Загрузка данных в Lakehouse с помощью записной книжки
В этом руководстве описано, как читать и записывать данные в lakehouse с помощью записной книжки. API Spark и API Pandas поддерживаются для достижения этой цели.
Загрузка данных с помощью API Apache Spark
В ячейке кода записной книжки используйте следующий пример кода, чтобы считывать данные из источника и загружать их в файлы, таблицы или оба раздела озера.
Чтобы указать расположение для чтения, можно использовать относительный путь, если данные находятся в озере по умолчанию текущей записной книжки или использовать абсолютный путь ABFS, если данные находятся из другого озера. Этот путь можно скопировать из контекстного меню данных.
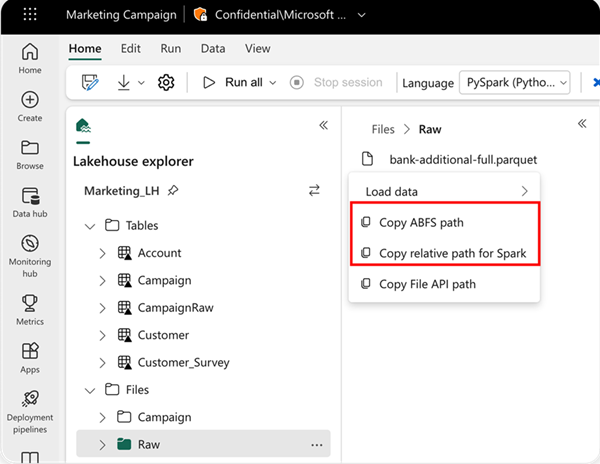
Скопируйте путь ABFS: это возвращает абсолютный путь к файлу
Скопируйте относительный путь для Spark : возвращает относительный путь к файлу в lakehouse по умолчанию.
df = spark.read.parquet("location to read from")
# Keep it if you want to save dataframe as CSV files to Files section of the default Lakehouse
df.write.mode("overwrite").format("csv").save("Files/ " + csv_table_name)
# Keep it if you want to save dataframe as Parquet files to Files section of the default Lakehouse
df.write.mode("overwrite").format("parquet").save("Files/" + parquet_table_name)
# Keep it if you want to save dataframe as a delta lake, parquet table to Tables section of the default Lakehouse
df.write.mode("overwrite").format("delta").saveAsTable(delta_table_name)
# Keep it if you want to save the dataframe as a delta lake, appending the data to an existing table
df.write.mode("append").format("delta").saveAsTable(delta_table_name)
Загрузка данных с помощью API Pandas
Для поддержки API Pandas приложение Lakehouse по умолчанию будет автоматически подключено к записной книжке. Точка подключения — "/lakehouse/default/". Эту точку подключения можно использовать для чтения и записи данных из или в озеро по умолчанию. Параметр "Путь к API копирования файлов" из контекстного меню возвращает путь к API файлов из этой точки подключения. Путь, возвращаемый из параметра Copy ABFS, также работает для API Pandas.
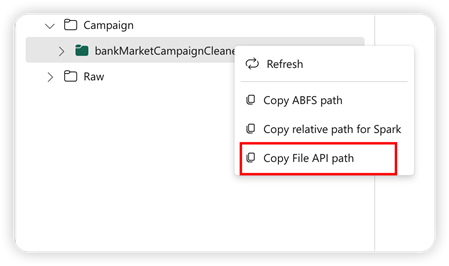
Путь к ФАЙЛу API: возвращает путь к точке подключения озера по умолчанию.
# Keep it if you want to read parquet file with Pandas from the default lakehouse mount point
import pandas as pd
df = pd.read_parquet("/lakehouse/default/Files/sample.parquet")
# Keep it if you want to read parquet file with Pandas from the absolute abfss path
import pandas as pd
df = pd.read_parquet("abfss://DevExpBuildDemo@msit-onelake.dfs.fabric.microsoft.com/Marketing_LH.Lakehouse/Files/sample.parquet")
Совет
Для API Spark используйте параметр "Копировать путь ABFS" или "Копировать относительный путь" для Spark , чтобы получить путь к файлу. Для API Pandas используйте параметр "Копировать путь ABFS" или путь к API копирования файлов, чтобы получить путь к файлу.
Самый быстрый способ работы кода с API Spark или API Pandas — использовать параметр загрузки данных и выбрать API, который требуется использовать. Код будет автоматически создан в новой ячейке кода записной книжки.

Связанный контент
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по