Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Узнайте, как с помощью ML.NET CLI автоматически создать модель ML.NET и базовый код C#. Вы предоставите набор данных и задачу машинного обучения, которую требуется реализовать, а CLI с помощью подсистемы AutoML создаст исходный код для формирования и развертывания модели, а также модель классификации.
Работая с этим учебником, вы выполните следующие действия:
- подготовку данных для выбранной задачи машинного обучения;
- запуск команды mlnet classification из CLI;
- просмотреть результаты показателей качества;
- изучение созданного кода C# для использования модели в приложении;
- анализ созданного кода C#, который использовался для обучения модели.
Примечание
Здесь описано, как использовать средство ML.NET CLI, которое сейчас доступно в режиме предварительной версии. Этот материал может быть изменен. Дополнительные сведения см. на странице ML.NET.
ML.NET CLI входит в состав ML.NET, и его основной целью является упрощение изучения ML.NET для разработчиков .NET, поэтому, чтобы приступить к работе, не нужно писать код с нуля.
Для создания качественных моделей и исходного кода ML.NET на основе предоставляемых наборов обучающих данных средство ML.NET CLI можно запускать в любой командной строке (Windows, Mac или Linux).
Предварительные требования
- Пакет SDK для .NET Core 6 или более поздней версии
- (Необязательно) Visual Studio
- ML.NET CLI
Вы можете запускать проекты, написанные на C#, из Visual Studio или с помощью dotnet run (.NET CLI).
подготавливать данные;
Мы будем работать с существующим набором данных, используемым в сценарии "Анализ тональности", который представляет собой задачу машинного обучения двоичной классификации. Вы точно так же можете использовать собственный набор данных, а модель и код будут созданы автоматически.
Скачайте ZIP-файл набора данных предложений с меткой тональности UCI (ссылка дана в следующем примечании) и распакуйте его в любую папку.
Примечание
Наборы данных в этом руководстве взяты из документа From Group to Individual Labels using Deep Features ("От групповых до индивидуальных меток с использованием функций глубокого обучения"), Котциас (Kotzias) и KDD 2015, и размещены в репозитории машинного обучения UCI Д. Дуа (D. Dua) и Э. Карра Танискиду (E. Karra Taniskidou) (2017). UCI Machine Learning Repository (Репозиторий машинного обучения UCI) [http://archive.ics.uci.edu/ml ]. Ирвайн, Калифорния: Калифорнийский университет, Школа информационных технологий и компьютерных наук.
Скопируйте файл
yelp_labelled.txtв созданную ранее папку (например,/cli-test).Откройте предпочитаемую командную строку и перейдите к папке, куда был скопирован файл набора данных. Пример:
cd /cli-testИспользуйте любой текстовый редактор, например Visual Studio Code, чтобы открыть и проанализировать файл набора данных
yelp_labelled.txt. Вы увидите следующую структуру:У файла нет заголовка. Вы будете использовать индекс столбца.
Существует только два столбца:
Текст (индекс столбца — 0) Надпись (индекс столбца — 1) Ого... Отличное место. 1 Корочка так себе. 0 Невкусно, и текстура просто отвратительна. 0 …ЕЩЕ БОЛЬШЕ СТРОК ТЕКСТА… …(1 или 0)…
Закройте файл набора данных в редакторе.
Теперь вы готовы использовать CLI в сценарии "Анализ тональности".
Примечание
После завершения работы с этим руководством попробуйте применить собственные наборы данных, при условии что они подходят для любой задачи машинного обучения, поддерживаемой в предварительной версии ML.NET CLI, — "Двоичная классификация", "Классификация", "Регрессия" и "Рекомендация" .
Выполнение команды mlnet classification
Выполните следующую команду ML.NET CLI:
mlnet classification --dataset "yelp_labelled.txt" --label-col 1 --has-header false --train-time 10Эта команда запускает
mlnet classificationкоманду:- для задачи машинного обученияклассификации;
- использует файл набора данных
yelp_labelled.txtв качестве обучающего и тестового набора данных (CLI внутренним образом применит перекрестную проверку или разделит его на два набора данных — один для обучения и один для тестирования); - где целевой столбец (обычно называемый меткой), который нужно спрогнозировать представляет собой столбец с индексом 1 (то есть второй столбец, поскольку индекс отсчитывается от нуля);
- не использует заголовок файла с именами столбцов, так как у этого конкретного файла набора данных нет заголовка;
- целевое время изучения или обучения в эксперименте составляет 10 секунд.
Вы увидите выходные данные CLI, аналогичные следующим:
В данном случае, когда у средства CLI было всего 10 секунд и небольшой набор данных, ему удалось выполнить довольно много итераций, то есть провести обучение несколько раз на основе сочетаний различных алгоритмов или конфигурации с преобразованиями различных внутренних данных и гиперпараметров алгоритма.
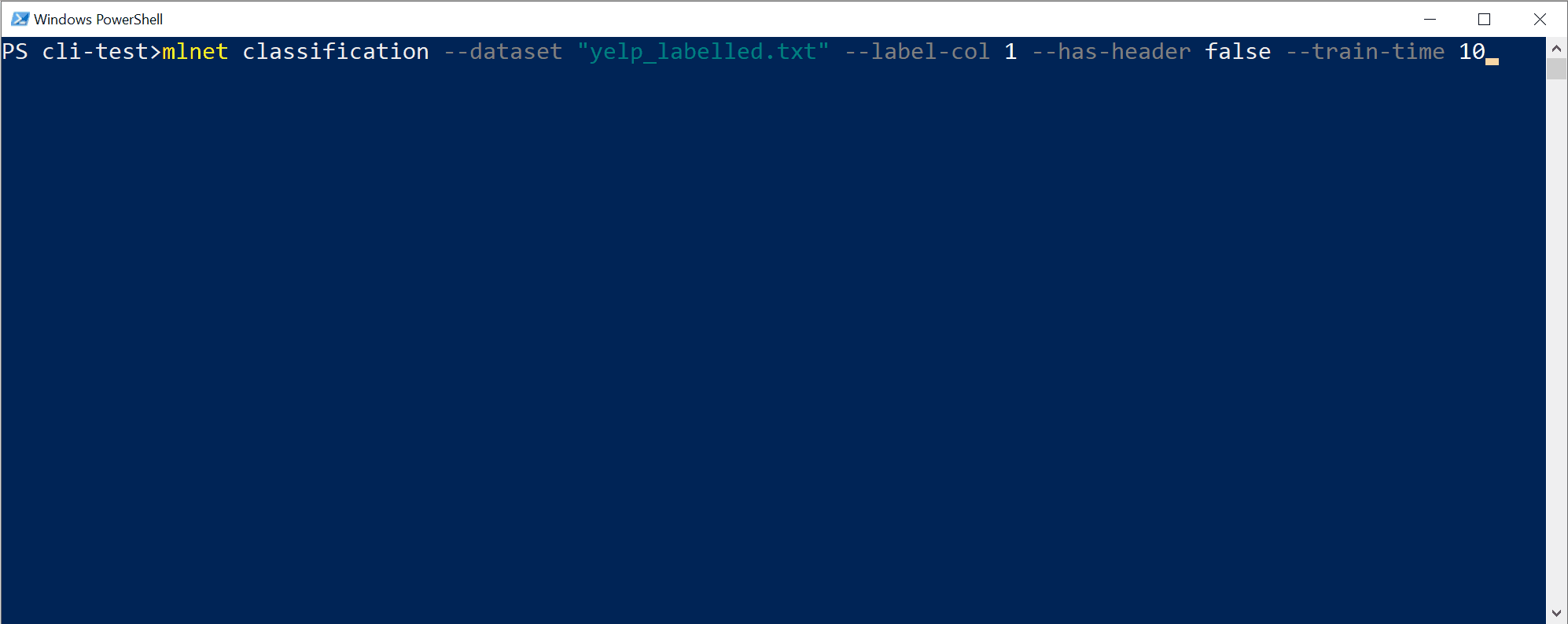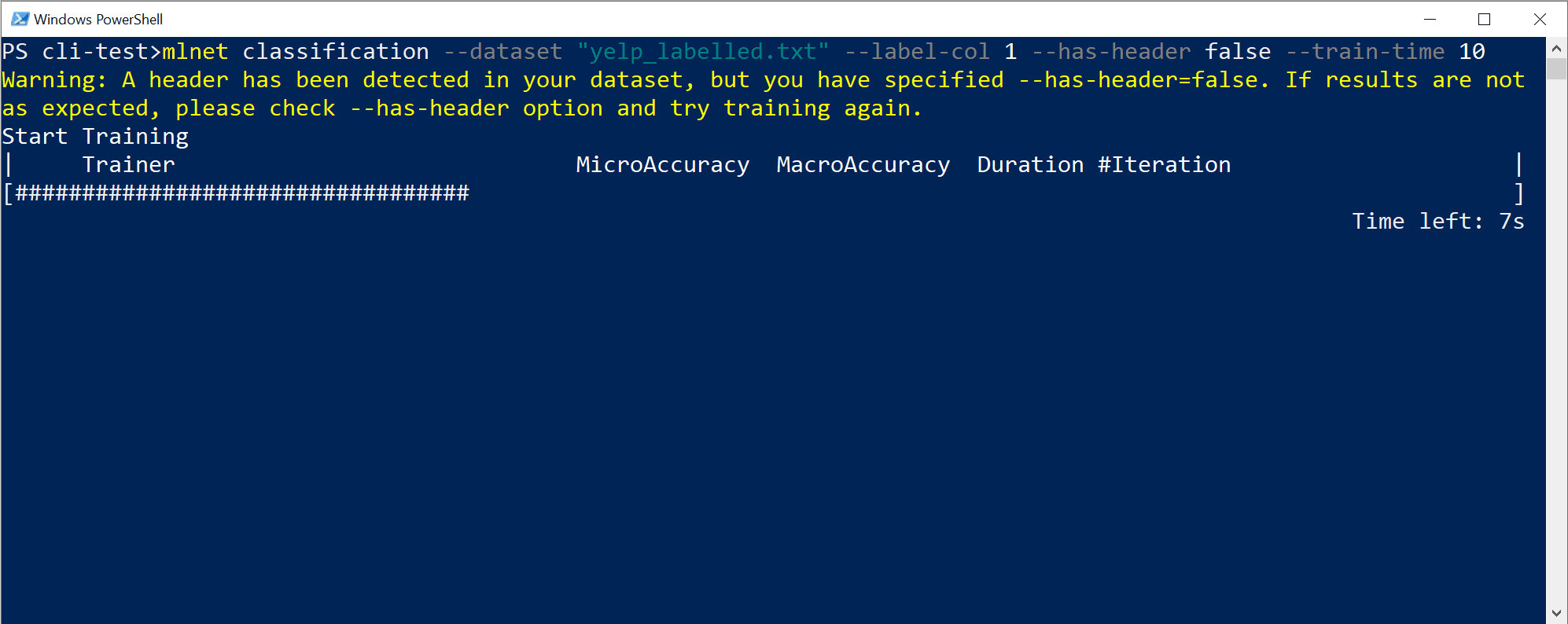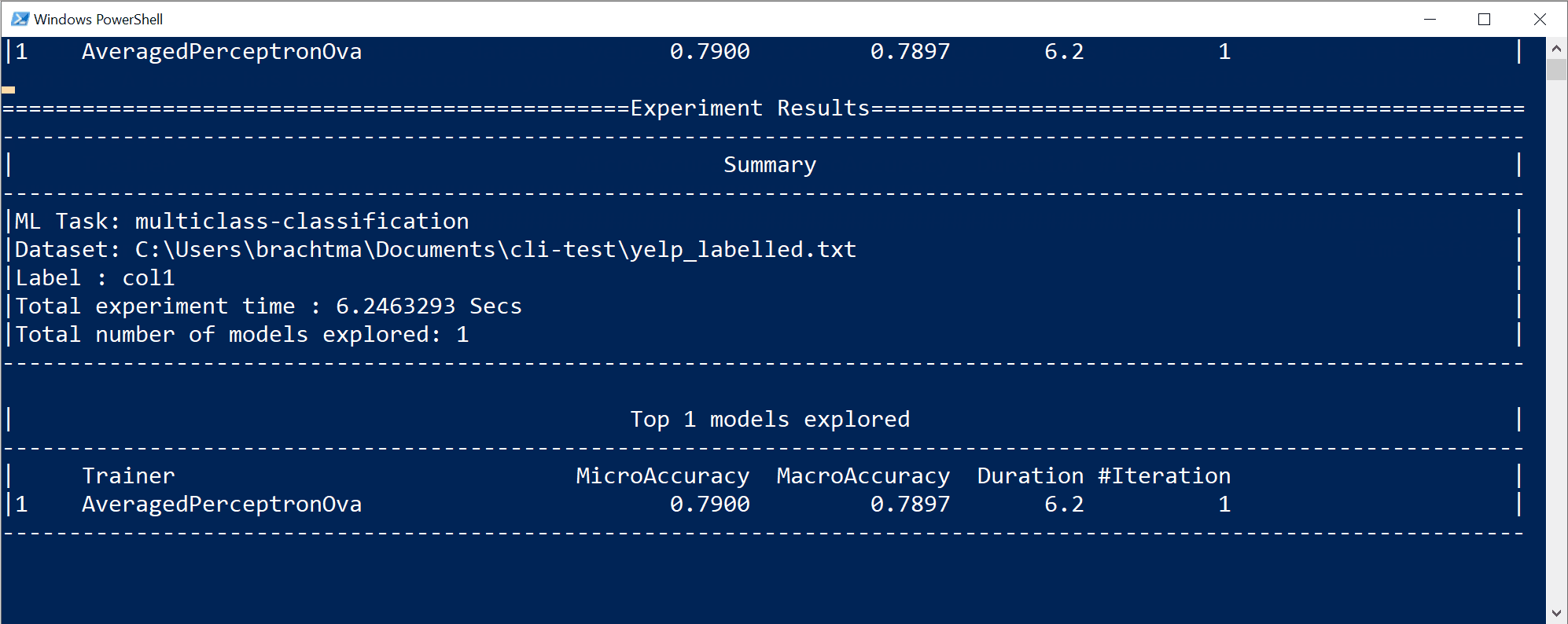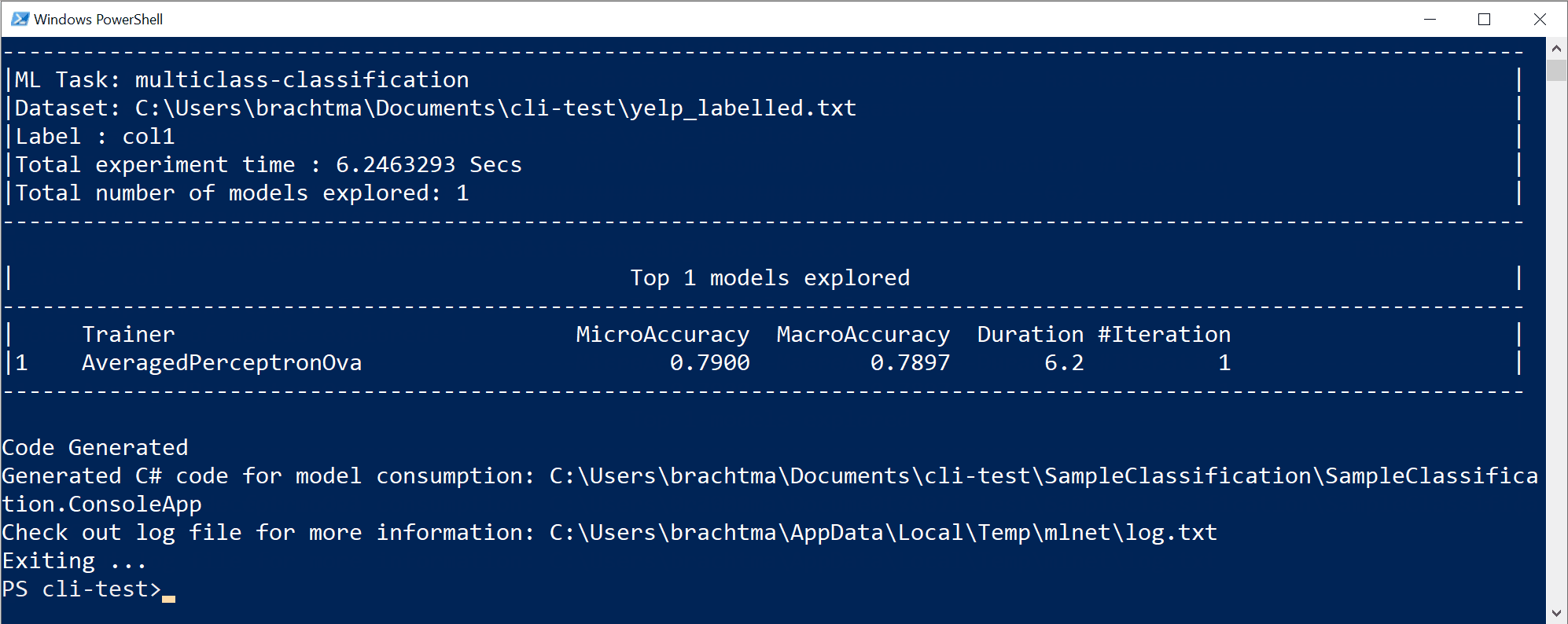
В итоге за 10 секунд найдена модель высшего качества с определенным алгоритмом обучения и конкретной конфигурацией. В зависимости от времени изучения команда может выдать другой результат. Выбор производится с учетом нескольких отображаемых метрик, таких как
Accuracy.Общие сведения о метриках качества модели
Первая и самая простая для понимания метрика оценки модели двоичной классификации — точность. "Точность — это доля правильных прогнозов на основе тестового набора данных". Чем ближе к 100 % (1,00), тем лучше.
Однако бывают случаи, когда оценки с помощью одной метрики точности недостаточно, особенно если метка (0 и 1 в данном случае) несбалансирована в тестовом наборе данных.
Примечание
Можно взять этот же набор данных и указать для
--max-exploration-timeнесколько минут (например, три минуты или 180 секунд), и в результате вы получите модель еще лучшего качества с другой конфигурацией обучающего конвейера для этого набора данных (размером 1000 строк).Чтобы найти готовую для работы модель высшего или хорошего качества, предназначенную для крупных наборов данных, необходимо проводить эксперименты с помощью CLI, указывая более продолжительное время изучения в зависимости от размера набора данных. На самом деле во многих случаях может потребоваться несколько часов, особенно если речь идет о наборе данных с большим числом строк и столбцов.
В результате выполнения предыдущей команды создаются следующие активы:
- готовый к использованию ZIP-файл сериализованной модели ("модели высшего качества");
- код C# для запуска или оценки созданной модели (для прогнозирования в приложениях пользователей);
- обучающий код C#, используемый для создания этой модели (в целях обучения);
- файл журнала со всеми изученными итерациями, содержащими подробные сведения о каждом опробованном алгоритме с сочетанием его гиперпараметров и преобразований данных.
Первые два актива (ZIP-файл модели и код C# для запуска этой модели) можно использовать непосредственно в приложениях конечных пользователей (веб-приложениях и службах ASP.NET Core, классических приложениях и т. д.) для прогнозирования с помощью созданной модели машинного обучения.
Третий актив, обучающий код, показывает, какой код ML.NET API использовало средство CLI для обучения созданной модели, поэтому можно определить, какой конкретный алгоритм обучения и гиперпараметры были выбраны средством CLI.
Эти активы ресурсы рассматриваются в следующих шагах руководства.
Изучение созданного кода C# для запуска модели прогнозирования
В Visual Studio откройте решение, созданное в папке с именем
SampleClassificationв исходной конечной папке (оно было названо/cli-testв учебнике). Вы увидите решение, аналогичное следующему:
Примечание
В этом руководстве мы рекомендуем использовать Visual Studio, но вы также можете изучить созданный код C# (два проекта) в любом текстовом редакторе и запустить созданное консольное приложение с на компьютере macOS
dotnet CLI, Linux или Windows.- Созданное консольное приложение содержит код выполнения, который нужно проверить, после чего можно многократно использовать код оценки (код, который запускает модель машинного обучения для прогнозирования), перемещая этот простой код (всего несколько строк) в приложения конечных пользователей для прогнозирования.
- Созданный mbconfig-файл — это файл конфигурации, который можно использовать для повторного обучения модели с помощью ИНТЕРФЕЙСА командной строки или Конструктора моделей. С ним также будут связаны два файла кода и ZIP-файл.
- Файл обучения содержит код для построения конвейера модели с помощью API ML.NET.
- Файл потребления содержит код для использования модели.
- ZIP-файл, который является моделью, созданной из интерфейса командной строки.
Откройте файл SampleClassification.consumption.cs в файле mbconfig . Вы увидите, что есть входные и выходные классы. Это классы данных или классы POCO, используемые для хранения данных. Классы содержат стандартный код, который полезен, если набор данных содержит десятки или даже сотни столбцов.
- Класс
ModelInputиспользуется при чтении данных из набора данных. - Класс
ModelOutputиспользуется для получения результата прогнозирования (данные прогнозирования).
- Класс
Откройте файл Program.cs и изучите код. С помощью всего нескольких строк вы сможете запустить модель и создать пример прогноза.
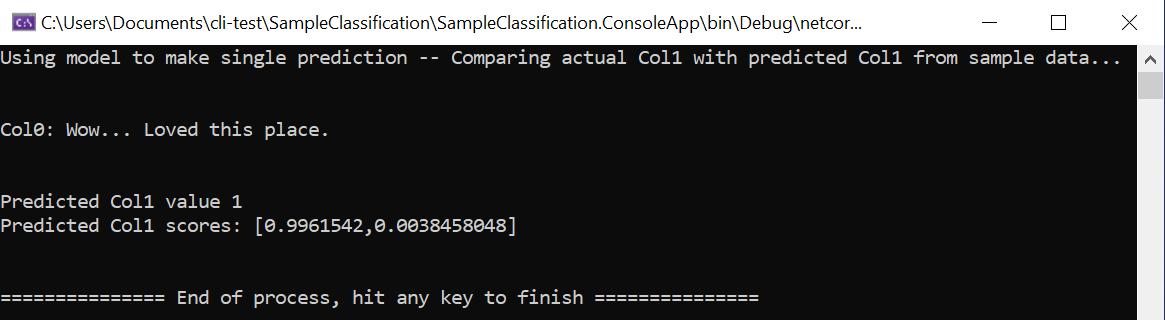
static void Main(string[] args) { // Create single instance of sample data from first line of dataset for model input ModelInput sampleData = new ModelInput() { Col0 = @"Wow... Loved this place.", }; // Make a single prediction on the sample data and print results var predictionResult = SampleClassification.Predict(sampleData); Console.WriteLine("Using model to make single prediction -- Comparing actual Col1 with predicted Col1 from sample data...\n\n"); Console.WriteLine($"Col0: {sampleData.Col0}"); Console.WriteLine($"\n\nPredicted Col1 value {predictionResult.PredictedLabel} \nPredicted Col1 scores: [{String.Join(",", predictionResult.Score)}]\n\n"); Console.WriteLine("=============== End of process, hit any key to finish ==============="); Console.ReadKey(); }В первых строках этого кода создается один образец данных, который в этом случае основывается на первой строке набора данных, используемого для составления прогноза. Вы также можете создать собственные "жестко заданные" данные, обновив код:
ModelInput sampleData = new ModelInput() { Col0 = "The ML.NET CLI is great for getting started. Very cool!" };В следующей строке кода к заданным входным данным применяется метод
SampleClassification.Predict(), который позволяет составить прогноз и возвращает результаты (на основе схемы ModelOutput.cs).В последних строках кода выводятся свойства образца данных (в этом случае комментарии), а также прогноз тональности и соответствующие оценки положительной (1) и отрицательной тональности (2).
Запустите проект с помощью исходного примера данных, загруженного из первой строки набора данных, или предоставьте пример собственных настраиваемых жестко закодированных данных. Вы должны получить прогноз, аналогичный следующему:
 )
)
- Попробуйте изменить пример жестко закодированных данных на другие предложения с различной тональностью и посмотрите, как модель прогнозирует положительную или отрицательную тональность.
Внедрение приложений для конечных пользователей с прогнозами модели машинного обучения
Запускать модель в приложении конечного пользователя и делать прогнозы можно с помощью аналогичного кода для оценки модели машинного обучения.
Например, этот код можно переместить прямо в классическое приложение Windows, такое как WPF и WinForms, и запустить модель так же, как в консольном приложении.
Однако способ реализации этих строк кода для запуска модели машинного обучения необходимо оптимизировать (то есть кэшировать и один раз загрузить ZIP-файл модели) и использовать одноэлементные модели, а не создавать их при каждом запросе, особенно в том случае, если приложение (веб-приложение или распределенная служба) должно быть масштабируемым, как описано в следующем разделе.
Запуск моделей ML.NET в масштабируемых веб-приложениях и службах ASP.NET Core (многопоточных приложениях)
Процесс создания объекта модели (объекта ITransformer, загруженного из ZIP-файла модели) и объекта PredictionEngine должен быть оптимизирован, особенно при запуске в масштабируемых веб-приложениях и распределенных службах. Оптимизация первого объекта модели (ITransformer) не вызывает трудностей. Так как объект ITransformer является потокобезопасным, его можно кэшировать как одноэлементный или статический, чтобы загружать модель всего один раз.
Для второго объекта PredictionEngine сделать это не так просто, поскольку объект PredictionEngine не является потокобезопасным и вы не можете создать его экземпляр в виде одноэлементного или статического объекта в приложении ASP.NET Core. Проблема потокобезопасности и масштабируемости подробно рассматривается в этой публикации блога.
Но сейчас все стало намного проще. Мы работали над более простым подходом и создали хороший пакет интеграции .NET Core, который можно легко использовать в приложениях и службах ASP.NET Core, зарегистрировав его в службах внедрения зависимостей приложения (службы внедрения зависимостей), а затем напрямую использовать из кода. См. инструкции в следующих руководствах и примерах:
- Учебник. Запуск моделей ML.NET в масштабируемых веб-приложениях и веб-API ASP.NET Core
- Пример. Масштабируемая модель ML.NET в веб-API ASP.NET Core
Изучение созданного кода C#, который использовался для модели высшего качества
Для получения более глубоких знаний изучите созданный код C#, который использовался для обучения модели средством CLI.
Этот код модели обучения создается в файле с именем SampleClassification.training.cs, поэтому вы можете исследовать этот код обучения.
Что еще более важно, можно сравнить созданный для этого конкретного сценария (модель анализа тональности) обучающий код с кодом, приведенным в следующем учебнике.
Будет интересно сравнить выбранный алгоритм и конфигурацию конвейера в этом руководстве с кодом, созданным с помощью средства CLI. В зависимости от продолжительности поиска оптимальных моделей вы можете выбрать особый алгоритм с собственными гиперпараметрами и конфигурацией конвейера.
В этом руководстве вы узнали, как:
- подготовить данные для выбранной задачи машинного обучения (устраняемой проблемы);
- запускать команду mlnet classification из средства CLI;
- просмотреть результаты показателей качества;
- понять созданный код C# код для запуска модели (код, используемый в приложении конечных пользователей);
- изучить созданный код C#, который использовался для модели высшего качества (в целях обучения).
См. также
- Автоматизация обучения модели с помощью интерфейса командной строки ML.NET
- Учебник. Запуск моделей ML.NET в масштабируемых веб-приложениях и веб-API ASP.NET Core
- Пример. Масштабируемая модель ML.NET в веб-API ASP.NET Core
- Справочное руководство по команде auto-train в ML.NET CLI
- Данные телеметрии в интерфейсе командной строки ML.NET
Совместная работа с нами на GitHub
Источник этого содержимого можно найти на GitHub, где также можно создавать и просматривать проблемы и запросы на вытягивание. Дополнительные сведения см. в нашем руководстве для участников.