Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье представлен обзор типов, которые помогают считывать данные, проходящие через несколько буферов. Они в основном используются для поддержки PipeReader объектов.
IBufferWriter<T>
System.Buffers.IBufferWriter<T> — это контракт для синхронной буферной записи. На самом низком уровне интерфейс:
- Базовый и не трудный для использования.
- Разрешает доступ к объекту Memory<T> или Span<T>. Можно записать в
Memory<T>илиSpan<T>, и вы можете определить, сколько элементовTбыло записано.
void WriteHello(IBufferWriter<byte> writer)
{
// Request at least 5 bytes.
Span<byte> span = writer.GetSpan(5);
ReadOnlySpan<char> helloSpan = "Hello".AsSpan();
int written = Encoding.ASCII.GetBytes(helloSpan, span);
// Tell the writer how many bytes were written.
writer.Advance(written);
}
Предыдущий метод:
- Запрашивает буфер размером не менее 5 байтов у
IBufferWriter<byte>, используяGetSpan(5). - Записывает байты строки ASCII "Hello" в возвращенный
Span<byte>объект. - Вызовы IBufferWriter<T> , указывающие, сколько байтов было записано в буфер.
Этот метод записи использует Memory<T>/Span<T> буфер, предоставленный IBufferWriter<T>. В качестве альтернативы метод расширения Write можно использовать для копирования существующего буфера в IBufferWriter<T>.
Write выполняет работу по вызову GetSpan/Advance соответствующим образом, поэтому не нужно вызывать Advance после написания:
void WriteHello(IBufferWriter<byte> writer)
{
byte[] helloBytes = Encoding.ASCII.GetBytes("Hello");
// Write helloBytes to the writer. There's no need to call Advance here
// since Write calls Advance.
writer.Write(helloBytes);
}
ArrayBufferWriter<T> — это реализация IBufferWriter<T>, у которой в качестве хранилища используется единый смежный массив.
Распространенные проблемы IBufferWriter
-
GetSpanиGetMemoryвозвращает буфер с по крайней мере запрошенным объемом памяти. Не предполагайте точные размеры буфера. - Нет никакой гарантии, что последовательные вызовы будут возвращать тот же буфер или тот же буфер с одинаковым размером.
- Новый буфер необходимо запросить после вызова
Advance, чтобы продолжить запись дополнительных данных. Ранее приобретенный буфер нельзя записывать после вызоваAdvance.
ReadOnlySequence<T>
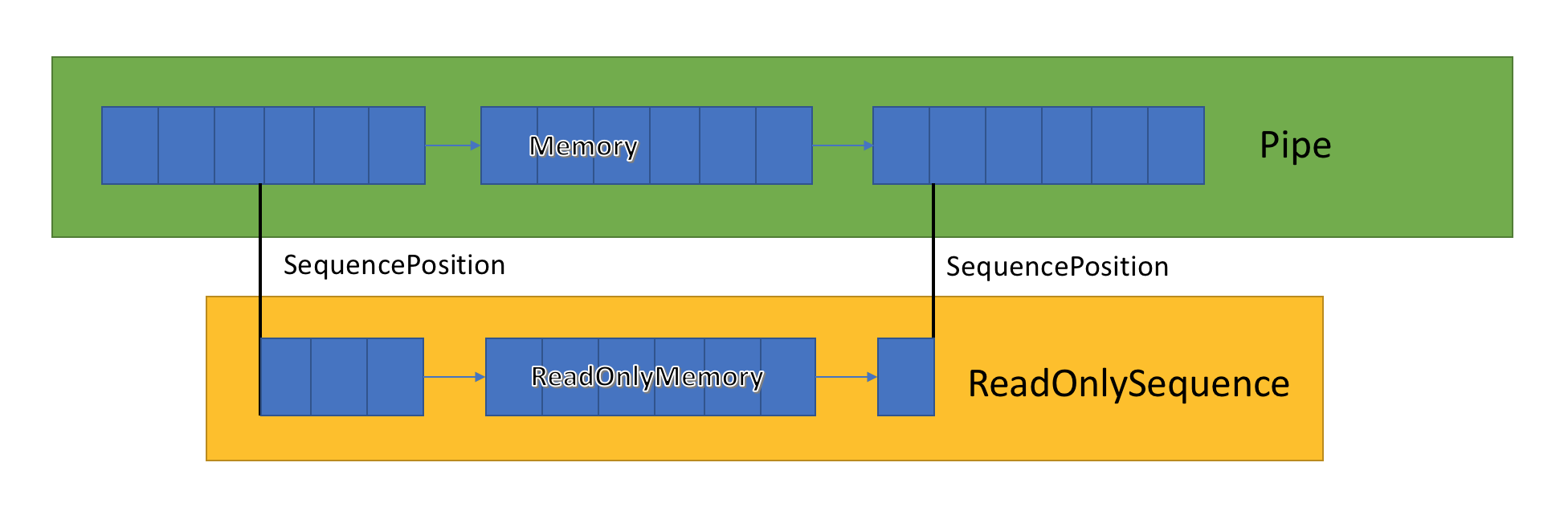
ReadOnlySequence<T> — это структуру, которая может представлять непрерывную или неконтигусную последовательность T. Его можно создать из следующих способов:
- Один
T[] - Один
ReadOnlyMemory<T> - Пара узла связанного списка ReadOnlySequenceSegment<T> и индекса, представляющая начальную и конечную позицию последовательности.
Третье представление является наиболее интересным, так как оно влияет на производительность различных операций на ReadOnlySequence<T>.
| Представление | Операция | Сложность |
|---|---|---|
T[]/ReadOnlyMemory<T> |
Length |
O(1) |
T[]/ReadOnlyMemory<T> |
GetPosition(long) |
O(1) |
T[]/ReadOnlyMemory<T> |
Slice(int, int) |
O(1) |
T[]/ReadOnlyMemory<T> |
Slice(SequencePosition, SequencePosition) |
O(1) |
ReadOnlySequenceSegment<T> |
Length |
O(1) |
ReadOnlySequenceSegment<T> |
GetPosition(long) |
O(number of segments) |
ReadOnlySequenceSegment<T> |
Slice(int, int) |
O(number of segments) |
ReadOnlySequenceSegment<T> |
Slice(SequencePosition, SequencePosition) |
O(1) |
Из-за этого смешанного представления индексы представлены как ReadOnlySequence<T> вместо целого числа. A SequencePosition:
- Непрозрачное значение, представляющее индекс в
ReadOnlySequence<T>, откуда оно произошло. - Состоит из двух частей, целого числа и объекта. То, что представляют эти два значения, привязаны к реализации
ReadOnlySequence<T>.
Доступ к данным
ReadOnlySequence<T> представляет данные в виде перечисляемого ReadOnlyMemory<T>. Перечисление каждого из сегментов можно сделать с помощью базового элемента foreach:
long FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
long position = 0;
foreach (ReadOnlyMemory<byte> segment in buffer)
{
ReadOnlySpan<byte> span = segment.Span;
var index = span.IndexOf(data);
if (index != -1)
{
return position + index;
}
position += span.Length;
}
return -1;
}
Предыдущий метод выполняет поиск каждого сегмента для определенного байта. Если вам нужно отслеживать каждый сегмент SequencePosition, ReadOnlySequence<T>.TryGet более подходит. Следующий пример изменяет предыдущий код, чтобы вернуть SequencePosition вместо целого числа. Возвращаемый объект SequencePosition имеет преимущество: он позволяет вызывающему объекту избежать второго сканирования для получения данных по определенному индексу.
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
SequencePosition position = buffer.Start;
SequencePosition result = position;
while (buffer.TryGet(ref position, out ReadOnlyMemory<byte> segment))
{
ReadOnlySpan<byte> span = segment.Span;
var index = span.IndexOf(data);
if (index != -1)
{
return buffer.GetPosition(index, result);
}
result = position;
}
return null;
}
Сочетание SequencePosition и TryGet действует как перечислитель. Поле позиции изменяется в начале каждой итерации, чтобы установить начало каждого сегмента внутри ReadOnlySequence<T>.
Представленный метод существует в качестве метода расширения на ReadOnlySequence<T>.
PositionOf можно использовать для упрощения предыдущего кода:
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data) => buffer.PositionOf(data);
Обработка ReadOnlySequence<T>
Обработка ReadOnlySequence<T> может быть сложной, так как данные могут быть разделены на несколько сегментов в последовательности. Для оптимальной производительности разбиение кода на два пути:
- Быстрый путь, который обрабатывает случай с одним сегментом.
- Медленный путь, который связан с разделением данных по сегментам.
Существует несколько подходов, которые можно использовать для обработки данных в нескольких сегментированных последовательностях:
- Используйте
SequenceReader<T>. - Анализировать данные посегментно, отслеживая
SequencePositionи индекс в каждом проанализированном сегменте. Это позволяет избежать ненужных выделений, но может оказаться неэффективным, особенно для небольших буферов. -
ReadOnlySequence<T>Скопируйте в смежный массив и обработайте его как один буфер:- Если размер
ReadOnlySequence<T>небольшой, может быть разумно скопировать данные в буфер, выделенный на стеке, с помощью оператора stackalloc. - Скопируйте
ReadOnlySequence<T>в общий массив с помощью ArrayPool<T>.Shared. - Используйте
ReadOnlySequence<T>.ToArray(). Это не рекомендуется в горячих путях, так как выделяет новыйT[]на куче.
- Если размер
В следующих примерах показаны некоторые распространенные случаи обработки ReadOnlySequence<byte>:
Обработка двоичных данных
В следующем примере анализируется 4-байтовая целочисленная длина целого числа с начала ReadOnlySequence<byte>.
bool TryParseHeaderLength(ref ReadOnlySequence<byte> buffer, out int length)
{
// If there's not enough space, the length can't be obtained.
if (buffer.Length < 4)
{
length = 0;
return false;
}
// Grab the first 4 bytes of the buffer.
var lengthSlice = buffer.Slice(buffer.Start, 4);
if (lengthSlice.IsSingleSegment)
{
// Fast path since it's a single segment.
length = BinaryPrimitives.ReadInt32BigEndian(lengthSlice.First.Span);
}
else
{
// There are 4 bytes split across multiple segments. Since it's so small, it
// can be copied to a stack allocated buffer. This avoids a heap allocation.
Span<byte> stackBuffer = stackalloc byte[4];
lengthSlice.CopyTo(stackBuffer);
length = BinaryPrimitives.ReadInt32BigEndian(stackBuffer);
}
// Move the buffer 4 bytes ahead.
buffer = buffer.Slice(lengthSlice.End);
return true;
}
Обработка текстовых данных
Следующий пример:
- Находит первую новую строку (
\r\n) в полеReadOnlySequence<byte>и возвращает ее с помощью параметра out 'line'. - Обрезает линию, исключая
\r\nиз входного буфера.
static bool TryParseLine(ref ReadOnlySequence<byte> buffer, out ReadOnlySequence<byte> line)
{
SequencePosition position = buffer.Start;
SequencePosition previous = position;
var index = -1;
line = default;
while (buffer.TryGet(ref position, out ReadOnlyMemory<byte> segment))
{
ReadOnlySpan<byte> span = segment.Span;
// Look for \r in the current segment.
index = span.IndexOf((byte)'\r');
if (index != -1)
{
// Check next segment for \n.
if (index + 1 >= span.Length)
{
var next = position;
if (!buffer.TryGet(ref next, out ReadOnlyMemory<byte> nextSegment))
{
// You're at the end of the sequence.
return false;
}
else if (nextSegment.Span[0] == (byte)'\n')
{
// A match was found.
break;
}
}
// Check the current segment of \n.
else if (span[index + 1] == (byte)'\n')
{
// It was found.
break;
}
}
previous = position;
}
if (index != -1)
{
// Get the position just before the \r\n.
var delimeter = buffer.GetPosition(index, previous);
// Slice the line (excluding \r\n).
line = buffer.Slice(buffer.Start, delimeter);
// Slice the buffer to get the remaining data after the line.
buffer = buffer.Slice(buffer.GetPosition(2, delimeter));
return true;
}
return false;
}
Пустые сегменты
Допустимо хранить пустые сегменты внутри ReadOnlySequence<T>. Пустые сегменты могут возникать при явном перечислении сегментов:
static void EmptySegments()
{
// This logic creates a ReadOnlySequence<byte> with 4 segments,
// two of which are empty.
var first = new BufferSegment(new byte[0]);
var last = first.Append(new byte[] { 97 })
.Append(new byte[0]).Append(new byte[] { 98 });
// Construct the ReadOnlySequence<byte> from the linked list segments.
var data = new ReadOnlySequence<byte>(first, 0, last, 1);
// Slice using numbers.
var sequence1 = data.Slice(0, 2);
// Slice using SequencePosition pointing at the empty segment.
var sequence2 = data.Slice(data.Start, 2);
Console.WriteLine($"sequence1.Length={sequence1.Length}"); // sequence1.Length=2
Console.WriteLine($"sequence2.Length={sequence2.Length}"); // sequence2.Length=2
// sequence1.FirstSpan.Length=1
Console.WriteLine($"sequence1.FirstSpan.Length={sequence1.FirstSpan.Length}");
// Slicing using SequencePosition will Slice the ReadOnlySequence<byte> directly
// on the empty segment!
// sequence2.FirstSpan.Length=0
Console.WriteLine($"sequence2.FirstSpan.Length={sequence2.FirstSpan.Length}");
// The following code prints 0, 1, 0, 1.
SequencePosition position = data.Start;
while (data.TryGet(ref position, out ReadOnlyMemory<byte> memory))
{
Console.WriteLine(memory.Length);
}
}
class BufferSegment : ReadOnlySequenceSegment<byte>
{
public BufferSegment(Memory<byte> memory)
{
Memory = memory;
}
public BufferSegment Append(Memory<byte> memory)
{
var segment = new BufferSegment(memory)
{
RunningIndex = RunningIndex + Memory.Length
};
Next = segment;
return segment;
}
}
Предыдущий код создает пустой ReadOnlySequence<byte> сегмент и показывает, как эти пустые сегменты влияют на различные API:
-
ReadOnlySequence<T>.SliceсSequencePosition, указующим на пустой сегмент, сохраняет этот сегмент. -
ReadOnlySequence<T>.Sliceс помощью int пропускает пустые сегменты. - Перечисление
ReadOnlySequence<T>перечисляет пустые сегменты.
Потенциальные проблемы с ReadOnlySequence<T> и SequencePosition
Существует несколько необычных результатов при работе с ReadOnlySequence<T>/SequencePosition по сравнению с нормальным ReadOnlySpan<T>/ReadOnlyMemory<T>/T[]/int:
-
SequencePosition— это маркер позиции для определеннойReadOnlySequence<T>, а не абсолютной позиции. Так как он относится к определенномуReadOnlySequence<T>, он не имеет значения, если используется внеReadOnlySequence<T>места его происхождения. - Арифметика не может выполняться на
SequencePositionбезReadOnlySequence<T>. Это означает выполнение таких базовых действий, какposition++пишетсяposition = ReadOnlySequence<T>.GetPosition(1, position). -
GetPosition(long)не поддерживает отрицательные индексы. Это означает, что невозможно получить предпоследний символ, не пройдя все сегменты. - Два
SequencePositionневозможно сравнить, что затрудняет:- Понимать, является ли одна позиция больше или меньше другой позиции.
- Напишите некоторые алгоритмы синтаксического анализа.
-
ReadOnlySequence<T>больше, чем ссылка на объект, и его следует передавать in или ref, где это возможно. ПередачаReadOnlySequence<T>с помощьюinилиrefуменьшает количество копий struct. - Пустые сегменты:
- Допустимы в пределах
ReadOnlySequence<T>. - Может отображаться при итерации с помощью
ReadOnlySequence<T>.TryGetметода. - Может возникнуть при разрезании последовательности с использованием метода
ReadOnlySequence<T>.Slice()с объектамиSequencePosition.
- Допустимы в пределах
SequenceReader<T>
- Это новый тип, который был введен в .NET Core 3.0, чтобы упростить обработку
ReadOnlySequence<T>. - Объединяет различия между одним сегментом
ReadOnlySequence<T>и несколькими сегментамиReadOnlySequence<T>. - Предоставляет вспомогательные средства для чтения двоичных и текстовых данных (
byteиchar) которые могут или не могут быть разделены между сегментами.
Существуют встроенные методы для обработки двоичных и разделенных данных. В следующем разделе показано, как выглядят те же методы с SequenceReader<T>:
Доступ к данным
SequenceReader<T> имеет методы для непосредственного перечисления данных внутри ReadOnlySequence<T>. Следующий код является примером обработки ReadOnlySequence<byte>byte за раз:
while (reader.TryRead(out byte b))
{
Process(b);
}
Предоставляет CurrentSpan текущий сегмент Span, аналогичный тому, что было сделано в методе вручную.
Используйте позицию
Следующий код является примером реализации FindIndexOf с использованием SequenceReader<T>.
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
var reader = new SequenceReader<byte>(buffer);
while (!reader.End)
{
// Search for the byte in the current span.
var index = reader.CurrentSpan.IndexOf(data);
if (index != -1)
{
// It was found, so advance to the position.
reader.Advance(index);
return reader.Position;
}
// Skip the current segment since there's nothing in it.
reader.Advance(reader.CurrentSpan.Length);
}
return null;
}
Обработка двоичных данных
В следующем примере анализируется 4-байтовая целочисленная длина целого числа с начала ReadOnlySequence<byte>.
bool TryParseHeaderLength(ref ReadOnlySequence<byte> buffer, out int length)
{
var reader = new SequenceReader<byte>(buffer);
return reader.TryReadBigEndian(out length);
}
Обработка текстовых данных
static ReadOnlySpan<byte> NewLine => new byte[] { (byte)'\r', (byte)'\n' };
static bool TryParseLine(ref ReadOnlySequence<byte> buffer,
out ReadOnlySequence<byte> line)
{
var reader = new SequenceReader<byte>(buffer);
if (reader.TryReadTo(out line, NewLine))
{
buffer = buffer.Slice(reader.Position);
return true;
}
line = default;
return false;
}
Распространенные проблемы SequenceReader<T>
- Так как
SequenceReader<T>это мутируемая структура, она всегда должна передаваться по ссылке. -
SequenceReader<T>— это структура ссылок , поэтому ее можно использовать только в синхронных методах и не может храниться в полях. Дополнительные сведения см. в разделе Избегайте выделений. -
SequenceReader<T>оптимизирован для использования в качестве последовательного средства чтения.Rewindпредназначен для небольших резервных копий, которые не могут быть обработаны с помощью другихRead,Peek, иIsNextAPI.
Совместная работа с нами на GitHub
Источник этого содержимого можно найти на GitHub, где также можно создавать и просматривать проблемы и запросы на вытягивание. Дополнительные сведения см. в нашем руководстве для участников.