Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этом руководстве вы создадите lakehouse, загрузите образцы данных в таблицу Delta, примените преобразования там, где это необходимо, и затем создадите отчеты.
Подсказка
Это руководство является частью серии. После завершения работы с этим руководством продолжайте загружать данные в Lakehouse, чтобы создать полноценный корпоративный Lakehouse, используя конвейеры Azure Data Factory, записные книжки Spark и расширенные методы создания отчетов.
Ниже приведен контрольный список действий, описанных в этом руководстве.
Если у вас нет Microsoft Fabric, зарегистрируйтесь для бесплатной пробной версии.
Предварительные требования
- Перед созданием lakehouse, необходимо создать рабочую область Fabric.
- Перед приемом CSV-файла необходимо настроить OneDrive. Если вы не настроили OneDrive, зарегистрируйтесь для бесплатной пробной версии Microsoft 365: бесплатная пробная версия — попробуйте Microsoft 365 в течение месяца. Инструкции по настройке см. в разделе "Настройка OneDrive".
Зачем мне нужен OneDrive для этого руководства?
Для этого руководства требуется OneDrive, так как процесс приема данных использует OneDrive в качестве базового механизма хранения для отправки файлов. При загрузке CSV-файла в Fabric, он временно хранится в вашей учетной записи OneDrive перед тем, как будет интегрирован в lakehouse. Эта интеграция обеспечивает безопасную и удобную передачу файлов в экосистеме Microsoft 365.
Этап загрузки не работает, если у вас не настроен OneDrive, так как Fabric не может получить доступ к загруженному файлу. Если у вас уже есть данные, доступные в вашем Lakehouse или другом поддерживаемом местоположении, OneDrive не обязателен.
Примечание.
Если у вас уже есть данные в lakehouse, вы можете использовать эти данные вместо примера CSV-файла. Чтобы проверить, связаны ли данные с lakehouse, используйте обозреватель Lakehouse или конечную точку аналитики SQL для просмотра таблиц, файлов и папок. Дополнительные сведения о проверке см. в обзоре Lakehouse и запросе таблиц в Lakehouse через SQL-аналитическую точку доступа.
Создание озера-хранилища
В этом разделе описано, как создать lakehouse в Fabric.
В Fabricвыберите Рабочие области на панели навигации.
Чтобы открыть рабочую область, введите её имя в поле поиска, находящемся вверху, и выберите его из результатов поиска.
В рабочей области выберите новый элемент, введите Lakehouse в поле поиска, а затем выберите Lakehouse.
В диалоговом окне New lakehouse введите wwilakehouse в поле "Имя".
Выберите "Создать", чтобы создать и открыть новый лакхаус.

Загрузка образцов данных
В этом разделе вы загружаете образцы данных клиента в lakehouse.
Примечание.
Если вы не настроили OneDrive, зарегистрируйтесь для бесплатной пробной версии Microsoft 365: бесплатная пробная версия — попробуйте Microsoft 365 в течение месяца.
Скачайте файл dimension_customer.csv из репозитория примеров Fabric.
Выберите Lakehouse и перейдите на вкладку "Главная ".
Выберите Получить данные>Новый поток данных 2-го поколения, чтобы создать новый поток данных. Этот поток данных используется для загрузки образцовых данных в lakehouse. Кроме того, в разделе Получение данных в Lakehouse можно выбрать плитку Новый Dataflow Gen2.
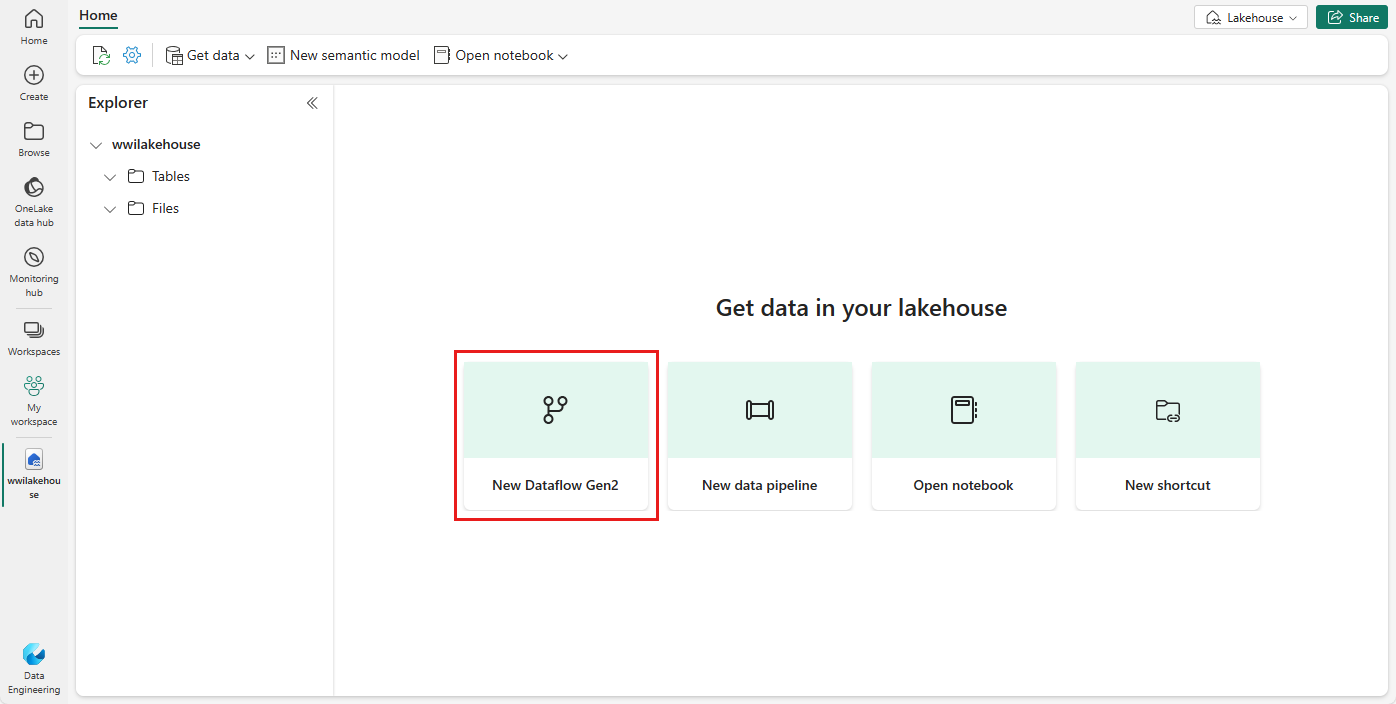
В области "Новый поток данных 2-го поколения " введите данные измерения клиента в поле "Имя " и нажмите кнопку "Создать".
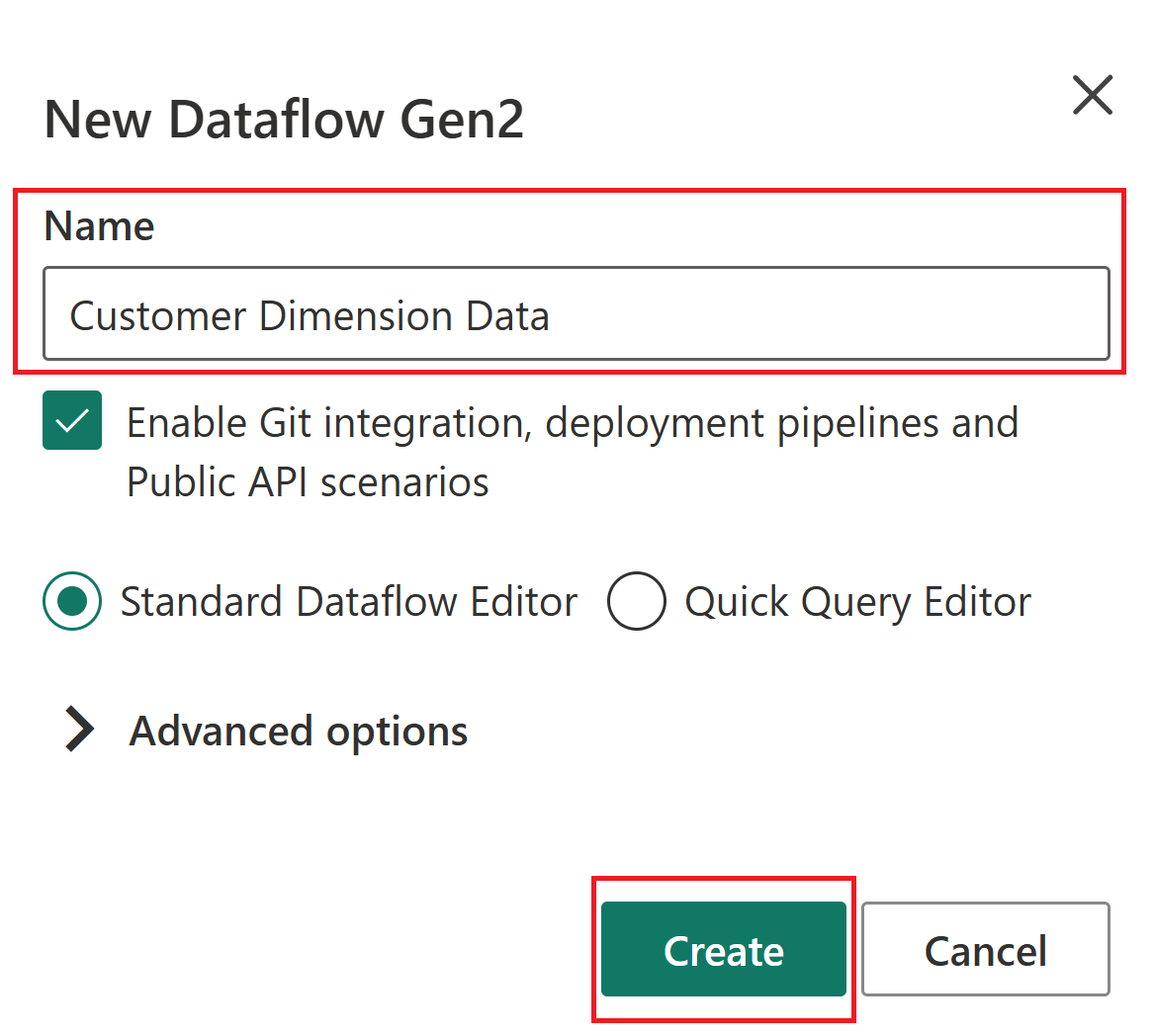
На вкладке Главная потоков данных выберите плитку Импорт из текстового или CSV-файла.
На экране "Подключиться к источнику данных" выберите переключатель "Отправить файл".
Просмотрите или перетащите файл dimension_customer.csv, загруженный на шаге 1. После отправки файла нажмите кнопку "Далее".
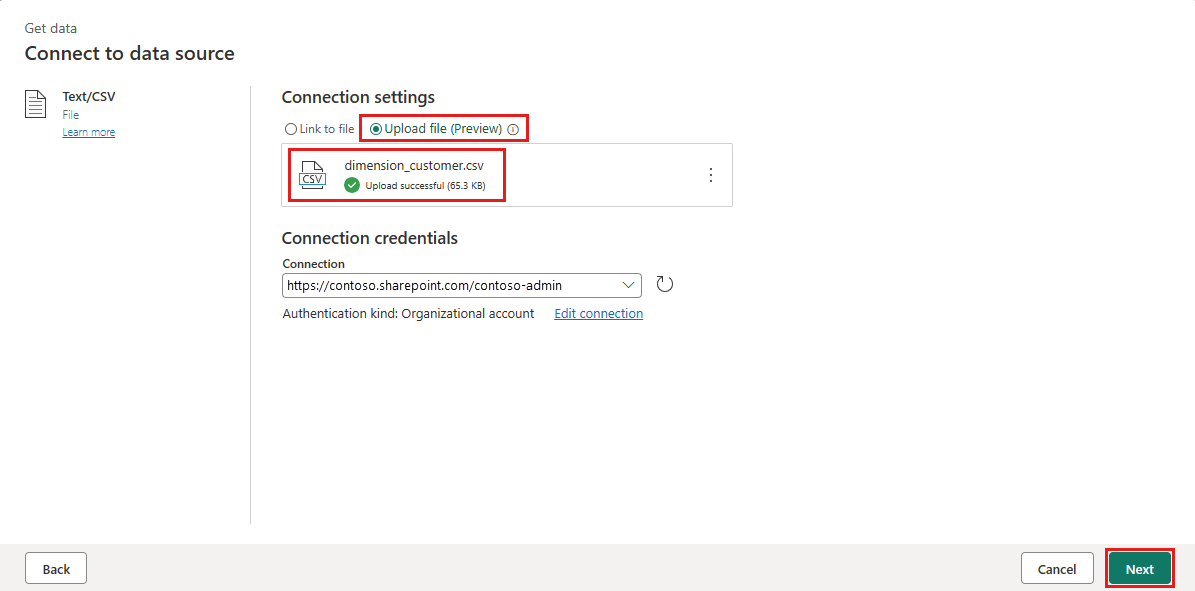
На странице данных предварительного просмотра можно просмотреть данные. Затем нажмите кнопку "Создать ", чтобы продолжить и вернуться на холст потока данных.



Преобразуйте и загрузите данные в Lakehouse
В этом разделе описано, как преобразовать данные на основе бизнес-требований и загрузить их в lakehouse.
В области параметров запроса убедитесь, что для поля "Имя " задано значение dimension_customer. Это имя используется в качестве имени таблицы в хранилище данных, поэтому оно должно быть в нижнем регистре и не должно содержать пробелы.
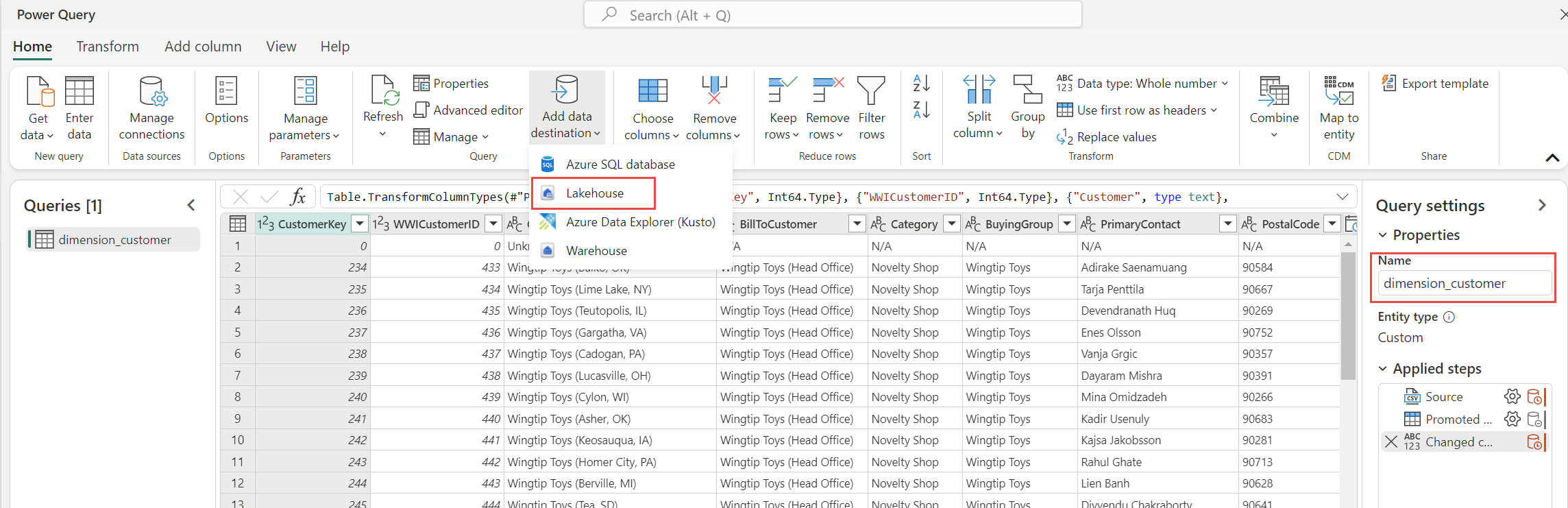
Поскольку вы создали поток данных из lakehouse, назначение данных автоматически устанавливается на ваш lakehouse. Это можно проверить, проверив назначение данных в области параметров запроса.
Подсказка
Если вы создаете поток данных из рабочей области вместо озера, необходимо вручную добавить назначение данных. Дополнительные сведения см. в статье о назначении по умолчанию для потока данных 2-го поколенияи назначениях данных и управляемых параметрах.
На холсте потока данных можно легко преобразовать данные на основе бизнес-требований. Для простоты мы не делаем никаких изменений в этом руководстве. Чтобы продолжить, нажмите кнопку "Сохранить и запустить " на панели инструментов.
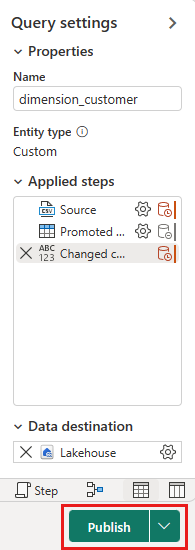
Дождитесь, пока выполнение потока данных завершится. Когда процесс выполняется, вы видите вращающийся индикатор состояния.
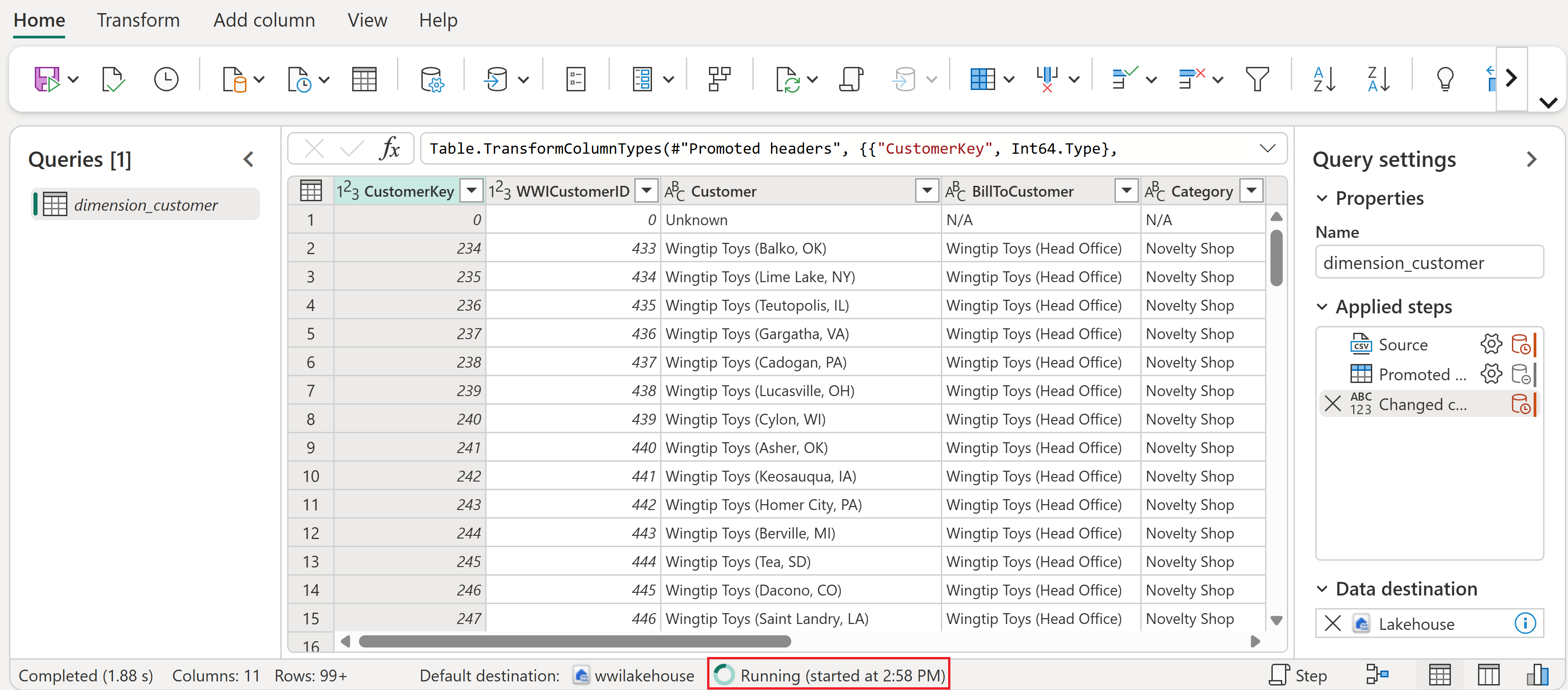
После успешного выполнения потока данных выберите lakehouse в верхней строке меню, чтобы открыть его.
В обозревателе lakehouse найдите схему dbo в таблицах, выберите меню ... (многоточие) рядом с ним, а затем нажмите кнопку "Обновить". Это запускает поток данных и загружает данные из исходного файла в таблицу Lakehouse.
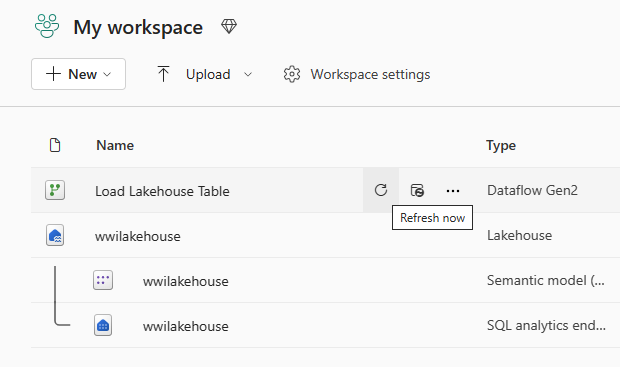
После завершения обновления разверните схему dbo и просмотрите таблицу Delta dimension_customer. Выберите таблицу для предварительного просмотра данных.
Вы можете использовать конечную точку аналитики SQL в lakehouse для запроса данных с помощью инструкций SQL. Выберите конечную точку аналитики SQL в раскрывающемся меню в правом верхнем углу экрана.
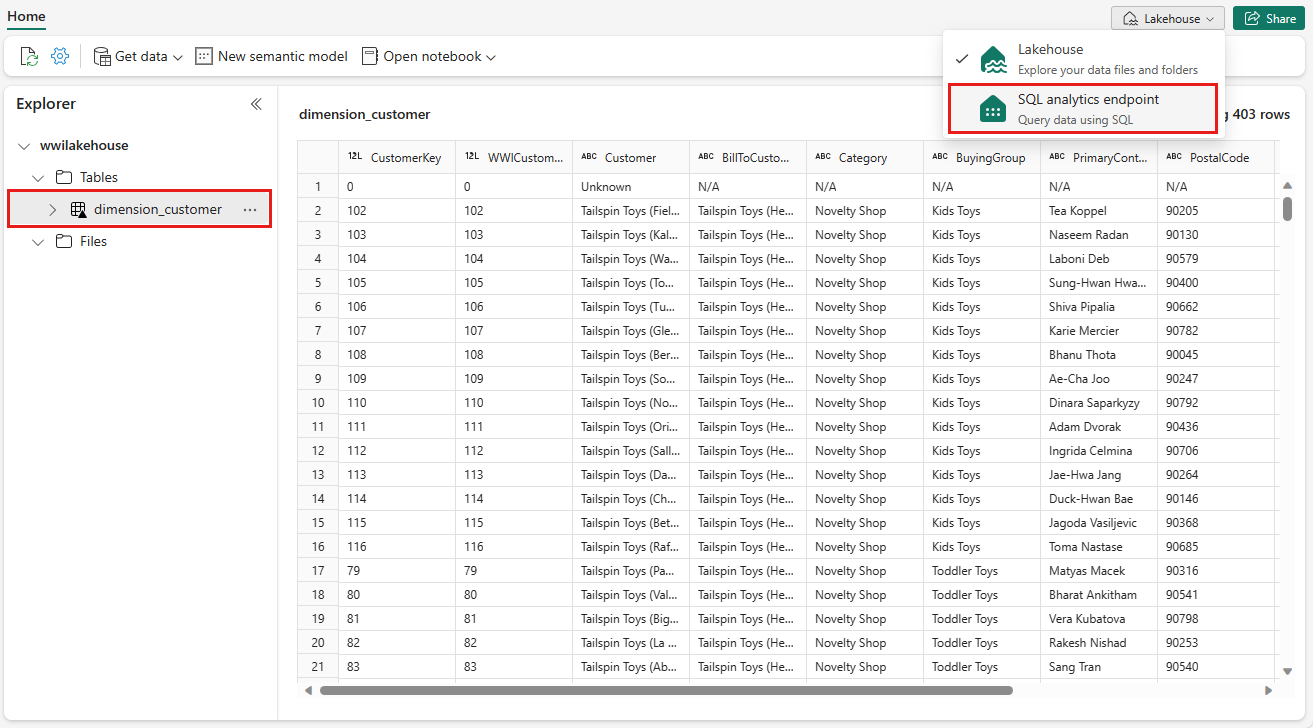
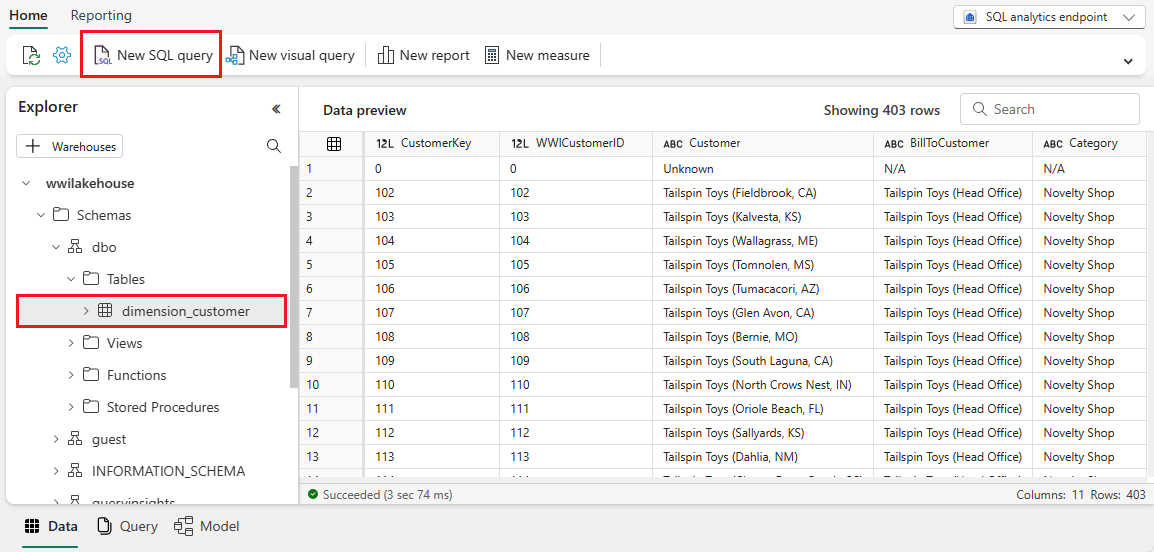
Выберите таблицу dimension_customer , чтобы просмотреть данные. Чтобы написать инструкции SQL, выберите "Создать SQL-запрос " в меню или щелкните плитку "Создать SQL-запрос ".
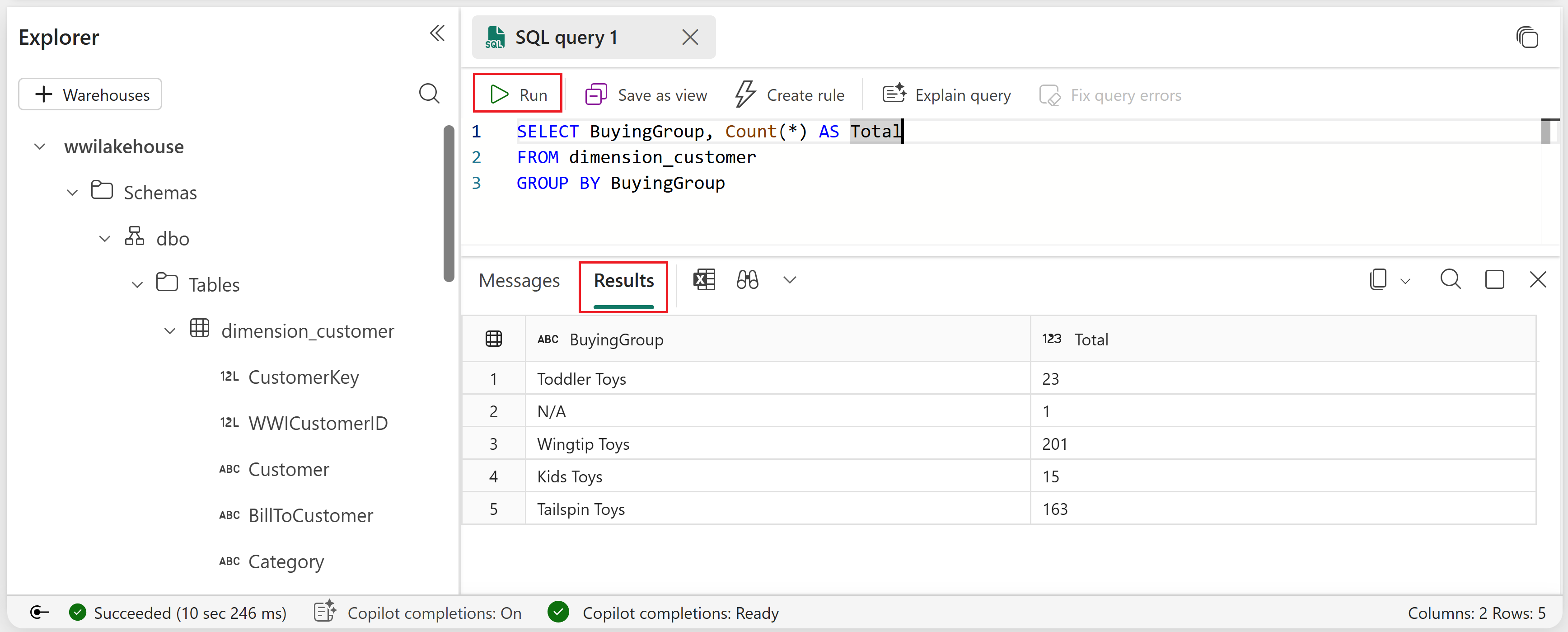
Введите следующий пример запроса, который агрегирует количество строк на основе столбца BuyingGroup таблицы dimension_customer .
SELECT BuyingGroup, Count(*) AS Total FROM dimension_customer GROUP BY BuyingGroupПримечание.
Файлы SQL-запросов сохраняются автоматически для будущей ссылки, и вы можете переименовать или удалить эти файлы в зависимости от необходимости.
Чтобы запустить скрипт, щелкните значок запуска в верхней части файла скрипта.







Добавление таблиц в семантику модели
В этом разделе вы добавите таблицы в семантику модели, чтобы их можно было использовать для создания отчетов.
Откройте lakehouse и перейдите в представление конечной точки аналитики SQL.
Выберите новую семантику.
В области "Новая семантическая модель" введите имя семантической модели , назначьте рабочую область и выберите таблицы, которые требуется добавить. В этом случае выберите таблицу dimension_customer.
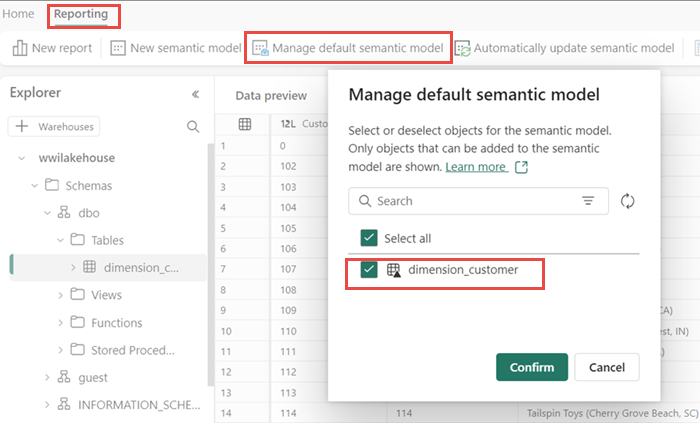
Нажмите кнопку "Подтвердить" , чтобы создать семантику модели.
Предупреждение
Если вы получаете сообщение об ошибке "Не удалось добавить или удалить таблицы" из-за превышения лимитов вычислительных мощностей Fabric вашей организации, подождите несколько минут и повторите попытку. Дополнительные сведения см. в документации по емкости Fabric.
Семантическая модель создается в режиме хранилища Direct Lake, что означает, что она считывает данные непосредственно из таблиц Delta в OneLake для быстрого выполнения запросов без необходимости импортировать данные. После создания можно изменить семантику модели, чтобы добавить связи, меры и многое другое.
Подсказка
Дополнительные сведения о Direct Lake и его преимуществах см. в обзоре Direct Lake.

Создание отчета
В этом разделе вы создадите отчет из созданной семантической модели.
В рабочей области найдите созданную семантику модели, выберите меню ... (многоточие), а затем выберите "Автоматически создать отчет".
Таблица является измерением, и в ней нет мер. Power BI создает меру для счетчика строк, объединяет ее по разным столбцам и создает различные диаграммы, как показано на следующем снимке экрана.
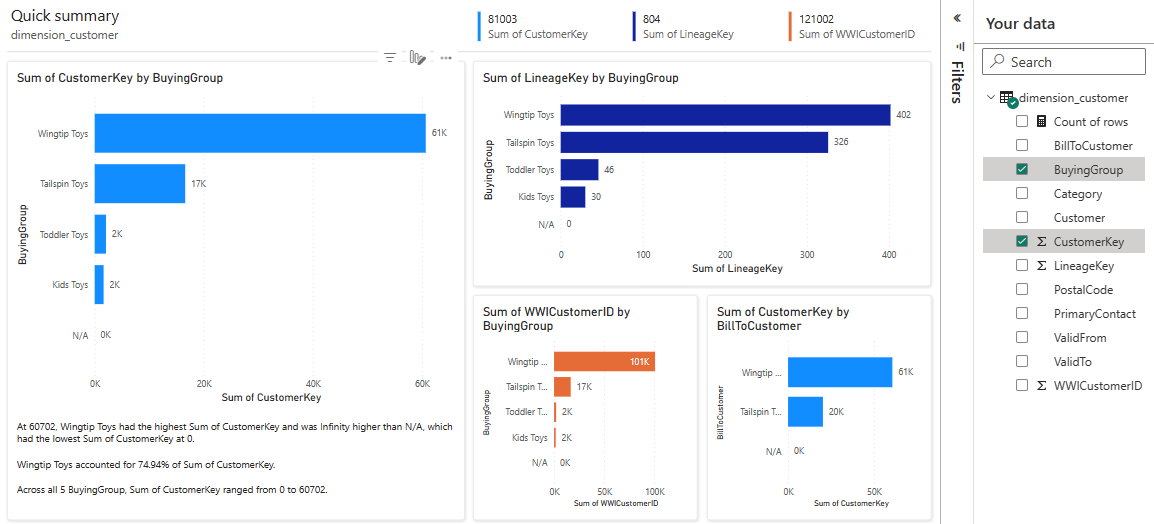
Этот отчет можно сохранить в будущем, нажав кнопку "Сохранить " на верхней ленте. Вы можете внести дополнительные изменения в этот отчет в соответствии с вашими требованиями, включив или исключив другие таблицы или столбцы.

