Заметка
Доступ к этой странице требует авторизации. Вы можете попробовать войти в систему или изменить каталог.
Доступ к этой странице требует авторизации. Вы можете попробовать сменить директорию.
Подсказка
Это фрагмент из электронной книги «Архитектура микрослужб .NET для контейнеризованных приложений .NET», доступной в документации .NET или в виде бесплатного скачиваемого PDF-файла, который можно прочитать в автономном режиме.

Задача #1. Определение границ каждой микрослужбы
Определение границ микрослужб, вероятно, является первой проблемой, с которой сталкиваются все. Каждая микрослужба должна быть частью приложения, и каждая микрослужба должна быть автономной со всеми преимуществами и проблемами, которые она передает. Но как определить эти границы?
Во-первых, необходимо сосредоточиться на моделях логического домена приложения и связанных данных. Попробуйте определить разделенные острова данных и разные контексты в одном приложении. Каждый контекст может иметь другой бизнес-язык (разные бизнес-термины). Контексты должны определяться и управляться независимо. Термины и сущности, используемые в этих разных контекстах, могут звучать аналогично, но вы можете обнаружить, что в определенном контексте бизнес-концепция с одной используется для другой цели в другом контексте и может даже иметь другое имя. Например, пользователь может быть обозначен как пользователь в контексте идентификации или членства, как клиент в контексте CRM, как покупатель в контексте заказа и т. д.
Способ определения границ между несколькими контекстами приложений с разным доменом для каждого контекста заключается в том, как определить границы для каждой бизнес-микрослужбы и связанной с ней модели домена и данных. Вы всегда пытаетесь свести к минимуму связь между этими микрослужбами. В этом руководстве подробно описано, как определить границы модели домена для каждой микрослужбы позже.
Задача 2. Создание запросов, извлекающих данные из нескольких микрослужб
Вторая проблема заключается в том, как реализовать запросы, которые извлекают данные из нескольких микрослужб, избегая чата связи с микрослужбами из удаленных клиентских приложений. Примером может быть один экран из мобильного приложения, которое должно отображать сведения о пользователях, принадлежащих корзине, каталогу и микрослужбам удостоверений пользователя. Другим примером будет сложный отчет, включающий множество таблиц, расположенных в нескольких микрослужбах. Правильное решение зависит от сложности запросов. Но в любом случае вам потребуется способ агрегирования информации, если вы хотите повысить эффективность взаимодействия системы. Ниже приведены наиболее популярные решения.
Шлюз API. Для простой агрегации данных из нескольких микрослужб, принадлежащих разным базам данных, рекомендуемый подход — это агрегатная микрослужба, называемая шлюзом API. Тем не менее, необходимо быть осторожным при реализации этого шаблона, так как это может быть узким местом в вашей системе, и это может нарушить принцип автономности микросервисов. Чтобы снизить риск, вы можете иметь несколько детализированных шлюзов API, каждый из которых ориентирован на вертикальную область или бизнес-область системы. Более подробно описан шаблон шлюза API в разделе шлюза API позже.
Федерация GraphQL Один из вариантов рассмотреть, если микрослужбы уже используют GraphQL , это Федерация GraphQL. Федерация позволяет определять "подграфы" из других служб и объединять их в агрегатный "суперграф", который действует как автономная схема.
CQRS с таблицами запросов и чтения. Другим решением для агрегирования данных из нескольких микрослужб является шаблон "Материализованное представление". В этом подходе необходимо заранее создать (подготовить денормализованные данные до выполнения фактических запросов) таблицу только для чтения с данными, принадлежащими нескольким микрослужбам. Таблица имеет формат, подходящий для потребностей клиентского приложения.
Рассмотрим что-то, подобное экрану для мобильного приложения. Если у вас есть одна база данных, вы можете объединить данные для этого экрана с помощью SQL-запроса, выполняющего сложное соединение с несколькими таблицами. Однако при наличии нескольких баз данных, и каждая база данных принадлежит другой микрослужбе, вы не можете запросить эти базы данных и создать соединение SQL. Сложный запрос становится проблемой. Вы можете устранить требование с помощью подхода CQRS— создать денормализованную таблицу в другой базе данных, которая используется только для запросов. Таблица может быть разработана специально для данных, необходимых для сложного запроса, с связью "один к одному" между полями, необходимыми для экрана приложения и столбцов в таблице запросов. Он также может служить в целях отчетности.
Этот подход не только решает исходную проблему (как запрашивать и присоединяться к микрослужбам), но и значительно повышает производительность по сравнению с сложным соединением, так как у вас уже есть данные, необходимые приложению в таблице запросов. Конечно, использование разделения ответственности за команды и запросы (CQRS) с таблицами запросов/чтения означает дополнительную работу по разработке, и вам потребуется принять постепенную согласованность. Тем не менее, требования к производительности и высокой масштабируемости в сценариях совместной работы (или конкурентных сценариях в зависимости от точки зрения) должны применяться CQRS с несколькими базами данных.
"Холодные данные" в центральных базах данных. Для сложных отчетов и запросов, которые могут не требовать данных в режиме реального времени, распространенный подход заключается в экспорте "горячих данных" (транзакционные данные из микрослужб) в виде "холодных данных" в большие базы данных, которые используются только для создания отчетов. Эта центральная система базы данных может быть системой на основе больших данных, например Hadoop; хранилище данных, например хранилище данных, основанное на хранилище данных SQL Azure; или даже отдельная база данных SQL, используемая только для отчетов (если размер не будет проблемой).
Помните, что эта централизованная база данных будет использоваться только для запросов и отчетов, которые не нуждаются в данных в режиме реального времени. Исходные обновления и транзакции, как источник истины, должны находиться в данных микрослужб. Способ синхронизации данных может быть либо с помощью взаимодействия на основе событий (описанных в следующих разделах), либо с помощью других средств импорта и экспорта инфраструктуры баз данных. Если вы используете взаимодействие на основе событий, процесс интеграции будет аналогичен тому, как вы распространяете данные, как описано ранее для таблиц запросов CQRS.
Однако если проект приложения агрегирует информацию из нескольких микрослужб для сложных запросов, это может быть признаком неудачного проектирования, -a микрослужбы должны быть максимально изолированы друг от друга. (Это исключает отчеты и аналитику, которые всегда должны использовать центральные базы данных с холодными данными.) Эта проблема часто может быть причиной слияния микрослужб. Необходимо сбалансировать автономию эволюции и развертывания каждой микрослужбы с сильными зависимостями, сплоченностью и агрегированием данных.
Задача 3. Как добиться согласованности между несколькими микрослужбами
Как упоминалось ранее, данные, принадлежащие каждой микрослужбе, являются частными для этой микрослужбы и могут быть доступны только с помощью API микрослужбы. Таким образом, представлена проблема в том, как реализовать комплексные бизнес-процессы, сохраняя согласованность между несколькими микрослужбами.
Чтобы проанализировать эту проблему, давайте рассмотрим пример из эталонного приложения eShopOnContainers. Микрослужба каталога сохраняет сведения обо всех продуктах, включая цену на продукт. Микрослужба корзины управляет темпоральными данными о продуктах, которые пользователи добавляют в свои корзины покупок, которая включает в себя цену элементов в момент их добавления в корзину. Когда цена продукта обновляется в каталоге, эта цена также должна быть обновлена в активных корзинах, которые содержат тот же продукт, а также система, вероятно, должна предупредить пользователя о том, что цена конкретного элемента изменилась, так как они добавили его в свою корзину.
В гипотетической монолитной версии этого приложения, когда цена изменяется в таблице продуктов, подсистема каталога может просто использовать транзакцию ACID для обновления текущей цены в таблице Корзины.
Однако в приложении на основе микрослужб таблицы Product и Basket принадлежат соответствующим микрослужбам. Ни одна микрослужба никогда не должна включать таблицы или хранилище, принадлежащие другой микрослужбе в своих собственных транзакциях, даже не в прямых запросах, как показано на рис. 4-9.
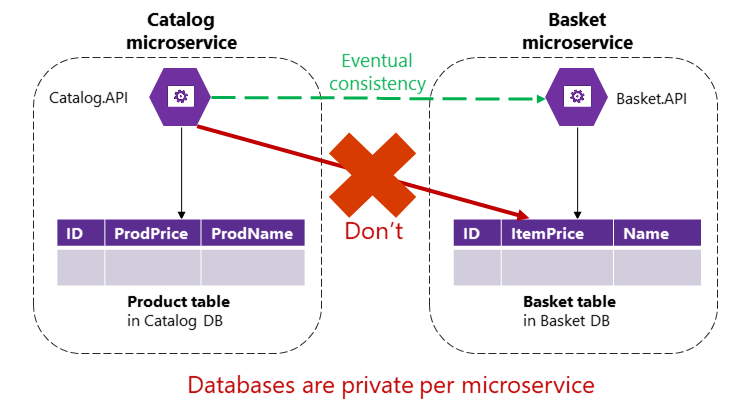
Рис. 4-9. Микрослужба не может напрямую получить доступ к таблице в другой микрослужбе
Микрослужба каталога не должна напрямую обновлять таблицу "Корзина", так как таблица "Корзина" принадлежит микрослужбе "Корзина". Чтобы обновить микрослужбу корзины, микрослужба каталога должна обеспечить конечную согласованность, вероятно, на основе асинхронного взаимодействия, такого как интеграционные события (сообщения и взаимодействие на основе событий). Это то, как эталонное приложение eShopOnContainers выполняет этот тип согласованности в микрослужбах.
Как указано в теореме CAP, необходимо выбрать между доступностью и строгой согласованностью ACID. Большинство сценариев на основе микрослужбы требуют доступности и высокой масштабируемости в отличие от строгой согласованности. Критически важные приложения должны оставаться в рабочем состоянии, при этом разработчики могут обойти строгую согласованность, используя методы для работы с слабой или конечной согласованностью. Это подход, принятый большинством архитектур на основе микрослужб.
Кроме того, транзакции фиксации в стиле ACID или двухэтапной фиксации не только против принципов микрослужб; Большинство баз данных NoSQL (например, Azure Cosmos DB, MongoDB и т. д.) не поддерживают двухфазные транзакции фиксации, типичные в сценариях распределенных баз данных. Однако обеспечение согласованности данных между службами и базами данных является важным. Эта проблема также связана с вопросом о том, как распространять изменения между несколькими микрослужбами, когда некоторые данные должны быть избыточными, например, если необходимо иметь имя или описание продукта в микрослужбе каталога и микрослужбе Корзины.
Хорошим решением этой проблемы является использование конечной согласованности между микрослужбами, обеспечиваемой через связь на основе событий и систему публикации и подписки. Эти разделы рассматриваются в разделе "Асинхронное взаимодействие на основе событий " далее в этом руководстве.
Задача 4. Проектирование взаимодействия между границами микрослужбы
Взаимодействие между границами микрослужб является реальной проблемой. В этом контексте обмен данными не относится к используемому протоколу (HTTP и REST, AMQP, обмен сообщениями и т. д.). Вместо этого он рассматривает, какой стиль общения следует использовать, и особенно насколько должны быть связаны ваши микрослужбы. В зависимости от уровня связи, когда происходит сбой, влияние этого сбоя на систему будет значительно отличаться.
В распределенной системе, такой как приложение на основе микрослужб, с таким количеством артефактов, перемещающихся между множеством серверов или узлов, компоненты в конечном итоге выходят из строя. Частичный сбой и даже большие сбои будут возникать, поэтому необходимо разработать микрослужбы и связь между ними с учетом распространенных рисков в этой распределенной системе.
Популярным подходом является реализация микрослужб на основе HTTP (REST) из-за их простоты. Подход на основе HTTP является совершенно приемлемым; Эта проблема связана с тем, как его использовать. Если вы используете HTTP-запросы и ответы только для взаимодействия с микрослужбами из клиентских приложений или из шлюзов API, это нормально. Но если вы создаете длинные цепочки синхронных http-вызовов между микрослужбами, взаимодействуя через их границы, как будто микрослужбы были объектами в монолитном приложении, ваше приложение в конечном итоге столкнутся с проблемами.
Например, предположим, что клиентское приложение вызывает HTTP-API к отдельной микрослужбе, например микрослужбе заказа. Если микрослужба заказа в свою очередь вызывает дополнительные микрослужбы с помощью HTTP в рамках одного цикла запроса и ответа, создается цепочка http-вызовов. Это может звучать разумно изначально. Однако есть важные моменты, которые следует учитывать при переходе по этому пути:
Блокировка и низкая производительность. Из-за синхронного характера HTTP исходный запрос не получает ответ до завершения всех внутренних http-вызовов. Представьте, что число этих вызовов значительно увеличивается и одновременно один из промежуточных HTTP-вызовов микрослужбы блокируется. Результатом является то, что производительность ухудшается, и общая масштабируемость будет экспоненциально затронута с увеличением количества дополнительных HTTP-запросов.
Связывание микрослужб с HTTP. Микрослужбы бизнеса не должны быть связаны с другими бизнес-микрослужбами. В идеале они не должны "знать" о существовании других микрослужб. Если ваше приложение зависит от связывания микрослужб, как в примере, достижение автономии каждого микросервиса будет почти невозможно.
Сбой в любой микрослужбе. Если вы реализовали цепочку микрослужб, связанных вызовами по протоколу HTTP, при сбое любой из микрослужб (а в конечном итоге сбои неизбежны) вся цепочка микрослужб тоже выйдет из строя. Система, основанная на микросервисах, должна быть спроектирована таким образом, чтобы продолжать работать как можно лучше в условиях частичных сбоев. Даже если вы реализуете логику клиента, которая использует повторные попытки с экспоненциальной задержкой или механизмом прерывания, чем сложнее цепочки вызовов HTTP, тем сложнее реализовать стратегию устранения сбоев на основе HTTP.
На самом деле, если внутренние микрослужбы взаимодействуют путем создания цепочек HTTP-запросов, как описано, можно утверждать, что у вас есть монолитное приложение, но одно на основе HTTP-процессов между процессами вместо механизмов внутрипроцессного обмена данными.
Таким образом, чтобы обеспечить автономию микрослужб и повысить устойчивость, следует свести к минимуму использование цепочек обмена данными между микрослужбами запросов и ответов. Рекомендуется использовать только асинхронное взаимодействие для обмена данными между микрослужбами, используя асинхронное взаимодействие на основе сообщений и событий или используя (асинхронный) http-опрос независимо от исходного цикла HTTP-запроса и ответа.
Использование асинхронной коммуникации объясняется с дополнительными сведениями далее в этом руководстве в разделах Интеграция асинхронных микрослужб в поддержание автономии микрослужб и Асинхронная коммуникация на основе сообщений.
Дополнительные ресурсы
Теорема CAP
https://en.wikipedia.org/wiki/CAP_theoremИтоговая согласованность
https://en.wikipedia.org/wiki/Eventual_consistencyПраймер согласованности данных
https://learn.microsoft.com/previous-versions/msp-n-p/dn589800(v=pandp.10)Мартин Фаулер. CQRS (разделение функций команд и запросов)
https://martinfowler.com/bliki/CQRS.htmlМатериализованное представление
https://learn.microsoft.com/azure/architecture/patterns/materialized-viewЧарльз Роу. ACID и BASE: сдвиг pH обработки транзакций базы данных
https://www.dataversity.net/acid-vs-base-the-shifting-ph-of-database-transaction-processing/Компенсирующие транзакции
https://learn.microsoft.com/azure/architecture/patterns/compensating-transactionУди Дахан. Сервисно-ориентированная композиция
https://udidahan.com/2014/07/30/service-oriented-composition-with-video/
Сотрудничайте с нами на GitHub
Исходный код этого содержимого можно найти на GitHub, где вы также можете создавать и просматривать проблемы и запросы на вытягивание. Для получения дополнительной информации см. наше руководство для авторов.