Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Подсказка
Это фрагмент из электронной книги «Архитектура микрослужб .NET для контейнеризованных приложений .NET», доступной в документации .NET или в виде бесплатного скачиваемого PDF-файла, который можно прочитать в автономном режиме.

В распределенных системах, таких как приложения на основе микрослужб, возникает риск частичного сбоя. Например, одна микрослужба или контейнер может выйти из строя или быть недоступна для реагирования в течение короткого времени, или одна виртуальная машина или один сервер могут завершиться сбоем. Так как клиенты и службы являются отдельными процессами, служба может не иметь возможности своевременно реагировать на запрос клиента. Служба может быть перегружена и отвечать очень медленно на запросы или может быть просто недоступна в течение короткого времени из-за проблем с сетью.
Например, рассмотрим страницу сведений о заказе из примера приложения eShopOnContainers. Если микросервис заказа не отвечает, когда пользователь пытается отправить заказ, неудачная реализация клиентского процесса (например, в MVC веб-приложении) при использовании синхронных RPC без указания времени ожидания может привести к бесконечному ожиданию потока ответа. Помимо создания плохого взаимодействия с пользователем, каждое неответственное ожидание потребляет или блокирует поток, и потоки очень ценны в высокомасштабируемых приложениях. Если существует множество заблокированных потоков, в конечном итоге приложение может исчерпать все потоки. В этом случае приложение может стать глобально не отвечающим, а не частично не отвечать, как показано на рис. 8-1.
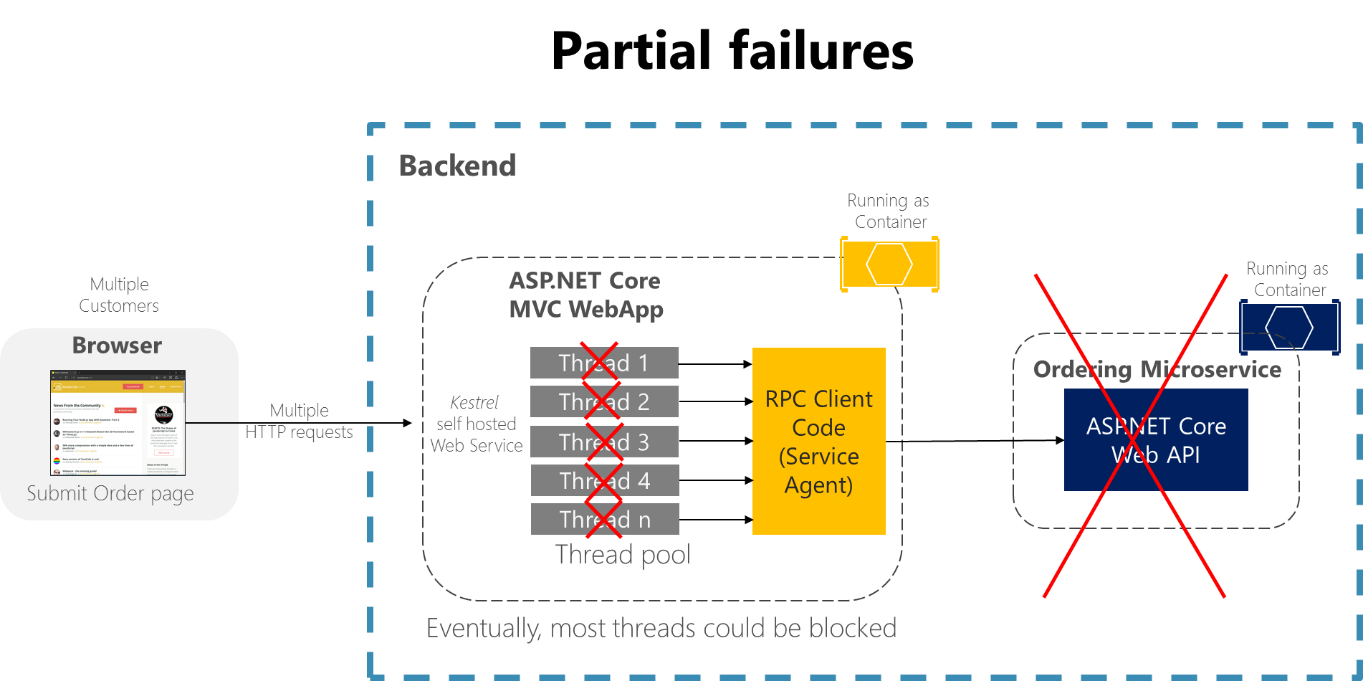
рис. 8-1. Частичные сбои из-за зависимостей, которые влияют на доступность потоков службы.
В большом приложении на основе микрослужб любой частичный сбой может усилиться, особенно если большинство взаимодействия микрослужб основано на синхронных HTTP-вызовах (которое считается анти-шаблоном). Подумайте о системе, которая получает миллионы входящих звонков в день. Если ваша система имеет плохой дизайн, основанный на длинных цепочках синхронных HTTP-вызовов, эти входящие вызовы могут привести к гораздо большему миллиону исходящих вызовов (предположим, соотношение 1:4) к десяткам внутренних микрослужб как синхронных зависимостей. Эта ситуация показана на рис. 8-2, особенно зависимость #3, которая запускает цепочку, вызывая зависимость #4, которая затем вызывает #5.
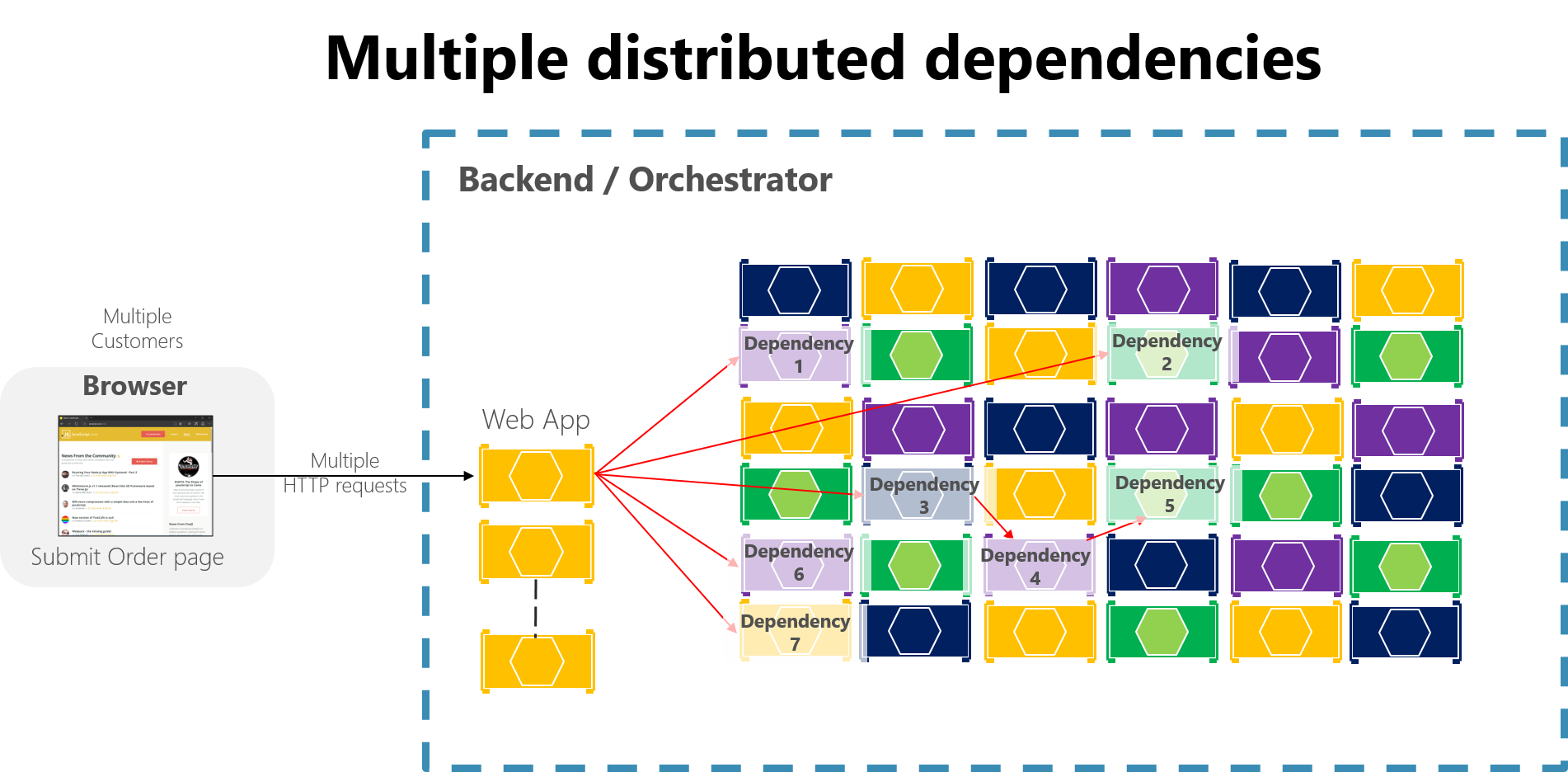
рис. 8-2. Влияние неправильной структуры с использованием длинных цепочек HTTP-запросов
Периодический сбой гарантируется в распределенной и облачной системе, даже если каждая зависимость имеет отличную доступность. Это тот факт, что вам нужно рассмотреть.
Если вы не разрабатываете и не реализуете методы обеспечения отказоустойчивости, то даже небольшие простои могут быть усилены. Например, 50 зависимостей, каждая из которых имеет 99,99% доступности, приведут к результату нескольких часов простоя каждый месяц из-за этого цепного эффекта. Если зависимость микрослужбы завершается сбоем при обработке большого объема запросов, эта ошибка может быстро перегрузить все доступные потоки запросов в каждой службе и привести к сбою всего приложения.
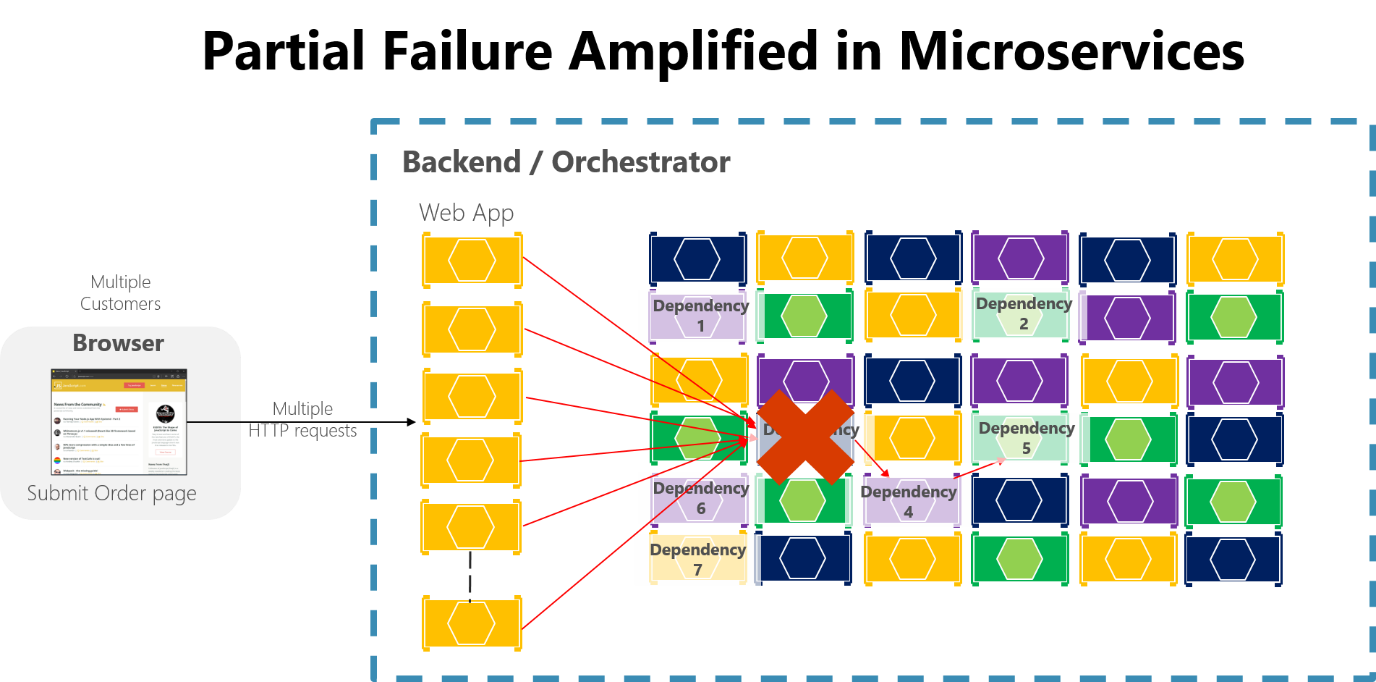
Рис. 8-3. Частичный сбой, усиленный микрослужбами с длинными цепочками синхронных вызовов HTTP
Чтобы свести к минимуму эту проблему, в разделе Асинхронная интеграция микрослужб применяет автономию микрослужб, в этом руководстве рекомендуется использовать асинхронное взаимодействие между внутренними микрослужбами.
Кроме того, важно разработать микрослужбы и клиентские приложения для обработки частичных сбоев, т. е. для создания устойчивых микрослужб и клиентских приложений.
Совместная работа с нами на GitHub
Источник этого содержимого можно найти на GitHub, где также можно создавать и просматривать проблемы и запросы на вытягивание. Дополнительные сведения см. в нашем руководстве для участников.