Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Подсказка
Это фрагмент из электронной книги «Архитектура облачных нативных приложений .NET для Azure», доступен на .NET Docs или как бесплатный загружаемый PDF-файл, который можно прочитать в автономном режиме.

Подобно тому, как были разработаны шаблоны, чтобы помочь в структуре кода приложений, существуют шаблоны для надежной эксплуатации приложений. Появились три полезных шаблона в обслуживании приложений: ведение журнала, мониторинг и оповещения.
Когда следует использовать логирование
Независимо от того, насколько внимательно мы разрабатываем приложения, в производственной среде они почти всегда ведут себя непредсказуемо. Когда пользователи сообщают о проблемах с приложением, полезно видеть, что происходит с приложением при возникновении проблемы. Одним из самых проверенных и надежных способов получения сведений о том, что делает приложение во время своей работы, является то, что приложение записывает свои действия. Этот процесс называется ведением журнала. В любое время ошибки или проблемы возникают в рабочей среде, необходимо воспроизвести условия, в которых произошли сбои, в нерабокой среде. Наличие хорошего ведения логов позволяет разработчикам следовать плану для воспроизведения проблем в среде, которую можно протестировать и исследовать.
Проблемы при ведении журнала с помощью облачных приложений
В традиционных приложениях файлы журналов обычно хранятся на локальном компьютере. На самом деле в операционных системах, таких как Unix, существует структура папок, определенная для хранения журналов, как правило, под /var/log.
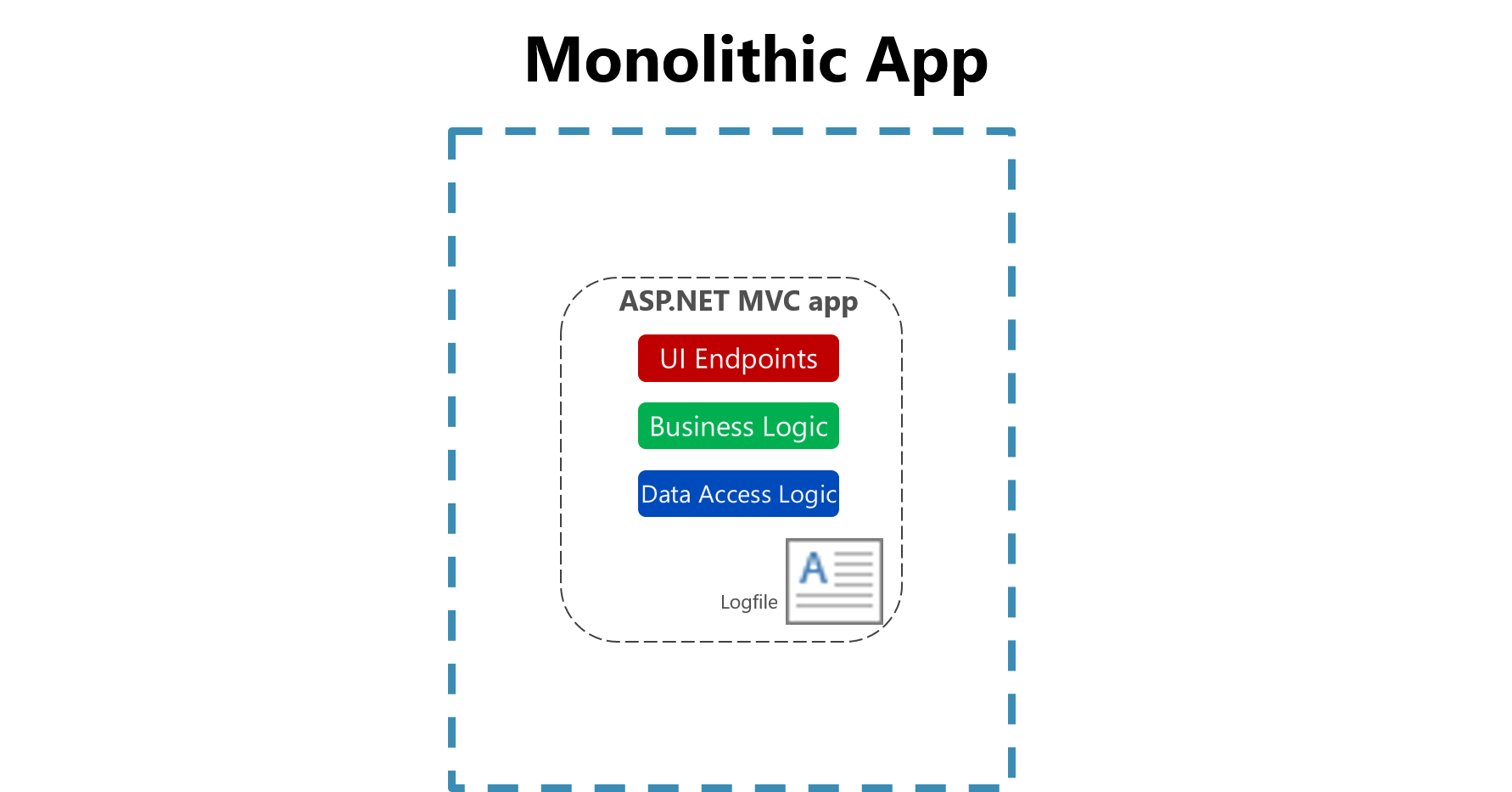 Рис. 7-1. Логирование в файл в монолитном приложении.
Рис. 7-1. Логирование в файл в монолитном приложении.
Полезность ведения журнала в плоский файл на одном компьютере значительно сокращается в облачной среде. Приложения, создающие журналы, могут не иметь доступа к локальному диску или локальный диск может быть очень нестабильным, так как контейнеры перемещаются между физическими машинами. Даже простое масштабирование монолитных приложений на нескольких узлах может затруднить поиск соответствующего журнала, хранящегося в виде файлов.
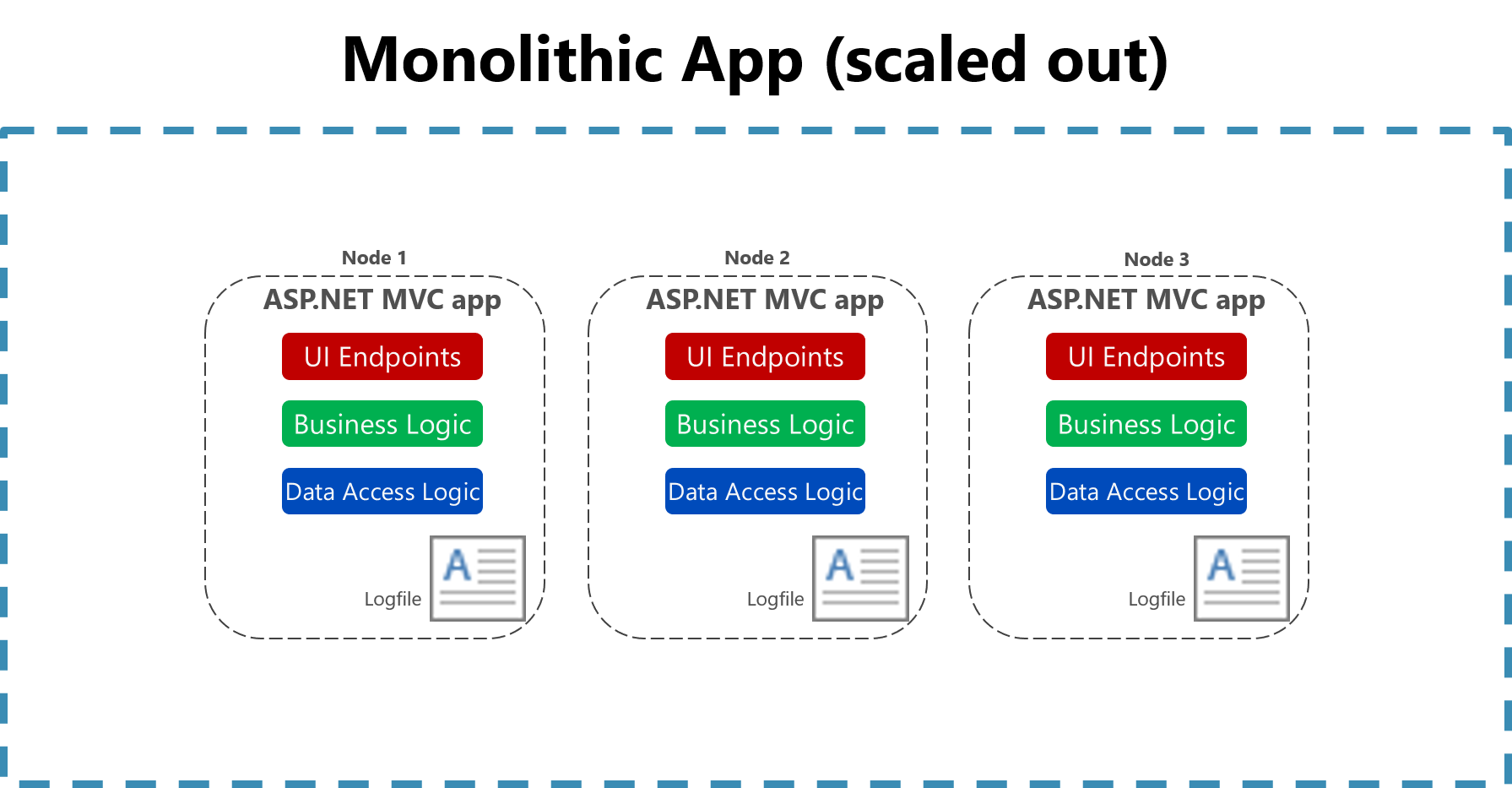 Рис. 7-2. Логирование в файлах в масштабируемом монолитном приложении.
Рис. 7-2. Логирование в файлах в масштабируемом монолитном приложении.
Облачные приложения, разработанные с помощью архитектуры микрослужб, также представляют некоторые проблемы для файловых средств ведения журнала. Теперь запросы пользователей могут охватывать несколько служб, выполняемых на разных компьютерах, и могут включать бессерверные функции без доступа к локальной файловой системе. Было бы очень сложно сопоставить журналы от пользователя или сеанса между этими многими службами и компьютерами.
 Рис. 7-3. Запись информации в локальные файлы в приложении с микросервисами.
Рис. 7-3. Запись информации в локальные файлы в приложении с микросервисами.
Наконец, число пользователей в некоторых облачных приложениях является высоким. Представьте, что каждый пользователь создает сотни строк сообщений журнала при входе в приложение. В отдельности это управляемо, но если умножить это на 100 000 пользователей, объем журналов становится настолько большим, что требуются специализированные инструменты для поддержки их эффективного использования.
Ведение журнала в облачных приложениях
Каждый язык программирования имеет средства, которые позволяют писать журналы, и, как правило, затраты на запись этих журналов низки. Многие библиотеки журналирования обеспечивают регистрацию различных типов критичности, которые можно настроить во время выполнения. Например, библиотека Serilog — это популярная структурированная библиотека ведения журнала для .NET, которая предоставляет следующие уровни ведения журнала:
- Многословный
- Отладка
- Информация
- Предупреждение
- Ошибка
- Смертельно
Эти различные уровни журнала обеспечивают детализацию журналирования. Если приложение работает правильно в рабочей среде, оно может быть настроено только для записи важных сообщений. Когда приложение работает неправильно, уровень ведения журнала может быть увеличен, чтобы собирать более подробные журналы. Это балансирует производительность с легкостью отладки.
Высокая производительность средств ведения журналов и регулируемая детализация должны поощрять разработчиков часто вести журналирование. Многие предпочитают шаблон ведения журнала входа и выхода каждого метода. Такой подход может показаться чрезмерным, но редко бывает, что разработчики хотят уменьшить количество ведения журнала. На самом деле, часто развертывания выполняются исключительно для того, чтобы добавить логирование вокруг проблемного метода. Ошибайтесь скорее в сторону избыточного ведения логов, чем недостаточного. Некоторые средства можно использовать для автоматического предоставления такого логирования.
Из-за проблем, связанных с использованием журналов на основе файлов в облачных приложениях, централизованные журналы предпочтительнее. Журналы собираются приложениями и отправляются в центральное приложение ведения журнала, которое индексирует и сохраняет журналы. Этот тип системы может ежедневно обрабатывать десятки гигабайт журналов.
Также полезно следовать некоторым стандартным практикам при создании логирования, затрагивающего множество служб. Например, создание идентификатора корреляции в начале длительного взаимодействия, а затем ведение журнала в каждом сообщении, связанном с этим взаимодействием, упрощает поиск всех связанных сообщений. Для поиска всех связанных сообщений необходимо найти только одно сообщение и извлечь идентификатор корреляции. Другой пример заключается в том, чтобы формат журнала был одинаковым для каждой службы, независимо от языка или библиотеки ведения журнала, которую он использует. Эта стандартизация упрощает чтение журналов. На рисунке 7-4 показано, как архитектура микрослужб может использовать централизованное ведение журнала в рамках рабочего процесса.
 Рис. 7-4. Журналы из различных источников собираются в централизованное хранилище логов.
Рис. 7-4. Журналы из различных источников собираются в централизованное хранилище логов.
Проблемы с обнаружением и реагированием на потенциальные проблемы работоспособности приложений
Некоторые приложения не являются критически важными. Может быть, они используются только во внутреннем режиме, и когда возникает проблема, пользователь может связаться с группой, ответственной и приложение можно перезапустить. Однако клиенты часто имеют более высокие ожидания для приложений, которые они используют. Вы должны знать о проблемах с приложением до того, как пользователи столкнутся с ними или уведомят вас. В противном случае первая информация, которую вы получите о проблеме, может появиться, когда вы заметите сердитый поток сообщений в социальных сетях, высмеивающих ваше приложение или даже вашу организацию.
Некоторые сценарии, которые могут потребоваться для рассмотрения:
- Одна служба в вашем приложении постоянно выходит из строя и перезапускается, что приводит к периодическим задержкам в откликах.
- В некоторые периоды дня время отклика приложения медленно.
- После недавнего развертывания загрузка базы данных в три раза больше.
При правильной реализации мониторинг может сообщить вам о условиях, которые могут привести к проблемам, позволяя устранять первопричины, прежде чем они приводят к каким-либо значительным последствиям для пользователей.
Мониторинг облачных приложений
Некоторые централизованные системы ведения журнала принимают на себя дополнительную роль сбора данных телеметрии за пределами чистых журналов. Они могут собирать метрики, такие как время выполнения запроса базы данных, среднее время отклика с веб-сервера, а также даже среднее время загрузки ЦП и давление на память, как сообщает операционная система. В сочетании с журналами эти системы могут обеспечить целостное представление о работоспособности узлов в системе и приложении в целом.
Возможности сбора метрик для средств мониторинга также можно загружать вручную из приложения. Бизнес-потоки, представляющие особый интерес, такие как регистрация новых пользователей или размещение заказов, могут быть инструментированы таким образом, чтобы они добавили счетчик в централизованной системе мониторинга. Этот аспект разблокирует средства мониторинга, чтобы не только отслеживать работоспособность приложения, но и работоспособность бизнеса.
Запросы можно создать в средствах агрегирования журналов для поиска определенных статистических данных или шаблонов, которые затем можно отобразить в графической форме на пользовательских панелях мониторинга. Часто команды инвестируют в большие настенные экраны, на которых отображаются различные статистические данные, связанные с приложением. Таким образом, легко заметить проблемы по мере их возникновения.
Средства мониторинга на основе облака предоставляют данные телеметрии в режиме реального времени и аналитические сведения о приложениях независимо от того, является ли они монолитными приложениями или распределенными архитектурами микрослужб. К ним относятся средства, позволяющие собирать данные из приложения, а также средства для запроса и отображения сведений о работоспособности приложения.
Проблемы с реагированием на критические проблемы в облачных приложениях
Если вам нужно реагировать на проблемы с приложением, вам потребуется способ оповестить соответствующий персонал. Это третий шаблон наблюдаемости приложений в облаке и зависит от ведения журнала и мониторинга. Приложение должно иметь ведение журнала, чтобы разрешить диагностику проблем и в некоторых случаях передавать данные в средства мониторинга. Для мониторинга требуется объединять метрики приложений и данные о состоянии в одном месте. После установки этого правила можно создать, которые будут запускать оповещения, когда определенные метрики выходят за пределы допустимых уровней.
Оповещения обычно добавляются к системе мониторинга таким образом, чтобы определенные условия активировали соответствующие оповещения и уведомляли членов команды о срочных проблемах. Некоторые сценарии, которые могут требовать оповещений, включают:
- Одна из служб приложения не отвечает через 1 минуту простоя.
- Ваше приложение возвращает ошибочные HTTP-ответы для более чем 1% запросов.
- Среднее время отклика приложения для ключевых конечных точек превышает 2000 мс.
Оповещения в облачных приложениях
Вы можете создавать запросы к средствам мониторинга для поиска известных условий сбоя. Например, запросы могут выполнять поиск по входящим журналам для указания кода состояния HTTP 500, который указывает на проблему на веб-сервере. Как только обнаружено одно из них, то может быть отправлено сообщение электронной почты или SMS владельцу исходной службы, которая может начать расследование.
Как правило, одна ошибка 500 недостаточна, чтобы точно установить, что возникла проблема. Это может означать, что пользователь неправильно ввел пароль или ввел некоторые неправильные данные. Запросы на оповещение можно создавать таким образом, чтобы они срабатывали только при обнаружении большего, чем в среднем, количества ошибок 500.
Одним из самых разрушительных шаблонов в оповещении является срабатывание слишком большого количества оповещений для изучения людьми. Владельцы служб быстро десенсизируются до ошибок, которые ранее расследовали и обнаружили, что они были доброкачественными. Затем, когда происходят настоящие ошибки, они будут потеряны в шуме от сотен ложных срабатываний. Притча о мальчике, который кричал "Волк!” часто рассказывается детям, чтобы предупредить их об этой самой опасности. Важно убедиться, что сработавшие оповещения свидетельствуют о реальной проблеме.
Совместная работа с нами на GitHub
Источник этого содержимого можно найти на GitHub, где также можно создавать и просматривать проблемы и запросы на вытягивание. Дополнительные сведения см. в нашем руководстве для участников.