response was between 6 and 100 words."); else metric.Interpretation = new EvaluationMetricInterpretation( EvaluationRating.Unacceptable, failed: true, reason: "The response was either too short or greater than 100 words."); } } public ValueTask<EvaluationResult> EvaluateAsync( IEnumerable<ChatMessage> messages, ChatResponse modelResponse, ChatConfiguration? chatConfiguration = null, IEnumerable<EvaluationContext>? additionalContext = null, CancellationToken cancellationToken = default) { // Count the number of words in the supplied <see cref="modelResponse"/>. int wordCount = CountWords(modelResponse.Text); string reason = $"This {WordCountMetricName} metric has a value of {wordCount} because " + $"the evaluated model response contained {wordCount} words."; // Create a <see cref="NumericMetric"/> with value set to the word count. // Include a reason that explains the score. var metric = new NumericMetric(WordCountMetricName, value: wordCount, reason); // Attach a default <see cref="EvaluationMetricInterpretation"/> for the metric. Interpret(metric); return new ValueTask<EvaluationResult>(new EvaluationResult(metric)); } }WordCountEvaluatorпроизводит подсчет количества слов, присутствующих в ответе. В отличие от некоторых оценщиков, он не основан на ИИ. МетодEvaluateAsyncвозвращает объект EvaluationResult, содержащий NumericMetric, который включает количество слов.Метод
EvaluateAsyncтакже присоединяет интерпретацию по умолчанию к метрике. Интерпретация по умолчанию считает метрику хорошей (приемлемой), если обнаруженное число слов составляет от 6 до 100. В противном случае метрика считается неудачной. Вызывающая сторона может переопределить эту трактовку по умолчанию при необходимости.Назад в
MyTests.cs, добавьте метод для сбора оценщиков для использования в оценке.private static IEnumerable<IEvaluator> GetEvaluators() { IEvaluator relevanceEvaluator = new RelevanceEvaluator(); IEvaluator coherenceEvaluator = new CoherenceEvaluator(); IEvaluator wordCountEvaluator = new WordCountEvaluator(); return [relevanceEvaluator, coherenceEvaluator, wordCountEvaluator]; }Добавьте метод для добавления системного запроса ChatMessage, определите параметры чата и попросите модель ответить на заданный вопрос.
private static async Task<(IList<ChatMessage> Messages, ChatResponse ModelResponse)> GetAstronomyConversationAsync( IChatClient chatClient, string astronomyQuestion) { const string SystemPrompt = """ You're an AI assistant that can answer questions related to astronomy. Keep your responses concise and under 100 words. Use the imperial measurement system for all measurements in your response. """; IList<ChatMessage> messages = [ new ChatMessage(ChatRole.System, SystemPrompt), new ChatMessage(ChatRole.User, astronomyQuestion) ]; var chatOptions = new ChatOptions { Temperature = 0.0f, ResponseFormat = ChatResponseFormat.Text }; ChatResponse response = await chatClient.GetResponseAsync(messages, chatOptions); return (messages, response); }Тест в этом уроке оценивает ответ LLM на астрономический вопрос. Так как кэширование ReportingConfiguration ответов включено, и так как предоставленный IChatClient объект всегда извлекается из созданной ScenarioRun конфигурации отчетов, ответ LLM для теста кэшируется и повторно используется. Ответ повторно используется до истечения срока действия соответствующей записи кэша (по умолчанию через 14 дней) или до тех пор, пока не изменится любой из параметров запроса, например, конечная точка LLM или задаваемый вопрос.
Добавьте метод для проверки ответа.
/// <summary> /// Runs basic validation on the supplied <see cref="EvaluationResult"/>. /// </summary> private static void Validate(EvaluationResult result) { // Retrieve the score for relevance from the <see cref="EvaluationResult"/>. NumericMetric relevance = result.Get<NumericMetric>(RelevanceEvaluator.RelevanceMetricName); Assert.IsFalse(relevance.Interpretation!.Failed, relevance.Reason); Assert.IsTrue(relevance.Interpretation.Rating is EvaluationRating.Good or EvaluationRating.Exceptional); // Retrieve the score for coherence from the <see cref="EvaluationResult"/>. NumericMetric coherence = result.Get<NumericMetric>(CoherenceEvaluator.CoherenceMetricName); Assert.IsFalse(coherence.Interpretation!.Failed, coherence.Reason); Assert.IsTrue(coherence.Interpretation.Rating is EvaluationRating.Good or EvaluationRating.Exceptional); // Retrieve the word count from the <see cref="EvaluationResult"/>. NumericMetric wordCount = result.Get<NumericMetric>(WordCountEvaluator.WordCountMetricName); Assert.IsFalse(wordCount.Interpretation!.Failed, wordCount.Reason); Assert.IsTrue(wordCount.Interpretation.Rating is EvaluationRating.Good or EvaluationRating.Exceptional); Assert.IsFalse(wordCount.ContainsDiagnostics()); Assert.IsTrue(wordCount.Value > 5 && wordCount.Value <= 100); }Подсказка
Метрики включают
Reasonсвойство, объясняющее причину оценки. Причина включена в созданный отчет и может просматриваться, щелкнув значок сведений на карточке соответствующей метрики.Наконец, добавьте сам метод теста .
[TestMethod] public async Task SampleAndEvaluateResponse() { // Create a <see cref="ScenarioRun"/> with the scenario name // set to the fully qualified name of the current test method. await using ScenarioRun scenarioRun = await s_defaultReportingConfiguration.CreateScenarioRunAsync( ScenarioName, additionalTags: ["Moon"]); // Use the <see cref="IChatClient"/> that's included in the // <see cref="ScenarioRun.ChatConfiguration"/> to get the LLM response. (IList<ChatMessage> messages, ChatResponse modelResponse) = await GetAstronomyConversationAsync( chatClient: scenarioRun.ChatConfiguration!.ChatClient, astronomyQuestion: "How far is the Moon from the Earth at its closest and furthest points?"); // Run the evaluators configured in <see cref="s_defaultReportingConfiguration"/> against the response. EvaluationResult result = await scenarioRun.EvaluateAsync(messages, modelResponse); // Run some basic validation on the evaluation result. Validate(result); }Этот метод теста:
ScenarioRunСоздает объект .
await usingобеспечивает правильное удалениеScenarioRunи правильное сохранение результатов оценки в хранилище результатов.Получает ответ LLM на конкретный астрономический вопрос. Тест передает тот же IChatClient, что применяется для оценки
GetAstronomyConversationAsyncметода, чтобы получить кэширование ответа для оценки основного ответа LLM. (Передача одного и того же клиента также позволяет кэшировать ответы для LLM обращений, которые оценщики используют для выполнения своих оценок. При кэшировании ответов ответ LLM извлекается следующим образом:)- Непосредственно из конечной точки LLM в первом запуске текущего теста или в последующих запусках, если кэшируемая запись истекла (14 дней по умолчанию).
- Кэш ответов на основе диска, настроенный в
s_defaultReportingConfiguration, используется в последующих запусках теста.
Запускает оценщики по отношению к ответу. Как и в ответе LLM, последующие запуски извлекают оценку из кэша ответов, использующего дисковый накопитель, настроенного в
s_defaultReportingConfiguration.Выполняет некоторую базовую проверку результатов оценки.
Этот шаг является необязательным и главным образом для демонстрационных целей. В реальных оценках может не потребоваться проверить отдельные результаты, так как ответы LLM и оценки могут меняться с течением времени по мере развития продукта (и используемых моделей). Вы можете не захотеть, чтобы отдельные тесты оценки «проваливались» и блокировали сборки в ваших конвейерах CI/CD при изменении результатов. Вместо этого лучше полагаться на созданный отчет и отслеживать общие тенденции оценочных показателей в разных сценариях с течением времени (и только при сбое отдельных сборок, когда происходит значительное падение оценочных баллов в нескольких различных тестах). То есть есть некоторые нюансы здесь и выбор того, следует ли проверять отдельные результаты или не может отличаться в зависимости от конкретного варианта использования.
При возврате метода объект
scenarioRunосвобождается, а результат оценки сохраняется в хранилище результатов на диске, настроенное вs_defaultReportingConfiguration.
Запуск теста или оценки
Запустите тест с помощью предпочтительного рабочего процесса тестирования, например с помощью команды dotnet test CLI или обозревателя тестов.
Создание отчета
Установите инструмент .NET Майкрософт.Extensions.AI.Evaluation.Console, выполнив следующую команду в окне терминала:
dotnet tool install --create-manifest-if-needed Microsoft.Extensions.AI.Evaluation.ConsoleСоздайте отчет, выполнив следующую команду:
dotnet tool run aieval report --path <path\to\your\cache\storage> --output report.htmlОткройте файл
report.html. Отчет выглядит примерно так, как показано на следующем снимок экрана.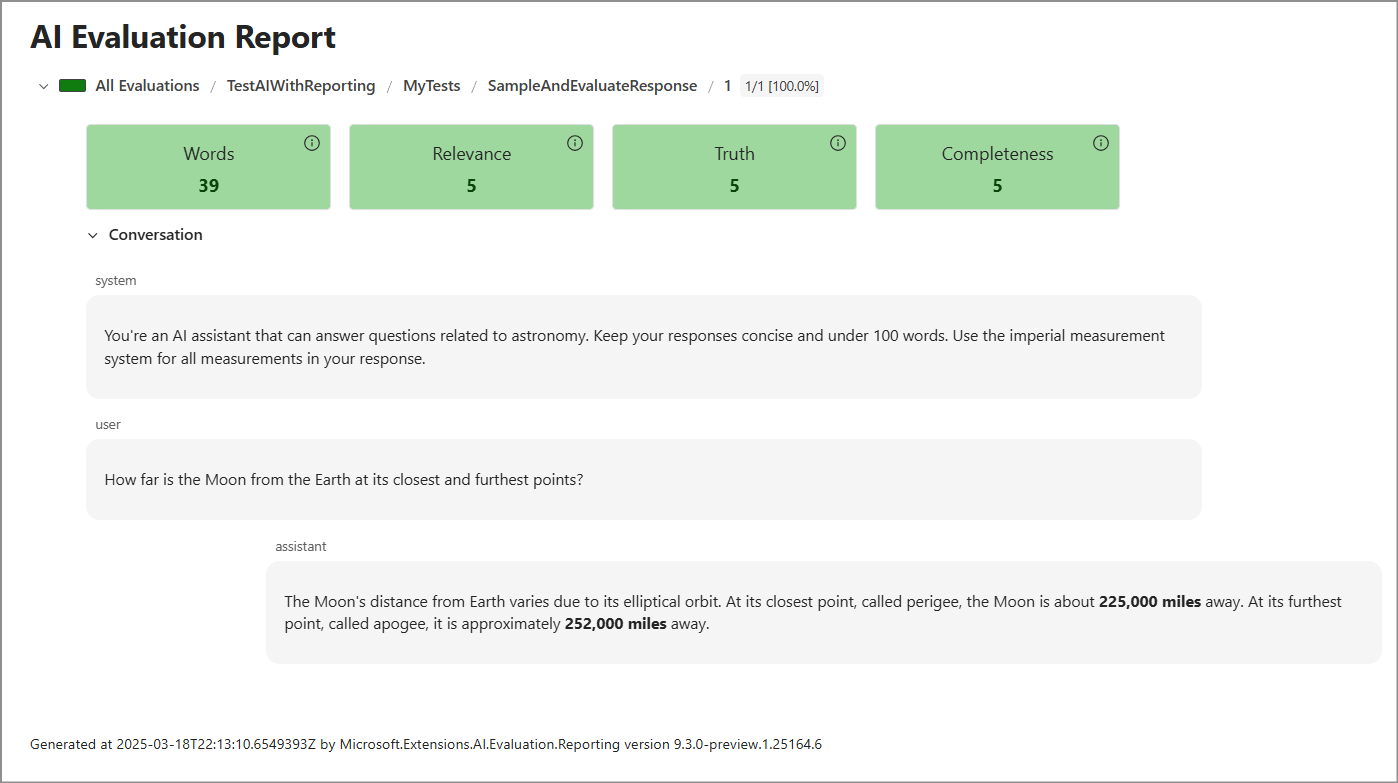
Дальнейшие шаги
- Перейдите в каталог, в котором хранятся результаты теста (то есть
C:\TestReports, если вы не изменили расположение при создании ReportingConfiguration).resultsОбратите внимание, что в подкаталоге есть папка для каждого тестового запуска с меткой времени (ExecutionName). В каждой из этих папок используется папка для каждого имени сценария. В этом случае используется только один метод теста в проекте. Эта папка содержит JSON-файл со всеми данными, включая сообщения, ответ и результат оценки. - Расширьте оценку. Вот несколько идей:
- Добавьте другой пользовательский оценщик, например оценщик, использующий искусственный интеллект для определения системы измерения, используемой в ответе.
- Добавьте другой метод теста, например метод, который оценивает несколько ответов из LLM. Так как каждый ответ может быть разным, хорошо провести выборку и оценить по крайней мере несколько ответов на вопрос. В этом случае вы указываете имя итерации при каждом вызове CreateScenarioRunAsync(String, String, IEnumerable<String>, IEnumerable<String>, CancellationToken).
Совместная работа с нами на GitHub
Источник этого содержимого можно найти на GitHub, где также можно создавать и просматривать проблемы и запросы на вытягивание. Дополнительные сведения см. в нашем руководстве для участников.