Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Построитель моделей ML.NET — это интуитивно понятное графическое расширение Visual Studio для создания, обучения и развертывания пользовательских моделей машинного обучения. Оно использует автоматизированное машинное обучение (AutoML) для проверки нескольких разных алгоритмов и параметров машинного обучения, выбирая из них наиболее подходящий для вашего сценария.
Для работы с построителем моделей не нужно быть экспертом в области машинного обучения. Все, что требуется, — это данные и проблема, которую нужно решить. Построитель моделей генерирует код для добавления модели в приложение .NET.

Создание проекта построителя моделей
При первом запуске построителя моделей он запрашивает имя проекта, а затем создает mbconfig файл конфигурации внутри проекта. В файле mbconfig отслеживается все, что вы делаете в Model Builder, что позволяет вам повторно открыть сеанс.
После обучения в файле *.mbconfig будут созданы три файла:
- Model.consumption.cs: этот файл содержит схемы
ModelInputиModelOutput, а также функциюPredict, созданную для использования модели. - Model.training.cs: этот файл содержит обучающий конвейер (преобразования данных, алгоритмы, гиперпараметры алгоритмов), выбранные Model Builder для обучения модели. Этот конвейер можно использовать для повторного обучения модели.
- Model.zip: это сериализованный ZIP-файл, который представляет вашу обученную модель ML.NET.
При создании файла mbconfig вам предлагается указать имя. Это имя применяется к файлам использования, обучения и модели. В этом случае используется имя Model.
Сценарий
Построитель моделей может создавать модели машинного обучения для приложения на основе множества различных сценариев.
Сценарий описывает тип прогноза, который нужно сделать с использованием данных. Например:
- Прогнозирование будущих объемов продаж продуктов на основе исторических данных о продажах.
- Классифицируйте настроения как положительные или отрицательные на основе отзывов клиентов.
- Определите, является ли банковский транзакция мошеннической.
- Маршрутизация отзывов клиентов в правильную команду в вашей компании.
Каждый сценарий сопоставляется с другой задачей машинного обучения, которая включает в себя:
| Задача | Сценарий |
|---|---|
| Двоичная классификация | Классификация данных |
| Классификация по нескольким классам | Классификация данных |
| Классификация изображений | Классификация изображений |
| Классификация текстов | Классификация текстов |
| Регрессия | Прогнозирование значения |
| Рекомендация | Рекомендация |
| Прогнозирование | Прогнозирование |
Например, сценарий для классификации тональностей на положительные или отрицательные относится к задаче классификации двоичных файлов.
Дополнительные сведения о различных задачах Машинного обучения, поддерживаемых ML.NET, см. в статье Задачи машинного обучения в ML.NET.
Выбор подходящего сценария машинного обучения
В построителе моделей необходимо выбрать сценарий. Тип сценария зависит от типа прогноза, который вы пытаетесь сделать.
табличный
Классификация данных
Классификация используется для разбиения данных по категориям.
Пример входных данных
Образец вывода
| SepalLength | SepalWidth | Длина лепестка | Ширина лепестка | Разновидность |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0,2 | setosa |
| Прогнозируемые виды |
|---|
| setosa |
Прогнозирование значения
Прогнозирование значений, которое относится к задачам регрессии, используется для прогнозирования чисел.
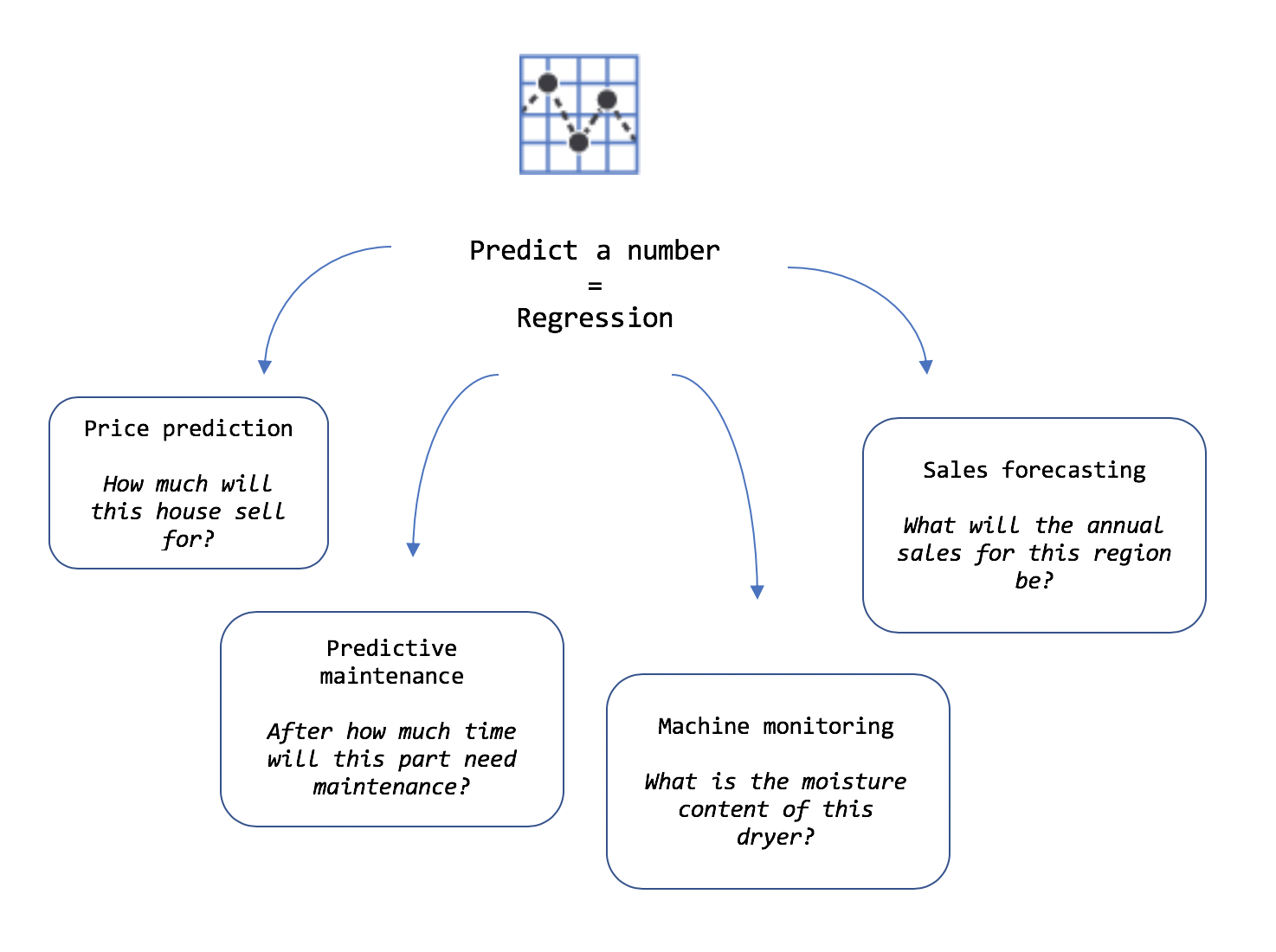
Пример входных данных
Образец вывода
| vendor_id | rate_code | passenger_count | trip_time_in_secs | trip_distance | payment_type | fare_amount |
|---|---|---|---|---|---|---|
| CMT | 1 | 1 | 1271 | 3,8 | CRD | 17,5 |
| Прогнозируемый тариф |
|---|
| 4,5 |
Рекомендация
В сценарии рекомендации прогнозируется список предлагаемых элементов для конкретного пользователя на основе схожести с понравившимися, а также не понравившимися публикациями других пользователей.
Сценарий рекомендаций можно использовать, когда у вас есть набор пользователей и набор "продуктов", таких как элементы для покупки, фильмы, книги или телепередачи, наряду с набором пользовательских "оценок" этих продуктов.
Пример входных данных
Образец вывода
| UserId | ИД продукта | Rating |
|---|---|---|
| 1 | 2 | 4.2 |
| Прогнозируемый рейтинг |
|---|
| 4,5 |
Прогнозирование
Сценарий прогнозирования использует исторические данные с временным рядом или сезонным компонентом.
Вы можете использовать сценарий прогнозирования для прогнозирования спроса или продажи продукта.
Пример входных данных
Образец вывода
| Дата | SaleQty |
|---|---|
| 1/1/1970 | 1000 |
| 3 дня прогноза |
|---|
| [1000,1001,1002] |
Компьютерное зрение
Классификация изображений
Классификация изображений помогает идентифицировать изображения разных категорий. Например, различные виды рельефа, животных или производственного брака.
Вы можете использовать сценарий классификации, если у вас есть набор изображений и вы хотите классифицировать изображения по различным категориям.
Пример входных данных
Образец вывода

| Прогнозируемая метка |
|---|
| Собака |
Обнаружение объектов
Обнаружение объектов используется для поиска и классификации сущностей на изображениях по категориям. Например, на изображениях можно находить и идентифицировать людей и автомобили.
Обнаружение объектов можно использовать, если изображения содержат несколько объектов разных типов.
Пример входных данных
Образец вывода

Обработка естественного языка
Классификация текстов
Классификация текста классифицирует необработанные текстовые входные данные.
Вы можете использовать сценарий классификации текста, если у вас есть набор документов или комментариев, и вы хотите классифицировать их в разные категории.
Пример входных данных
Пример выходных данных
| Отзыв |
|---|
| Мне очень нравится этот стейк! |
| Тональность |
|---|
| Положительные |
Среда
В зависимости от сценария, модель машинного обучения можно обучить локально на компьютере или в облаке в Azure.
При локальном обучении вы работаете в пределах ограничений ресурсов компьютера (ЦП, память и диск). При обучении в облаке ресурсы можно масштабировать в соответствии с потребностями вашего сценария, особенно для больших наборов данных.
| Сценарий | Локально (ЦП) | Локально (GPU) | Azure |
|---|---|---|---|
| Классификация данных | ✔️ | ❌ | ❌ |
| Прогнозирование значения | ✔️ | ❌ | ❌ |
| Рекомендация | ✔️ | ❌ | ❌ |
| Прогнозирование | ✔️ | ❌ | ❌ |
| Классификация изображений | ✔️ | ✔️ | ✔️ |
| Обнаружение объектов | ❌ | ❌ | ✔️ |
| Классификация текстов | ✔️ | ✔️ | ❌ |
Data
После выбора сценария построитель моделей просит предоставить набор данных. Данные используются для обучения, оценки и выбора оптимальной модели для сценария.
Построитель моделей поддерживает наборы данных в форматах баз данных .tsv, .csv, .txt и базы данных SQL. Если у вас есть файл .txt, столбцы должны быть разделены с ,помощью , ;или \t.
При использовании набора данных, состоящего из изображений, поддерживаются файлы с такими расширениями: .jpg и .png.
Дополнительные сведения см. в статье Загрузка данных для обучения в построитель моделей.
Выбор результата для прогнозирования (метка)
Набор данных — это таблица, строки которой содержат образцы для обучения, а столбцы — атрибуты. В каждой строке есть:
- метка (атрибут, который нужно спрогнозировать);
- функции (атрибуты, используемые в качестве входных данных для прогнозирования метки)
В сценарии прогнозирования цен на недвижимость признаками могут быть:
- Квадратные кадры дома.
- Количество спален и ванных комнат.
- Почтовый индекс.
Метка — это историческая цена на дом данной площади, с данным количеством спален и ванных комнат, а также почтовым индексом.
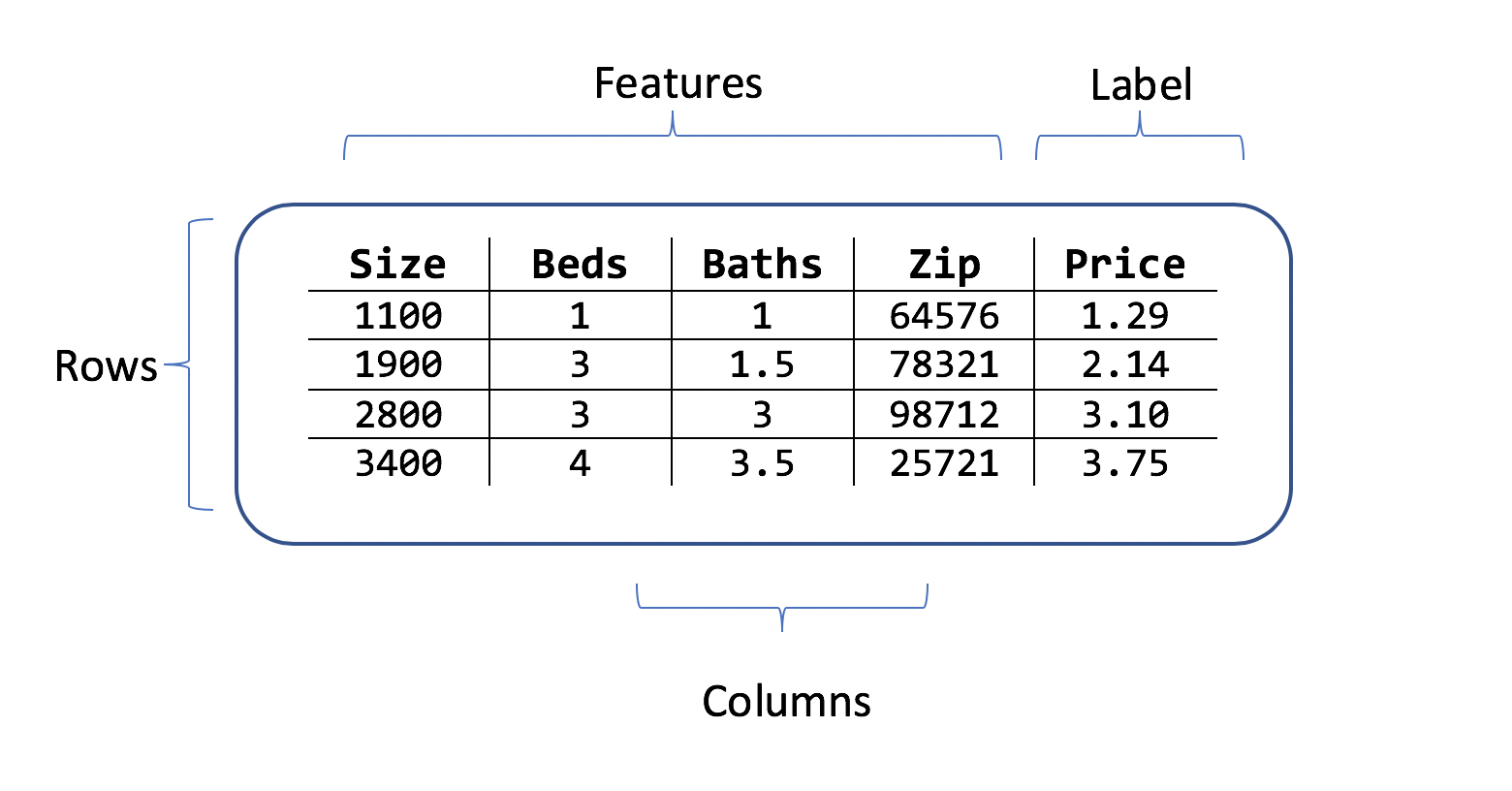
Примеры наборов данных
Если у вас нет собственного набора данных, можно воспользоваться одним из следующих:
| Сценарий | Пример | Data | Этикетка | Функции |
|---|---|---|---|---|
| Классификация | Прогнозирование аномалий продаж | данные по продажам продуктов | Продажи продукта | месяц |
| Прогнозирование тональности комментариев веб-сайта | данные по комментариям на веб-сайте | Метка (1 при отрицательном настроении, 0 при положительном значении) | Комментарий, год | |
| Прогнозирование мошеннических операций с кредитной картой | данные по кредитным картам | Класс (1 — мошенничество, 0 — нет) | Сумма, V1–V28 (анонимизированные признаки) | |
| Прогнозирование типа проблемы в репозитории GitHub | Данные по проблемам на GitHub | Площадь | Название, описание | |
| Прогнозирование значения | Прогнозирование платы за такси | данные по платам за такси | Тариф | Время поездки, расстояние |
| Классификация изображений | Прогнозирование категории, к которой относится цветок | изображения цветов | Вид цветов: маргаритки, одуванчики, розы, подсолнухи, тюльпаны | Данные изображения |
| Рекомендация | Прогнозирование фильмов, которые понравятся пользователям | рейтинги фильмов | пользователи, фильмы | Рейтинги |
Обучение
После выбора сценария, среды, данных и метки Model Builder обучает модель.
Что такое обучение?
Обучение — это автоматический процесс, посредством которого построитель моделей учит модель отвечать на вопросы в рамках сценария. После обучения модель может делать прогнозы на основе новых входных данных. Например, если модель прогнозирует цены на недвижимость и на рынке появляется новый дом, она может спрогнозировать цену его продажи.
Так как построитель моделей использует автоматизированное машинное обучение (AutoML), во время обучения вводить данные или производить настройку не нужно.
Требуемая длительность обучения
С помощью AutoML построитель моделей изучает несколько моделей, определяя самую эффективную.
Более длительное время обучения позволяет AutoML исследовать больше моделей с более широким диапазоном параметров.
В приведенной ниже таблице указано обобщенное среднее время, необходимое для получения хорошей эффективности для набора примеров наборов данных на локальном компьютере.
| Размер набора данных | Среднее время обучения |
|---|---|
| 0–10 МБ | 10 с |
| 10–100 МБ | 10 мин. |
| 100–500 МБ | 30 мин |
| 500 МБ — 1 ГБ | 60 мин |
| Более 1 ГБ | Более 3 часов |
Это ориентировочные числа. Точная продолжительность обучения зависит от:
- Количество функций (столбцов), используемых в качестве входных данных модели.
- Тип столбцов.
- Задача машинного обучения.
- Производительность ЦП, диска и памяти компьютера, используемого для обучения.
Обычно рекомендуется использовать более 100 строк, так как наборы данных меньшего размера могут не дать никаких результатов.
Вычислить
Оценка — это процесс измерения эффективности модели. Построитель моделей использует обученную модель для составления прогнозов на основе новых данных с последующим измерением их точности.
Построитель моделей разделяет обучающие данные на набор для обучения и тестовый набор. Обучающие данные (80 %) служат для обучения модели, а тестовые (20 %) резервируются для ее оценки.
Как определить эффективность модели?
Сценарий сопоставляется с задачей машинного обучения. Каждая задача машинного обучения имеет собственный набор метрик оценки.
Прогнозирование значения
Метрика по умолчанию для проблем прогнозирования значений — RSquared, где допустимо значение в диапазоне от 0 до 1. 1 — наилучшее из возможных значений. Чем ближе значение коэффициента детерминации к 1, тем выше эффективность вашей модели.
Другие метрики, такие как абсолютная потеря, квадратичная потеря и среднеквадратичная потеря, являются дополнительными. Их можно использовать для анализа модели и сравнения ее с другими моделями прогнозирования значений.
Классификация (2 категории)
Метрика по умолчанию для задач классификации — точность. Точность — это доля правильных прогнозов, которые модель делает на основе тестового набора данных. Чем ближе она к 100 % или 1,0, тем лучше.
Чтобы модель считалась приемлемой, другие метрики, например площадь под кривой, которая представляет собой отношение доли истинно положительных результатов к доле ложноположительных результатов, должны превышать 0,50.
Дополнительные метрики, такие как показатель F1, можно использовать для контроля баланса между точностью и полнотой.
Классификация (3 и более категорий)
Метрика по умолчанию для многоклассовой классификации — микроточность. Чем ближе значение микроточности к 100 % или 1,0, тем лучше.
Еще одна важная метрика для многоклассовой классификации — макроточность. Подобно микроточности, чем ближе ее значение к 1,0, тем лучше. Ниже приведены лучшие определения этих двух типов точности:
- Микро-точность: как часто входящий билет классифицируется в правильную команду?
- Макрос-точность: Для средней команды, как часто входящий билет правильный для своей команды?
Дополнительные сведения о метриках оценки
Дополнительные сведения см. в статье Метрики оценки модели.
Улучшение
Если точность модели недостаточно высока, можно сделать следующее:
Увеличить время обучения. Чем дольше длится обучение, тем больше алгоритмов и параметров может опробовать система машинного обучения.
Добавить больше данных. Иногда объем данных недостаточен для обучения высококачественной модели машинного обучения. Это особенно справедливо для наборов данных с небольшим количеством примеров.
Сбалансировать данные. Для задач классификации обучающий набор должен быть сбалансирован по всем категориям. Например, если имеются четыре класса для 100 образцов, причем первые два класса (тег1 и тег2) используются для 90 записей, а другие два (тег3 и тег4) — для остальных 10 записей, несбалансированность данных может сказаться на правильности прогнозирования классов тег3 и тег4.
Потребление
После этапа оценки построитель моделей предоставляет файл модели и код, с помощью которого можно добавить модель в свое приложение. Модели ML.NET сохраняются как ZIP-файлы. Код для загрузки и использования модели добавляется в решение как новый проект. Кроме того, построитель моделей добавляет для примера консольное приложение, которое можно запустить, чтобы увидеть модель в действии.
Кроме того, Model Builder предоставляет возможность создания проектов, использующих вашу модель. Сейчас Model Builder создаст следующие проекты:
- Консольное приложение: создает консольное приложение .NET для прогнозирования из модели.
- Веб-API: создает веб-API ASP.NET Core, который позволяет использовать модель через Интернет.
Дальнейшие действия
Установите расширение Visual Studio для конструктора моделей.
Попробуйте прогнозирование цен или любой сценарий регрессии.
Совместная работа с нами на GitHub
Источник этого содержимого можно найти на GitHub, где также можно создавать и просматривать проблемы и запросы на вытягивание. Дополнительные сведения см. в нашем руководстве для участников.