Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Потоки данных — это самостоятельная облачная технология подготовки данных. В этой статье вы создадите первый поток данных, получите данные для потока данных, а затем преобразуете данные и опубликуете поток данных.
Предварительные требования
Перед началом работы требуются следующие предварительные требования:
- Учетная запись клиента Microsoft Fabric с активной подпиской. Создайте бесплатную учетную запись.
- Убедитесь, что у вас есть включенная рабочая область Microsoft Fabric: Создайте рабочую область.
Создание потока данных
В этом разделе вы создаете первый поток данных.
Замечание
По состоянию на апрель 2026 г. все новые элементы потока данных 2-го поколения создаются с поддержкой интеграции CI/CD и Git по умолчанию. Возможность создания элементов потока данных 2-го поколения без поддержки CI/CD больше недоступна. Существующие потоки данных, отличные от CI/CD, продолжают работать.
Перейдите к рабочей области Microsoft Fabric, перейдя на портал Microsoft Fabric выберите Workspaces в области навигации слева и выберите рабочую область из списка.
Выберите +Новый элемент, а затем выберите Поток данных Gen2.
Получить данные
Давайте получим некоторые данные! В этом примере вы получаете данные из службы OData. Чтобы получить данные в потоке данных, выполните следующие действия.
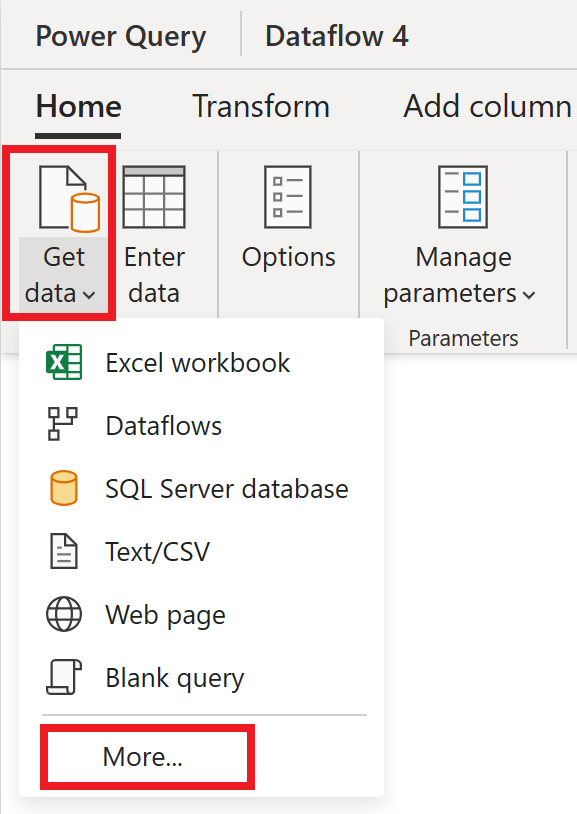
В редакторе потока данных выберите " Получить данные " и нажмите кнопку "Дополнительно".
В разделе "Выбор источника данных" выберите "Просмотреть больше".
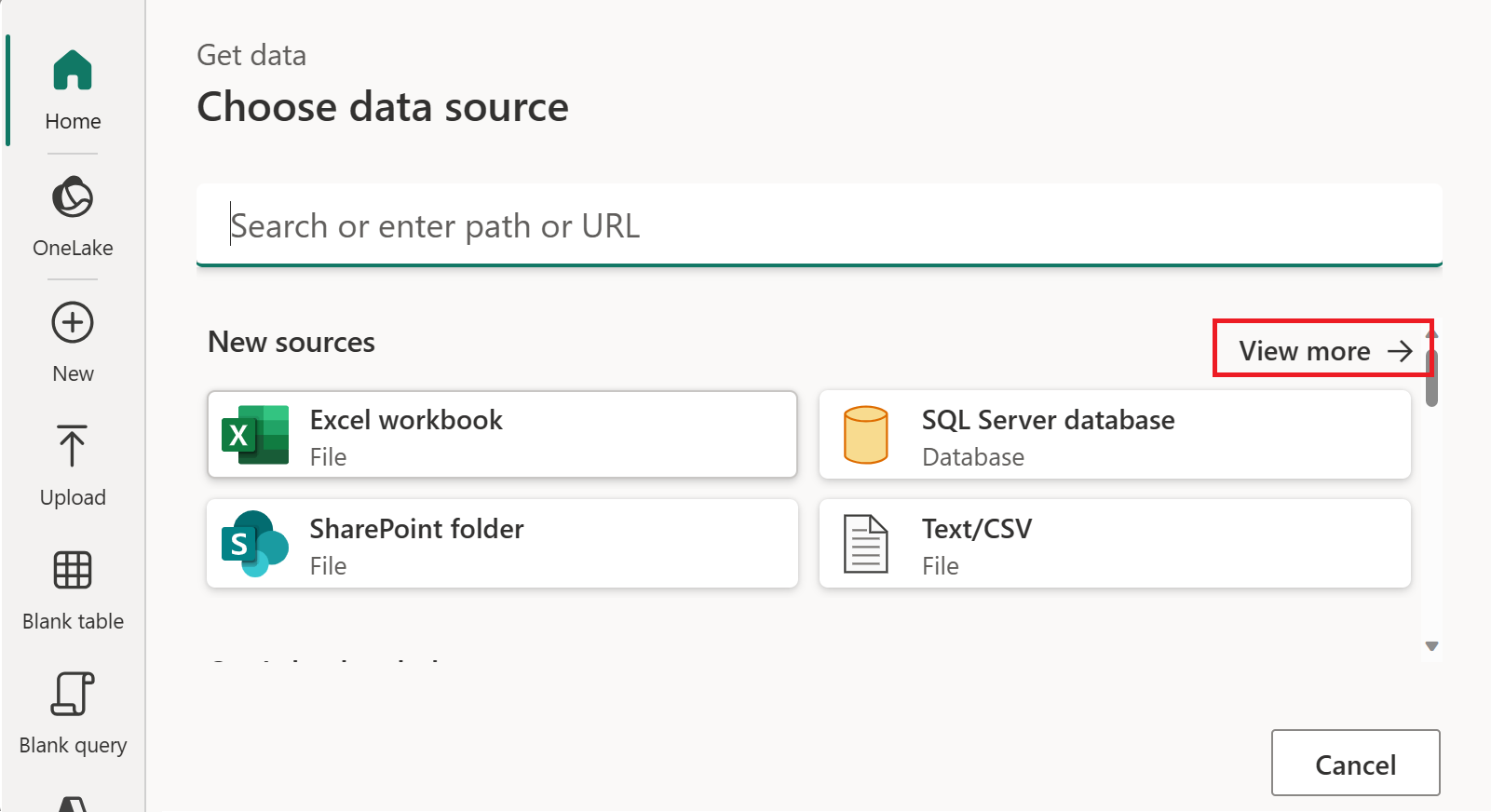
В новом источнике выберите "Другие>OData" в качестве источника данных.

Введите URL-адрес
https://services.odata.org/v4/northwind/northwind.svc/и нажмите кнопку "Далее".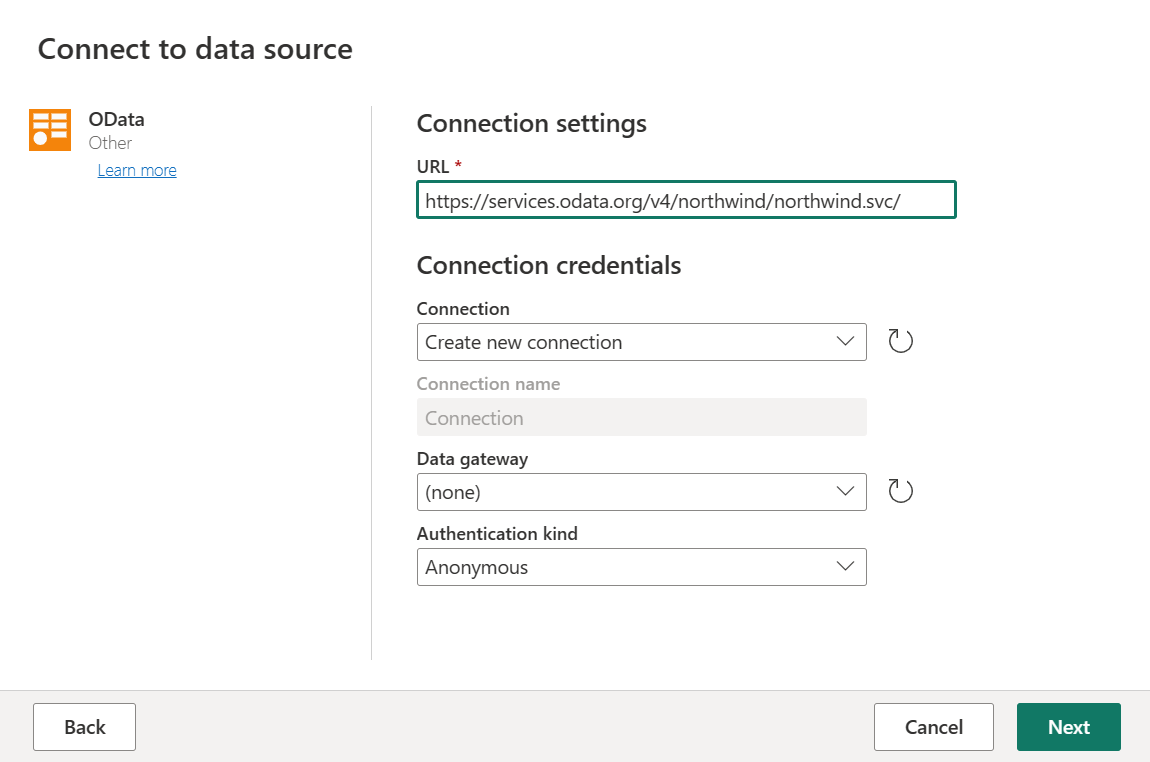
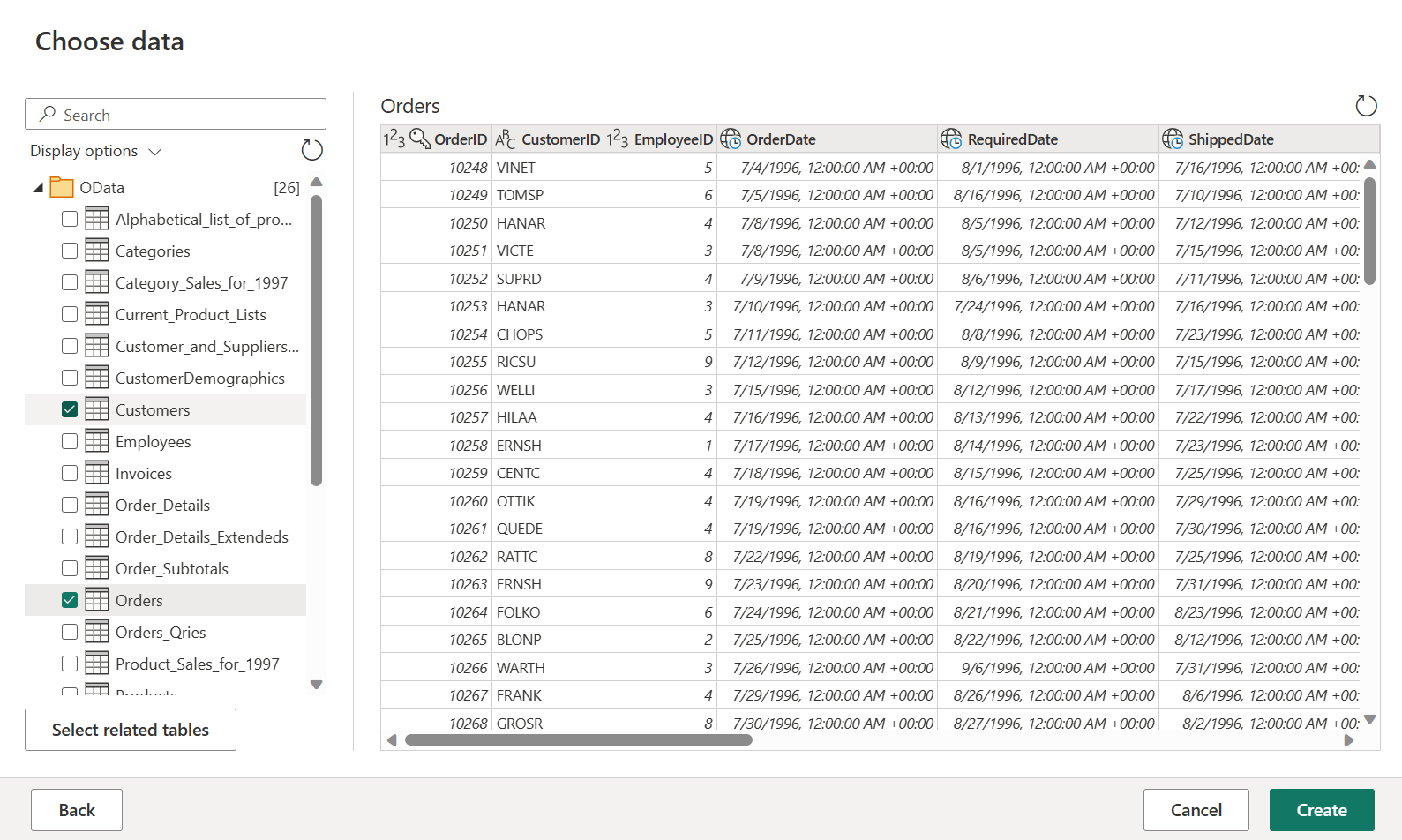
Выберите таблицы "Заказы и клиенты", а затем нажмите кнопку "Создать".



Дополнительные сведения о возможностях и функциональности получения данных см. в обзоре получения данных.
Применение преобразований и публикация
Вы загружаете данные в первый поток данных. Поздравляю! Теперь пришло время применить несколько преобразований, чтобы перенести эти данные в нужную форму.
Данные преобразуются в редакторе Power Query. Подробный обзор редактора Power Query можно найти в Пользовательском интерфейсе Power Query, но в этом разделе описаны основные действия.
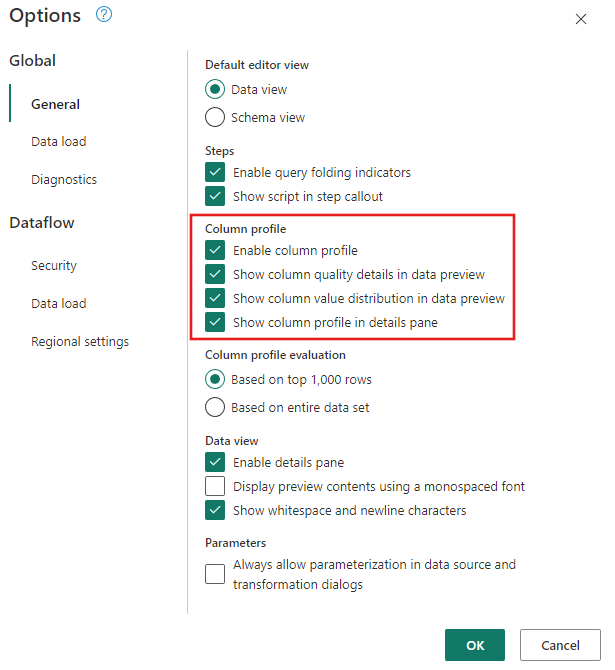
Убедитесь, что средства профилирования данных включены. Перейдите в раздел "Главная>Параметры>Глобальные параметры", а затем выберите все параметры в разделе "Профиль столбца".
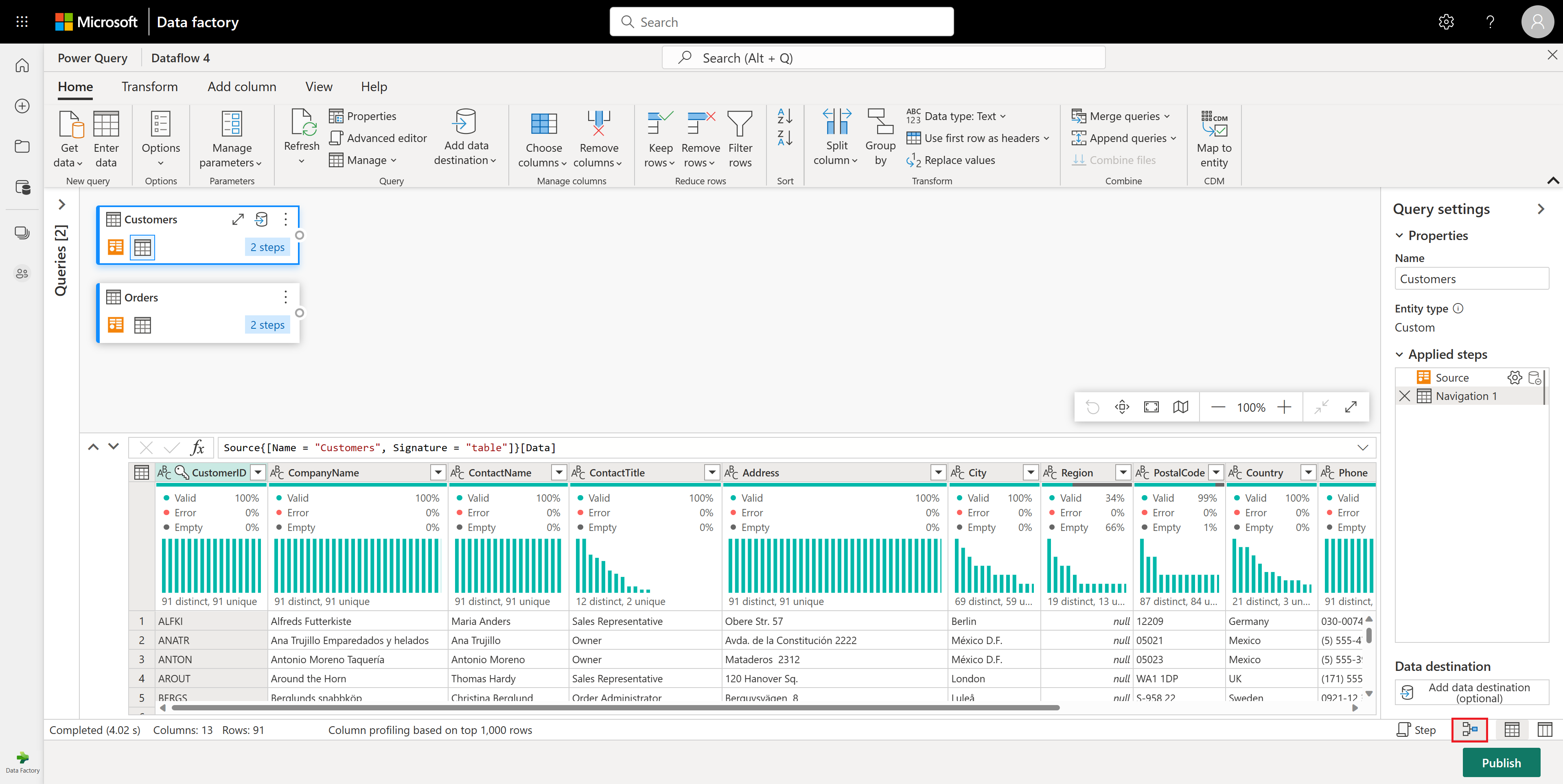
Кроме того, включите представление диаграммы с помощью параметров макета на вкладке Вид на ленте редактора Power Query или выбрав значок представления диаграммы в правой нижней части окна Power Query.
В таблице "Заказы" вычислите общее количество заказов для каждого клиента: выберите столбец CustomerID в предварительной версии данных и выберите "Группировать по " на вкладке "Преобразование " на ленте.
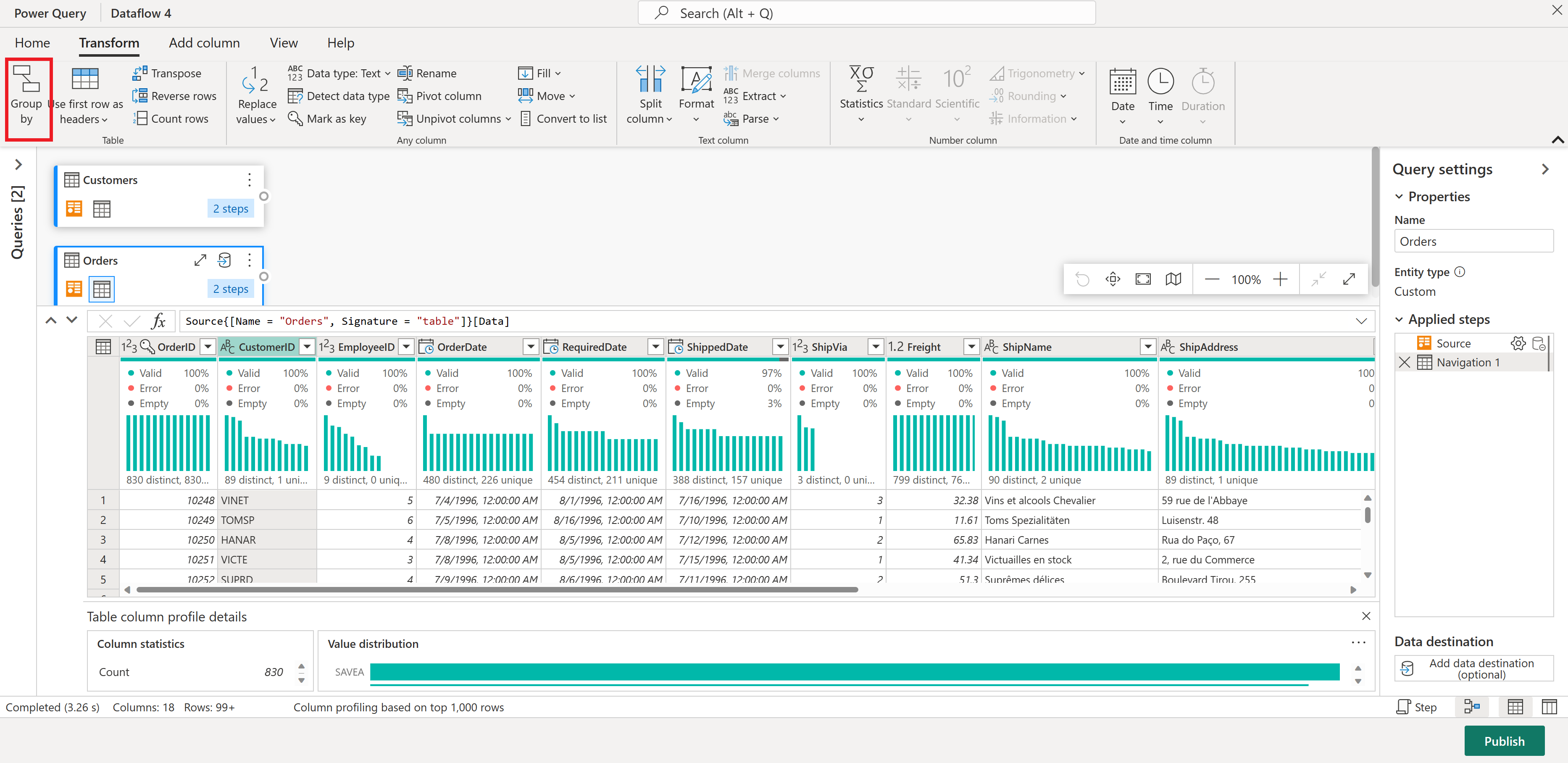
Вы выполняете подсчет строк в качестве агрегатной функции в Group By. Дополнительные сведения о возможностях group By см. в разделе "Группирование" или "Сводка строк".
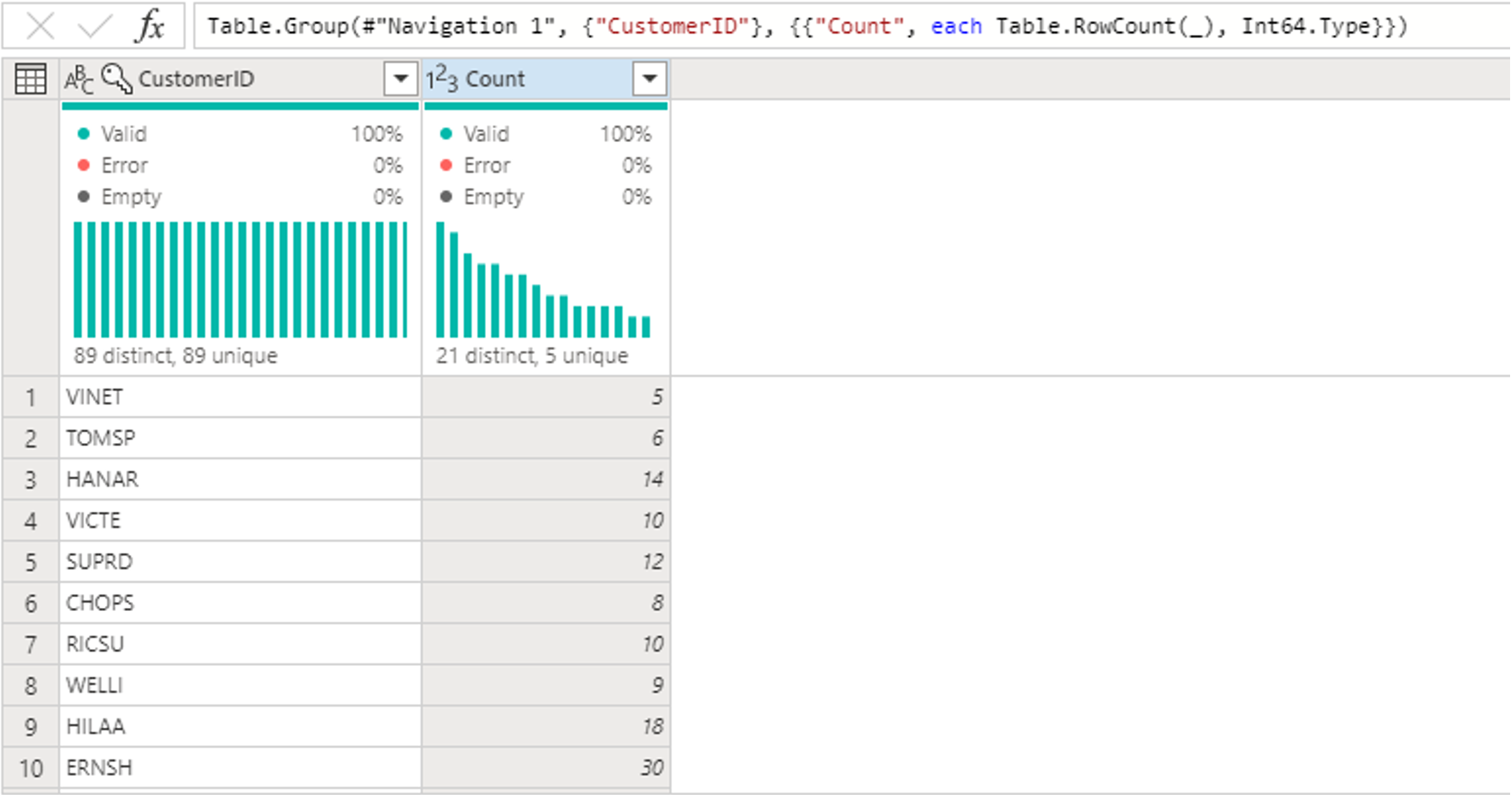
После группировки данных в таблице Orders мы получим таблицу с двумя столбцами с CustomerID и Count в качестве столбцов.
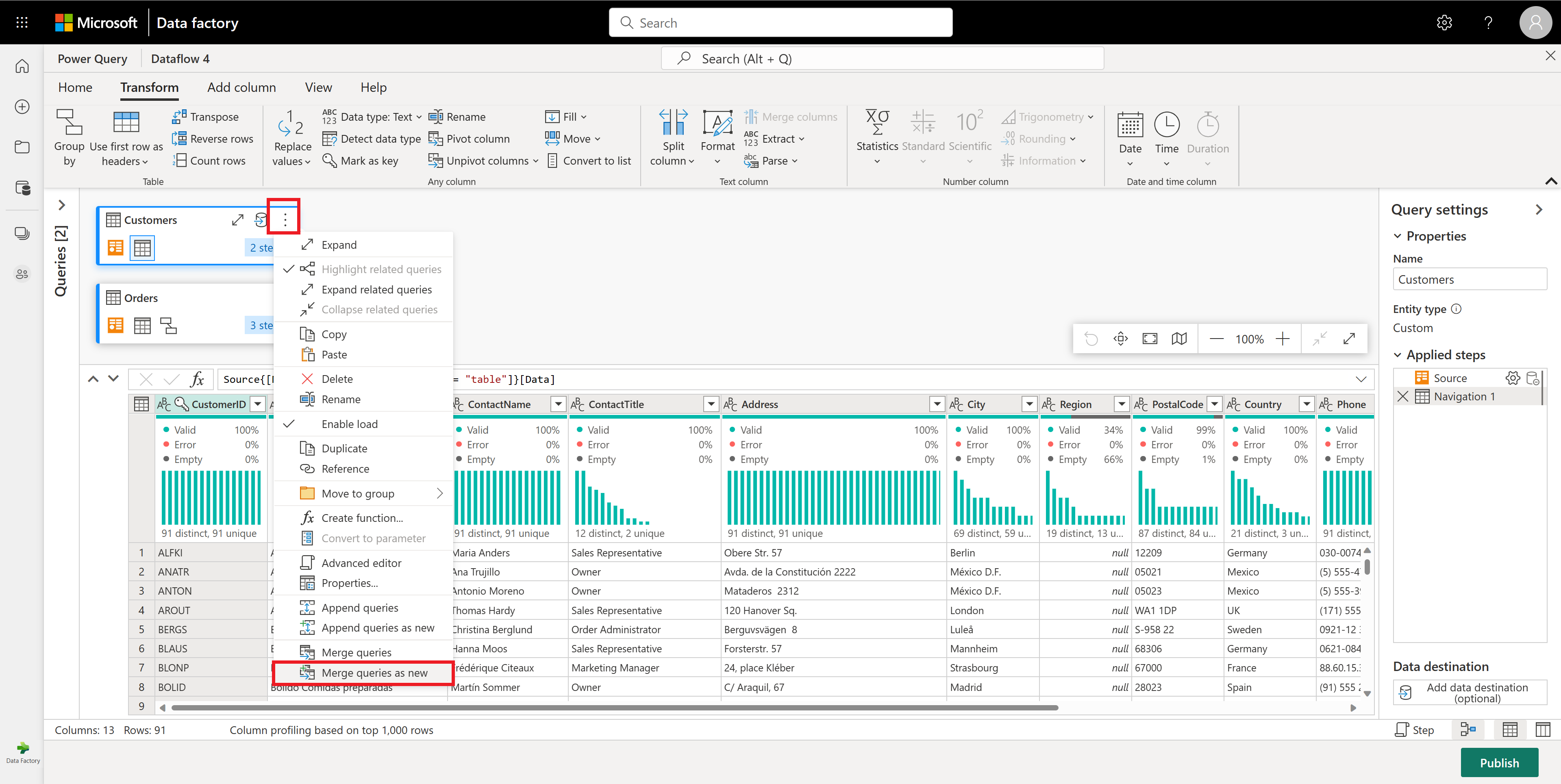
Затем необходимо объединить данные из таблицы "Клиенты" с числом заказов на клиента: выберите запрос "Клиенты" в представлении схемы и используйте меню "⋮" для доступа к запросам слияния в качестве нового преобразования.
Настройте операцию слияния , выбрав CustomerID в качестве соответствующего столбца в обеих таблицах. Затем выберите ОК.
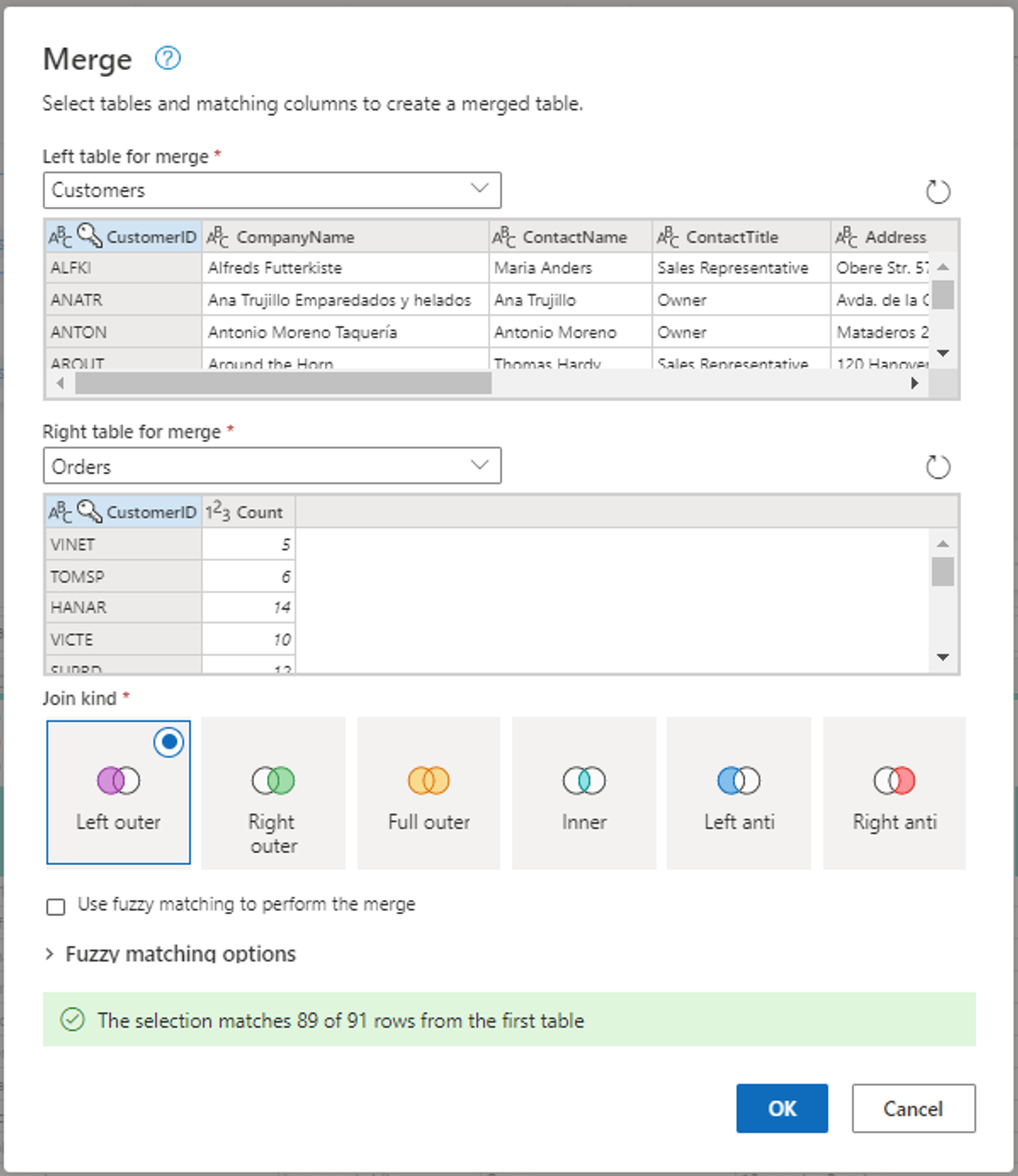
Снимок экрана: окно слияния с левой таблицей для слияния, заданной в таблице Customers, и правой таблицей для слияния, заданной в таблице Orders. Столбец CustomerID выбран для таблиц "Клиенты" и "Заказы". Тип соединения установлен как "Левый внешний". Все остальные выборы задаются по умолчанию.
Теперь есть новый запрос со всеми столбцами из таблицы Customers и одним столбцом с вложенными данными из таблицы Orders.
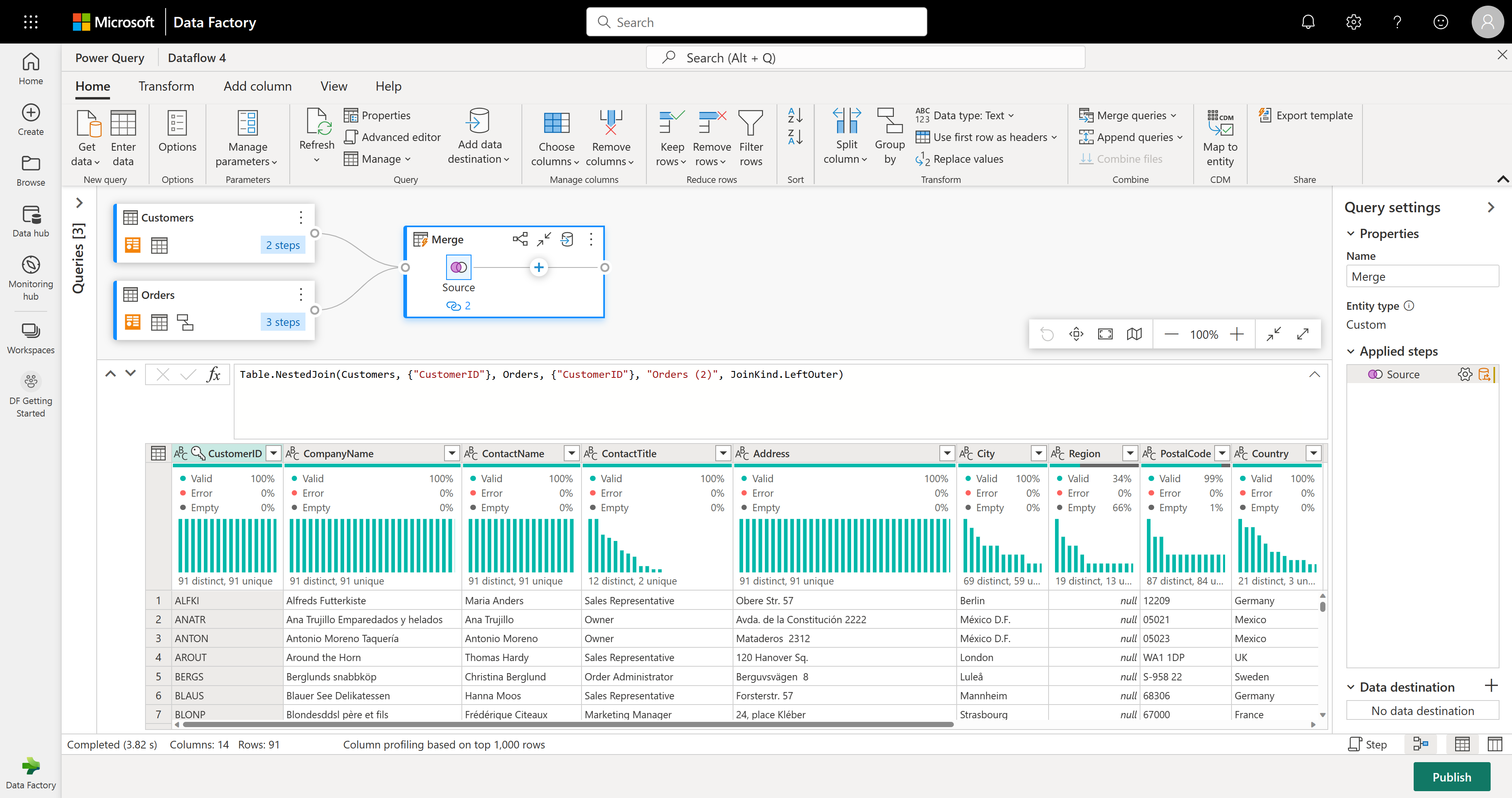
Давайте сосредоточимся на нескольких столбцах из таблицы Customers. Для этого включите представление схемы, нажав кнопку представления схемы в правом нижнем углу редактора потока данных.
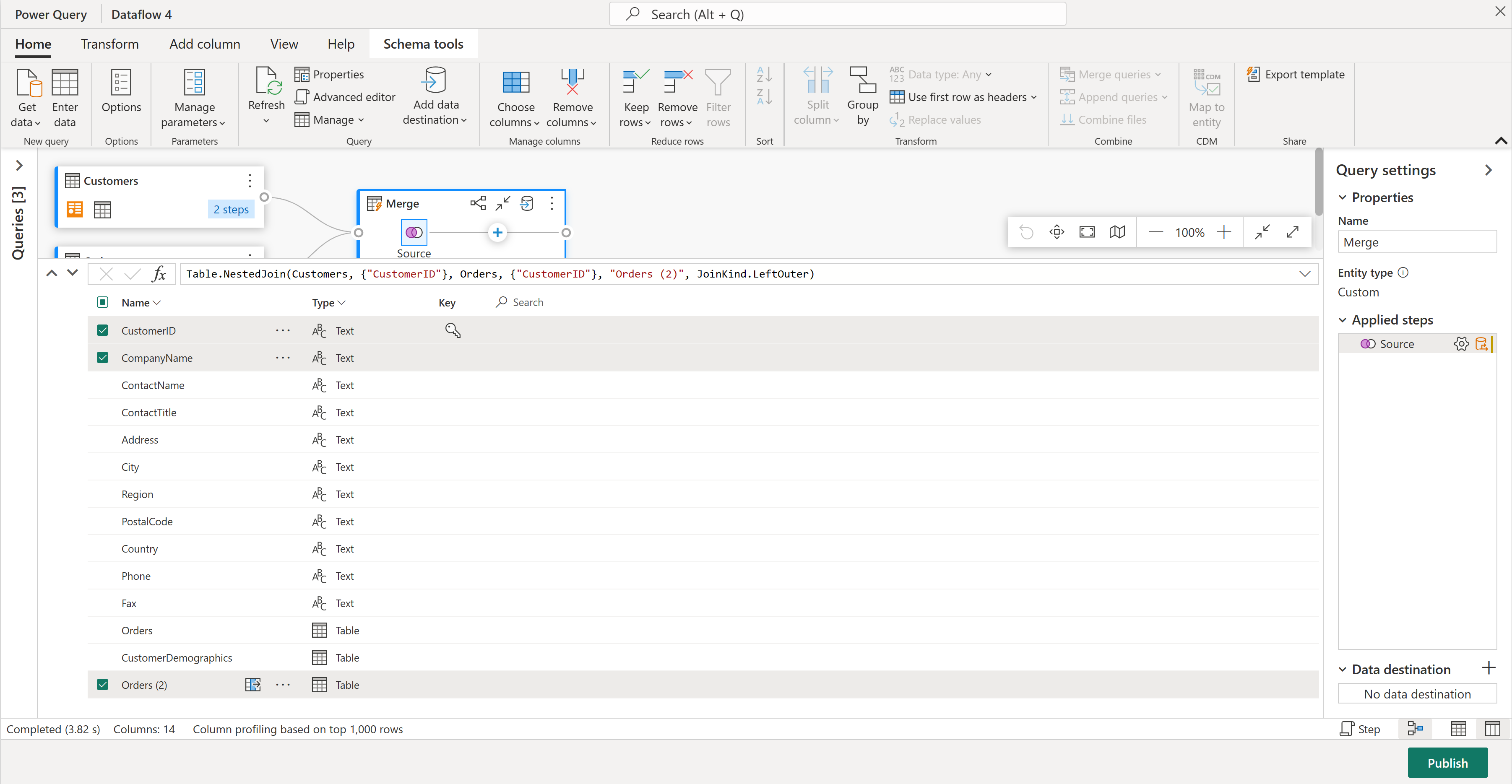
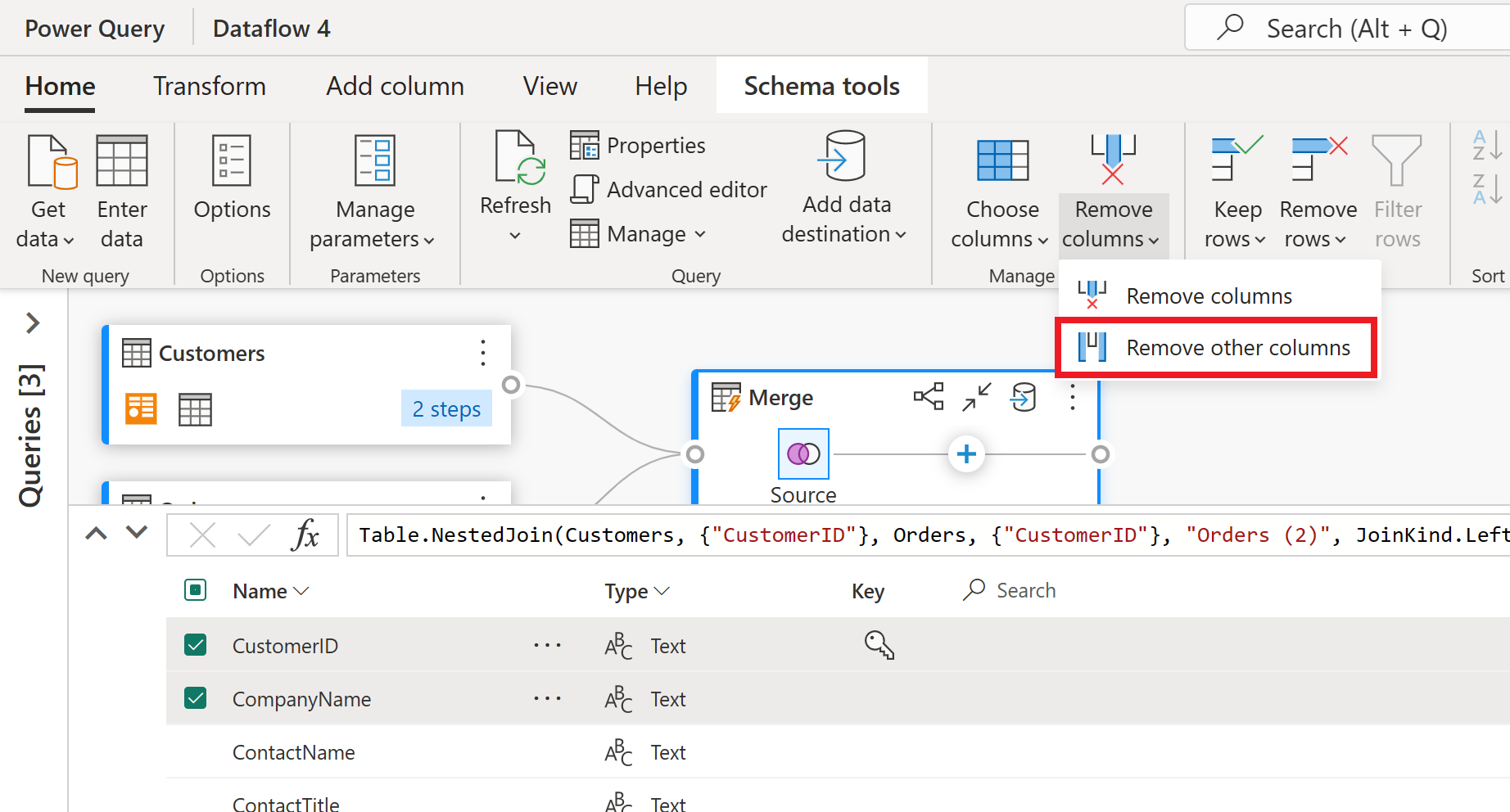
В представлении схемы вы увидите все столбцы в таблице. Выберите CustomerID, CompanyName и Orders (2). Затем перейдите на вкладку "Средства схемы" , выберите " Удалить столбцы" и выберите "Удалить другие столбцы". Это сохраняет только нужные столбцы.
Столбец Orders (2) содержит дополнительные сведения из шага слияния. Чтобы просмотреть и использовать эти данные, нажмите кнопку "Показать представление данных " в правом нижнем углу рядом с представлением схемы. Затем в заголовке столбца Orders (2) выберите значок "Развернуть столбец " и выберите столбец Count . Это добавляет количество заказов для каждого клиента в таблицу.
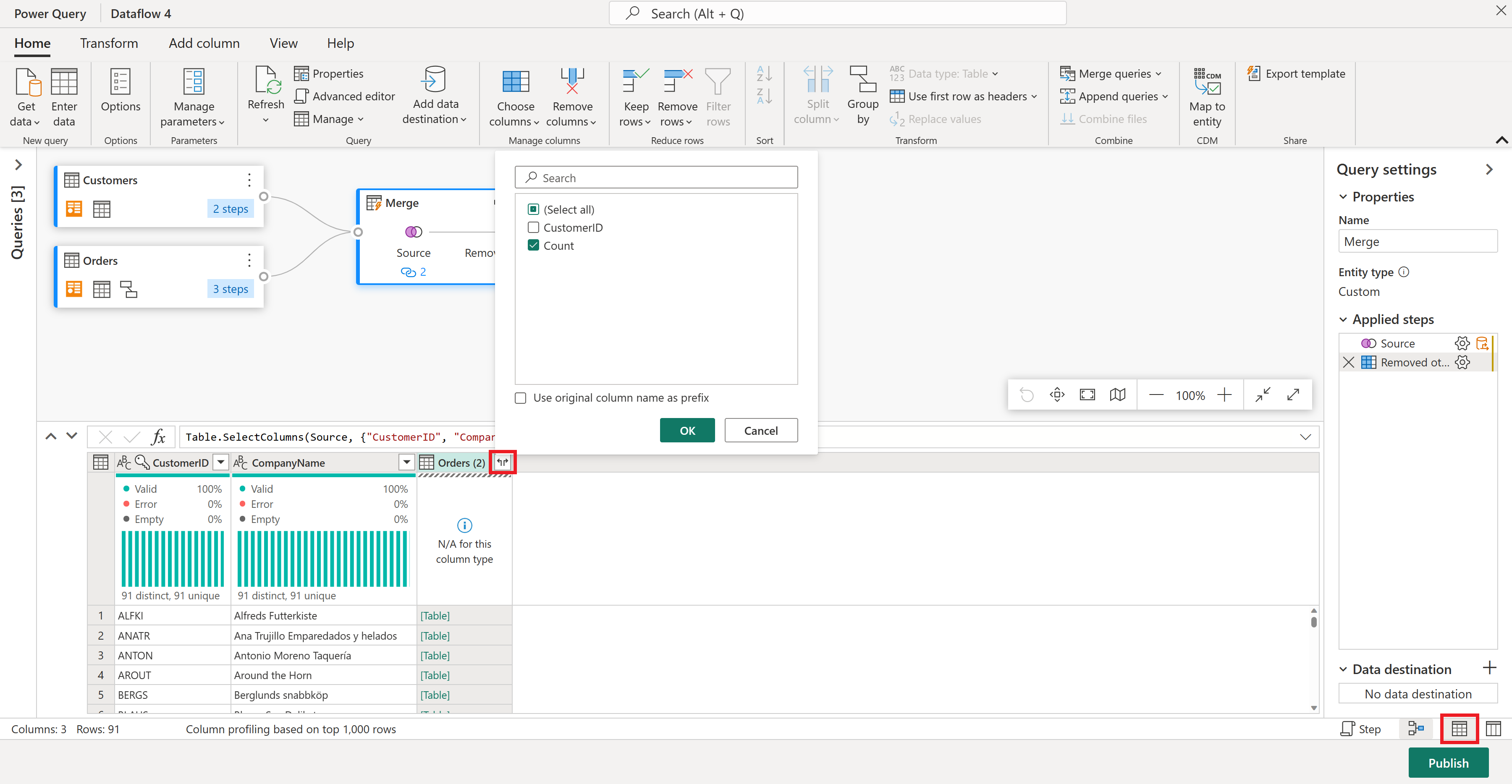
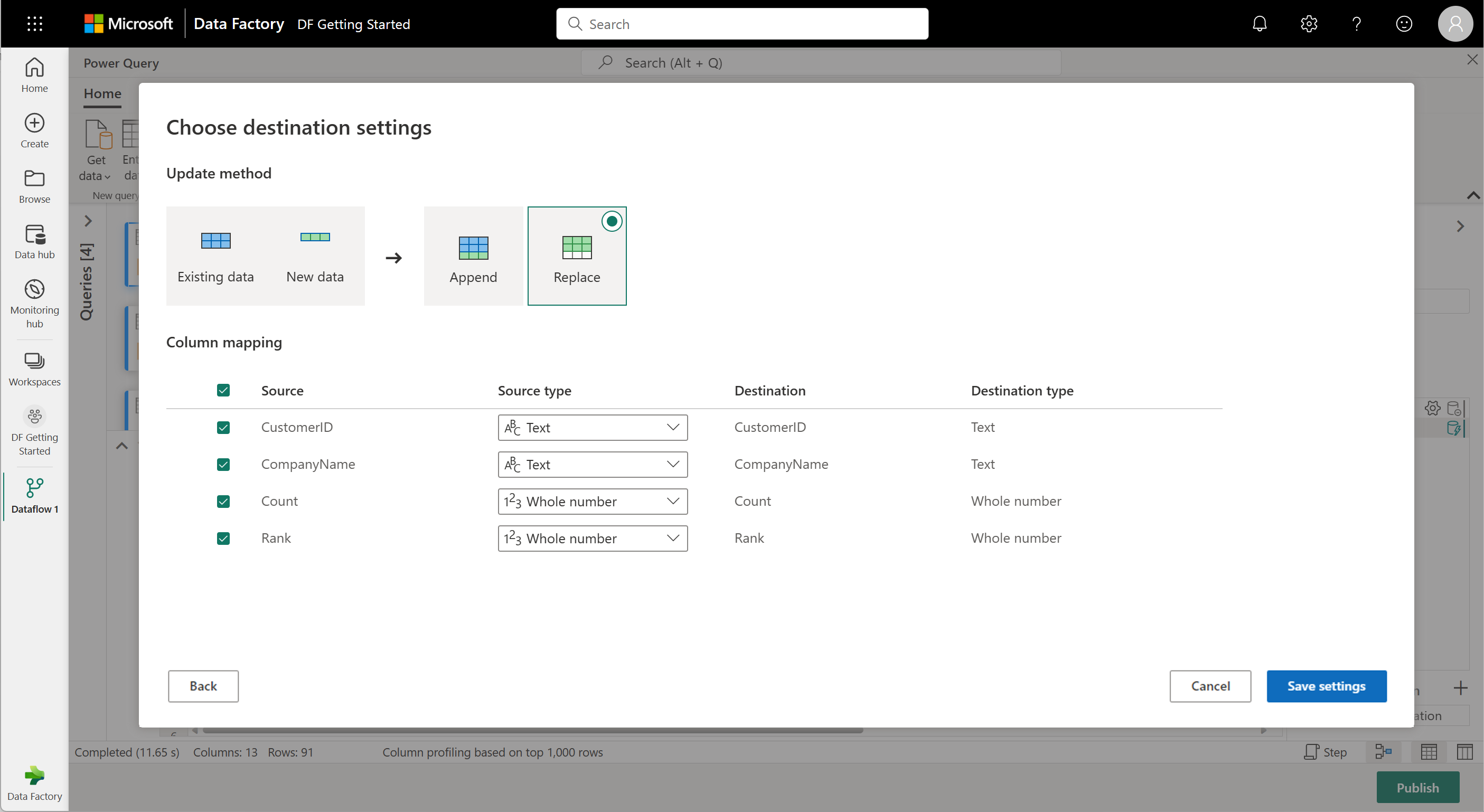
Теперь давайте ранжируем ваших клиентов по сколько заказов они сделали. Выберите столбец Count , а затем перейдите на вкладку "Добавить столбец " и выберите столбец "Ранжирование". При этом добавляется новый столбец, показывающий ранг каждого клиента на основе их количества заказов.
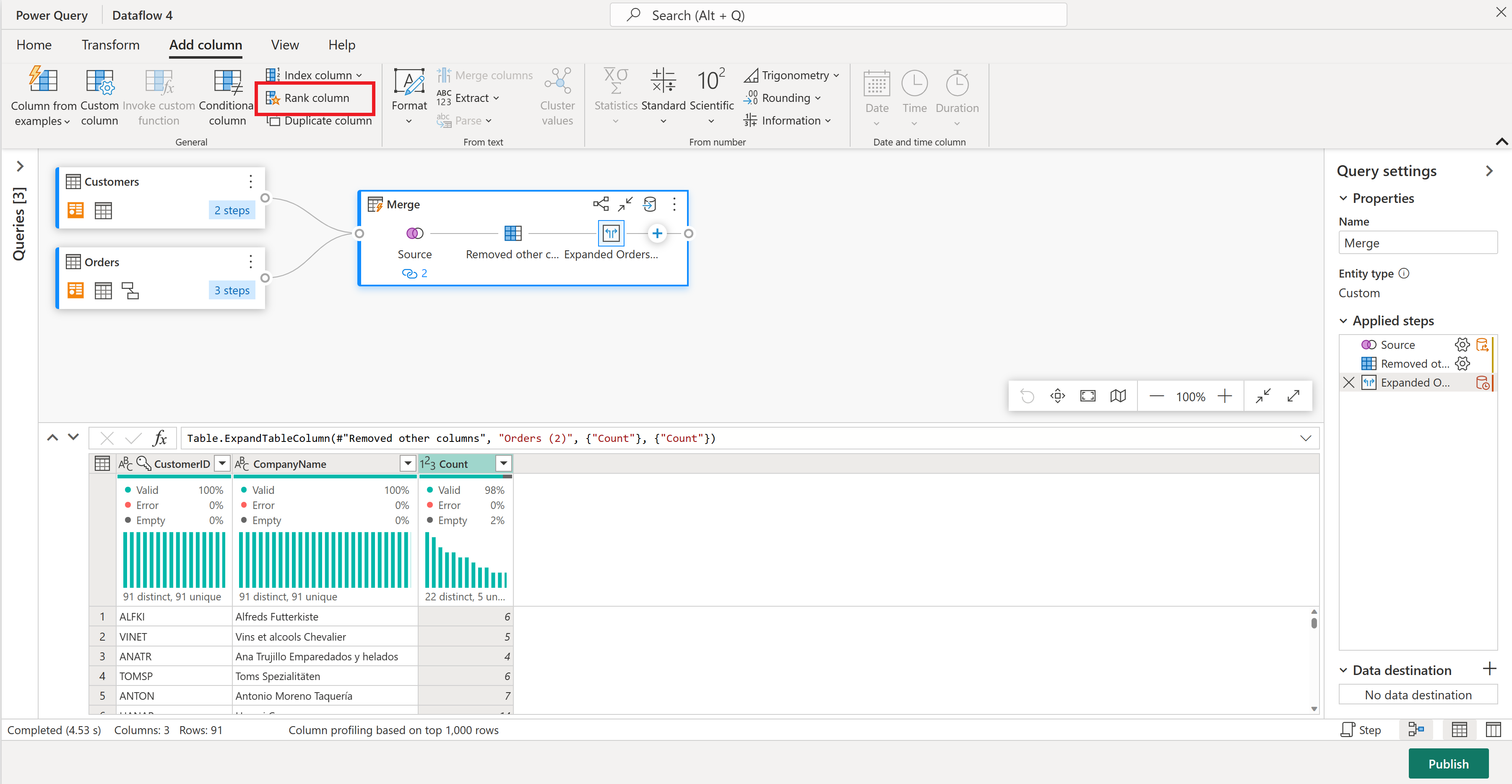
Сохраните параметры по умолчанию в столбце ранжирования. Затем нажмите кнопку "ОК ", чтобы применить это преобразование.
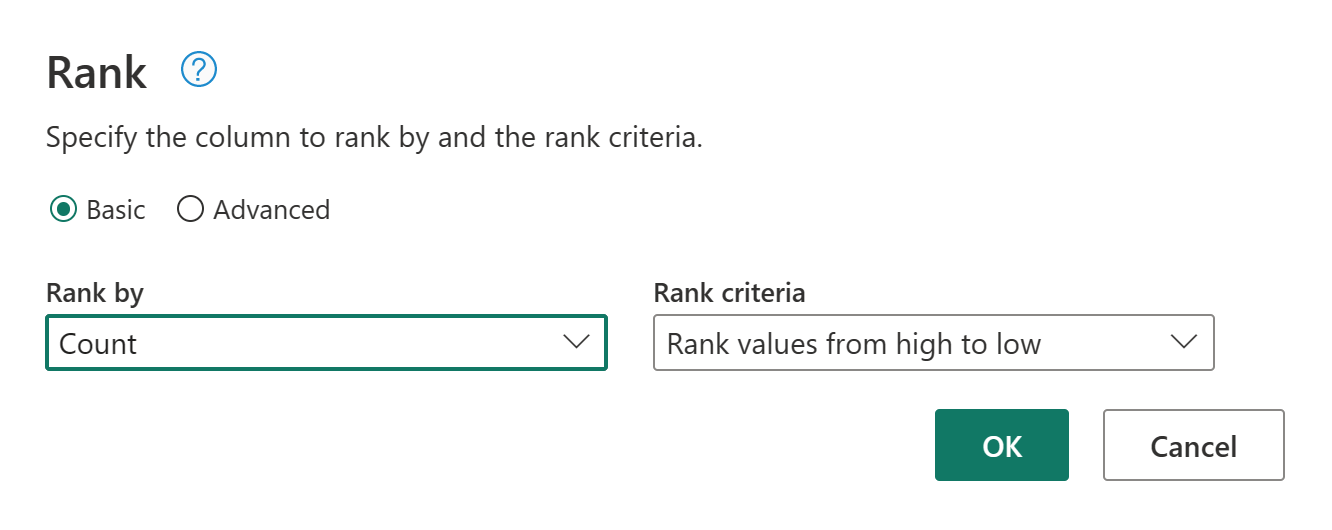
Теперь переименуйте полученный запрос в ранжированные клиенты с помощью панели настроек запроса справа от экрана.
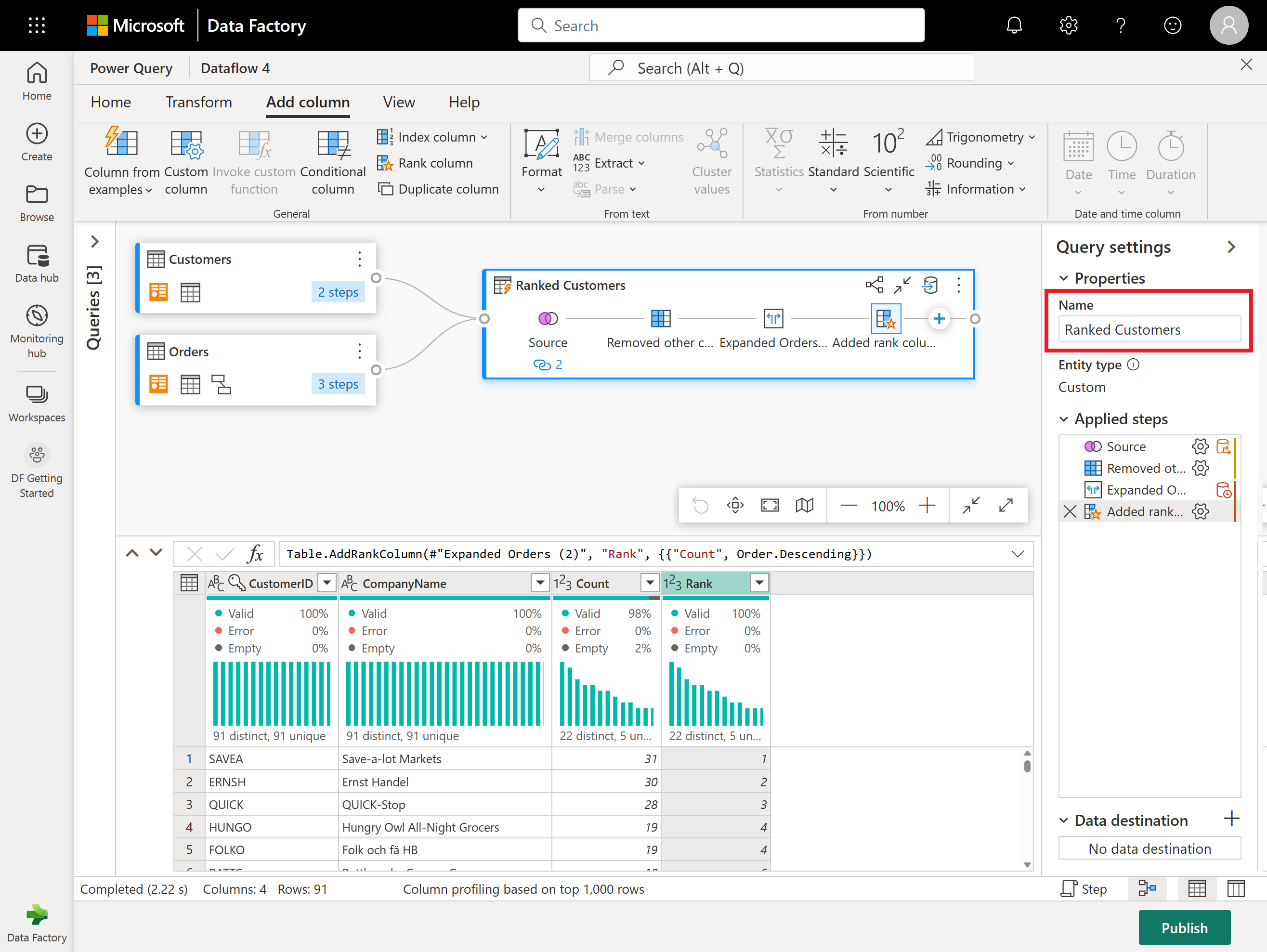
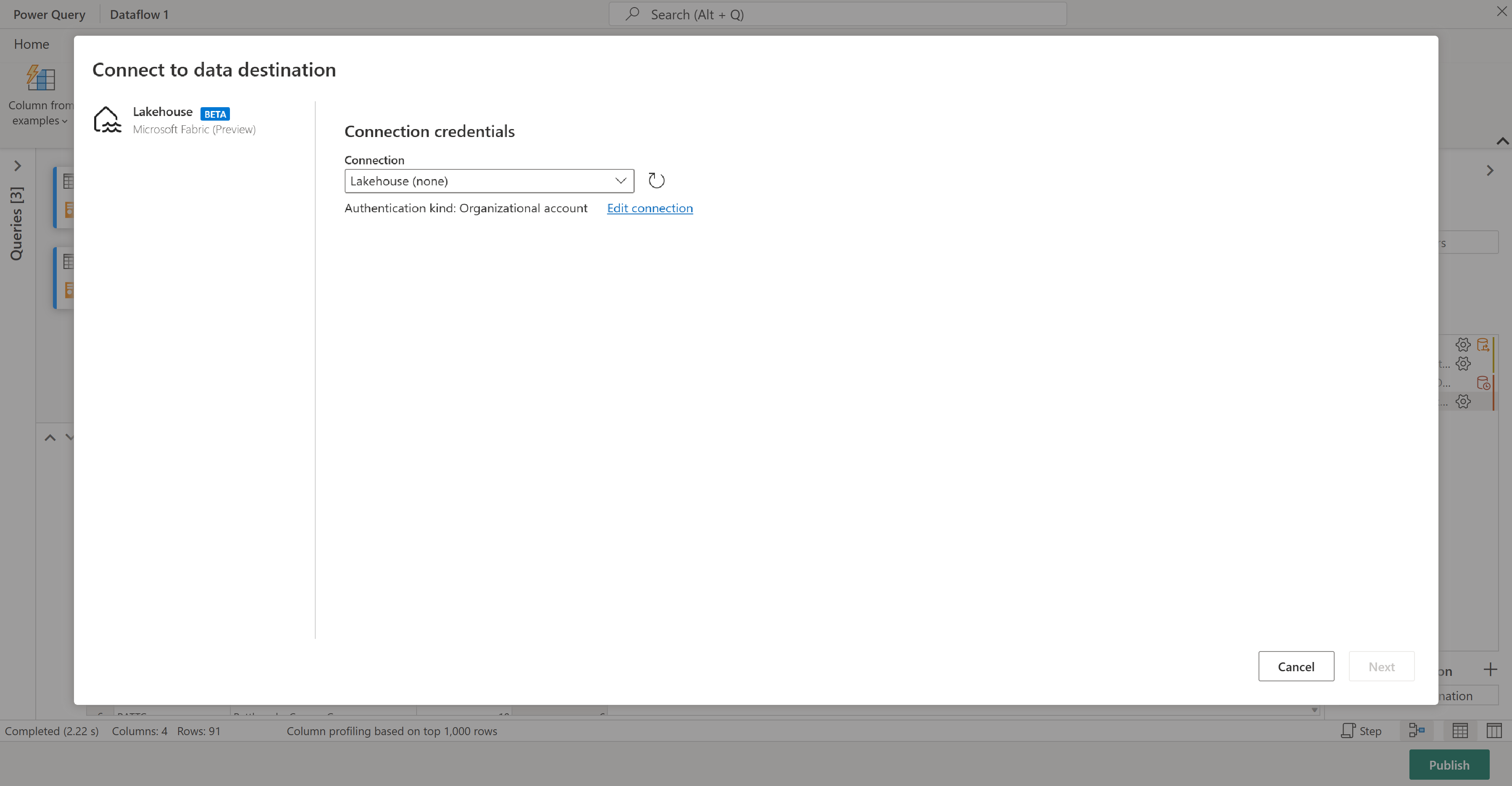
Вы готовы указать, куда будут отправлены ваши данные. В области параметров запроса прокрутите страницу вниз и выберите пункт "Выбрать назначение данных".
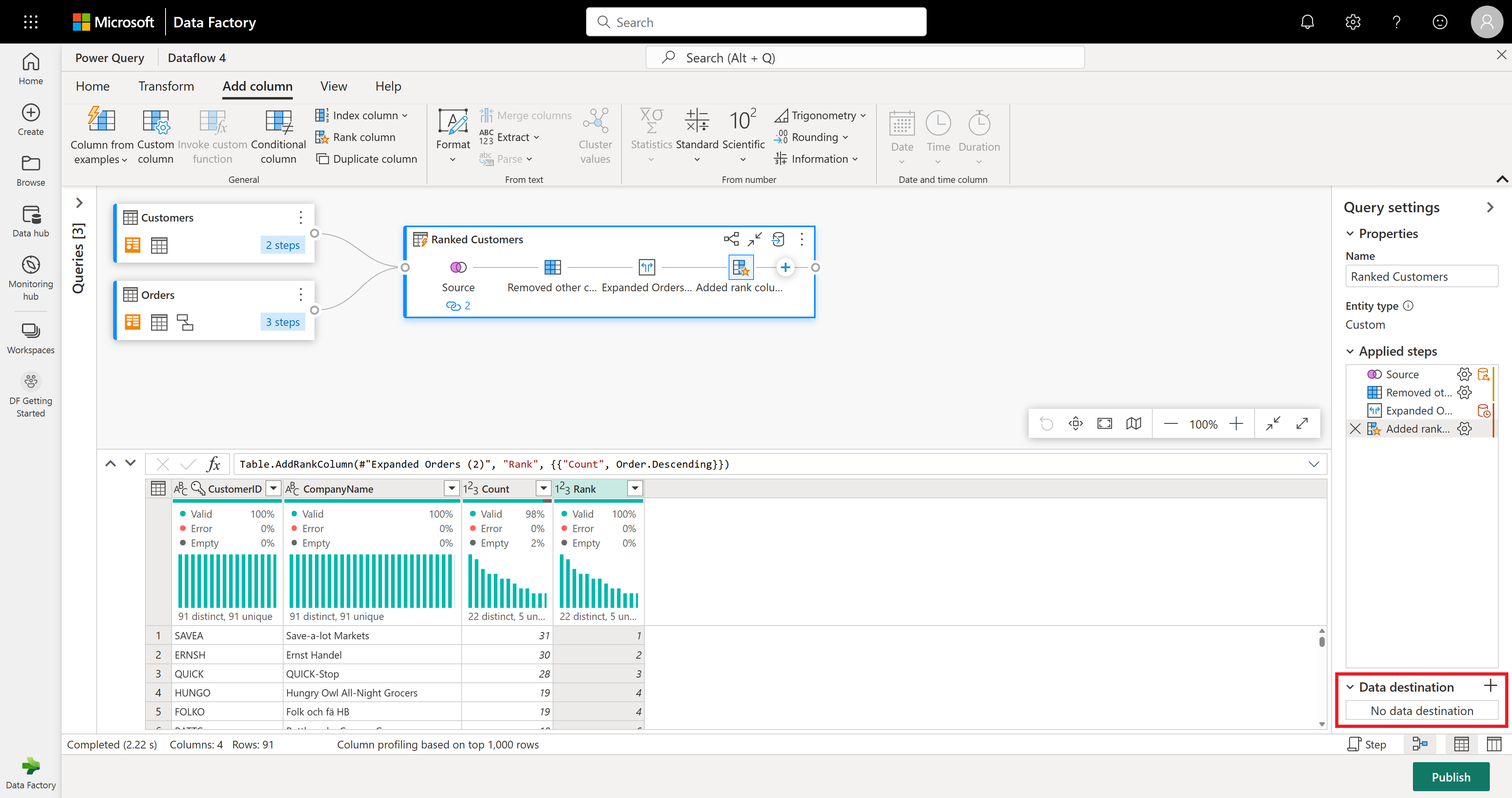
Вы можете отправить результаты в lakehouse, если у вас есть один, или пропустить этот шаг, если вы этого не сделали. Здесь вы можете выбрать, какой "lakehouse" и таблицу использовать для данных, и выбрать, следует ли добавлять новые данные (Добавить) или заменить существующие данные (Заменить).
Поток данных теперь готов к публикации. Просмотрите запросы в представлении диаграммы и выберите " Опубликовать".
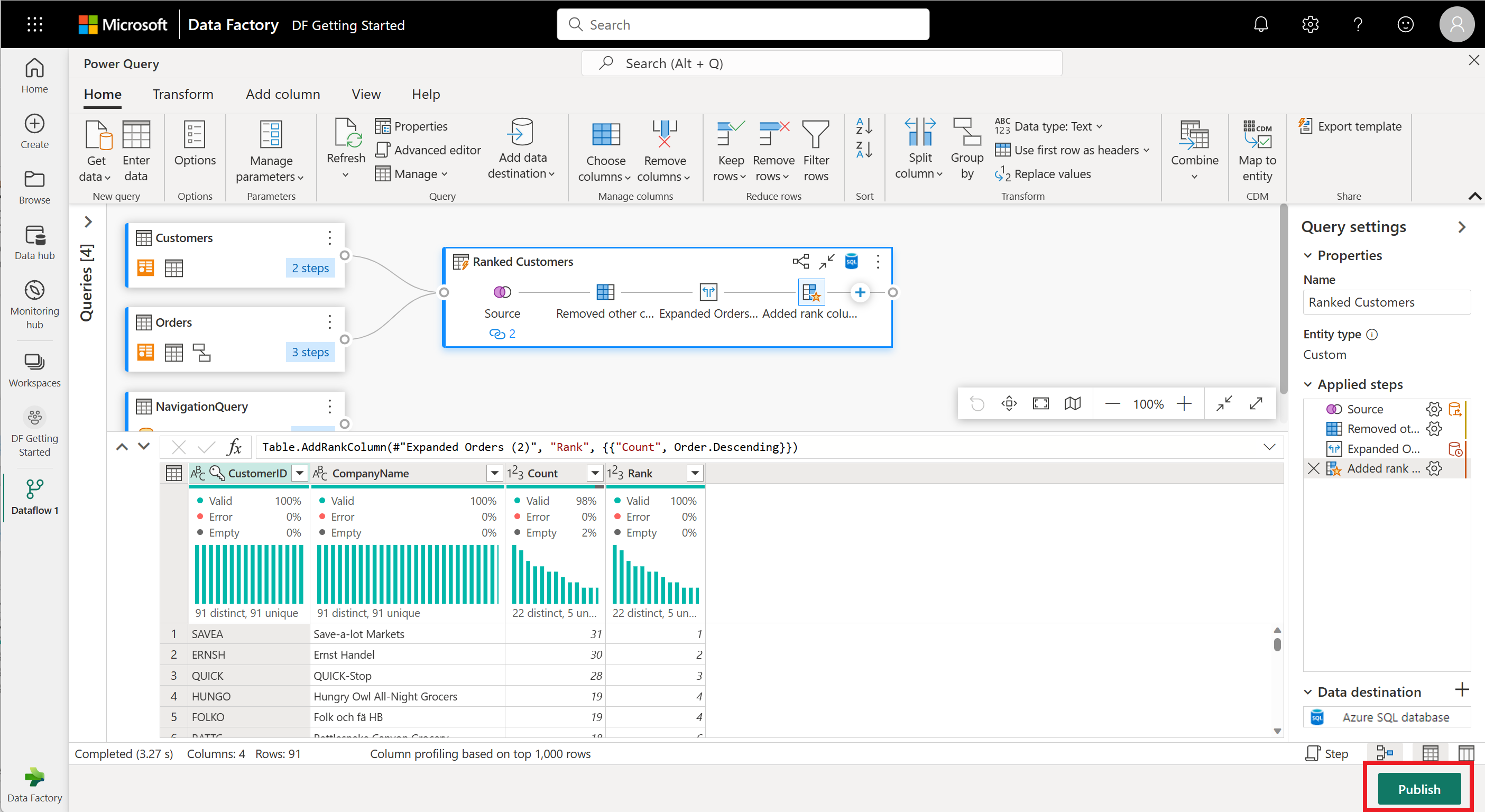
Выберите "Опубликовать " в правом нижнем углу, чтобы сохранить поток данных. Вы вернетесь в свою рабочую область, где рядом с именем вашего потока данных значок спиннера указывает, что идет публикация. Когда спиннер исчезнет, поток данных готов к обновлению!
Внимание
При первом создании Dataflow Gen2 в рабочей области Fabric настраивает некоторые фоновые компоненты (Лейкхаус и Дата-Хранилище), которые помогают работать вашему потоку данных. Эти элементы разделяются всеми потоками данных в рабочей области, и их не следует удалять. Они не предназначены для использования напрямую и обычно не отображаются в рабочей области, но их можно увидеть в других местах, таких как записные книжки или аналитика SQL. Ищите имена, которые начинаются с
DataflowStaging, чтобы заметить их.В рабочей области выберите значок "Запланировать обновление ".

Включите запланированное обновление, нажмите кнопку "Добавить еще раз" и настройте обновление, как показано на следующем снимке экрана.
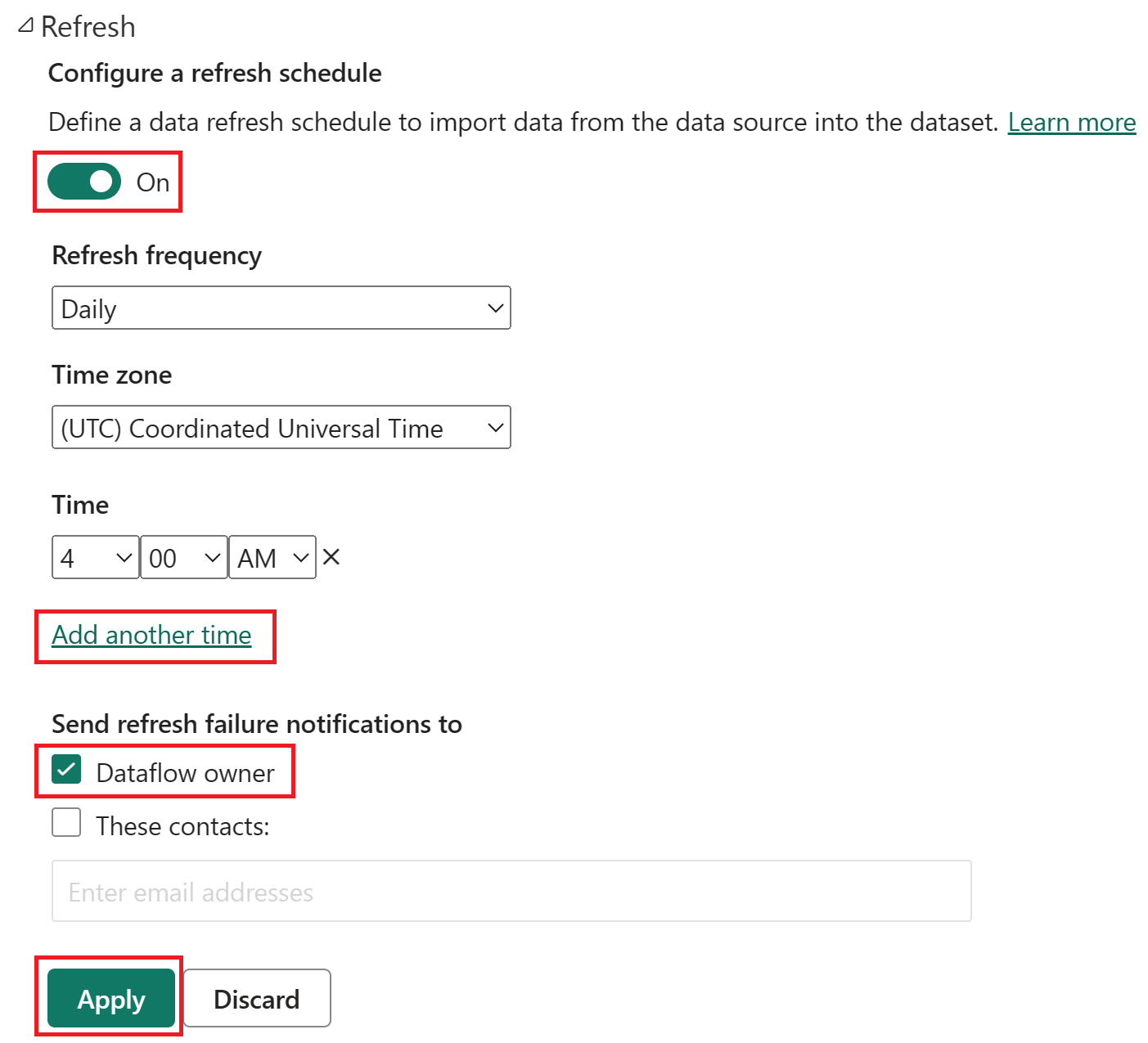
Снимок экрана с параметрами запланированного обновления, где запланированное обновление включено, частота обновления установлена на ежедневно, часовой пояс задан как координированное универсальное время, а время— 4:00 утра. Кнопка включения, кнопка "Добавить другое время", владелец потока данных и кнопка "Применить" все выделены.













Очистка ресурсов
Если вы не собираетесь продолжать использовать этот поток данных, удалите поток данных, выполнив следующие действия.
Перейдите в рабочую область Microsoft Fabric.
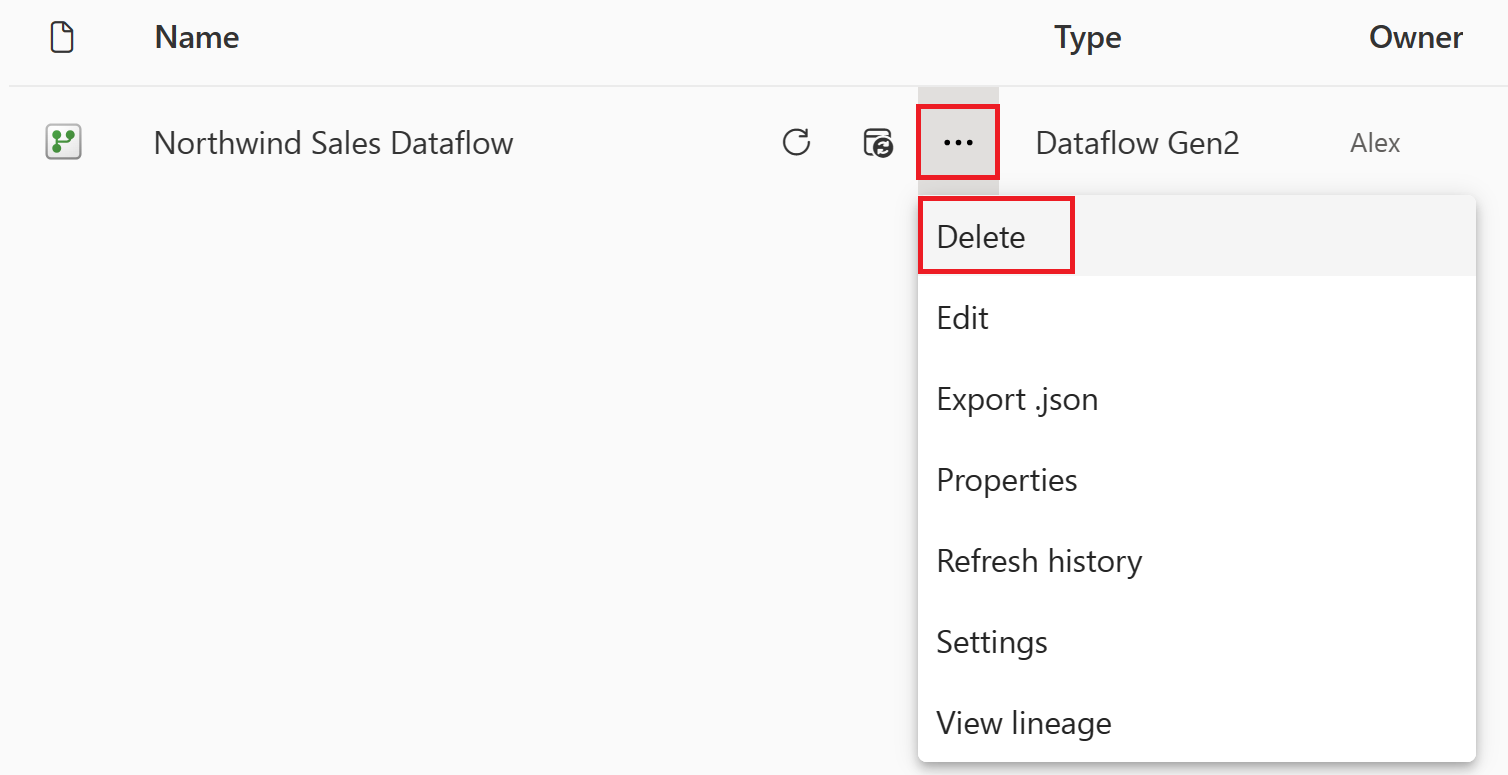
Выберите вертикальное многоточие рядом с именем потока данных и нажмите кнопку "Удалить".
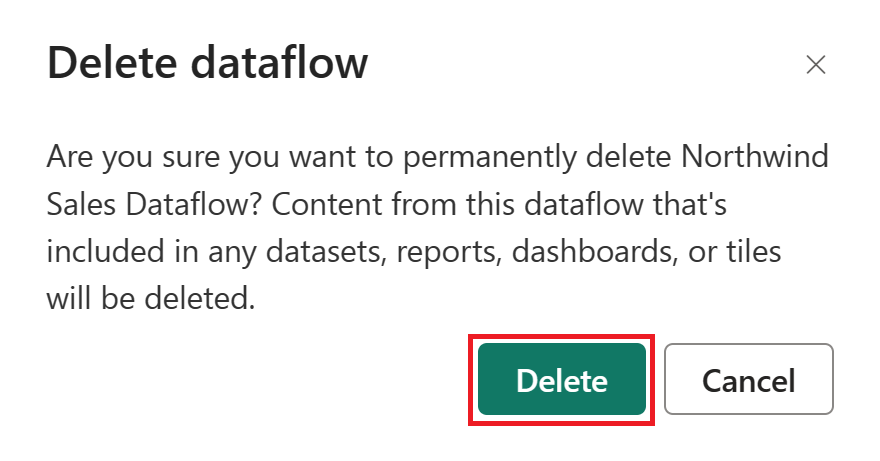
Выберите "Удалить" , чтобы подтвердить удаление потока данных.
Связанный контент
Поток данных в этом примере показывает, как загружать и преобразовывать данные в поток данных 2-го поколения. Вы научились выполнять следующие задачи:
- Создание потока данных 2-го поколения.
- Преобразовать данные.
- Настройте параметры назначения для преобразованных данных.
- Запустите и запланируйте конвейер.
Перейдите к следующей статье, чтобы узнать, как создать первый конвейер.