Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Используйте настраиваемые пулы Spark для настройки вычислений для рабочих нагрузок в Fabric. Вы можете выбрать размер узла, настроить поведение автомасштабирования и включить динамическое выделение исполнителя.
Пользовательские пулы помогают сбалансировать производительность и затраты, позволяя задать ограничения масштабирования, соответствующие требованию рабочей нагрузки.
Замечание
Пользовательские пулы Spark могут обеспечивать начало сессии примерно за 5 секунд при настройке в качестве пользовательского динамического пула со средой, использующей полный режим для публикации библиотеки. Без конфигурации пула в реальном времени настраиваемые пулы Spark запускаются примерно за три минуты.
Если вы уже используете начальные пулы, настраиваемые пулы являются дополнительными вариантами, если вам требуется больше контроля над поведением размера и масштабирования для определенных рабочих нагрузок. Используйте начальные пулы для быстрого запуска и параметров по умолчанию, а также переход к пользовательским пулам при необходимости настройки вычислительных ресурсов для конкретной рабочей нагрузки. Дополнительные сведения о начальных пулах см. в статье "Настройка начальных пулов" в Fabric.
Предпосылки
Чтобы создать пользовательский пул Spark, выполните приведенные действия.
- Вам нужна роль администратора в рабочей области.
- Администратор ресурса должен включить настраиваемые пулы рабочих пространств в параметрах Spark Compute для ресурса.
Дополнительные сведения см. в разделе "Настройка и управление параметрами проектирования и обработки и анализа данных" для емкостей Fabric.
Создание настраиваемых пулов Spark
Чтобы создать или управлять пулом Spark, связанным с вашей рабочей областью:
Перейдите в рабочую область и выберите параметры рабочей области.

Выберите опцию Инженерия данных/Наука, чтобы развернуть меню, а затем выберите настройки Spark.
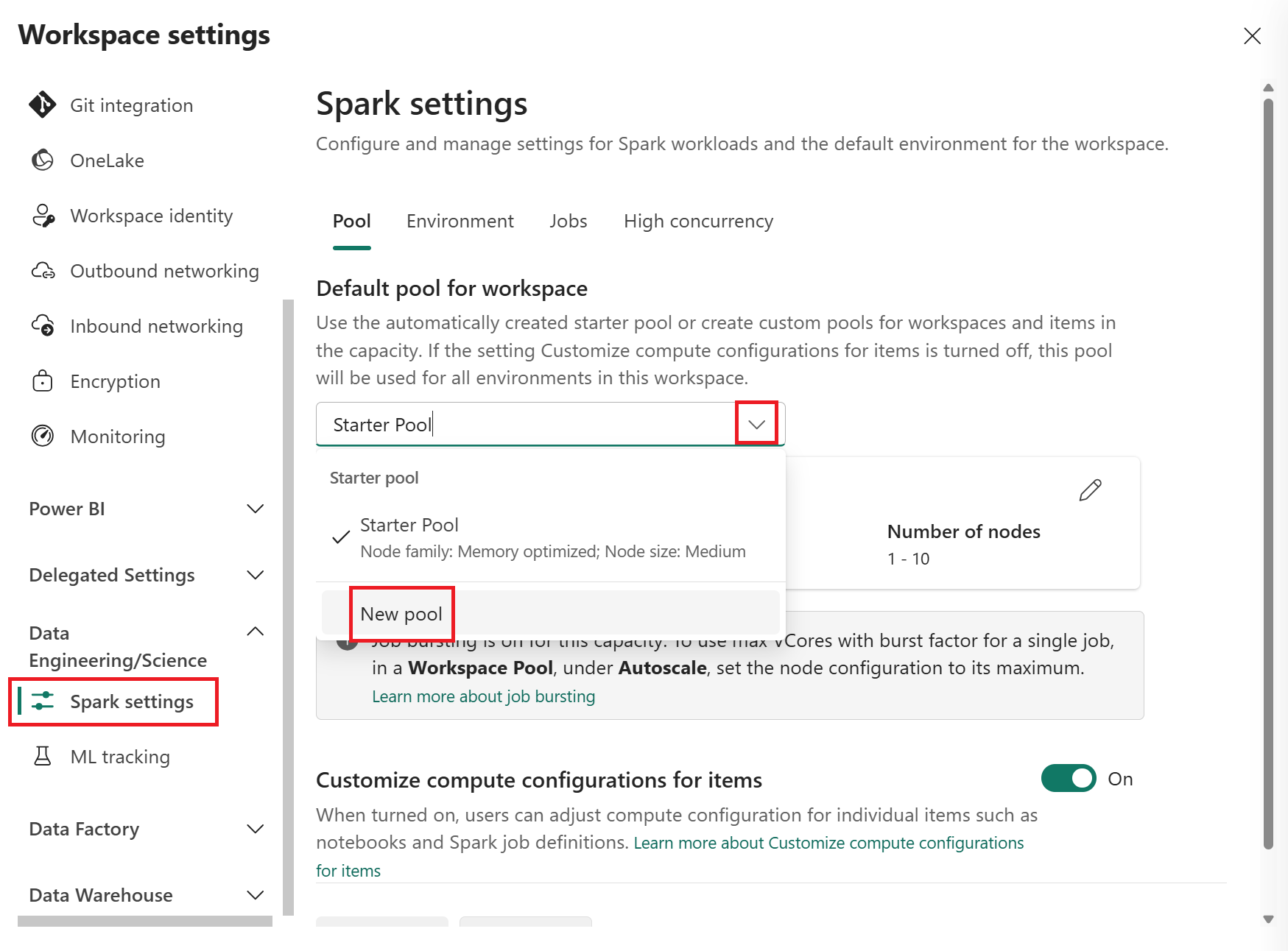
Выберите новый пул в раскрывающемся списке пула по умолчанию для рабочей области, чтобы создать новый настраиваемый пул Spark. Можно создать несколько настраиваемых пулов и выбрать любой из них в качестве пула по умолчанию для рабочей области.
На странице "Создание пула " введите имя пула. Выберите семейство узлов (например , оптимизированное для памяти) и размер узла в зависимости от требований к рабочей нагрузке. Дополнительные сведения о размерах узлов см. в разделе "Параметры размера узла " ниже.
Подсказка
Размер узла определяется единицами емкости (CU), которые представляют вычислительные ресурсы, назначенные каждому узлу.
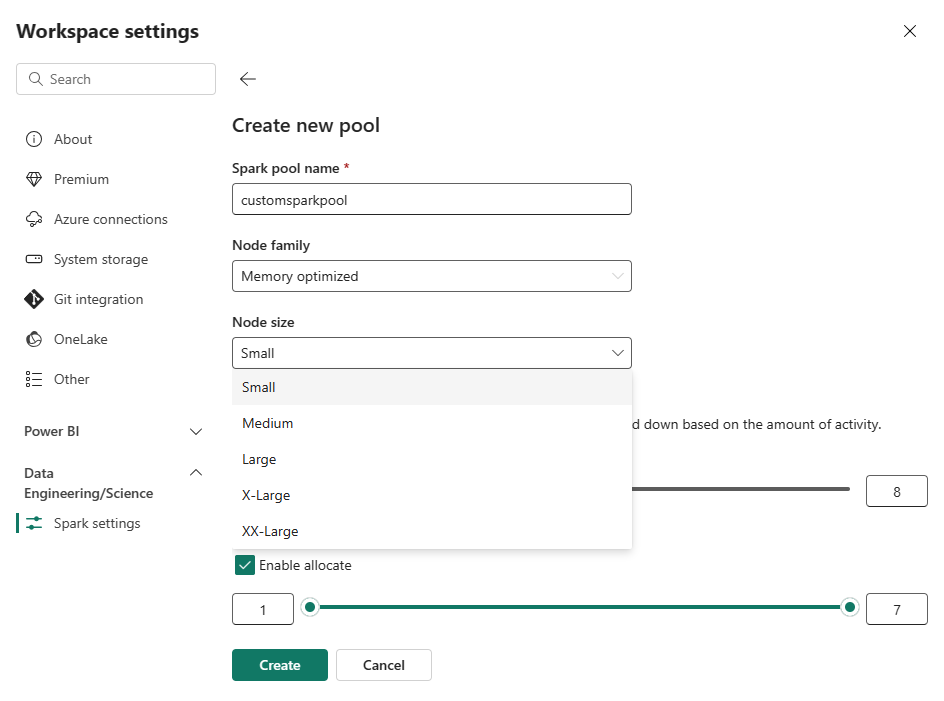
В представлении редактирования настройте автомасштабирование и динамическое выделение исполнителей.
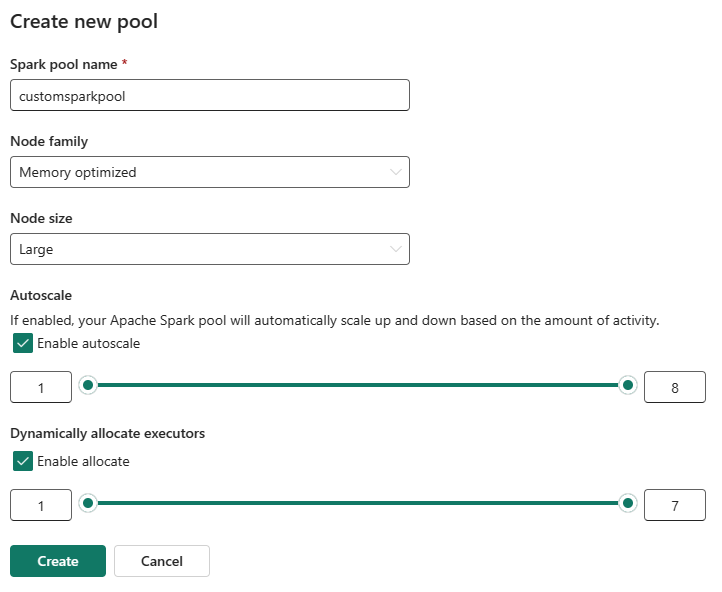
Используйте ползунки для увеличения или уменьшения каждого параметра в зависимости от потребностей рабочей нагрузки.
Если автомасштабирование включено, пул масштабируется между настроенными минимальными и максимальными значениями узлов на основе действия.
Если динамически выделять исполнителей, Fabric настраивает выделение исполнителей в зависимости от спроса на рабочую нагрузку в пределах настроенных границ.
Нажмите кнопку "Создать".




Подсказка
После создания настраиваемого пула Spark время развертывания библиотеки зависит от режима публикации в подключенной среде. Быстрый режим публикует около 5 секунд и устанавливает библиотеки при запуске сеанса. Полный режим занимает от 3 до 6 минут для публикации и развертывания библиотек в рамках запуска сеанса (от 1 до 3 минут). Для самого быстрого опыта настройте пул как настраиваемый динамический пул в полном режиме, чтобы достичь времени начала сеанса примерно 5 секунд.
Настраиваемые пулы имеют время по умолчанию для автопаузы в 2 минуты после бездействия. Когда автопауза достигается, сеанс завершается, и кластер деактивируется. Выставление счетов применяется только во время активного использования вычислений. Настраиваемые пулы Spark в Microsoft Fabric в настоящее время поддерживают максимальное ограничение на 200 узлов, поэтому убедитесь, что минимальные и максимальные значения автомасштабирования остаются в пределах этого предела.
Параметры размера узла
При настройке настраиваемого пула Spark выберите один из следующих размеров узлов:
| Размер узла | vCores | Память (ГБ) | Описание |
|---|---|---|---|
| Небольшой | 4 | 32 | Для упрощенных заданий разработки и тестирования. |
| Средний | 8 | 64 | Для общих рабочих нагрузок и типичных операций. |
| Крупный | 16 | 128 | Для задач с интенсивным объемом памяти или больших заданий обработки данных. |
| Размер XL | 32 | 256 | Для наиболее требовательных рабочих нагрузок Spark, которым требуются значительные ресурсы. |
| XX-большой | 64 | 512 | Для крупнейших рабочих нагрузок Spark, требующих наибольшего объема вычислительных ресурсов и памяти на узел. |
Связанное содержимое
- Подробнее см. в общедоступной документации по Apache Spark .
- Начало работы с параметрами администрирования рабочей области Spark в Microsoft Fabric.
- Управление библиотеками в средах Fabric