Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Узнайте, как создать приложение обнаружения аномалий для данных о продажах продуктов. В этом руководстве создается консольное приложение .NET с помощью C# в Visual Studio.
В этом руководстве вы узнаете, как:
- Загрузка данных
- Создайте трансформацию для обнаружения аномалий всплесков
- Обнаружение аномалий пиков с помощью преобразования
- Создание преобразования для обнаружения аномалий точки изменения
- Обнаружение аномалий точки изменения с помощью преобразования
Исходный код для этого руководства можно найти в репозитории dotnet/samples .
Предпосылки
Visual Studio 2022 или более поздней версии с установленной нагрузкой разработки для настольных приложений .NET.
Замечание
Формат product-sales.csv данных основан на наборе данных "Продажи шампуней за три года", первоначально созданном из DataMarket и предоставленном библиотекой данных временных рядов (TSDL), созданной Робом Хайндманом.
"Набор данных «Продажи шампуня в течение трехлетнего периода» лицензирован по лицензии DataMarket Default Open."
Создайте консольное приложение
Создайте консольное приложение C# с именем ProductSalesAnomalyDetection. Нажмите кнопку Далее.
Выберите .NET 8 в качестве платформы для использования. Нажмите кнопку Создать.
Создайте каталог с именем Data в проекте, чтобы сохранить файлы набора данных.
Установите пакет NuGet Microsoft.ML:
Замечание
В этом примере используется последняя стабильная версия упомянутых пакетов NuGet, если не указано иное.
В обозревателе решений щелкните проект правой кнопкой мыши и выберите пункт "Управление пакетами NuGet". Выберите "nuget.org" в качестве источника пакета, перейдите на вкладку "Обзор", найдите Microsoft.ML и выберите "Установить". Нажмите кнопку "ОК " в диалоговом окне "Предварительные изменения" , а затем нажмите кнопку "Принять" в диалоговом окне принятия лицензий, если вы согласны с условиями лицензии для перечисленных пакетов. Повторите эти действия для Microsoft.ML.TimeSeries.
Добавьте следующие
usingдирективы в верхней части файла Program.cs :using Microsoft.ML; using ProductSalesAnomalyDetection;
Скачайте свои данные
Скачайте набор данных и сохраните его в ранее созданной папке данных :
Щелкните правой кнопкой мыши product-sales.csv и выберите "Сохранить ссылку (или цель) как..."
Убедитесь, что файл *.csv сохранен в папке данных или после сохранения в другом месте, переместите файл *.csv в папку данных .
В обозревателе решений щелкните правой кнопкой мыши файл *.csv и выберите "Свойства". В разделе "Дополнительно" измените значение Копировать в выходной каталог на Копировать, если новее.
Следующая таблица — это предварительная версия данных из файла *.csv:
| Месяц | ProductSales |
|---|---|
| 1-январь | 271 |
| 2-январь | 150.9 |
| ..... | ..... |
| 1-февраль | 199.3 |
| ..... | ..... |
Создание классов и определение путей
Затем определите структуры данных входных и прогнозирующих классов.
Добавьте новый класс в проект:
В обозревателе решений щелкните проект правой кнопкой мыши и выберите пункт "Добавить > новый элемент".
В диалоговом окне "Добавление нового элемента" выберите класс и измените поле "Имя " на ProductSalesData.cs. Затем нажмите кнопку "Добавить".
Файл ProductSalesData.cs откроется в редакторе кода.
Добавьте следующую
usingдирективу в начало ProductSalesData.cs:using Microsoft.ML.Data;Удалите существующее определение класса и добавьте следующий код, имеющий два класса
ProductSalesDataиProductSalesPredictionфайл ProductSalesData.cs :public class ProductSalesData { [LoadColumn(0)] public string? Month; [LoadColumn(1)] public float numSales; } public class ProductSalesPrediction { //vector to hold alert,score,p-value values [VectorType(3)] public double[]? Prediction { get; set; } }ProductSalesDataуказывает входной класс данных. Атрибут LoadColumn указывает, какие столбцы (по индексу столбца) в наборе данных должны быть загружены.ProductSalesPredictionзадает класс данных прогнозирования. Для обнаружения аномалий прогноз состоит из оповещения, указывающего, существует ли аномалия, необработанный показатель и p-значение. Чем ближе p-значение равно 0, тем более вероятно, произошла аномалия.Создайте два глобальных поля для хранения недавно скачаемого пути к файлу набора данных и сохраненного пути к файлу модели:
-
_dataPathимеет путь к набору данных, используемому для обучения модели. -
_docsizeсодержит количество записей в файле набора данных. Вы будете использовать_docSizeдля вычисленияpvalueHistoryLength.
-
Добавьте следующий код в строку справа от
usingдиректив, чтобы указать эти пути:string _dataPath = Path.Combine(Environment.CurrentDirectory, "Data", "product-sales.csv"); //assign the Number of records in dataset file to constant variable const int _docsize = 36;
Инициализация переменных
Замените
Console.WriteLine("Hello World!")строку следующим кодом, чтобы объявить и инициализироватьmlContextпеременную:MLContext mlContext = new MLContext();Класс MLContext — это отправная точка для всех операций ML.NET, и инициализация
mlContextсоздает новую среду ML.NET, которую можно совместно использовать для объектов рабочего процесса создания модели. Это концептуально похоже наDBContextв Entity Framework.
Загрузка данных
Данные в ML.NET представлены в виде интерфейса IDataView.
IDataView — это гибкий, эффективный способ описания табличных данных (числовых и текстовых данных). Данные можно загрузить из текстового файла или из других источников (например, базы данных SQL или файлов журналов) в IDataView объект.
Добавьте следующий код после создания переменной
mlContext:IDataView dataView = mlContext.Data.LoadFromTextFile<ProductSalesData>(path: _dataPath, hasHeader: true, separatorChar: ',');LoadFromTextFile() определяет схему данных и считывает его в файле. Он принимает переменные пути к данным и возвращает значение
IDataView.
Обнаружение аномалий временных рядов
Флаги обнаружения аномалий непредвиденного или необычного события или поведения. Он дает подсказки, где искать проблемы и помогает ответить на вопрос "Это странно?".

Обнаружение аномалий — это процесс обнаружения вылитых данных временных рядов; указывает на заданный временный ряд входных данных, где поведение не является ожидаемым или "странным".
Обнаружение аномалий может быть полезно во многих отношениях. Например:
Если у вас есть автомобиль, вам может захотеться узнать: нормально ли показывает датчик уровня масла, или у меня утечка? Если вы отслеживаете потребление электроэнергии, вы хотите знать: Есть ли сбой?
Существует два типа аномалий временных рядов, которые можно обнаружить:
Пики указывают на временные всплески аномального поведения в системе.
Точки изменения указывают на начало постоянных изменений с течением времени в системе.
В ML.NET алгоритмы обнаружения выбросов IID или точек изменения IID подходят для независимых и одинаково распределенных наборов данных. Предполагается, что входные данные представляют собой последовательность точек данных, которые независимо отбираются из одного стационарного распределения.
В отличие от моделей в других руководствах, детектор аномалий временных рядов осуществляет преобразования непосредственно на входных данных. Метод IEstimator.Fit() не нуждается в обучающих данных для создания преобразования. Однако для нее требуется схема данных, которая предоставляется представлением данных, созданным из пустого ProductSalesDataсписка.
Вы проанализируете одни и те же данные о продажах продуктов, чтобы обнаружить пики и точки изменения. Процесс построения и обучения модели совпадает с обнаружением пиковых точек и обнаружением точек изменения; Основное отличие — это конкретный алгоритм обнаружения, используемый.
Обнаружение пиков
Цель обнаружения пиков заключается в выявлении внезапных временных всплесков, которые значительно отличаются от большинства значений данных временных рядов. Важно своевременно обнаружить эти подозрительные редкие элементы, события или наблюдения, чтобы свести их к минимуму. Следующий подход можно использовать для обнаружения различных аномалий, таких как сбои, кибератаки или вирусное веб-содержимое. На следующем рисунке показан пример пиков в наборе данных временных рядов:
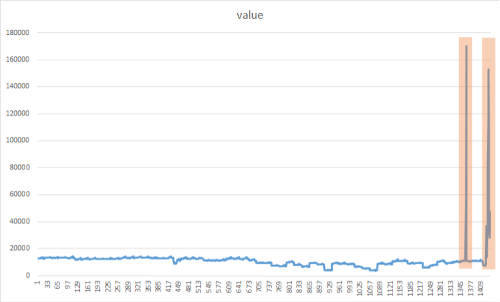
Добавление метода CreateEmptyDataView()
Добавьте следующий метод Program.cs:
IDataView CreateEmptyDataView(MLContext mlContext) {
// Create empty DataView. We just need the schema to call Fit() for the time series transforms
IEnumerable<ProductSalesData> enumerableData = new List<ProductSalesData>();
return mlContext.Data.LoadFromEnumerable(enumerableData);
}
Создает CreateEmptyDataView() пустой объект представления данных с правильной схемой, которая будет использоваться в качестве входных данных метода IEstimator.Fit() .
Создание метода DetectSpike()
Метод DetectSpike():
- Создает преобразование из оценщика.
- Обнаруживает пики на основе исторических данных о продажах.
- Отображает результаты.
DetectSpike()Создайте метод в нижней части файла Program.cs с помощью следующего кода:DetectSpike(MLContext mlContext, int docSize, IDataView productSales) { }Используйте метод IidSpikeEstimator для обучения модели для обнаружения пиков. Добавьте его в
DetectSpike()метод со следующим кодом:var iidSpikeEstimator = mlContext.Transforms.DetectIidSpike(outputColumnName: nameof(ProductSalesPrediction.Prediction), inputColumnName: nameof(ProductSalesData.numSales), confidence: 95d, pvalueHistoryLength: docSize / 4);Создайте преобразование обнаружения пиков, добавив следующую строку кода в
DetectSpike()методе:Подсказка
confidenceИpvalueHistoryLengthпараметры влияют на обнаружение пиков.confidenceопределяет, насколько чувствительна модель к пикам. Чем ниже достоверность, тем более вероятно, что алгоритм будет обнаруживать "меньшие" пики. ПараметрpvalueHistoryLengthопределяет количество точек данных в скользящем окне. Значение этого параметра обычно является процентом всего набора данных. Чем нижеpvalueHistoryLength, тем быстрее модель забывает предыдущие большие пики.ITransformer iidSpikeTransform = iidSpikeEstimator.Fit(CreateEmptyDataView(mlContext));Добавьте следующую строку кода для преобразования
productSalesданных в следующую строку методаDetectSpike():IDataView transformedData = iidSpikeTransform.Transform(productSales);Предыдущий код использует метод Transform() для прогнозирования для нескольких входных строк набора данных.
Преобразуйте объект
transformedDataв строго типизированныйIEnumerableдля упрощения отображения с помощью метода CreateEnumerable() со следующим кодом:var predictions = mlContext.Data.CreateEnumerable<ProductSalesPrediction>(transformedData, reuseRowObject: false);Создайте строку заголовка отображения с помощью следующего Console.WriteLine() кода:
Console.WriteLine("Alert\tScore\tP-Value");В результатах обнаружения пиков вы увидите следующие сведения:
-
Alertуказывает оповещение о пике для заданной точки данных. -
ScoreProductSales— значение заданной точки данных в наборе данных. -
P-Value"P" означает вероятность. Чем ближе p-значение равно 0, тем более вероятно, что точка данных является аномалией.
-
Используйте следующий код, чтобы выполнить итерацию
predictionsIEnumerableи отобразить результаты:foreach (var p in predictions) { if (p.Prediction is not null) { var results = $"{p.Prediction[0]}\t{p.Prediction[1]:f2}\t{p.Prediction[2]:F2}"; if (p.Prediction[0] == 1) { results += " <-- Spike detected"; } Console.WriteLine(results); } } Console.WriteLine("");Добавьте вызов
DetectSpike()к методу под вызовомLoadFromTextFile()метода:DetectSpike(mlContext, _docsize, dataView);
Результаты обнаружения пиков
Ваши результаты должны быть похожи на следующие. Во время обработки отображаются сообщения. Вы можете видеть предупреждения или обрабатывать сообщения. Некоторые сообщения были удалены из следующих результатов для ясности.
Detect temporary changes in pattern
=============== Training the model ===============
=============== End of training process ===============
Alert Score P-Value
0 271.00 0.50
0 150.90 0.00
0 188.10 0.41
0 124.30 0.13
0 185.30 0.47
0 173.50 0.47
0 236.80 0.19
0 229.50 0.27
0 197.80 0.48
0 127.90 0.13
1 341.50 0.00 <-- Spike detected
0 190.90 0.48
0 199.30 0.48
0 154.50 0.24
0 215.10 0.42
0 278.30 0.19
0 196.40 0.43
0 292.00 0.17
0 231.00 0.45
0 308.60 0.18
0 294.90 0.19
1 426.60 0.00 <-- Spike detected
0 269.50 0.47
0 347.30 0.21
0 344.70 0.27
0 445.40 0.06
0 320.90 0.49
0 444.30 0.12
0 406.30 0.29
0 442.40 0.21
1 580.50 0.00 <-- Spike detected
0 412.60 0.45
1 687.00 0.01 <-- Spike detected
0 480.30 0.40
0 586.30 0.20
0 651.90 0.14
Обнаружение точек изменения
Change points представляют собой постоянные изменения в распределении значений потоков событий временных рядов, таких как изменения уровня и тенденции. Эти постоянные изменения длились гораздо дольше, чем spikes и могут указывать на катастрофические события.
Change points обычно не видны невооруженным глазом, но их можно обнаружить в ваших данных, используя подобные подходы, как в следующем методе. На следующем рисунке показан пример обнаружения точки изменения.
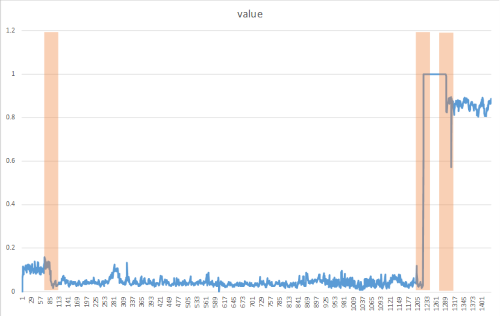
Создание метода DetectChangepoint()
Метод DetectChangepoint() выполняет следующие задачи:
- Создает преобразование из оценщика.
- Обнаруживает точки изменения на основе исторических данных о продажах.
- Отображает результаты.
DetectChangepoint()Создайте метод сразу после объявления метода с помощью следующегоDetectSpike()кода:void DetectChangepoint(MLContext mlContext, int docSize, IDataView productSales) { }Создайте в методе
DetectChangepoint()со следующим кодом:var iidChangePointEstimator = mlContext.Transforms.DetectIidChangePoint(outputColumnName: nameof(ProductSalesPrediction.Prediction), inputColumnName: nameof(ProductSalesData.numSales), confidence: 95d, changeHistoryLength: docSize / 4);Как и ранее, создайте преобразование из оценщика, добавив следующую строку кода в
DetectChangePoint()метод:Подсказка
Обнаружение точек изменений происходит с небольшой задержкой, так как модель должна убедиться, что текущее отклонение является постоянным изменением, а не только некоторыми случайными пиками перед созданием оповещения. Сумма этой задержки равна параметру
changeHistoryLength. Увеличив значение этого параметра, оповещения об обнаружении изменений при более постоянных изменениях, но компромисс будет более длительным.var iidChangePointTransform = iidChangePointEstimator.Fit(CreateEmptyDataView(mlContext));Transform()Используйте метод для преобразования данных, добавив следующий кодDetectChangePoint()в:IDataView transformedData = iidChangePointTransform.Transform(productSales);Как и ранее, преобразуйте приложение
transformedDataв строго типизированныйIEnumerableдля упрощения отображения с помощьюCreateEnumerable()метода со следующим кодом:var predictions = mlContext.Data.CreateEnumerable<ProductSalesPrediction>(transformedData, reuseRowObject: false);Создайте заголовок отображения с помощью следующего кода в следующей строке метода
DetectChangePoint().Console.WriteLine("Alert\tScore\tP-Value\tMartingale value");В результатах обнаружения точек изменения отображаются следующие сведения:
-
Alertуказывает оповещение о точке изменения для заданного значения данных. -
ScoreProductSales— значение заданной точки данных в наборе данных. -
P-Value"P" означает вероятность. Чем ближе P-значение равно 0, тем более вероятно, что точка данных является аномалией. -
Martingale valueиспользуется для определения того, как "странная" точка данных основана на последовательности P-значений.
-
Выполните итерацию
predictionsIEnumerableи отображение результатов с помощью следующего кода:foreach (var p in predictions) { if (p.Prediction is not null) { var results = $"{p.Prediction[0]}\t{p.Prediction[1]:f2}\t{p.Prediction[2]:F2}\t{p.Prediction[3]:F2}"; if (p.Prediction[0] == 1) { results += " <-- alert is on, predicted changepoint"; } Console.WriteLine(results); } } Console.WriteLine("");Добавьте следующий вызов метода
DetectChangepoint()после вызова методаDetectSpike().DetectChangepoint(mlContext, _docsize, dataView);
Результаты обнаружения точек изменения
Ваши результаты должны быть похожи на следующие. Во время обработки отображаются сообщения. Вы можете видеть предупреждения или обрабатывать сообщения. Некоторые сообщения были удалены из следующих результатов для ясности.
Detect Persistent changes in pattern
=============== Training the model Using Change Point Detection Algorithm===============
=============== End of training process ===============
Alert Score P-Value Martingale value
0 271.00 0.50 0.00
0 150.90 0.00 2.33
0 188.10 0.41 2.80
0 124.30 0.13 9.16
0 185.30 0.47 9.77
0 173.50 0.47 10.41
0 236.80 0.19 24.46
0 229.50 0.27 42.38
1 197.80 0.48 44.23 <-- alert is on, predicted changepoint
0 127.90 0.13 145.25
0 341.50 0.00 0.01
0 190.90 0.48 0.01
0 199.30 0.48 0.00
0 154.50 0.24 0.00
0 215.10 0.42 0.00
0 278.30 0.19 0.00
0 196.40 0.43 0.00
0 292.00 0.17 0.01
0 231.00 0.45 0.00
0 308.60 0.18 0.00
0 294.90 0.19 0.00
0 426.60 0.00 0.00
0 269.50 0.47 0.00
0 347.30 0.21 0.00
0 344.70 0.27 0.00
0 445.40 0.06 0.02
0 320.90 0.49 0.01
0 444.30 0.12 0.02
0 406.30 0.29 0.01
0 442.40 0.21 0.01
0 580.50 0.00 0.01
0 412.60 0.45 0.01
0 687.00 0.01 0.12
0 480.30 0.40 0.08
0 586.30 0.20 0.03
0 651.90 0.14 0.09
Поздравляю! Теперь вы успешно создали модели машинного обучения для обнаружения пиков и аномалий точки изменения в данных о продажах.
Исходный код для этого руководства можно найти в репозитории dotnet/samples .
Из этого руководства вы узнали, как:
- Загрузка данных
- Обучение модели для обнаружения пиковых аномалий
- Обнаружение аномалий пиков с помощью обученной модели
- Обучение модели для обнаружения аномалий точки изменения
- Обнаружение аномалий точки изменения с помощью обученного режима
Дальнейшие шаги
Ознакомьтесь с примерами в репозитории GitHub по машинному обучению, чтобы изучить образец обнаружения аномалий в данных о сезонности.
Совместная работа с нами на GitHub
Источник этого содержимого можно найти на GitHub, где также можно создавать и просматривать проблемы и запросы на вытягивание. Дополнительные сведения см. в нашем руководстве для участников.