Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Microsoft Fabric — это интегрированная служба аналитики, которая ускоряет анализ данных в хранилищах данных и системах больших данных. Визуализация данных в записных книжках — это ключевая функция, которая позволяет получить представление о данных, помогая пользователям легко определять шаблоны, тенденции и выбросы.
При работе с Apache Spark в Fabric есть встроенные параметры визуализации данных, включая функции диаграммы записной книжки Fabric и доступ к популярным библиотекам с открытым исходным кодом.
Записные книжки Fabric также позволяют преобразовать табличные результаты в настраиваемые диаграммы без написания кода, что обеспечивает более интуитивно понятный и простой процесс изучения данных.
Встроенная команда визуализации — функция display()
Встроенная функция визуализации Fabric позволяет преобразовать DataFrame из Apache Spark, Pandas DataFrames и результаты SQL-запросов в насыщенные интерактивные визуализации данных.
Используя функцию отображения , вы можете отобразить кадры данных PySpark и Scala Spark или устойчивые распределенные наборы данных (RDD) в виде динамических таблиц или диаграмм.
Можно указать количество строк отрисовываемого кадра данных. Значение по умолчанию — 1000. Виджет вывода блокнота

Функцию фильтра можно использовать на глобальной панели инструментов для применения настраиваемых правил к данным. Условие фильтра применяется к указанному столбцу, а результаты отражаются как в представлениях таблиц, так и диаграмм.

Выходные данные оператора SQL по умолчанию используют тот же выходной виджет с display().
Подробный вид таблицы датафрейма
Поддержка свободного выбора в представлении таблицы
По умолчанию представление таблицы отображается при использовании команды display() в записной книжке Fabric. Расширенная предварительная версия кадра данных предлагает интуитивно понятную функцию свободного выбора, предназначенную для улучшения возможностей анализа данных, обеспечивая гибкие, интерактивные параметры выбора. Эта функция позволяет пользователям эффективно перемещаться и изучать кадры данных с легкостью.
Выбор столбцов
- Один столбец: щелкните заголовок столбца, чтобы выбрать весь столбец.
- Несколько столбцов: После выбора одного столбца, нажмите и удерживайте клавишу 'Shift', затем нажмите на заголовок другого столбца, чтобы выбрать несколько столбцов.
выбор строк
- одна строка: Щелкните по заголовку строки, чтобы выбрать всю строку.
- несколько строк: после выбора одной строки нажмите и удерживайте клавишу SHIFT, а затем щелкните другой заголовок строки, чтобы выбрать несколько строк.
предварительный просмотр содержимого ячейки: просмотрите содержимое отдельных ячеек, чтобы получить быстрый и подробный просмотр данных без необходимости писать дополнительный код.
сводка столбцов. Получайте сводку по каждому столбцу, включая распределение данных и ключевую статистику, чтобы быстро понять характеристики данных.
выбор свободных областей: выберите любой непрерывный сегмент таблицы, чтобы получить обзор общих выбранных ячеек и числовых значений в выбранной области.
копирование выбранного содержимого: во всех случаях выбора можно быстро скопировать выбранное содержимое с помощью сочетания клавиш CTRL+C. Выбранные данные копируются в формате CSV, что упрощает обработку в других приложениях.
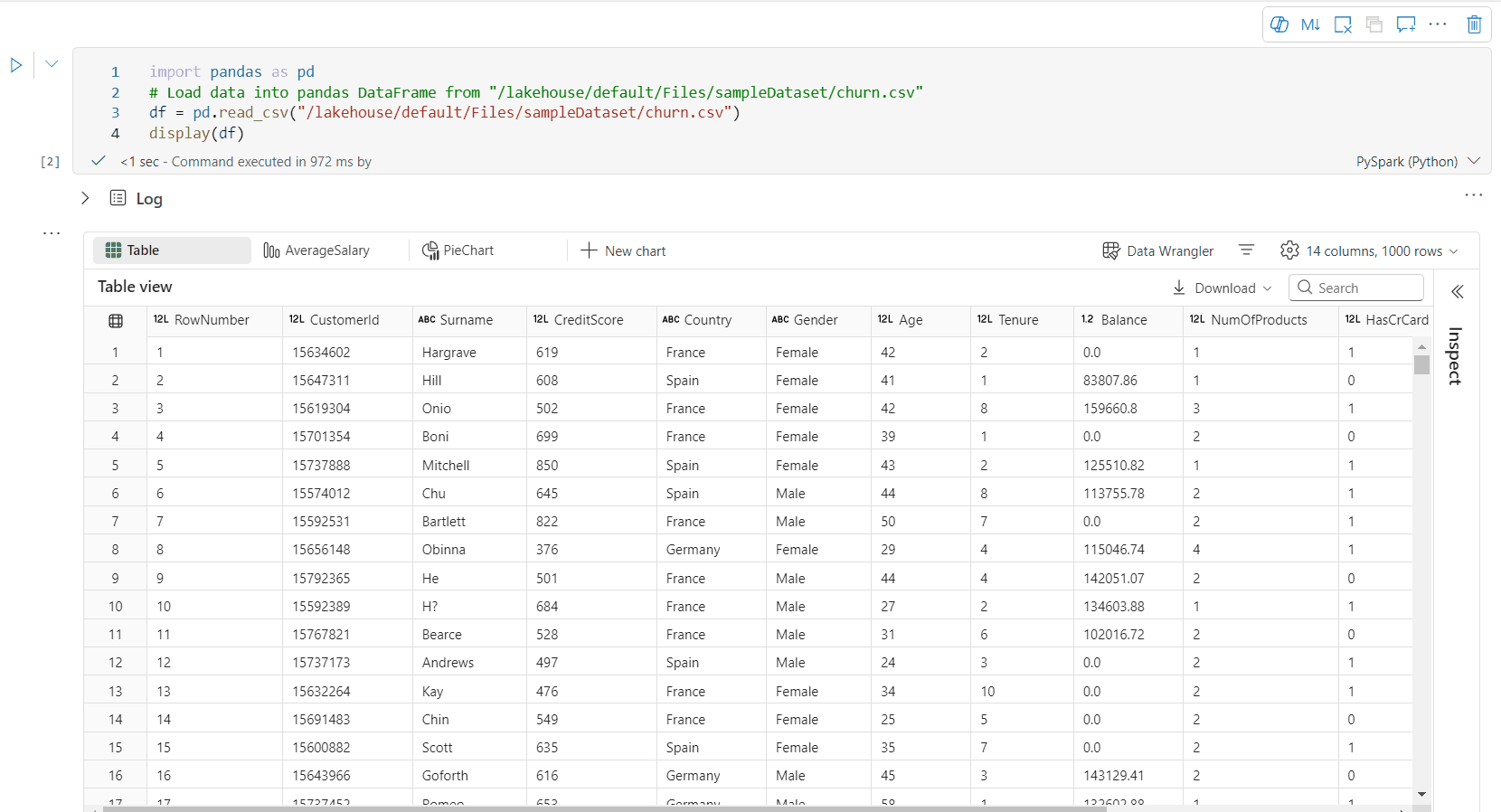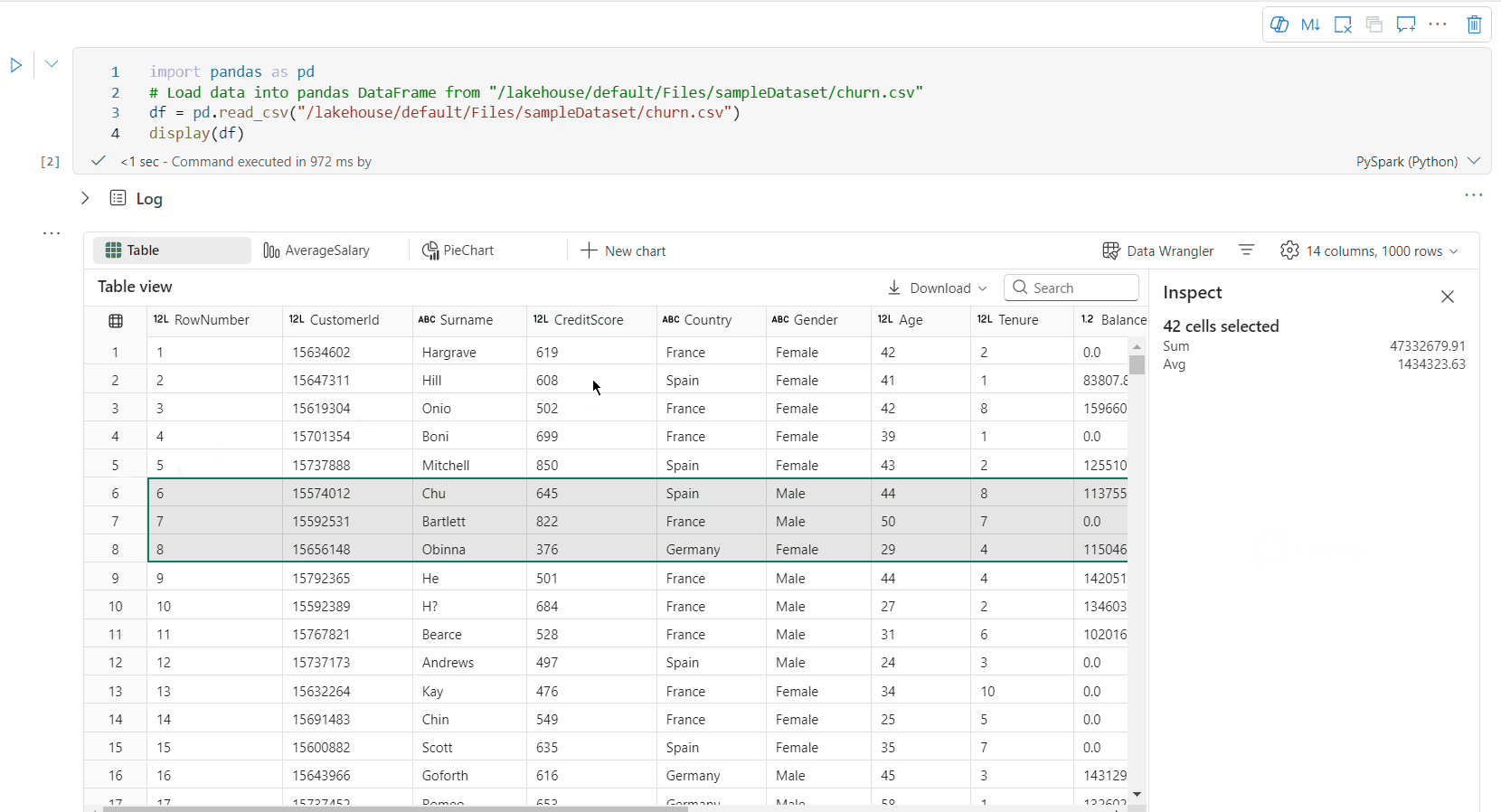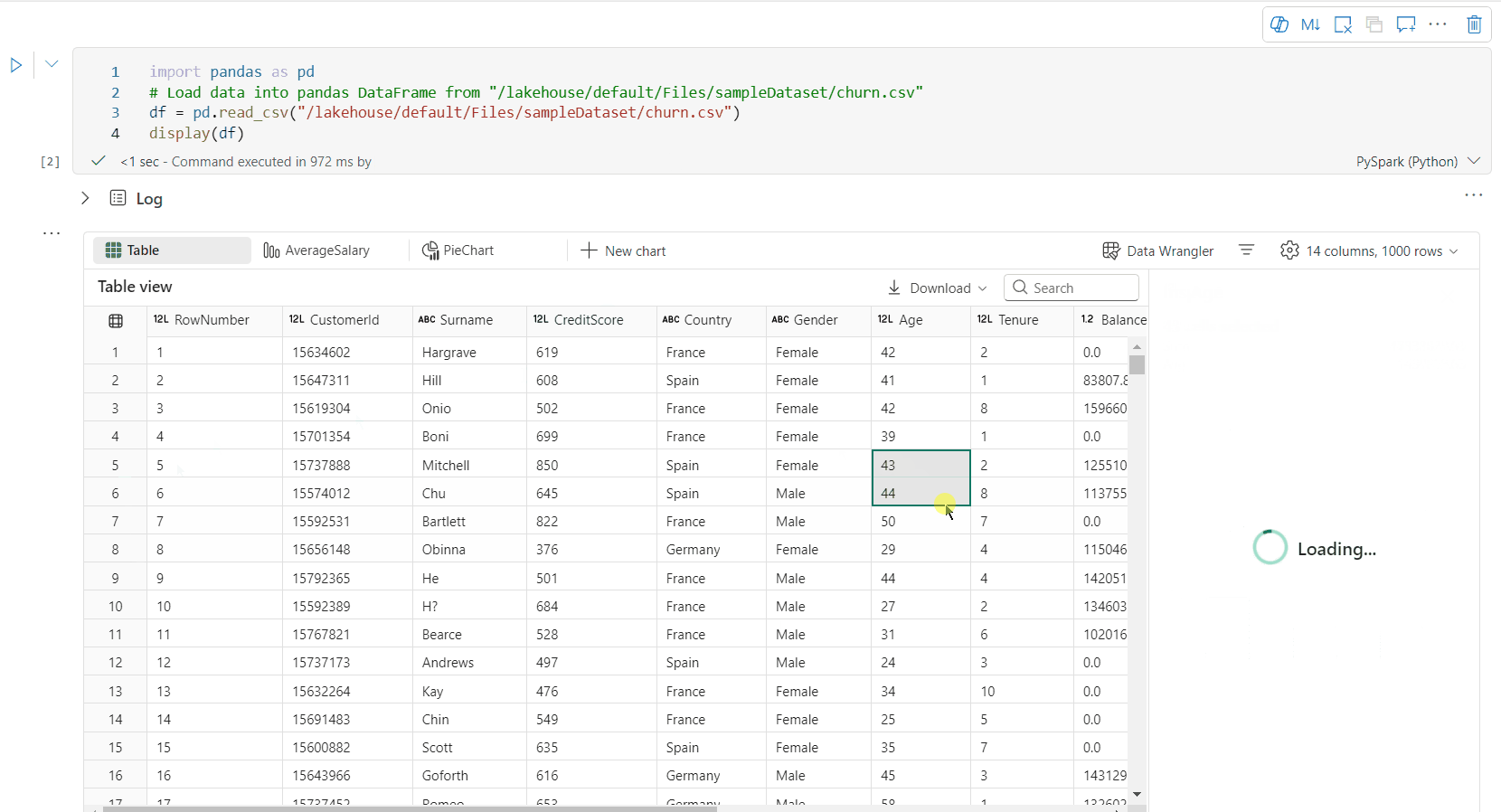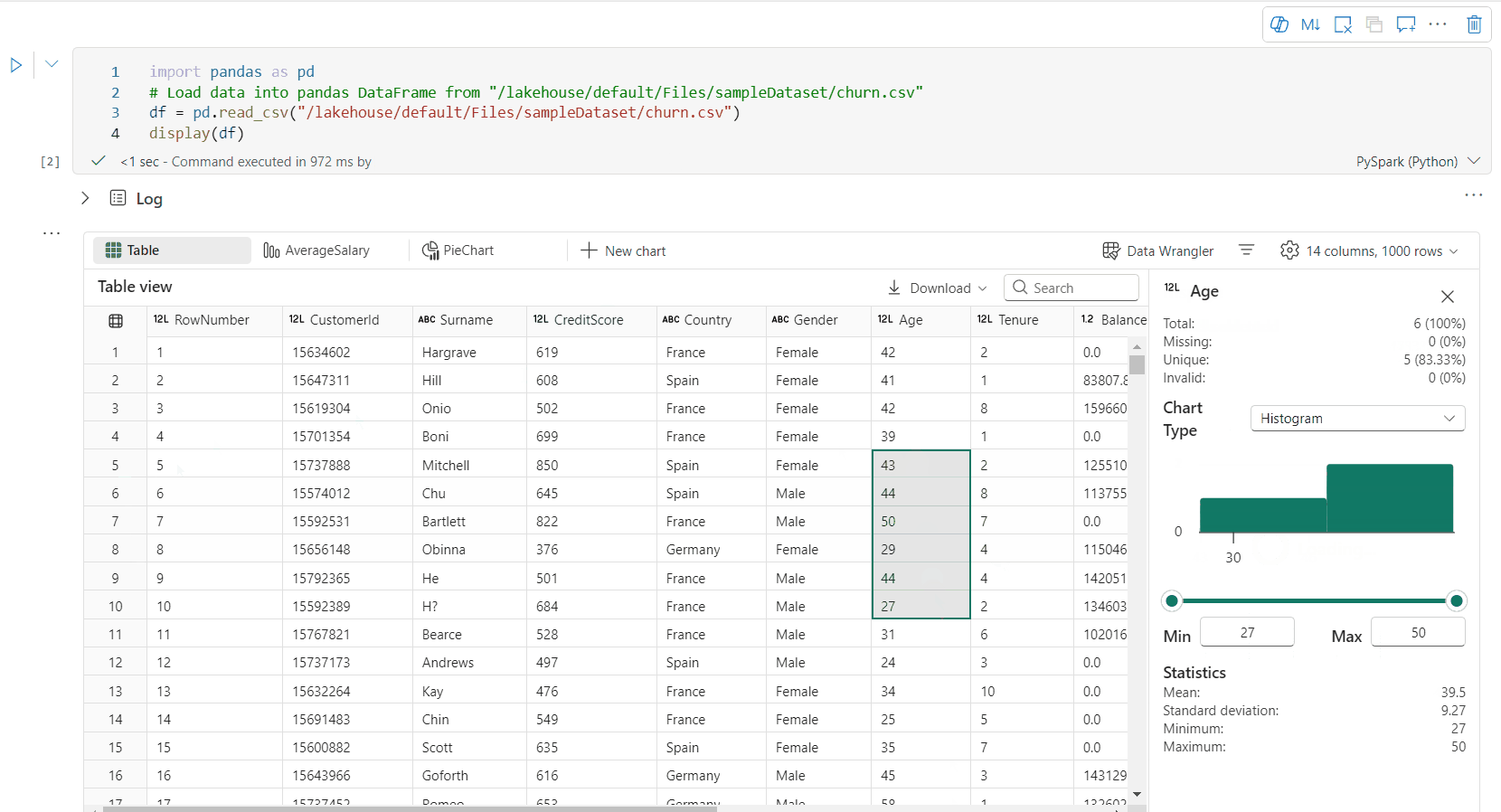

Поддержка профилирования данных с помощью панели проверки

Вы можете проанализировать ваш датафрейм, нажав на кнопку Inspect. Он предоставляет распределение данных в резюме и показывает статистику каждого столбца.
Каждая карточка в боковой панели «Просмотр» соответствует столбцу в фрейме данных; вы можете просмотреть дополнительные сведения, кликнув на карточку или выбрав столбец в таблице.
Вы можете просмотреть детали ячейки, щелкнув по ячейке таблицы. Эта функция полезна, если кадр данных содержит длинный строковый тип содержимого.
Расширенное представление диаграммы с богатым набором данных
Улучшенное представление диаграммы в команде display() обеспечивает более понятный и динамический способ визуализации данных.
Основные улучшения:
Поддержка нескольких диаграмм: добавьте до пяти диаграмм в одном мини-приложении вывода дисплея(), выбрав "Создать диаграмму", чтобы упростить сравнение между различными столбцами.
Рекомендации по смарт-диаграммам. Получение списка предлагаемых диаграмм на основе кадра данных. Выберите изменение рекомендуемой визуализации или создание пользовательской диаграммы с нуля.

Гибкая настройка: персонализация визуализаций с настраиваемыми параметрами, которые адаптируются на основе выбранного типа диаграммы.
Категория Основные параметры Описание Тип диаграммы Функция отображения поддерживает широкий диапазон типов диаграмм, включая гистограммы, точечные диаграммы, линейные графики, сводные таблицы и многое другое. Заголовок Заголовок Заголовок диаграммы. Заголовок Субтитры Подзаголовок диаграммы с дополнительными описаниями. Данные Ось X Укажите ключ диаграммы. Данные Ось Y Укажите значения диаграммы. Легенда Показать легенду Включить/отключить условные обозначения. Легенда Позиция Настройте положение легенды. Другое Группа серий Используйте эту конфигурацию для определения групп для агрегирования. Другое Аггрегация Используйте этот метод для агрегации данных в вашей визуализации. Другое сложенный Настройте стиль отображения результата. Другое Отсутствующие значения и NULL-значения Настройте способ отображения отсутствующих значений или значений NULL на диаграмме. Примечание
Кроме того, можно указать количество отображаемых строк с параметром по умолчанию 1000. Виджет дисплея ноутбука поддерживает просмотр и профилирование до 10 000 строк кадра данных. Выберите Агрегация по всем результатам, а затем выберите Применить, чтобы применить создание графика ко всей базе данных. Задание Spark активируется при изменении параметра диаграммы. Для выполнения вычисления и отрисовки диаграммы может потребоваться несколько минут.
Категория Дополнительные параметры Описание Цвет Тема Определите набор тематических цветов диаграммы. Ось X Этикетка Укажите метку для оси X. Ось X масштаб Укажите функцию масштабирования оси X. Ось X Диапазон Укажите диапазон значений по оси X. Ось Y Этикетка Укажите метку в оси Y. Ось Y масштаб Укажите функцию шкалы оси Y. Ось Y Диапазон Укажите диапазон значений для оси Y. Экран Показать метки Показать/скрыть метки результатов на графике. Изменения конфигураций вступили в силу немедленно, и все конфигурации автоматически сохраняются в содержимом записной книжки.
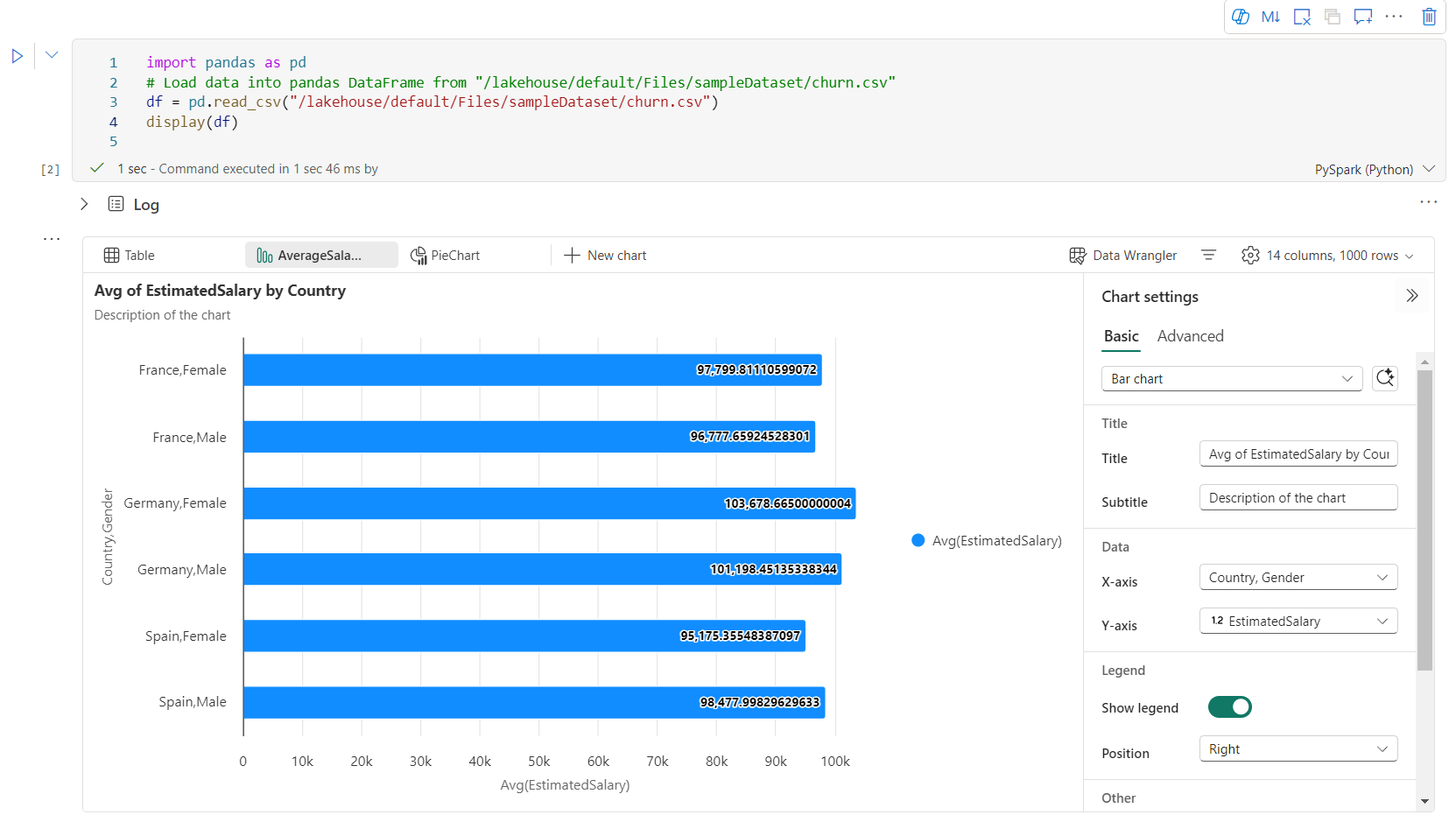
Вы можете легко переименовать, дублировать, удалять или перемещать диаграммы в меню вкладок диаграммы. Вы также можете перетаскивать вкладки для их переупорядочения. Первая вкладка будет отображаться в качестве значения по умолчанию при открытии записной книжки.
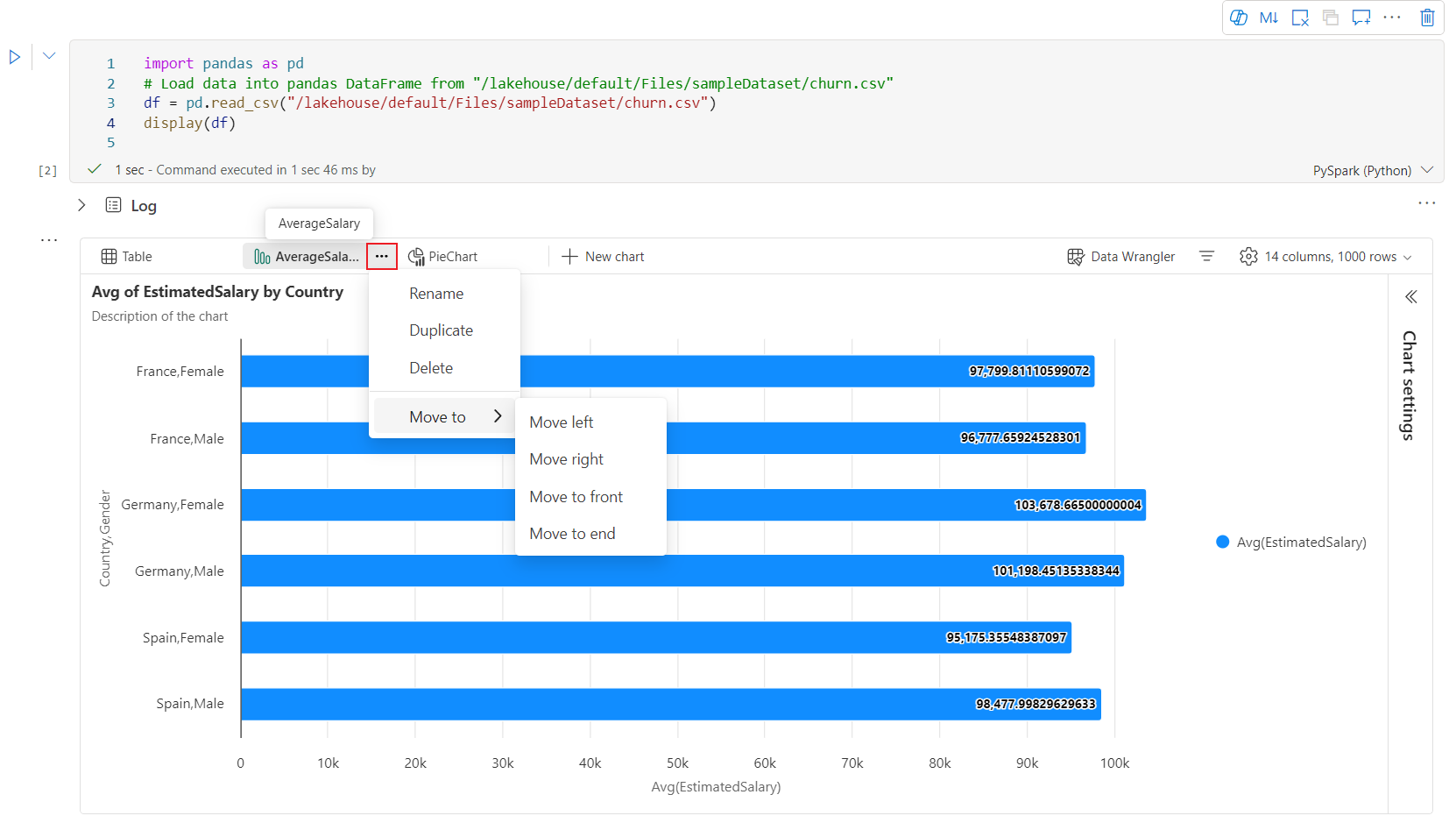
Интерактивная панель инструментов доступна в новом интерфейсе диаграммы при наведении указателя мыши на диаграмму. Поддержка таких операций, как приближение, уменьшение, выбор для увеличения, сброс, панорамирование, редактирование аннотаций и т. д.
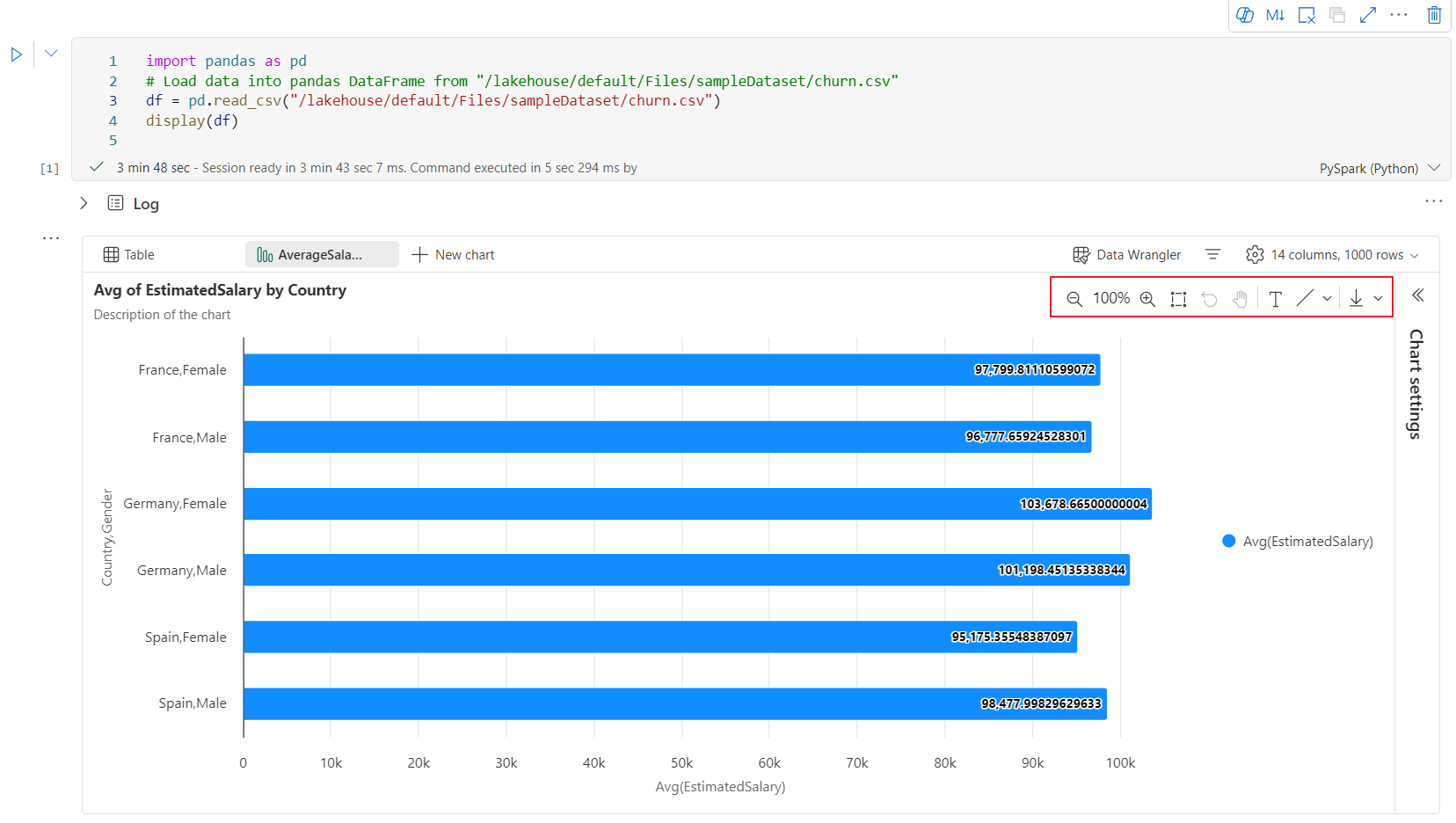
Здесь приведён пример аннотации диаграммы.





Показать краткий обзор
Используйте display(df, summary = true), чтобы проверить статистическое резюме заданного Apache Spark DataFrame. Сводка содержит имя столбца, тип столбца, уникальные значения и отсутствующие значения для каждого столбца. Можно также выбрать конкретный столбец, чтобы увидеть минимальное значение, максимальное значение, среднее значение и стандартное отклонение.

опция displayHTML()
В блокнотах Fabric поддерживается HTML-графика с использованием функции displayHTML.
Следующее изображение является примером создания визуализаций с использованием D3.js.

Чтобы создать эту визуализацию, выполните следующий код.
displayHTML("""<!DOCTYPE html>
<meta charset="utf-8">
<!-- Load d3.js -->
<script src="https://d3js.org/d3.v4.js"></script>
<!-- Create a div where the graph will take place -->
<div id="my_dataviz"></div>
<script>
// set the dimensions and margins of the graph
var margin = {top: 10, right: 30, bottom: 30, left: 40},
width = 400 - margin.left - margin.right,
height = 400 - margin.top - margin.bottom;
// append the svg object to the body of the page
var svg = d3.select("#my_dataviz")
.append("svg")
.attr("width", width + margin.left + margin.right)
.attr("height", height + margin.top + margin.bottom)
.append("g")
.attr("transform",
"translate(" + margin.left + "," + margin.top + ")");
// Create Data
var data = [12,19,11,13,12,22,13,4,15,16,18,19,20,12,11,9]
// Compute summary statistics used for the box:
var data_sorted = data.sort(d3.ascending)
var q1 = d3.quantile(data_sorted, .25)
var median = d3.quantile(data_sorted, .5)
var q3 = d3.quantile(data_sorted, .75)
var interQuantileRange = q3 - q1
var min = q1 - 1.5 * interQuantileRange
var max = q1 + 1.5 * interQuantileRange
// Show the Y scale
var y = d3.scaleLinear()
.domain([0,24])
.range([height, 0]);
svg.call(d3.axisLeft(y))
// a few features for the box
var center = 200
var width = 100
// Show the main vertical line
svg
.append("line")
.attr("x1", center)
.attr("x2", center)
.attr("y1", y(min) )
.attr("y2", y(max) )
.attr("stroke", "black")
// Show the box
svg
.append("rect")
.attr("x", center - width/2)
.attr("y", y(q3) )
.attr("height", (y(q1)-y(q3)) )
.attr("width", width )
.attr("stroke", "black")
.style("fill", "#69b3a2")
// show median, min and max horizontal lines
svg
.selectAll("toto")
.data([min, median, max])
.enter()
.append("line")
.attr("x1", center-width/2)
.attr("x2", center+width/2)
.attr("y1", function(d){ return(y(d))} )
.attr("y2", function(d){ return(y(d))} )
.attr("stroke", "black")
</script>
"""
)
Внедрение отчета Power BI в записную книжку
Важный
Эта функция доступна в предварительной версии.
Пакет Python Powerbiclient теперь поддерживается нативно в ноутбуках Fabric. Вам не нужно делать дополнительную настройку (например, процесс аутентификации) в среде выполнения Fabric notebook Spark 3.4. Просто импортируйте powerbiclient, а затем продолжайте своё исследование. Чтобы узнать больше о том, как использовать пакет powerbiclient, смотрите документацию по powerbiclient.
Powerbiclient поддерживает следующие ключевые функции.
Отобразить существующий отчет Power BI
Вы можете легко внедрять и взаимодействовать с отчетами Power BI в записных книжках с несколькими строками кода.
На следующем рисунке показан пример отрисовки существующего отчета Power BI.

Выполните следующий код, чтобы отобразить существующий отчет Power BI.
from powerbiclient import Report
report_id="Your report id"
report = Report(group_id=None, report_id=report_id)
report
Создайте визуализацию отчетов из Spark DataFrame
Используя Spark DataFrame в вашей записной книжке, вы можете быстро создавать наглядные визуализации. Вы также можете выбрать "Сохранить в внедренном отчете", чтобы создать элемент отчета в целевой рабочей области.
Следующее изображение является примером QuickVisualize() из Spark DataFrame.

Выполните следующий код, чтобы отобразить отчет из Spark DataFrame.
# Create a spark dataframe from a Lakehouse parquet table
sdf = spark.sql("SELECT * FROM testlakehouse.table LIMIT 1000")
# Create a Power BI report object from spark data frame
from powerbiclient import QuickVisualize, get_dataset_config
PBI_visualize = QuickVisualize(get_dataset_config(sdf))
# Render new report
PBI_visualize
Создайте визуализацию отчетов из DataFrame pandas
Вы также можете создавать отчеты на основе DataFrame библиотеки pandas в блокноте.
Следующее изображение является примером QuickVisualize() из pandas DataFrame.

Выполните следующий код, чтобы отобразить отчет из Spark DataFrame.
import pandas as pd
# Create a pandas dataframe from a URL
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv")
# Create a pandas dataframe from a Lakehouse csv file
from powerbiclient import QuickVisualize, get_dataset_config
# Create a Power BI report object from your data
PBI_visualize = QuickVisualize(get_dataset_config(df))
# Render new report
PBI_visualize
Популярные библиотеки
Когда речь идет о визуализации данных, Python предлагает несколько библиотек для создания графиков, которые оснащены множеством различных функций. По умолчанию каждый пул Apache Spark в Fabric содержит набор отобранных и популярных библиотек с открытым исходным кодом.
Matplotlib
Вы можете отображать стандартные библиотеки для построения графиков, такие как Matplotlib, используя встроенные функции рендеринга для каждой библиотеки.
Следующее изображение является примером создания столбчатой диаграммы с использованием Matplotlib.


Запустите следующий пример кода, чтобы нарисовать эту столбчатую диаграмму.
# Bar chart
import matplotlib.pyplot as plt
x1 = [1, 3, 4, 5, 6, 7, 9]
y1 = [4, 7, 2, 4, 7, 8, 3]
x2 = [2, 4, 6, 8, 10]
y2 = [5, 6, 2, 6, 2]
plt.bar(x1, y1, label="Blue Bar", color='b')
plt.bar(x2, y2, label="Green Bar", color='g')
plt.plot()
plt.xlabel("bar number")
plt.ylabel("bar height")
plt.title("Bar Chart Example")
plt.legend()
plt.show()
эффект боке
Вы можете отобразить HTML или интерактивные библиотеки, такие как bokeh, используя displayHTML(df).
Следующее изображение демонстрирует пример нанесения глифов на карту с помощью bokeh.

Чтобы нарисовать это изображение, выполните следующий пример кода.
from bokeh.plotting import figure, output_file
from bokeh.tile_providers import get_provider, Vendors
from bokeh.embed import file_html
from bokeh.resources import CDN
from bokeh.models import ColumnDataSource
tile_provider = get_provider(Vendors.CARTODBPOSITRON)
# range bounds supplied in web mercator coordinates
p = figure(x_range=(-9000000,-8000000), y_range=(4000000,5000000),
x_axis_type="mercator", y_axis_type="mercator")
p.add_tile(tile_provider)
# plot datapoints on the map
source = ColumnDataSource(
data=dict(x=[ -8800000, -8500000 , -8800000],
y=[4200000, 4500000, 4900000])
)
p.circle(x="x", y="y", size=15, fill_color="blue", fill_alpha=0.8, source=source)
# create an html document that embeds the Bokeh plot
html = file_html(p, CDN, "my plot1")
# display this html
displayHTML(html)
Plotly
Вы можете визуализировать HTML или интерактивные библиотеки, такие как Plotly, используя displayHTML().
Чтобы нарисовать это изображение, выполните следующий пример кода.

from urllib.request import urlopen
import json
with urlopen('https://raw.githubusercontent.com/plotly/datasets/master/geojson-counties-fips.json') as response:
counties = json.load(response)
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv",
dtype={"fips": str})
import plotly
import plotly.express as px
fig = px.choropleth(df, geojson=counties, locations='fips', color='unemp',
color_continuous_scale="Viridis",
range_color=(0, 12),
scope="usa",
labels={'unemp':'unemployment rate'}
)
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
# create an html document that embeds the Plotly plot
h = plotly.offline.plot(fig, output_type='div')
# display this html
displayHTML(h)
Панды
Выходные данные HTML pandas DataFrames можно просмотреть как выходные данные по умолчанию. Записные книжки Fabric автоматически отображают стильное HTML-содержимое.

import pandas as pd
import numpy as np
df = pd.DataFrame([[38.0, 2.0, 18.0, 22.0, 21, np.nan],[19, 439, 6, 452, 226,232]],
index=pd.Index(['Tumour (Positive)', 'Non-Tumour (Negative)'], name='Actual Label:'),
columns=pd.MultiIndex.from_product([['Decision Tree', 'Regression', 'Random'],['Tumour', 'Non-Tumour']], names=['Model:', 'Predicted:']))
df