Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Совет
Это фрагмент из книги, архитектор современных веб-приложений с ASP.NET Core и Azure, доступный в документации .NET или в виде бесплатного скачиваемого PDF-файла, который можно читать в автономном режиме.

"Данные — это самый ценный ресурс, который намного переживет сами системы".
Тим Бернерс-Ли (Tim Berners-Lee)
Доступ к данным является одной из важнейших составляющих практически любой программы. ASP.NET Core поддерживает различные способы доступа к данным, включая Entity Framework Core (и Entity Framework 6), и может работать с любыми платформами доступа к данным .NET. Выбор используемой платформы доступа к данным зависит от потребностей приложения. Абстрагируя выбор такой платформы от проектов ядра приложения и пользовательского интерфейса, а также инкапсулируя детали реализации в инфраструктуре, можно создавать слабо связанное приложение с расширенными возможностями для тестирования.
Entity Framework Core (для реляционных баз данных)
Если вы создаете новое приложение ASP.NET Core для работы с реляционными данными, рекомендуется выбирать Entity Framework Core (EF Core) для доступа к данным. EF Core является объектно-реляционным модулем сопоставления (O/RM), который позволяет разработчикам .NET обеспечивать двустороннюю сохраняемость объектов во взаимодействии с источником данных. Это устраняет необходимость в большей части кода для доступа к данным, который разработчикам обычно приходится писать. Как и ASP.NET Core, платформа EF Core была переработана, чтобы обеспечить поддержку модульных кроссплатформенных приложений. Вы можете добавить ее в приложение в виде пакета NuGet, настроить при запуске приложения и запросить ее посредством внедрения зависимостей в нужный момент.
Чтобы использовать EF Core с базой данных SQL Server, выполните следующую команду dotnet CLI:
dotnet add package Microsoft.EntityFrameworkCore.SqlServer
Чтобы добавить поддержку источника данных в памяти для тестирования, выполните следующую команду:
dotnet add package Microsoft.EntityFrameworkCore.InMemory
DbContext
Для работы с EF Core вам потребуется подкласс DbContext. Этот класс содержит свойства, представляющие коллекцию сущностей, с которыми будет работать ваше приложение. Пример eShopOnWeb содержит CatalogContext коллекции для элементов, брендов и типов:
public class CatalogContext : DbContext
{
public CatalogContext(DbContextOptions<CatalogContext> options) : base(options)
{
}
public DbSet<CatalogItem> CatalogItems { get; set; }
public DbSet<CatalogBrand> CatalogBrands { get; set; }
public DbSet<CatalogType> CatalogTypes { get; set; }
}
DbContext должен иметь конструктор, который принимает DbContextOptions и передает этот аргумент базовому DbContext конструктору. Если у вас есть только один DbContext в приложении, можно передать экземпляр DbContextOptions, но если у вас есть несколько универсальных типов, передавая тип DbContext в качестве универсального DbContextOptions<T> параметра.
Настройка EF Core
В приложении ASP.NET Core обычно настраивается EF Core в Program.cs с другими зависимостями приложения. EF Core использует функцию DbContextOptionsBuilder, которая поддерживает несколько полезных методов расширения для оптимизации конфигурации. Чтобы настроить CatalogContext для использования базы данных SQL Server с строка подключения, определенной в конфигурации, добавьте следующий код:
builder.Services.AddDbContext<CatalogContext>(
options => options.UseSqlServer(
builder.Configuration.GetConnectionString("DefaultConnection")));
Чтобы использовать выполняющуюся в памяти базу данных:
builder.Services.AddDbContext<CatalogContext>(options =>
options.UseInMemoryDatabase());
После установки EF Core создайте дочерний тип DbContext и добавили тип в службы приложения, вы можете использовать EF Core. Вы можете запросить экземпляр типа DbContext в любой службе, которая нуждается в ней, и начать работу с сохраненными сущностями с помощью LINQ, как если бы они были просто в коллекции. EF Core автоматически преобразует выражения LINQ в запросы SQL для хранения и извлечения данных.
Чтобы просмотреть выполнение запросов EF Core, настройте ведение журналов как минимум на уровне информационных сообщений, как показано на рис. 8-1.
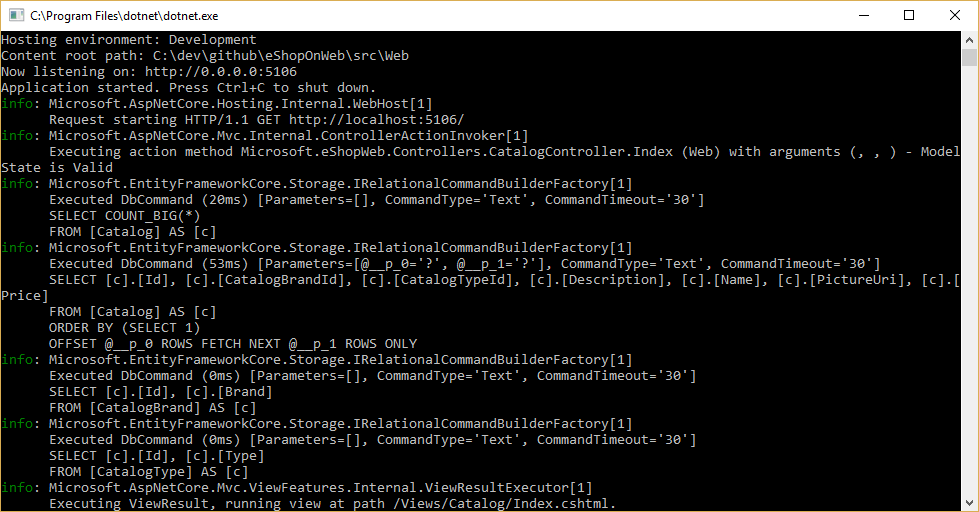
Рис. 8-1. Ведение журналов запросов EF Core на консоль
Получение и сохранение данных
Чтобы извлечь данные из EF Core, необходимо обратиться к соответствующему свойству и использовать LINQ для фильтрации результатов. Также можно использовать LINQ для выполнения проекции (преобразования результата из одного типа в другой). В следующем примере вы получите CatalogBrands, упорядоченные по имени, отфильтрованные по их свойству Enabled и проецируемые SelectListItem на тип:
var brandItems = await _context.CatalogBrands
.Where(b => b.Enabled)
.OrderBy(b => b.Name)
.Select(b => new SelectListItem {
Value = b.Id, Text = b.Name })
.ToListAsync();
В приведенном выше примере важно добавить вызов ToListAsync для немедленного выполнения запроса. В противном случае оператор назначит IQueryable<SelectListItem> брендItems, который не будет выполняться до перечисления. Существуют плюсы и минусы для возврата IQueryable результатов из методов. Такой подход позволяет осуществлять дальнейшие изменения запроса, который будет создавать EF Core, но также может привести к ошибке, которая проявится только во время выполнения при добавлении операций в запрос, который EF Core не сможет преобразовать. Обычно это безопаснее, чтобы передать все фильтры в метод, выполняющий доступ к данным, и вернуть коллекцию в памяти (например, List<T>в результате).
EF Core отслеживает изменения сущностей, которые получаются из хранилища сохраняемости. Чтобы сохранить изменения в отслеживаемой сущности, просто вызовите SaveChangesAsync метод в DbContext, убедившись, что это тот же экземпляр DbContext, который использовался для получения сущности. Добавление и удаление сущностей выполняется непосредственно в соответствующем свойстве DbSet и вызове для SaveChangesAsync выполнения команд базы данных. В следующем примере показано добавление, обновление и удаление сущностей из хранилища сохраняемости.
// create
var newBrand = new CatalogBrand() { Brand = "Acme" };
_context.Add(newBrand);
await _context.SaveChangesAsync();
// read and update
var existingBrand = _context.CatalogBrands.Find(1);
existingBrand.Brand = "Updated Brand";
await _context.SaveChangesAsync();
// read and delete (alternate Find syntax)
var brandToDelete = _context.Find<CatalogBrand>(2);
_context.CatalogBrands.Remove(brandToDelete);
await _context.SaveChangesAsync();
EF Core поддерживает как синхронные, так и асинхронные методы получения и сохранения. В веб-приложениях рекомендуется использовать шаблон async/await для асинхронных методов. В этом случае потоки веб-сервера не блокируются на время ожидания завершения операций доступа к данным.
Дополнительные сведения см. в разделе "Буферизация и потоковая передача".
Получение связанных данных
При получении сущностей EF Core заполняет все свойства, которые хранятся в базе данных непосредственно с этой сущностью. Свойства навигации, например списки связанных сущностей, не заполняются и могут получать значения null. Этот процесс гарантирует, что EF Core не будет извлекать объем данных больше необходимого, что особенно важно для веб-приложений, которые должны быстро обрабатывать запросы и возвращать ответы эффективным способом. Чтобы включить отношение с сущностью, используя безотложную загрузку, необходимо указать свойство, используя метод расширения Include для запроса, как показано ниже:
// .Include requires using Microsoft.EntityFrameworkCore
var brandsWithItems = await _context.CatalogBrands
.Include(b => b.Items)
.ToListAsync();
С помощью ThenInclude можно включить несколько отношений, а также вложенные отношения. EF Core выполнит один запрос для извлечения результирующего набора сущностей. Кроме того, вы можете включить свойства навигации, передав строку с разделением "." в метод расширения .Include() следующим образом:
.Include("Items.Products")
Помимо инкапсуляции логики фильтрации, эта спецификация может указывать форму возвращаемых данных, включая свойства, которые следует заполнить. Пример приложения eShopOnWeb содержит несколько спецификаций, которые демонстрируют сведения об инкапсулирующей безотложной загрузке в спецификации. Вы видите, как спецификация используется в рамках запроса:
// Includes all expression-based includes
query = specification.Includes.Aggregate(query,
(current, include) => current.Include(include));
// Include any string-based include statements
query = specification.IncludeStrings.Aggregate(query,
(current, include) => current.Include(include));
Также для загрузки связанных данных можно использовать явную загрузку. Явная загрузка позволяет загружать дополнительные данные в уже извлеченную сущность. Так как для этого требуется отдельный запрос к базе данных, такой подход не рекомендуется для веб-приложений, в которых необходимо свести к минимуму число обращений к базе данных в рамках одного запроса.
Отложенная загрузка позволяет автоматически загружать данные в тот момент, когда на них ссылается приложение. В EF Core добавлена поддержка отложенной загрузки в версии 2.1. Отложенная загрузка не включена по умолчанию и требует установки Microsoft.EntityFrameworkCore.Proxies. Как и явная загрузка, отложенная загрузка обычно отключена для веб-приложений, так как ее использование приведет к дополнительным запросам к базе данных в пределах каждого веб-запроса. К сожалению, издержки, связанные с отложенной загрузкой, часто трудно заметить во время разработки, когда задержка маленькая и для тестирования используются небольшие наборы данных. Но в рабочей среде с большим количеством пользователей, данных и задержек запросы к базе данных могут приводить к снижению производительности для веб-приложений, где активно используется отложенная загрузка.
Предотвращение отложенной загрузки сущностей в веб-приложениях
Рекомендуется протестировать приложение при изучении фактических запросов к базе данных, которые он делает. В определенных обстоятельствах EF Core может сделать гораздо больше запросов или более дорогостоящий запрос, чем оптимальный для приложения. Одна из таких проблем называется декартовским взрывом. Команда EF Core предоставляет метод AsSplitQuery одним из нескольких способов настройки поведения среды выполнения.
Инкапсуляция данных
EF Core поддерживает несколько функций, которые позволяют модели правильно инкапсулировать свое состояние. Распространенной проблемой моделей предметной области является то, что они предоставляют свойства навигации коллекции как общедоступные типы списка. Таким образом, любой участник совместной работы может управлять содержимым этих типов в коллекции. В результате могут обходиться важные бизнес-правила, связанные с коллекцией, из-за чего объект может оказаться в недопустимом состоянии. Чтобы решить эту проблему, рекомендуется разрешать доступ к связанным коллекциям только для чтения и явно предоставлять методы, которые определяют возможные способы работы клиентов с этими коллекциями, как в следующем примере:
public class Basket : BaseEntity
{
public string BuyerId { get; set; }
private readonly List<BasketItem> _items = new List<BasketItem>();
public IReadOnlyCollection<BasketItem> Items => _items.AsReadOnly();
public void AddItem(int catalogItemId, decimal unitPrice, int quantity = 1)
{
var existingItem = Items.FirstOrDefault(i => i.CatalogItemId == catalogItemId);
if (existingItem == null)
{
_items.Add(new BasketItem()
{
CatalogItemId = catalogItemId,
Quantity = quantity,
UnitPrice = unitPrice
});
}
else existingItem.Quantity += quantity;
}
}
Этот тип сущности не предоставляет открытое свойство List или ICollection, но вместо этого предоставляет тип IReadOnlyCollection, который создает оболочку для базового типа списка. При использовании этого шаблона можно указать для Entity Framework Core использовать резервное поле следующим образом:
private void ConfigureBasket(EntityTypeBuilder<Basket> builder)
{
var navigation = builder.Metadata.FindNavigation(nameof(Basket.Items));
navigation.SetPropertyAccessMode(PropertyAccessMode.Field);
}
Еще один способ улучшить модель предметной области — использовать объекты значений для типов, которым не хватает удостоверений и которые различаются только по своим свойствам. Использование таких типов в качестве свойств сущностей может помочь сохранить логику, присущую объекту значения, и избежать повторяющуюся логику между несколькими сущностями, использующими одну концепцию. В Entity Framework Core можно сохранить объекты значений в той же таблице, что и сущность-владелец, настроив тип в качестве принадлежащей сущности следующим образом:
private void ConfigureOrder(EntityTypeBuilder<Order> builder)
{
builder.OwnsOne(o => o.ShipToAddress);
}
В этом примере свойство ShipToAddress принадлежит типу Address.
Address является объектом значения с несколькими свойствами, такими как Street и City. EF Core сопоставляет объект Order со своей таблицей, по одному столбцу на свойство Address, вставляя перед именем каждого столбца имя свойства. В этом примере таблица Order должна включать такие столбцы, как ShipToAddress_Street и ShipToAddress_City. При необходимости собственные типы можно также хранить в отдельных таблицах.
Узнайте больше о поддержке сущностей в EF Core.
Устойчивые подключения
Внешние ресурсы, например базы данных SQL, время от времени могут быть недоступны. Если ресурс временно недоступен, приложение может использовать логику повторных попыток, чтобы избежать возникновения исключения. Такой подход часто называют устойчивостью подключений. Вы можете реализовать собственную логику повторных попыток с экспоненциальной выдержкой, при которой приложение пытается повторить операцию с экспоненциально растущим временем ожидания, пока не будет достигнуто максимальное число повторных попыток. В этом методе учитывается, что облачные ресурсы могут периодически становиться недоступными на несколько секунд по разным причинам, что может приводить к неудачному завершению некоторых запросов.
Для баз данных Azure SQL платформа Entity Framework Core уже предоставляет логику устойчивости и повторного выполнения при подключении к внутренним базам данных. Но вам необходимо применить стратегию выполнения Entity Framework к каждому подключению DbContext, если вы хотите иметь устойчивое подключение к EF Core.
Например, следующий код на уровне подключения к EF Core обеспечивает устойчивое SQL-подключение, которое устанавливается повторно при сбое.
builder.Services.AddDbContext<OrderingContext>(options =>
{
options.UseSqlServer(builder.Configuration["ConnectionString"],
sqlServerOptionsAction: sqlOptions =>
{
sqlOptions.EnableRetryOnFailure(
maxRetryCount: 5,
maxRetryDelay: TimeSpan.FromSeconds(30),
errorNumbersToAdd: null);
}
);
});
Стратегии выполнения и явные транзакции с использованием BeginTransaction и нескольких DbContext
Если в подключениях к EF Core включены повторные попытки, каждая операция, выполняемая с помощью EF Core, будет предпринимать повторные попытки. Каждый запрос и каждый вызов к SaveChangesAsync будет повторяться снова как единица в случае сбоя.
Но если код запускает транзакцию с помощью BeginTransaction, вы сами определяете группу операций, которые должны рассматриваться как единица, — все содержимое транзакции можно будет откатить в случае сбоя. При попытке выполнить эту транзакцию при использовании стратегии выполнения EF (политики повторных попыток) вы увидите исключение, включающее несколько SaveChangesAsync из нескольких dbContexts.
System.InvalidOperationException: настроенная стратегия SqlServerRetryingExecutionStrategy выполнения не поддерживает инициированные пользователем транзакции. Используйте стратегию выполнения, возвращаемую DbContext.Database.CreateExecutionStrategy() для выполнения всех операций в транзакции в качестве единицы повтора.
Необходимо вручную вызвать стратегию выполнения EF с делегатом, который представляет все, что должно быть выполнено. Если происходит временный сбой, стратегия выполнения снова вызывает делегат. В следующем примере кода показано, как реализовать этот подход:
// Use of an EF Core resiliency strategy when using multiple DbContexts
// within an explicit transaction
// See:
// https://learn.microsoft.com/ef/core/miscellaneous/connection-resiliency
var strategy = _catalogContext.Database.CreateExecutionStrategy();
await strategy.ExecuteAsync(async () =>
{
// Achieving atomicity between original Catalog database operation and the
// IntegrationEventLog thanks to a local transaction
using (var transaction = _catalogContext.Database.BeginTransaction())
{
_catalogContext.CatalogItems.Update(catalogItem);
await _catalogContext.SaveChangesAsync();
// Save to EventLog only if product price changed
if (raiseProductPriceChangedEvent)
{
await _integrationEventLogService.SaveEventAsync(priceChangedEvent);
transaction.Commit();
}
}
});
Первый DbContext — это _catalogContext и второй DbContext находится в объекте _integrationEventLogService . Наконец, действие фиксации выполняется в нескольких DbContext с помощью стратегии выполнения EF.
Ссылки — получение Entity Framework Core
- Документация по EF Corehttps://learn.microsoft.com/ef/
- EF Core: связанные данныеhttps://learn.microsoft.com/ef/core/querying/related-data
- Avoid Lazy Loading Entities in ASP.NET Applicationshttps://ardalis.com/avoid-lazy-loading-entities-in-asp-net-applications (Предотвращение отложенной загрузки сущностей в приложениях ASP.NET)
EF Core или микро-ORM?
EF Core хорошо подходит для управления сохраняемостью и по большей части инкапсулирует детали базы данных, освобождая от труда разработчиков приложения. Но это средство — не единственный вариант. Популярное альтернативное решение с открытым кодом — Dapper, который также называется микро-ORM. Микро-ORM — это упрощенное средство сопоставления объектов со структурами данных, обладающее сокращенным набором функции. Основной задачей Dapper является оптимизация производительности при проектировании, а не полная инкапсуляция базовых запросов, которые используются для извлечения и обновления данных. Поскольку это средство не абстрагирует SQL от разработчика, Dapper является более низкоуровневым инструментом, позволяя разработчикам создавать точные запросы, которые они хотят использовать для конкретных операций доступа к данным.
EF Core может предложить две существенных функциональных возможности, которые отличают эту платформу Dapper, но при этом приводят к снижению производительности. Первая из них — это преобразование выражений LINQ в SQL. Эти преобразования кэшируются, однако даже в этом случае при их первом выполнении производительность снижается. Вторая возможность — отслеживание изменений сущностей, что позволяет создавать эффективные операторы обновления. Такое поведение можно отключить для конкретных запросов с помощью расширения AsNoTracking. EF Core также создает эффективные SQL-запросы, которые крайне эффективны и в любом случае приемлемы с точки зрения производительности. Однако если вам требуется детальный контроль над тем, какой в точности запрос выполняется, вы также можете передать настраиваемый SQL (или выполнить хранимую процедуру) с помощью EF Core. В такой ситуации Dapper по-прежнему, хотя и незначительно, превосходит EF Core в отношении производительности. Текущие данные теста производительности для различных методов доступа к данным можно найти на сайте Dapper.
Чтобы ознакомиться с различиями в синтаксисе между Dapper и EF Core, рассмотрите следующие две версии одного и того же метода, извлекающего список элементов:
// EF Core
private readonly CatalogContext _context;
public async Task<IEnumerable<CatalogType>> GetCatalogTypes()
{
return await _context.CatalogTypes.ToListAsync();
}
// Dapper
private readonly SqlConnection _conn;
public async Task<IEnumerable<CatalogType>> GetCatalogTypesWithDapper()
{
return await _conn.QueryAsync<CatalogType>("SELECT * FROM CatalogType");
}
Для построения более сложных графов объектов с помощью Dapper вам потребуется написать связанные запросы самостоятельно (в отличие от EF Core, где для этого используется Include). Эта функциональная возможность поддерживается разными вариантами синтаксиса, в том числе с помощью функции множественного сопоставления, которая позволяет сопоставлять отдельные строки с несколькими сопоставленными объектами. Например, для класса Post со свойством Owner типа User следующий SQL-код будет возвращать все необходимые данные:
select * from #Posts p
left join #Users u on u.Id = p.OwnerId
Order by p.Id
Каждая возвращаемая строка будет включать данные User и Post. Поскольку данные User должны быть присоединены к данным Post посредством свойства Owner, используется следующая функция:
(post, user) => { post.Owner = user; return post; }
Полный код, возвращающий коллекцию элементов Post, свойства Owner которых будут заполнены соответствующими данными User, будет выглядеть следующим образом:
var sql = @"select * from #Posts p
left join #Users u on u.Id = p.OwnerId
Order by p.Id";
var data = connection.Query<Post, User, Post>(sql,
(post, user) => { post.Owner = user; return post;});
Dapper обеспечивает более низкий уровень инкапсуляции, в связи с чем разработчики должны знать больше о том, как хранятся их данные, как эффективно выполнять запросы к ним, а также о том, как писать дополнительный код для их получения. Если модель изменяется вместо создания новой миграции (еще одна функция EF Core) и (или) обновления данных сопоставления в одном месте в DbContext, необходимо обновить каждый затрагиваемый запрос. Для таких запросов не гарантируется время компиляции. Поэтому они могут завершиться сбоем во время выполнения при любых изменениях в модели или базе данных. Это значительно усложняет своевременное выявление ошибок. Тем не менее эти недостатки Dapper компенсирует крайне высокой производительностью.
Для большинства приложений и большинства компонентов практически любых приложений EF Core предлагает приемлемый уровень производительности. Таким образом, преимущества в удобстве для разработчика в большинстве случаев перевешивают возможное снижение производительности. Для запросов, эффективность которых может быть повышена за счет кэширования, фактический запрос выполняется крайне редко, в связи с чем эти относительно небольшие различия в производительности обработки запросов теряют значимость.
SQL или NoSQL
Реляционные базы данных, такие как SQL Server, традиционно занимают львиную долю рынка решений для хранения постоянных данных, однако они также не являются единственным решением. Такие базы данных NoSQL, как MongoDB, предлагают другой подход к хранению объектов. Вместо сопоставления объектов с таблицами и строками выполняется сериализация всего графа объектов с сохранением результата. Преимущества такого подхода, как минимум на начальной стадии, заключаются в простоте и производительности. Проще сохранить один сериализованный объект с ключом, чем разложить объект на многие таблицы с связями и обновить строки, которые могли измениться с момента последнего извлечения объекта из базы данных. Аналогичным образом, получение и десериализация одного объекта из основанного на ключах хранилища, как правило, выполняется значительно быстрее и проще, чем сложные объединения или множественные запросы к базе данных, необходимые для полного воссоздания объекта на основе реляционной базы данных. Отсутствие блокировок, транзакций или фиксированной схемы также обеспечивает высокую степень пригодности баз данных NoSQL для масштабирования на множестве компьютеров для поддержки очень крупных наборов данных.
С другой стороны, базы данных NoSQL имеют свои недостатки. Для обеспечения согласованности и предотвращения дублирования данных в реляционных базах данных применяется нормализация. Это позволяет уменьшить общий размер базы данных и гарантировать немедленную доступность обновлений общих данных на уровне всей базы данных. В реляционной базе данных таблица Address может ссылаться на таблицу Country по идентификатору. Таким образом, при изменении названия страны или региона записи адресов будут использовать обновленные данные и не потребуют отдельного обновления. Тем не менее в базе данных NoSQL таблица Address и связанная с ней таблица Country могут быть сериализованы в составе множества хранимых объектов. В таких случаях при изменении названия страны или региона потребуется обновить все такие объекты, а не одну строку. Реляционные базы данных также гарантируют реляционную целостность посредством применения правил, например внешних ключей. Базы данных NoSQL, как правило, не реализуют такие ограничения для данных.
Также с базами данных NoSQL связаны трудности при управлении версиями. При изменении свойств объекта может быть невозможна десериализация объекта на основе хранимых предыдущих версий. Таким образом, все существующие объекты, у которых есть сериализованная (предыдущая) версия, должны быть обновлены в соответствии с новой схемой. Такой подход не имеет принципиальных различий с реляционными базами данных, в которых изменение схемы иногда требует обновления скриптов или сопоставления обновлений. Тем не менее для баз данных NoSQL число изменяемых записей зачастую намного больше из-за большего объема дублированных данных.
В базах данных NoSQL может храниться несколько версий объектов, что в некоторых реляционных базах данных обычно не поддерживается. Однако в данном случае в коде приложения необходимо учитывать существование предыдущих версий объектов, что увеличивает сложность.
В базах данных NoSQL, как правило, не применяется концепция ACID (атомарность, согласованность, изолированность, устойчивость), в связи с чем они превосходят реляционные базы данных в отношении производительности и масштабируемости. Такие базы данных хорошо подходят для очень больших наборов данных и объектов, которые неэффективно хранить в нормализованных табличных структурах. При этом нет никаких ограничений на использование преимуществ как реляционных баз, так и баз данных NoSQL, в рамках одного приложения в тех случаях, где это необходимо.
Azure Cosmos DB (облачная база данных)
Azure Cosmos DB — это полностью управляемая служба баз данных NoSQL, которая предлагает облачное хранилище данных без схемы. Cosmos DB обеспечивает высокую прогнозируемую производительность, высокую доступность, эластичную масштабируемость и возможность глобального распределения. Несмотря на то, что это база данных NoSQL, разработчики могут использовать все хорошо знакомые возможности SQL-запросов к данным JSON. Все ресурсы в Azure Cosmos DB хранятся в виде документов JSON. Ресурсы управляются в виде элементов (документы, содержащие метаданные) и веб-каналов, которые представляют собой коллекции элементов. На рис. 8-2 показаны связи между разными ресурсами Azure Cosmos DB.
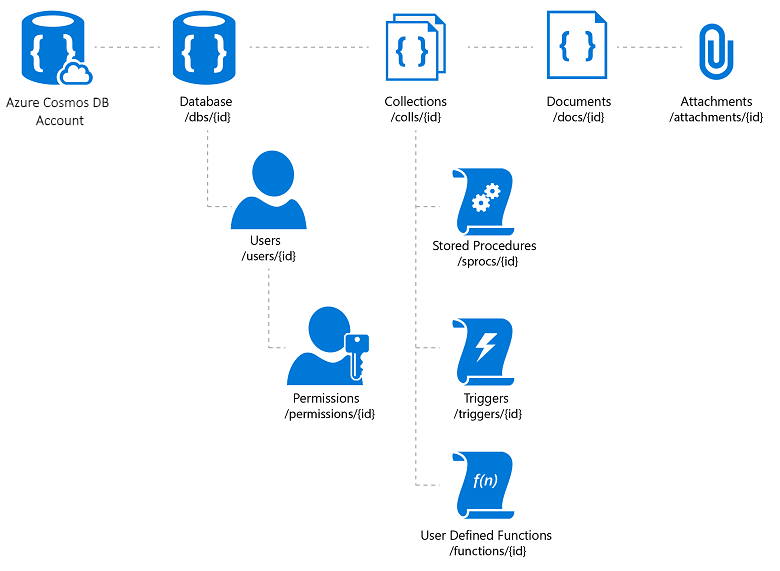
Рис. 8-2. Организация ресурсов Azure Cosmos DB.
Язык запросов Azure Cosmos DB — это простой, но мощный интерфейс для создания запросов документов JSON. Язык поддерживает грамматику подмножества ANSI SQL и добавляет глубокую интеграцию объектов, массивов, создания объектов и вызова функций JavaScript.
Ссылки. Azure Cosmos DB
- Основные сведения об Azure Cosmos DB https://learn.microsoft.com/azure/cosmos-db/introduction
Другие варианты сохраняемости
В дополнение к реляционным и NoSQL вариантам хранения, в приложениях ASP.NET Core можно использовать облачное масштабируемое хранилище Azure для хранения данных и файлов в различных форматах. Хранилище Azure обеспечивает высокую степень масштабируемости, позволяя начать с хранения небольших объемов данных и при необходимости увеличить объем хранилища до сотен терабайт. Хранилище Azure поддерживает четыре вида данных:
Хранилище BLOB-объектов для хранения неструктурированных текстовых или двоичных данных, которое также называется хранилищем объектов.
Хранилище таблиц для структурированных наборов данных, доступных по ключам строк.
Хранилище очередей для надежного обмена сообщениями на основе очередей.
Хранилище файлов для совместного доступа к файлам между виртуальными машинами Azure и локальными приложениями.
Ссылки — хранилище Azure
- Общие сведения о службе хранилища Azure https://learn.microsoft.com/azure/storage/common/storage-introduction
Кэширование
В веб-приложениях каждый веб-запрос должен быть выполнен в максимально короткое время. Одним из способов добиться этого является ограничение числа внешних вызовов, которые сервер должен выполнить для обработки запроса. Процесс кэширования предусматривает сохранение копии данных на сервере (или в другом хранилище данных, запросы к которому выполняются более эффективно по сравнению с источником данных). Веб-приложения, в особенности традиционные многостраничные веб-приложения, для каждого запроса должны осуществлять полное построение пользовательского интерфейса. При этом в пользовательских запросах, следующих друг за другом, часто выполняются одни и те же запросы к базе данных. В большинстве случаев эти данные редко изменяются, поэтому не имеет практического смысла постоянно запрашивать их из базы данных. ASP.NET Core поддерживает кэширование ответов для кэширования страниц целиком, а также кэширование данных, благодаря которому обеспечивается более детальная реализация кэширования.
При реализации кэширования важно учитывать необходимость разделения задач. Рекомендуется избегать кэширования логики в логике доступа к данным или в пользовательском интерфейсе. Вместо этого следует инкапсулировать кэширование в собственных классах и использовать конфигурацию для управления ее поведением. Такой подход соответствует принципам открытости/закрытости и персональной ответственности, позволяя управлять использованием кэширования в приложении по мере его расширения.
Кэширование ответов в ASP.NET Core
ASP.NET Core поддерживает два уровня кэширования ответов. На первом уровне на сервере ничего не кэшируется, однако добавляются заголовки HTTP с инструкциями по кэшированию ответов для клиентов и прокси-серверов. Это реализуется путем добавления атрибута ResponseCache в отдельные контроллеры или действия:
[ResponseCache(Duration = 60)]
public IActionResult Contact()
{
ViewData["Message"] = "Your contact page.";
return View();
}
В предыдущем примере к ответу будет добавлен следующий заголовок, предписывающий клиентам кэшировать результат до 60 секунд.
Cache-Control: public,max-age=60
Чтобы добавить кэширование на стороне сервера в приложение, необходимо ссылаться на Microsoft.AspNetCore.ResponseCaching пакет NuGet, а затем добавить ПО промежуточного слоя кэширования ответа. ПО промежуточного слоя настраивается со службами и другим ПО промежуточного слоя во время запуска приложения:
builder.Services.AddResponseCaching();
// other code omitted, including building the app
app.UseResponseCaching();
ПО промежуточного слоя для кэширования ответов будет автоматически кэшировать ответы на основе набора условий, которые при необходимости можно настроить. По умолчанию кэшируются только ответы 200 (OK) на запросы, выполненные с помощью методов GET или HEAD. Кроме того, запросы должны иметь ответ Cache-Control: открытый заголовок и не могут включать заголовки для Authorization или Set-Cookie. См. полный перечень условий кэширования, применяемых ПО промежуточного уровня для кэширования ответов.
Кэширование данных
Вместо кэширования полных веб-ответов или в дополнение к нему вы можете кэшировать результаты отдельных запросов данных. Для этого вы можете использовать кэширование в памяти на веб-сервере или распределенный кэш. В этом разделе демонстрируется, как реализовать кэширование в памяти.
Добавьте поддержку кэширования памяти (или распределенного) со следующим кодом:
builder.Services.AddMemoryCache();
builder.Services.AddMvc();
Обязательно также добавьте пакет NuGet Microsoft.Extensions.Caching.Memory.
После добавления службы вы выполняете запрос IMemoryCache посредством внедрения зависимостей каждый раз, когда вам требуется доступ к кэшу. В этом примере служба CachedCatalogService использует конструктивный шаблон прокси-сервера (или декоратора), предоставляя альтернативную реализацию ICatalogService, которая управляет доступом к базовой реализации CatalogService или дополняет ее поведение.
public class CachedCatalogService : ICatalogService
{
private readonly IMemoryCache _cache;
private readonly CatalogService _catalogService;
private static readonly string _brandsKey = "brands";
private static readonly string _typesKey = "types";
private static readonly TimeSpan _defaultCacheDuration = TimeSpan.FromSeconds(30);
public CachedCatalogService(
IMemoryCache cache,
CatalogService catalogService)
{
_cache = cache;
_catalogService = catalogService;
}
public async Task<IEnumerable<SelectListItem>> GetBrands()
{
return await _cache.GetOrCreateAsync(_brandsKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetBrands();
});
}
public async Task<Catalog> GetCatalogItems(int pageIndex, int itemsPage, int? brandID, int? typeId)
{
string cacheKey = $"items-{pageIndex}-{itemsPage}-{brandID}-{typeId}";
return await _cache.GetOrCreateAsync(cacheKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetCatalogItems(pageIndex, itemsPage, brandID, typeId);
});
}
public async Task<IEnumerable<SelectListItem>> GetTypes()
{
return await _cache.GetOrCreateAsync(_typesKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetTypes();
});
}
}
Чтобы настроить приложение для использования кэшируемой версии службы, но по-прежнему разрешить службе получать экземпляр CatalogService, который он нуждается в конструкторе, вы добавите следующие строки в Program.cs:
builder.Services.AddMemoryCache();
builder.Services.AddScoped<ICatalogService, CachedCatalogService>();
builder.Services.AddScoped<CatalogService>();
После этого вызовы базы данных для получения данных каталога будут выполняться только один раз в минуту, а не при каждом запросе. В зависимости от объема трафика на сайте это может повлиять на число запросов к базе данных и среднее время загрузки домашней страницы, которое сейчас зависит от всех трех запросов, предоставляемых этой службой.
При использовании кэширования возникает проблема устаревших данных, то есть данных, которые были изменены в источнике, но для которых в кэше хранится устаревшая версия. Самый простой способ устранить эту проблему заключается в сокращении продолжительности кэширования, так как в приложениях с высоким уровнем загрузки увеличение продолжительности кэширования данных дает минимальные преимущества. Рассмотрим страницу, которая выполняет 1 запрос к базе данных, который повторяется 10 раз в секунду. Если эта страница будет кэшироваться 1 раз в минуту, число запросов к базе данных за минуту уменьшится с 600 до 1, то есть на 99,8 %. Если вместо этого задать продолжительность кэширования в 1 час, число запросов сократится на 99,997 %, однако при этом значительно увеличится вероятность получения устаревших данных и их потенциальный "возраст".
Другой подход заключается в упреждающем удалении записей кэша при обновлении данных, которые они содержат. Любую отдельную запись можно удалить по ее ключу:
_cache.Remove(cacheKey);
Если в вашем приложении предоставляются функции обновления кэшируемых записей, вы можете удалять соответствующие записи кэша в коде, который выполняет обновления. В некоторых случаях от конкретного набора данных может зависеть множество различных записей. В таких ситуациях рекомендуется создать зависимости между записями кэша с помощью CancellationChangeToken. Используя CancellationChangeToken, вы можете одновременно завершить срок действия нескольких записей, аннулировав этот маркер.
// configure CancellationToken and add entry to cache
var cts = new CancellationTokenSource();
_cache.Set("cts", cts);
_cache.Set(cacheKey, itemToCache, new CancellationChangeToken(cts.Token));
// elsewhere, expire the cache by cancelling the token\
_cache.Get<CancellationTokenSource>("cts").Cancel();
Кэширование может значительно повысить производительность веб-страниц, которые постоянно запрашивают одни и те же значения из базы данных. Обязательно измеряйте производительность доступа к данным и страниц перед применением кэширования и используйте кэширование только при необходимости. Кэширование потребляет ресурсы памяти веб-сервера и увеличивает сложность приложения, поэтому очень важно не внедрять оптимизацию с помощью этой методики преждевременно.
Получение данных в BlazorWebAssembly приложения
При создании приложений, использующих Blazor Server, можно использовать Entity Framework и другие технологии прямого доступа к данным, как описано выше в этой главе. Однако при создании BlazorWebAssembly приложений, таких как другие платформы SPA, вам потребуется другая стратегия доступа к данным. Как правило, эти приложения обращаются к данным и взаимодействуют с сервером через конечные точки веб-API.
Если данные или операции выполняются с учетом секрета, обязательно ознакомьтесь с разделом о безопасности в предыдущей главе и защитите свои интерфейсы API от несанкционированного доступа.
Вы найдете пример BlazorWebAssembly приложения в справочном приложении eShopOnWeb в проекте BlazorAdmin. Этот проект размещается в веб-проекте eShopOnWeb и позволяет пользователям в группе "Администраторы" управлять элементами в хранилище. Снимок экрана приложения представлен на рисунке 8-3.
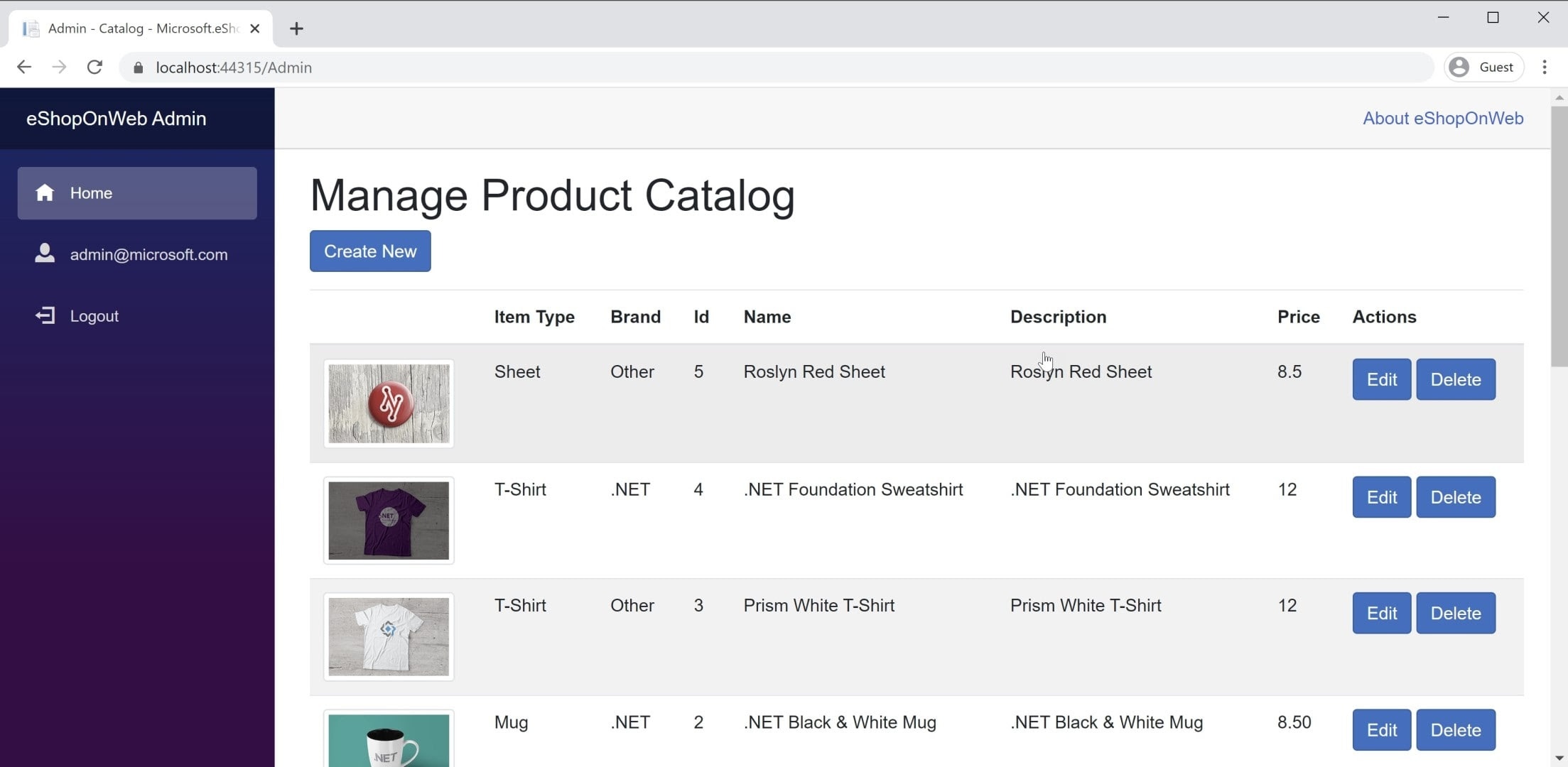
Рис. 8-3. Снимок экрана администратора каталога eShopOnWeb.
При получении данных из веб-API в BlazorWebAssembly приложении вы просто используете экземпляр HttpClient , как и в любом приложении .NET. Основные этапы — создание запроса на отправку (если это необходимо, обычно для запросов POST или PUT), ожидание запроса, проверка кода состояния и десериализация ответа. Если вы собираетесь делать много запросов к определенному набору API, рекомендуется инкапсулировать их и настроить базовый адрес HttpClient. Таким образом, если необходимо изменить любой из этих параметров между средами, можно внести изменения только в одном месте. Необходимо добавить поддержку для этой службы в Program.Main:
builder.Services.AddScoped(sp => new HttpClient
{
BaseAddress = new Uri(builder.HostEnvironment.BaseAddress)
});
Если необходимо безопасно получить доступ к службам, необходимо получить доступ к безопасному маркеру и настроить HttpClient для передачи этого маркера в качестве заголовка проверки подлинности с каждым запросом:
_httpClient.DefaultRequestHeaders.Authorization =
new AuthenticationHeaderValue("Bearer", token);
Это можно сделать из любого компонента, в который внедрен HttpClient, при условии, что HttpClient не был добавлен в службы приложения с временем существования Transient. Каждая ссылка на HttpClient в приложении ссылается на один и тот же экземпляр, поэтому изменения в одном компоненте проходят через все приложение. Хорошим местом для выполнения этой проверки подлинности (а затем указания маркера) является общий компонент, такой как основная навигация по сайту. Дополнительные сведения об этом подходе см. в проекте BlazorAdminэталонного приложения ShopOnWeb.
Одним из BlazorWebAssembly преимуществ традиционных spAs JavaScript является то, что вам не нужно хранить копии объектов передачи данных (DTOs) синхронизированы. Проект BlazorWebAssembly и проект веб-API могут совместно использовать одни и те же объекты DTOs в общем проекте. Это устраняет некоторые проблемы, связанные с разработкой одностраничных приложений.
Чтобы быстро получить данные из конечной точки API, можно использовать встроенный вспомогательный метод GetFromJsonAsync. Существуют аналогичные методы для POST, PUT и т. д. Ниже показано, как получить CatalogItem из конечной точки API с помощью настроенного HttpClientBlazorWebAssembly в приложении:
var item = await _httpClient.GetFromJsonAsync<CatalogItem>($"catalog-items/{id}");
После получения необходимых данных вы обычно отслеживаете изменения локально. Если требуется внести обновления в серверное хранилище данных, вызовите дополнительные веб-API.
Ссылки — данныеBlazor
- Вызов веб-API из ASP.NET Core Blazorhttps://learn.microsoft.com/aspnet/core/blazor/call-web-api
Совместная работа с нами на GitHub
Источник этого содержимого можно найти на GitHub, где также можно создавать и просматривать проблемы и запросы на вытягивание. Дополнительные сведения см. в нашем руководстве для участников.