Параметры конфигурации вычислений Spark в средах Fabric
Интерфейсы microsoft Fabric Инжиниринг данных и Обработка и анализ данных работают на полностью управляемой вычислительной платформе Spark. Эта платформа предназначена для обеспечения непарабельной скорости и эффективности. Он включает начальные пулы и настраиваемые пулы.
Среда Fabric содержит коллекцию конфигураций, включая свойства вычислений Spark, которые позволяют пользователям настраивать сеанс Spark после подключения к записным книжкам и заданиям Spark. В среде можно настроить конфигурации вычислений для выполнения заданий Spark. В среде раздел вычислений позволяет настроить свойства уровня сеанса Spark для настройки памяти и ядер исполнителей на основе требований к рабочей нагрузке.
Администраторы рабочей области могут включать или отключать настройки вычислений с помощью переключателя "Настройка конфигураций вычислений для элементов" на вкладке "Пул" раздела "Инжиниринг данных/Наука" на экране параметров рабочей области.
Администраторы рабочей области могут делегировать участников и участник, чтобы изменить конфигурации вычислений уровня сеанса по умолчанию в среде Fabric, включив этот параметр.
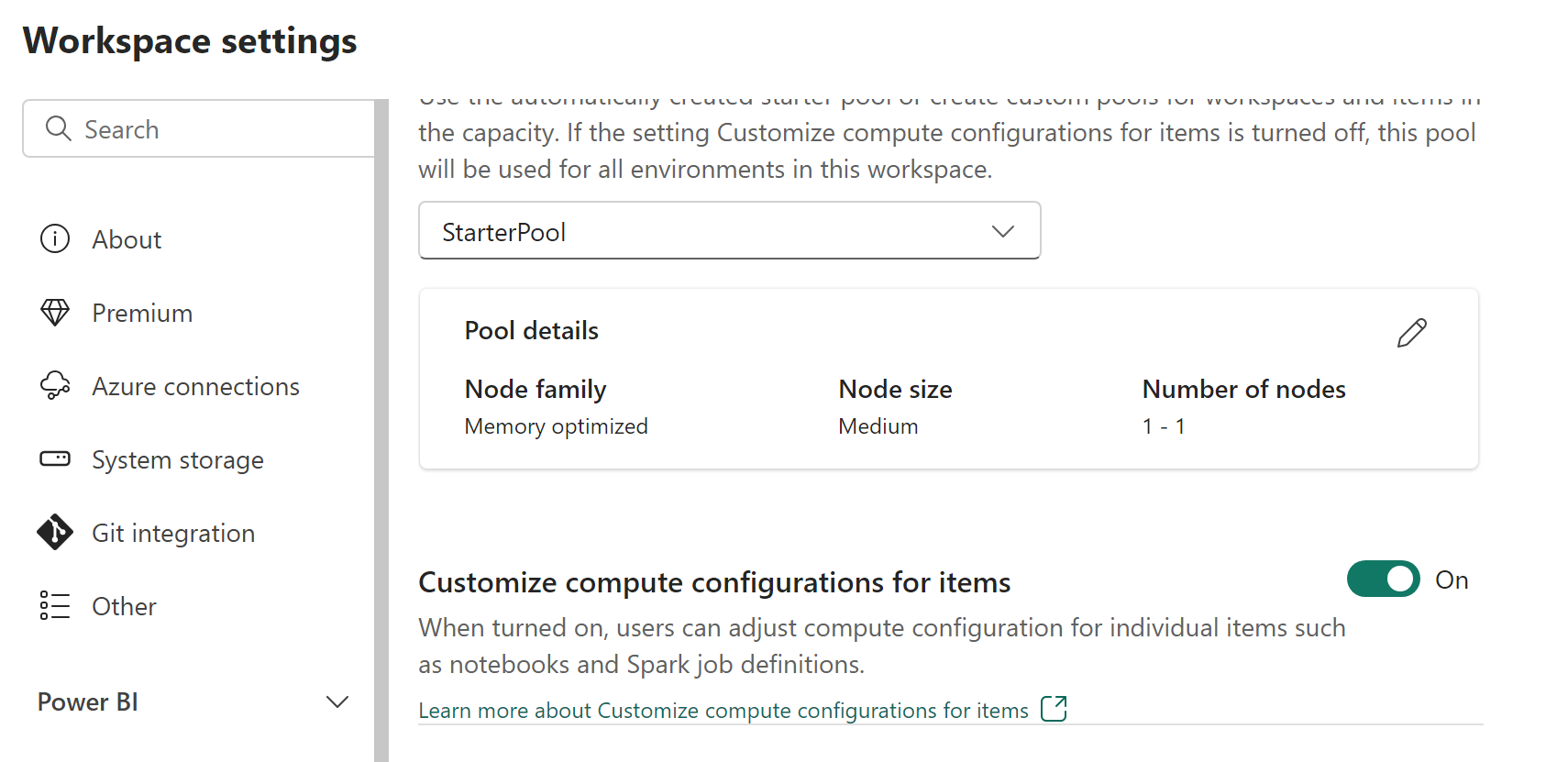
Если администратор рабочей области отключает этот параметр в параметрах рабочей области, раздел вычислений среды отключен, а конфигурации вычислений пула по умолчанию для рабочей области используются для выполнения заданий Spark.
Настройка свойств вычислений уровня сеанса в среде
В качестве пользователя можно выбрать пул для среды из списка пулов, доступных в рабочей области Fabric. Администратор рабочей области Fabric создает начальный пул по умолчанию и настраиваемые пулы.
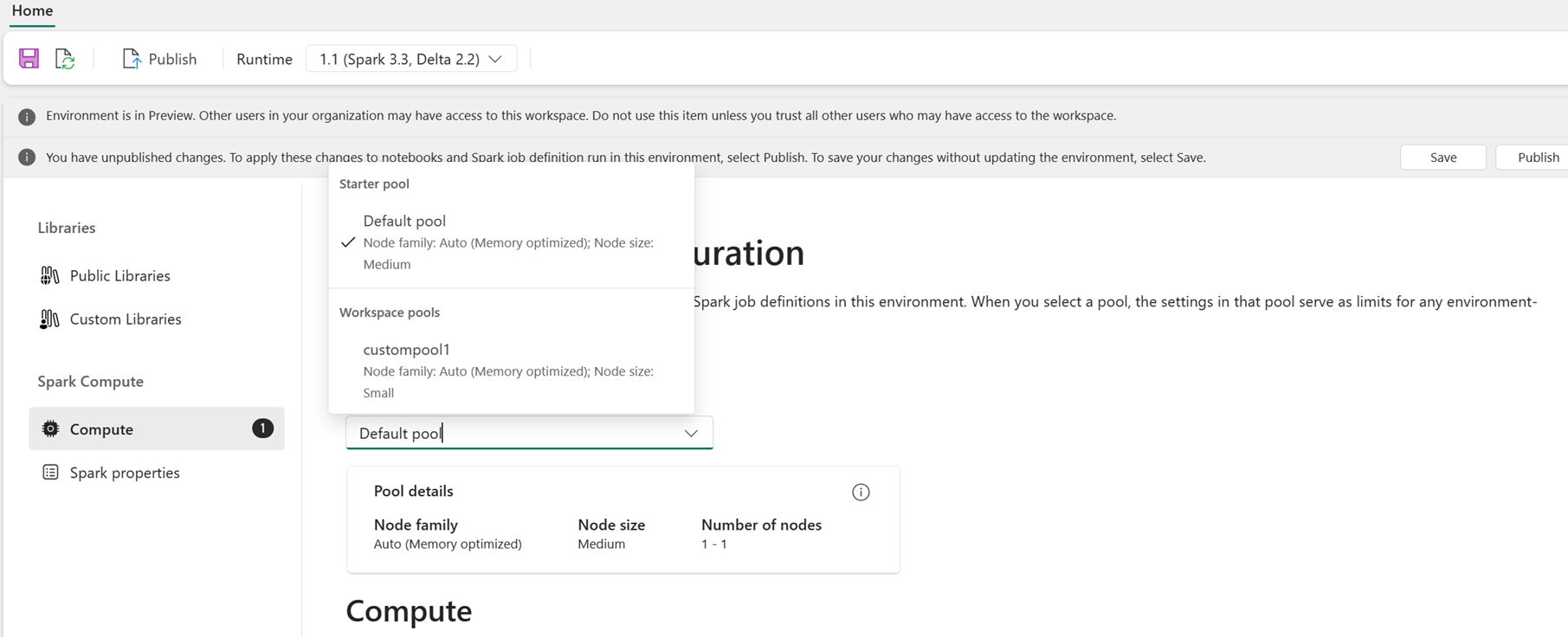
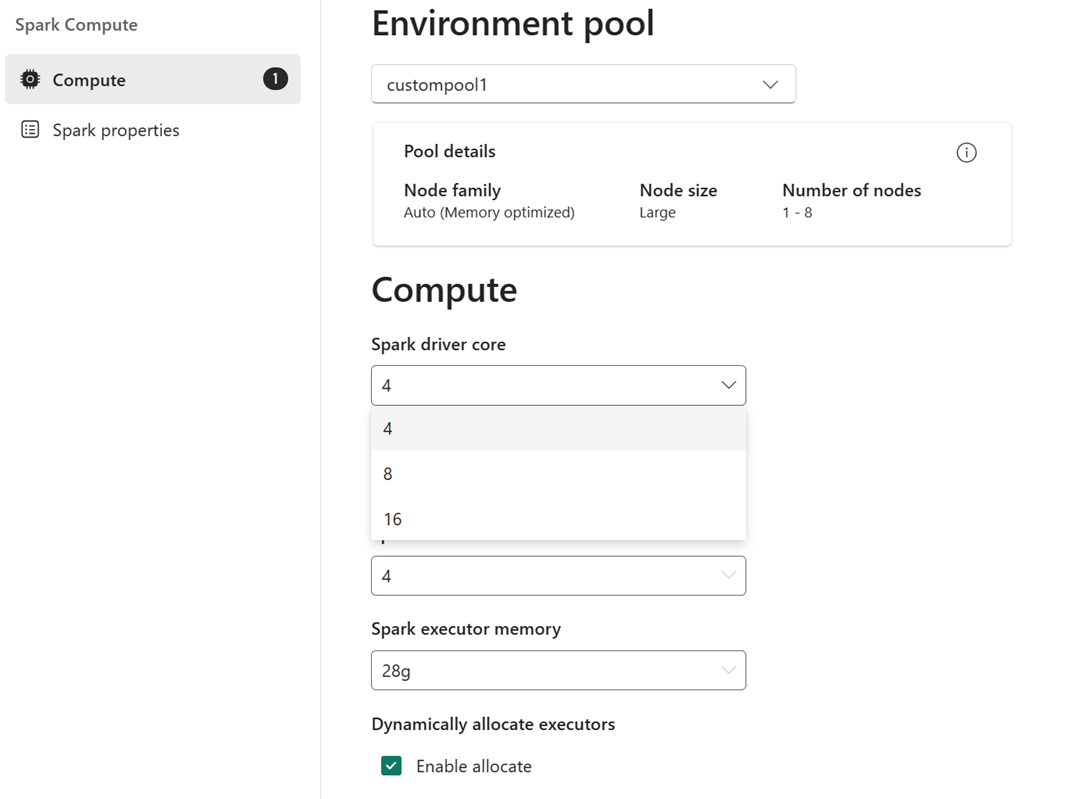
После выбора пула в разделе вычислений можно настроить ядра и память для исполнителей в пределах размеров узлов и ограничений выбранного пула.
Например: вы выбираете пользовательский пул с размером узла большого размера, который составляет 16 виртуальных ядер Spark в качестве пула среды. Затем можно выбрать ядро драйвера или исполнителя, чтобы иметь значение 4, 8 или 16 на основе требований уровня задания. Для памяти, выделенной драйверам и исполнителям, можно выбрать 28 г, 56 г или 112 г, которые находятся в пределах ограничения памяти большого узла.
Дополнительные сведения о размерах вычислений Spark и их ядрах или параметрах памяти см. в статье "Что такое вычисления Spark в Microsoft Fabric?".
Связанный контент
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по