Заметка
Доступ к этой странице требует авторизации. Вы можете попробовать войти в систему или изменить каталог.
Доступ к этой странице требует авторизации. Вы можете попробовать сменить директорию.
Подсказка
Это фрагмент из электронной книги «Архитектура микрослужб .NET для контейнеризованных приложений .NET», доступной в документации .NET или в виде бесплатного скачиваемого PDF-файла, который можно прочитать в автономном режиме.

Как отмечалось ранее, следует управлять сбоями, которые могут требовать различное время на восстановление, что может произойти, если вы пытаетесь подключиться к удаленной службе или ресурсу. Обработка этого типа сбоя может повысить стабильность и устойчивость приложения.
В распределенной среде вызовы к удаленным ресурсам и службам могут завершиться сбоем из-за временных сбоев, таких как медленные сетевые подключения и время ожидания, или если ресурсы реагируют медленно или временно недоступны. Эти ошибки обычно исправляют себя через короткое время, и надежное облачное приложение должно быть готово к их обработке с помощью стратегии, такой как шаблон повторных попыток.
Однако также могут возникнуть ситуации, когда ошибки возникают из-за непреднамеренных событий, которые могут занять гораздо больше времени для устранения. Эти ошибки могут варьироваться по серьезности от частичной потери возможности подключения до полного отказа службы. В таких ситуациях бессмысленно для приложения постоянно повторять операцию, которая маловероятно, что приведет к успеху.
Вместо этого приложение должно быть закодировано, чтобы принять, что операция завершилась сбоем и обработает ошибку соответствующим образом.
Небрежное использование Http повторных попыток может привести к созданию атаки типа «отказ в обслуживании» (DoS) в собственном программном обеспечении. Так как микрослужба завершается сбоем или выполняется медленно, несколько клиентов могут многократно повторить неудачные запросы. Это создает опасный риск экспоненциального роста трафика, направленного на вышедшую из строя службу.
Таким образом, вам нужен какой-то защитный барьер, чтобы остановить чрезмерные запросы, когда не стоит продолжать эти попытки. Этот защитный барьер и есть автоматический выключатель.
Паттерн Circuit Breaker имеет другое назначение, чем паттерн повторной попытки. Шаблон повторных попыток позволяет приложению повторить операцию в ожидании успешной операции. Шаблон разбиения цепи запрещает приложению выполнять операцию, которая, скорее всего, завершится ошибкой. Приложение может объединить эти два шаблона. Однако логика повторных попыток должна быть чувствительна к любому исключению, возвращаемому выключателем, и она должна отказаться от попыток повторных попыток, если средство останова цепи указывает, что ошибка не является временной.
Реализация шаблона автоматического выключателя с использованием IHttpClientFactory и библиотеки Polly
Как и при реализации повторных попыток, рекомендованный подход для автоматических выключателей заключается в использовании проверенных библиотек .NET, таких как Polly и ее встроенная интеграция с IHttpClientFactory.
Добавление политики выключателя цепи в IHttpClientFactory исходящий промежуточный конвейер так же просто, как добавление одного фрагмента кода в ваш уже существующий код при использовании IHttpClientFactory.
Единственное дополнение к коду, используемому для повторных попыток вызова HTTP, — это код, в который добавляется политика разбиения цепи в список используемых политик, как показано в следующем добавочном коде.
// Program.cs
var retryPolicy = GetRetryPolicy();
var circuitBreakerPolicy = GetCircuitBreakerPolicy();
builder.Services.AddHttpClient<IBasketService, BasketService>()
.SetHandlerLifetime(TimeSpan.FromMinutes(5)) // Sample: default lifetime is 2 minutes
.AddHttpMessageHandler<HttpClientAuthorizationDelegatingHandler>()
.AddPolicyHandler(retryPolicy)
.AddPolicyHandler(circuitBreakerPolicy);
Метод AddPolicyHandler() — это то, что добавляет политики в объекты HttpClient, которые вы будете использовать. В этом случае она добавляет политику Polly для разбиения цепи.
Для более модульного подхода политика разбиения цепи определяется в отдельном методе GetCircuitBreakerPolicy(), как показано в следующем коде:
// also in Program.cs
static IAsyncPolicy<HttpResponseMessage> GetCircuitBreakerPolicy()
{
return HttpPolicyExtensions
.HandleTransientHttpError()
.CircuitBreakerAsync(5, TimeSpan.FromSeconds(30));
}
В приведенном выше примере кода политика разбиения цепи настраивается таким образом, чтобы она прерывала или открывала канал, если при повторных попытках http-запросов произошло пять последовательных сбоев. Когда это произойдет, схема будет разорвана на 30 секунд: в этом периоде вызовы будут немедленно отклонены автоматическим выключателем вместо их выполнения. Политика автоматически интерпретирует соответствующие исключения и коды состояния HTTP как ошибки.
Кроме того, для перенаправления запросов на резервную инфраструктуру следует использовать средства разбиения каналов, если у вас возникли проблемы с определенным ресурсом, развернутым в среде, отличной от клиентского приложения или службы, выполняющей вызов HTTP. Таким образом, если в центре обработки данных возникает сбой, который влияет только на внутренние микрослужбы, но не клиентские приложения, клиентские приложения могут перенаправляться в резервные службы. Полли планирует новую политику для автоматизации этого сценария отработки отказа.
Все эти функции предназначены для случаев, когда вы управляете переключением на резервный сервер из кода .NET, в отличие от автоматического управления для вас Azure с прозрачностью расположения.
При использовании HttpClient с точки зрения применения ничего нового добавлять не нужно, так как код совпадает с кодом при использовании HttpClient, IHttpClientFactory, как показано в предыдущих разделах.
Тестирование повторных попыток и срабатывания предохранителей HTTP в eShopOnContainers
При запуске решения eShopOnContainers на узле Docker необходимо запустить несколько контейнеров. Некоторые контейнеры медленно запускаются и инициализируются, например контейнер SQL Server. Это особенно верно при первом развертывании приложения eShopOnContainers в Docker, так как необходимо настроить образы и базу данных. Тот факт, что некоторые контейнеры запускаются медленнее, чем другие, может привести к первоначальному выбрасыванию HTTP исключений, несмотря на то, что вы устанавливаете зависимости между контейнерами на уровне docker-compose, как описано в предыдущих разделах. Эти зависимости Docker Compose между контейнерами находятся лишь на уровне процессов. Процесс точки входа контейнера может быть запущен, но SQL Server может быть не готов к запросам. Результатом может быть каскад ошибок, и приложение может получить исключение при попытке использовать этот конкретный контейнер.
Вы также можете увидеть этот тип ошибки при запуске при развертывании приложения в облаке. В этом случае оркестраторы могут перемещать контейнеры из одного узла или виртуальной машины в другой (то есть запуская новые экземпляры) при балансировке количества контейнеров между узлами кластера.
Решение eShopOnContainers для этих проблем при запуске всех контейнеров заключается в использовании паттерна повторных попыток, описанного ранее.
Тестирование автоматического выключателя в eShopOnContainers
Существует несколько способов, которыми вы можете прервать или открыть цепь и протестировать её с помощью eShopOnContainers.
Одним из вариантов является снижение допустимого количества повторных попыток до 1 в политике разбиения цепи и повторное развертывание всего решения в Docker. При одной повторной попытке велика вероятность, что HTTP-запрос завершится сбоем во время развертывания, автоматический выключатель отключится, и вы встретите ошибку.
Другим вариантом является использование пользовательского ПО промежуточного слоя, реализованного в микрослужбе Корзины . Если это ПО промежуточного слоя включено, он перехватывает все HTTP-запросы и возвращает код состояния 500. Вы можете включить промежуточное ПО, выполнив запрос GET к неисправному URI, как показано ниже.
GET http://localhost:5103/failing
Этот запрос возвращает текущее состояние ПО промежуточного слоя. Если ПО промежуточного слоя включено, запрос возвращает код состояния 500. Если ПО промежуточного слоя отключено, нет ответа.GET http://localhost:5103/failing?enable
Этот запрос активирует промежуточное программное обеспечение.GET http://localhost:5103/failing?disable
Этот запрос отключает ПО промежуточного слоя.
Например, после запуска приложения можно включить ПО промежуточного слоя, выполнив запрос с помощью следующего URI в любом браузере. Обратите внимание, что микрослужба заказа использует порт 5103.
http://localhost:5103/failing?enable
Затем можно проверить состояние с помощью URI http://localhost:5103/failing, как показано на рис. 8-5.
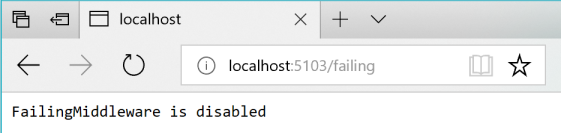
Рис. 8-5. Проверка состояния промежуточного слоя ASP.NET "неисправный" — в данном случае он отключен.
На данном этапе микросервис Корзина отвечает с кодом состояния 500 всякий раз, когда вы его вызываете.
После запуска ПО промежуточного слоя, вы можете попробовать разместить заказ через MVC веб-приложение. Поскольку запросы завершаются сбоем, цепь откроется.
В следующем примере видно, что в логике размещения заказа веб-приложение MVC содержит блок catch. Если код перехватывает исключение открытой цепи, пользователю отображается дружественное сообщение, говорящее им подождать.
public class CartController : Controller
{
//…
public async Task<IActionResult> Index()
{
try
{
var user = _appUserParser.Parse(HttpContext.User);
//Http requests using the Typed Client (Service Agent)
var vm = await _basketSvc.GetBasket(user);
return View(vm);
}
catch (BrokenCircuitException)
{
// Catches error when Basket.api is in circuit-opened mode
HandleBrokenCircuitException();
}
return View();
}
private void HandleBrokenCircuitException()
{
TempData["BasketInoperativeMsg"] = "Basket Service is inoperative, please try later on. (Business message due to Circuit-Breaker)";
}
}
Вот сводка. Политика повторных попыток делает HTTP-запрос несколько раз и получает ошибки HTTP. Когда число повторных попыток достигает максимального числа, установленного для политики Circuit Breaker (в данном случае 5), приложение вызывает исключение BrokenCircuitException. Результатом является понятное сообщение, как показано на рис. 8-6.
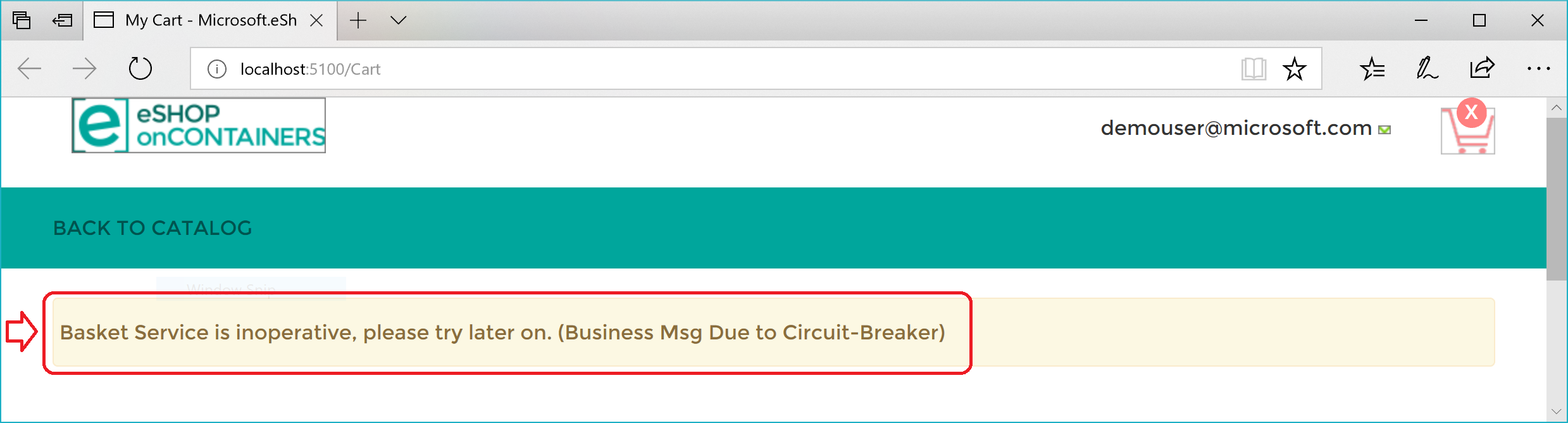
Рис. 8-6. Средство разбиения цепи, возвращающее ошибку пользовательскому интерфейсу
Вы можете реализовать другую логику для открытия или разрыва канала. Или вы можете попробовать HTTP-запрос к другой бэкэнд микрослужбе, если есть резервный центр обработки данных или резервная серверная система.
Наконец, еще одна возможность использования CircuitBreakerPolicy – это Isolate (которая заставляет открыть и держит цепь) и Reset (которая снова закрывает). Их можно использовать для создания служебной HTTP-конечной точки, которая вызывает изоляцию и сброс непосредственно на политике. Такую конечную точку HTTP можно также использовать, надлежащим образом защитив, в рабочей среде для временной изоляции зависимой системы, например, при ее обновлении. Или это может вручную отключить цепь, чтобы защитить зависящую систему, которую подозреваете в неисправности.
Дополнительные ресурсы
-
Шаблон прерывателя цепи
https://learn.microsoft.com/azure/architecture/patterns/circuit-breaker
Сотрудничайте с нами на GitHub
Исходный код этого содержимого можно найти на GitHub, где вы также можете создавать и просматривать проблемы и запросы на вытягивание. Для получения дополнительной информации см. наше руководство для авторов.