Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье рассматриваются матрицы ошибок, проблемы классификации и точность в моделях машинного обучения (ML). Целью является улучшение понимания точности в результатах прогнозирования в ML. Целевые аудитории включают инженеров, аналитиков и руководителей, желающих расширить свои знания и навыки в области обработки и анализа данных.
Матрица ошибок
После того, как контролируемая система ML обучена по набору исторических данных, она тестируется с использованием данных, которые можно исключить из процесса обучения. Таким образом можно сравнить прогнозы из обученной модели с фактическими значениями. Матрица ошибок предоставляет средство оценки успешности решения задачи классификации и мест возникновения ошибок (то есть, когда она "путается").
Например, ваша цель — предсказать, является ли домашнее животное собакой или кошкой, на основе некоторых физических и поведенческих атрибутов. Если имеется тестовый набор данных, содержащий 30 собак и 20 кошек, то матрица ошибок может быть похожа на следующую иллюстрацию.

Числа в зеленых ячейках представляют собой правильные прогнозы. Как можно видеть, модель правильно прогнозируется более высокий процент фактических кошек. Общую точность модели легко рассчитать. В данном случае это 42 ÷ 50 или 0,84.
Классификаторы по нескольким классам в матрице ошибок
Большинство дискуссий о матрице ошибок сосредоточено на двоичных классификаторах, как в предыдущем примере. Этот случай представляет собой особый случай, когда могут учитываться другие показатели, такие как чувствительность и отзыв.
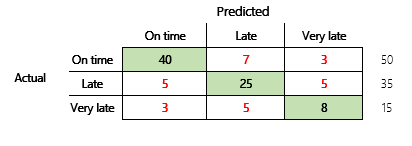
Далее будет рассмотрена проблема классификации для финансового сценария, имеющая три состояния. Модель прогнозирует, будет ли накладная клиента оплачена вовремя, поздно или очень поздно. Например, из 100 тестовых накладных, 50 оплачиваются вовремя, 35 — с опозданием, а 15 — с очень большим опозданием. В этом случае модель может создать матрицу ошибок, которая напоминает следующий рисунок.
 ]
]
Матрица ошибок предоставляет значительно больше информации, чем простая метрика точности. Однако ее по-прежнему довольно легко понять. Матрица ошибок сообщает, имеется ли сбалансированный набор данных, в котором выходные классы имеют похожее количество. В случае с несколькими классами она показывает, насколько может ошибаться прогнозирование, когда выходные классы являются порядковыми, как в предыдущем примере о платежах клиентов.
Точность модели
У различных показателей точности имеется преимущество измерения качества модели.
Так как точность является простой метрикой для понимания, она является хорошей отправной точкой для объяснения модели другим людям, особенно пользователем модели, не являющихся специалистами в области обработки данных. Понимание статистики не требуется, чтобы понять точность модели. При наличии матрицы ошибок она предоставляет дальнейшее понимание эффективности модели.
Однако для более глубокого понимания необходимо отметить несколько проблем, связанных с точностью. Полезность метрики зависит от контекста проблемы. Вопрос, который часто возникает в связи с эффективностью модели, — "Насколько хороша модель?" Однако ответ на этот вопрос необязательно прост. Рассмотрим следующую матрицу ошибок (модель 2).
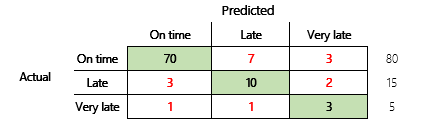
Быстрый расчет показывает, что точность этой модели составляет (70 + 10 + 3) ÷ 100 или 0,83. На поверхности этот результат кажется более подходящим, чем результат для предыдущей модели с несколькими классами (модель 1), имеющей точность 0,73. Но лучше ли это?
Чтобы начать рассмотрение этого вопроса, необходимо оценить точность наивного предположения. При проблемы классификации простая догадка всегда будет спрогнозировать самый распространенный класс. Для модели 1 эта догадка будет иметь значение "вовремя", и это приведет к точности 0,50. Догадка для модели 2 также будет "вовремя", и это приведет к точности 0,80. Поскольку модель 1 улучшает наивную догадку на 0,73 – 0,50 = 0,23, в то время как модель 2 улучшает наивную догадку на 0,83 – 0,80 = 0,03, модель 1 является лучшей моделью, даже если она имеет меньшую точность. Расчет показывает, что эффективная оценка качества модели требует большего количества контекста, чем значение точности.
Стоит отметить еще один аспект. Рассмотрим ситуацию, в которой медицинские тесты используются для обнаружения болезни у пациентов. Эта проблема является проблемой двоичной классификации, когда положительный результат указывает на то, что пациент болен. В этом случае необходимо подумать о влиянии следующих ошибок:
- Ложный положительный результат, когда тест говорит о том, что пациент болен, но на самом деле пациент здоров.
- Ложный отрицательный результат, когда тест говорит о том, что пациент здоров, но на самом деле пациент болен.
Очевидно, что эти типы ошибок нежелательны, но что хуже? Опять, это зависит от ситуации. В случае опасной для жизни болезни, требующей быстрого лечения, приоритет имеет минимизация ложных отрицательных результатов (за которыми желательно следуют дополнительные тесты). В других, менее критических случаях, создатели моделей могут минимизировать ложные положительные результаты. В любом случае разумным заключением является то, что для эффективного определения качества модели необходимо иметь большее количество сведений, чем дает метрика точности.
Рекомендации
Точность — важное средство для общения со специалистами в экспертной области, знакомых со статистикой. Однако, чтобы сделать информацию полезной, очень важно, чтобы дополнительный контекст был одновременно представлен со значением точности.
Для сценария прогнозирования платежей можно настроить цель для модели ML, которая включает факторы в различном поведении платежей. Цель состоит в том, что модель должна быть улучшена относительно наивной догадки путем уменьшения количества неправильных ответов не менее чем на 50 процентов. Другими словами, требуется целевая точность, которая находится между точностью наивной догадки и 100 процентами.
В следующей таблице этот принцип обобщен для матриц ошибок, рассмотренных в этой статье.
| Модель | Наивное предположение | Цель | Точность модели | Цель достигнута? |
|---|---|---|---|---|
| Модель 1 | 0.50 | 0.75 | 0.73 | Почти. Эта модель значительно лучше догадки. |
| Модель 2 | 0.80 | 0.90 | 0.83 | Нет. Необходимо улучшить. |
Точность F1классификации
Последнее, что будет рассмотрено в этой статье, — это более сложная мера производительности ML-процесса классификации, которая называется точностью F1.
Прежде чем можно будет определить точность F1, должны быть введены две дополнительные метрики: точность и отзыв. Точность показывает, сколько общего количества прогнозов, указанных как положительные, правильно назначено. Эта метрика также называется положительным прогнозируемым значением. Отзыв — это общее число фактических положительных случаев, которые были спрогнозированы правильно. Эта метрика также известна как чувствительность.

В матрице ошибок на предыдущем рисунке эти показатели рассчитываются следующим образом:
- Точность = TP ÷ (TP + FP)
- Отзыв = TP ÷ (TP + FN)
Мера F1 сочетает точность и отзыв. Результатом является среднее гармоническое двух значений. Она вычисляется следующим образом:
- F1 = 2 × (Точность × Отзыв) ÷ (Точность + Отзыв)
Рассмотрим конкретный пример. Ранее в этой статье был приведен пример модели, которая прогнозирует, является ли животное собакой или кошкой. Здесь повторяется это изображение.
Здесь приведены результаты, если "Собака" используется как положительный ответ.
- Точность = 24 ÷ (24 + 2) = 0,9231
- Отзыв = 24 ÷ (24 + 6) = 0,8
- F1 = 2 × (0,9231 × 0,8) ÷ (0,9231 + 0,8) = 0,8572
Как можно видеть, значение F1 находится между значениями точности и отзыва.
Хотя точность F1 не так проста в понимании, она добавляет нюансы к базовому числу точности. Она также может помочь в несбалансированном наборе данных, так как будет показано в следующем обсуждении.
В разделе Точность модели данной статьи сравниваются следующие две матрицы ошибок. Даже несмотря на то, что первая модель имела меньшую точность, она была признана более полезной моделью, поскольку она показала более значительное улучшение по сравнению с предположением по умолчанию для времени оплаты.
Давайте посмотрим, как эти две модели сравниваются при использовании оценки F1. Оценка F1 учитывает точность и отзыв для каждого состояния, а вычисление макроса F1 затем усредняет оценку F1 по всем состояниям для определения общего показателя F1. Имеются другие варианты F1, но очень важно рассмотреть версию макроса с учетом того, что все три состояния учитываются одинаково.
Для упрощения вычислений образцы массивов создавались в соответствии с фактическими и прогнозируемыми значениями. Эти массивы использовали библиотеку показателей sklearn в Python для расчета значений. Вот результат.
| Модель | Наивное предположение | Точность | Макрос F1 |
|---|---|---|---|
| Модель 1 | 0.5 | 0.73 | 0.67 |
| Модель 2 | 0.80 | 0.83 | 0.66 |
Для получения более подробной информации о том, как выполняется этот расчет, здесь приведен отчет о классификации sklearn.metrics для модели 1. Три состояния, "Вовремя", "Поздно" и "Очень поздно", представлены строками, которые имеют метку 1, 2 и 3 соответственно. Среднее макроса — это просто среднее значение столбца "оценка-f1".
| точность | отзыв | оценка-f1 | |
|---|---|---|---|
| 1 | 0.83 | 0.80 | 0.82 |
| 2 | 0.68 | 0.71 | 0.69 |
| 3 | 0.50 | 0.50 | 0.50 |
Как показывают эти результаты, две модели имеют почти одинаковые результаты точности макросов F1. В этом и многих других случаях точность F1 обеспечивает лучший индикатор возможности модели. Для точности, интерпретация результатов требует понимания того, что наиболее важно для учета в модели.