Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Среда выполнения Fabric обеспечивает простую интеграцию с Azure. Она предоставляет сложную среду для проектов по проектированию и обработке и анализу данных, использующих Apache Spark. В этой статье представлен обзор основных функций и компонентов среды выполнения Fabric 1.3.
Среда выполнения Microsoft Fabric 1.3 — это версия среды выполнения общедоступной версии, которая включает следующие компоненты и обновления, предназначенные для улучшения возможностей обработки данных:
Apache Spark 3.5
Операционная система: Mariner 2.0 (Azure Linux 2.0)
Java: 11.
Scala: 2.12.17
Python: 3.11
Delta Lake: 3.2
R: 4.4.1
Совет
Среда выполнения Fabric 1.3 включает поддержку собственного обработчика выполнения, что может значительно повысить производительность без дополнительных затрат. Чтобы включить собственный модуль выполнения для всех заданий и записных книжек в вашей среде, перейдите к параметрам среды, выберите вычисление Spark, перейдите на вкладку "Ускорение" и установите флажок "Включить собственный обработчик выполнения". После сохранения и публикации этот параметр применяется в среде, поэтому все новые задания и записные книжки автоматически наследуют и получают преимущества от расширенных возможностей производительности.
Интеграция среды выполнения 1.3
Замечание
Сведения обо всех доступных средах выполнения Fabric и их текущем состоянии см. в разделе " Среда выполнения Apache Spark" в Fabric.
Используйте следующие инструкции для интеграции среды выполнения 1.3 в рабочую область и использования новых функций:
Перейдите на вкладку "Параметры рабочей области" в рабочей области Fabric.
Перейдите на вкладку Инжиниринг данных/Наука и выберите "Параметры Spark".
Перейдите на вкладку Среда.
Под версиями среды выполнения разверните раскрывающийся список.
Выберите 1.3 (Spark 3.5, Delta 3.2) и сохраните изменения. Это действие задает 1.3 в качестве среды выполнения по умолчанию для рабочей области.
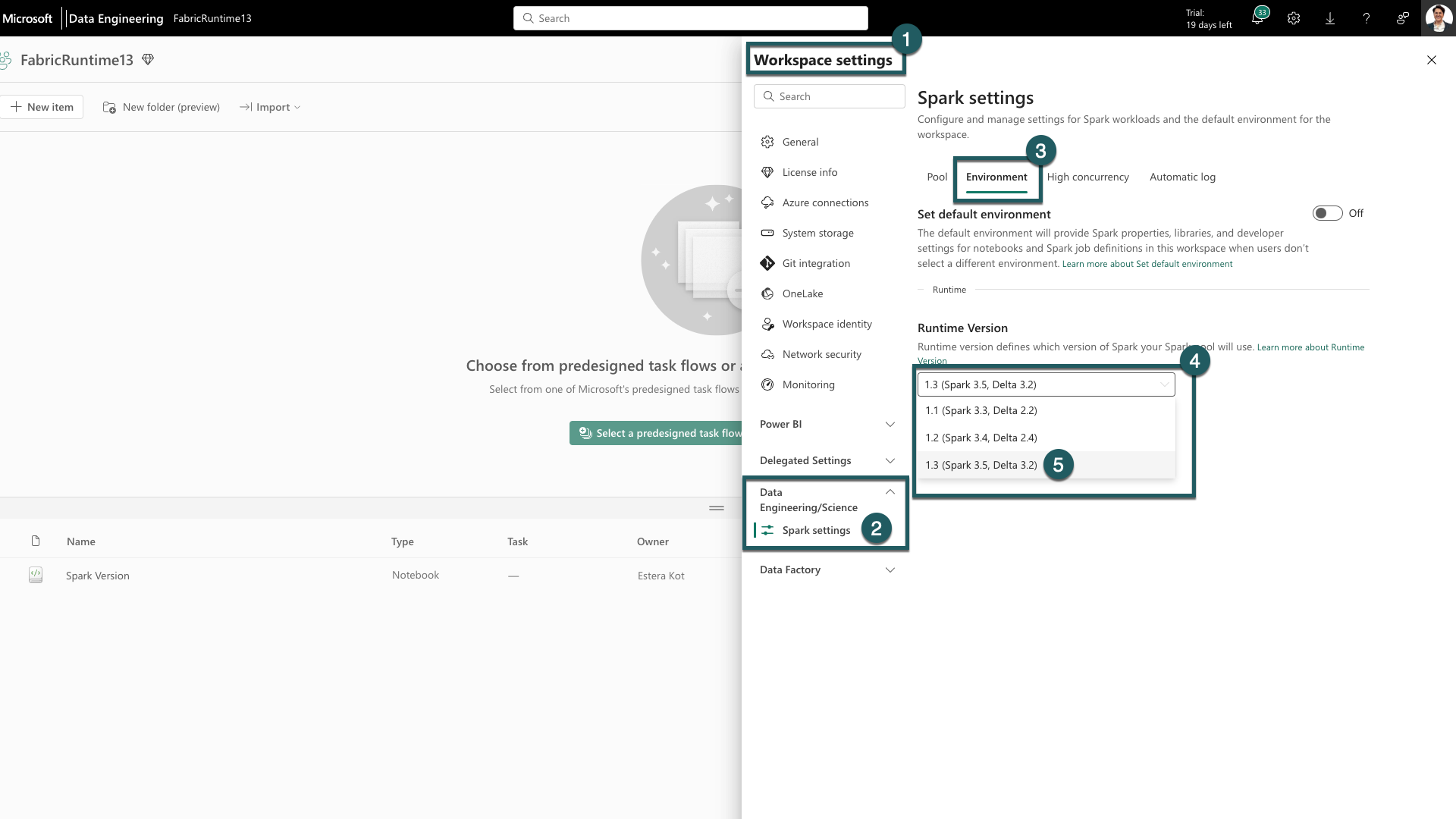

Теперь вы можете начать работу с новыми улучшениями и функциями, представленными в среде выполнения Fabric 1.3 (Spark 3.5 и Delta Lake 3.2).
Сведения об Apache Spark 3.5
Apache Spark 3.5.0 — шестая версия серии 3.x. Эта версия является продуктом обширной совместной работы в сообществе с открытым исходным кодом, устраняя более 1300 проблем, как записано в Jira.
В этой версии существует обновление в совместимости для структурированной потоковой передачи. Кроме того, этот выпуск расширяет функциональные возможности PySpark и SQL. Он добавляет такие функции, как клаузула идентификатора SQL, именованные аргументы в вызовах функций SQL, а также включение функций SQL для HyperLogLog приблизительных агрегатов.
Другие новые возможности также включают функции таблицы, определяемые пользователем на Python, упрощение распределенного обучения с помощью DeepSpeed и новые структурированные возможности потоковой передачи, такие как распространение водяного знака и операция dropDuplicatesWithinWatermark.
Вы можете проверить полный список и подробные изменения здесь: Релиз Spark 3.5.0.
Сведения о Delta Spark
Delta Lake 3.2 отмечает коллективное обязательство обеспечить совместимость Delta Lake в разных форматах, упростить работу с ним и повысить производительность. Delta Spark 3.2 построен на основе Apache Spark™ 3.5. Артефакт Delta Spark maven переименован из delta-core в delta-spark.
Здесь можно проверить полный список и подробные изменения https://docs.delta.io/index.html.
Компоненты и библиотеки
Чтобы получить актуальную информацию, подробный список изменений и конкретные заметки о выпуске для сред выполнения Fabric, проверяйте и подписывайтесь на выпуски и обновления Spark Runtimes.
Замечание
EventHubConnector устарел в Среде выполнения Fabric 1.3 (Spark 3.5) и будет удален из будущих версий среды выполнения Fabric. Клиентам рекомендуется использовать соединитель Kafka Spark, так как центры событий уже совместимы с Kafka. Дополнительные сведения об использовании соединителя Kafka Spark с центрами событий см. здесь: руководство по Центрам событий Kafka Spark
Связанный контент
- Узнайте о средах выполнения Apache Spark в Fabric: обзор, управление версиями, поддержка нескольких сред выполнения и обновление протокола Delta Lake
- Руководство по миграции Spark Core
- Руководства по миграции SQL, датасетов и DataFrame
- Руководство по миграции структурированной потоковой передачи
- Руководство по миграции MLlib (Машинное обучение)
- Руководство по миграции PySpark (Python в Spark)
- Руководство по миграции SparkR (R в Spark)